文章目录
模仿C库,自己封装一个最简单的文件接口 FILE
创建makefile
testfile: main.c mystdio.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f testfile
创建MY_FILE结构体 内部包含文件描述符fd,输出缓冲区ou’tputbuffer 、flags刷新方法
分别通过C库中fopen 、fwrite、fclose 接口的实现,设计属于自己的接口




分别实现了读、写追加方式
若想打开文件,需要调用open函数

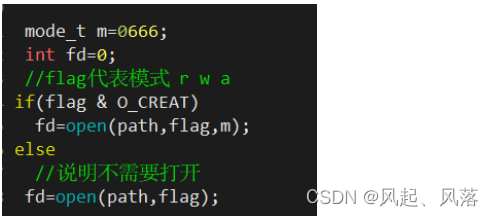
若需要创建文件,则需调用第二个open函数
由于open中的mode参数受umask影响,所以设置一个默认的mode
若不需要创建文件,则调用第一个open函数

判断对象是否创建成功,若失败需要将文件关闭

将自己设置的结构体MY_FILE内部的fd赋值为 open函数打开的返回值fd
刷新方法设置成行缓冲
outputbuffer缓冲区中全部初始化为0
current代表缓冲区中没有数据
当关闭文件的时候,fclose(FILE*) 将C语言当中的文件指针传进来
当关闭文件的时候,C要自己帮助我们进行冲刷缓冲区
为了方便表述,在MY_FILE结构体添加current变量

current代表下次写入时应该写入什么位置
如 outputbuffer中有5个字符 ,对应下标0 1 2 3 4 ,所以cuurrent代表下标5
自己实现一个fflush(刷新缓冲区),叫做MY_fflush


