目录
写在前面
本小节内容主要针对异步FIFO进行设计验证,设计结构较为简单。作为SV学习阶段的大练习,其主要目的