判断缓冲区是否有数据,若有数据就刷新出去

缓冲区为ptr,单个单元的大小为size,nmemb代表想要写入几个单元,写入对应的流中
实际上是往缓冲区里写的

刷新流的缓冲区
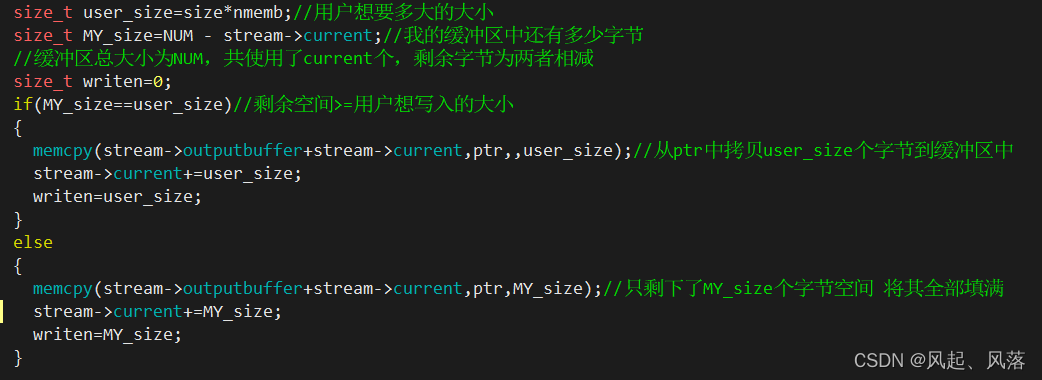
共分为两种情况,若剩余空间足够,则调用if语句,将用户从ptr拷贝的数据全部拷贝给缓冲区
同时由于缓冲区加入user_size个字节,要更新current的位置
若剩余空间不足够,则调用else语句,将从ptr拷贝的数据填满剩余空间即可
同时由于缓冲区加入MY_size个字节,要更新current的位置
通过调用sriten 代表实际写了多少字节,为了充当最后的的返回值
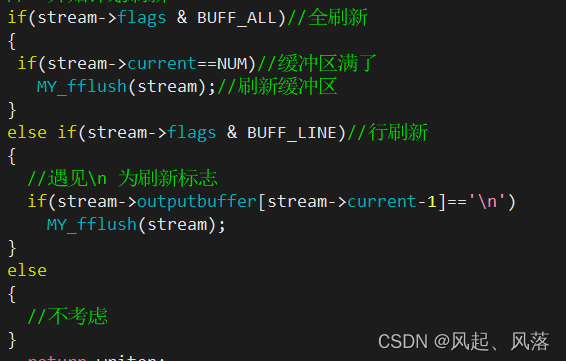
主要分为全刷新和行刷新两种情况,其他不考虑
全刷新判断缓冲区是否满了,若满了则直接刷新缓冲区
行刷新判断是否遇见\n,若遇见\n则直接刷新缓冲区
为了防止出现每次打印都会有之前的内容情况,所以刷新之后要清空
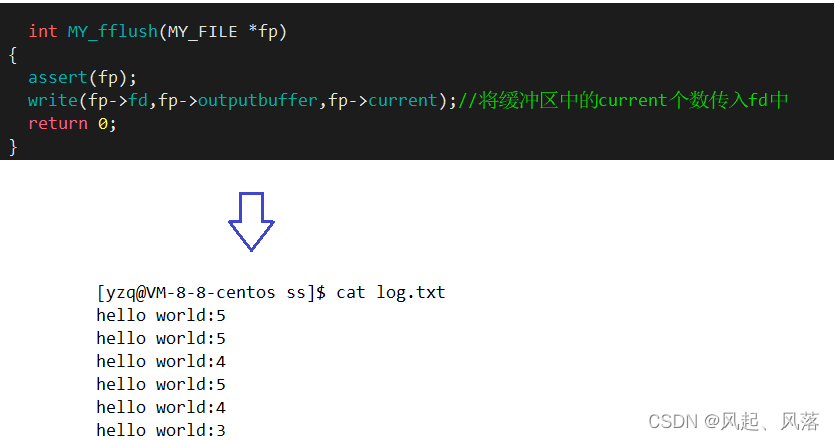
在这种情况下,之前的内容会被打印出来
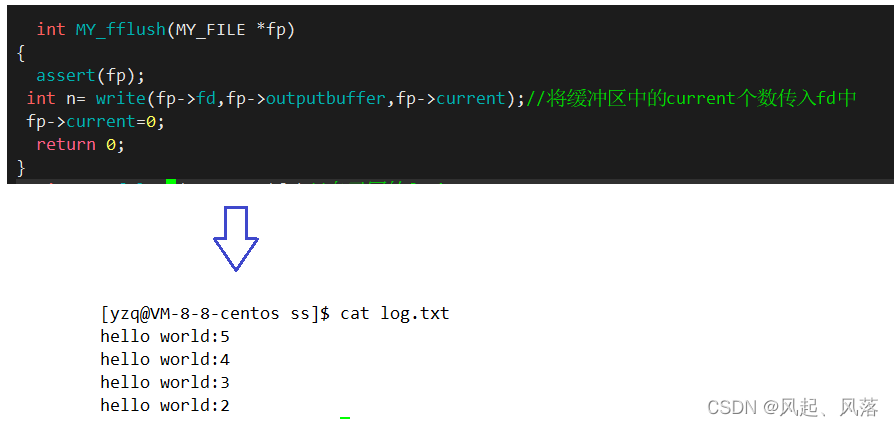
将current置为0后,下次写入就可以覆盖上次缓冲区内容
#include"mystdio.h"
#include<string.h>
#include<unistd.h>
#define MYFILE "log.txt"
int main()
{
MY_FILE*fp=MY_fopen(MYFILE,"w");
if(fp==NULL) return 1;
const char*str="hello world";
int cnt=5;
//操作文件
while(1)
{
char buffer[1024];
snprintf(buffer,sizeof(buffer),"%s:%d\n",str,cnt--);
size_t size=MY_fwrite(buffer,strlen(buffer),1,fp);
sleep(1);
printf("当前成功写入:%lu个字节\n",size);
}
MY_fclose(fp);
return 0;
}
#include<stdio.h>
#define NUM 1024
#define BUFF_NONE 0x1 //表示无缓冲
#define BUFF_LINE 0x2 //行缓冲
#define BUFF_ALL 0x4 //全缓冲
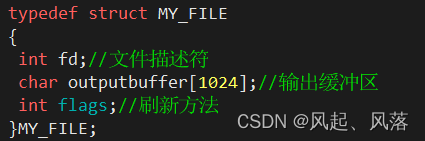
typedef struct MY_FILE
{
int fd;//文件描述符
int flags;//刷新方法
char outputbuffer[1024];//输出缓冲区
int current;
}MY_FILE;
MY_FILE *MY_fopen(const char *path, const char *mode);//自己写fopen
size_t MY_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream);//自己写的fwrite
int MY_fclose(MY_FILE *fp);//自己写的fwrite
int MY_fflush (MY_FILE*fp);//自己实现的缓冲区
#include"mystdio.h"
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<stdlib.h>
#include<unistd.h>
#include<assert.h>
MY_FILE*MY_fopen(const char *path, const char *mode)//自己写fopen
{
int flag=0;
if(strcmp(mode,"r")==0)//说明当前使用读方式打开文件
flag |= O_RDONLY;//读取
else if(strcmp(mode,"w")==0)
flag |=(O_CREAT | O_WRONLY | O_TRUNC);//创建文件 以写的方式打开文件 清空文件
else if(strcmp(mode,"a")==0)
flag |=(O_CREAT | O_WRONLY | O_APPEND); //创建文件 以写的方式打开文件 追加
else {
//其他不考虑
}
//2. 尝试打开文件
mode_t m=0666;
int fd=0;
//flag代表模式 r w a
if(flag & O_CREAT)
fd=open(path,flag,m);
else
//说明不需要打开
fd=open(path,flag);
if(fd<0)//当前打开文件失败
return NULL;
//3.给用户返回MY_FILE对象,需要先进行构建
MY_FILE*mf=(MY_FILE*)malloc(sizeof(MY_FILE));
if(mf==NULL)//申请空间失败
{
close(fd);//关闭文件
return NULL;
}
// 4. 初始化 MY_FILE对象
mf->fd=fd;//将上述的fd传入结构体的fd中
mf->flags=0;
mf->flags=BUFF_LINE;//设置成行缓冲
memset(mf->outputbuffer,'\0',sizeof(mf->outputbuffer));//将outputbufeer中的内容全部初始化为0
mf->current=0;//代表缓冲区中没有数据
W>}
size_t MY_fwrite(const void *ptr, size_t size, size_t nmemb,MY_FILE *stream)
{
// 1. 缓冲区如果已经满了,就直接写入
if(stream->current == NUM) MY_fflush(stream);
// 2. 根据缓冲区剩余情况,进行数据拷贝即可
size_t user_size = size * nmemb;
size_t my_size = NUM - stream->current; // 100 - 10 = 90
size_t writen = 0;
if(my_size >= user_size)
{
memcpy(stream->outputbuffer+stream->current, ptr, user_size);
//3. 更新计数器字段
stream->current += user_size;
writen = user_size;
}
else
{
memcpy(stream->outputbuffer+stream->current, ptr, my_size);
//3. 更新计数器字段
stream->current += my_size;
writen = my_size;
}
// 4. 开始计划刷新, 他们高效体现在哪里 -- TODO
// 不发生刷新的本质,不进行写入,就是不进行IO,不进行调用系统调用,所以MY_fwrite函数调用会非常快,数据会暂时保存在缓冲区中
// 可以在缓冲区中积压多份数据,统一进行刷新写入,本质:就是一次IO可以IO更多的数据,提高IO效率
if(stream->flags & BUFF_ALL)
{
if(stream->current == NUM) MY_fflush(stream);
}
else if(stream->flags & BUFF_LINE)
{
if(stream->outputbuffer[stream->current-1] == '\n') MY_fflush(stream);
}
else
{
//TODO
}
return writen;
}
int MY_fflush(MY_FILE *fp)
{
assert(fp);
W> int n= write(fp->fd,fp->outputbuffer,fp->current);//将缓冲区中的current个数传入fd中
fp->current=0;
return 0;
}
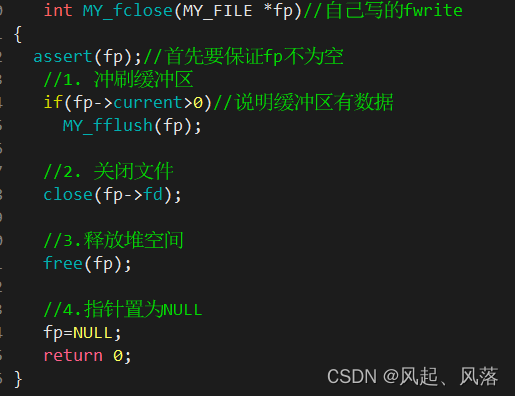
int MY_fclose(MY_FILE *fp)//自己写的fwrite
{
assert(fp);//首先要保证fp不为空
//1. 冲刷缓冲区
if(fp->current>0)//说明缓冲区有数据
MY_fflush(fp);
//2. 关闭文件
close(fp->fd);
//3.释放堆空间
free(fp);
//4.指针置为NULL
fp=NULL;
return 0;
}
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
从给定URL下载文件并立即将其上传到AmazonS3的更直接的方法是什么(+将有关文件的一些信息保存到数据库中,例如名称、大小等)?现在,我既不使用Paperclip,也不使用Carrierwave。谢谢 最佳答案 简单明了:require'open-uri'require's3'amazon=S3::Service.new(access_key_id:'KEY',secret_access_key:'KEY')bucket=amazon.buckets.find('image_storage')url='http://www.ex
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A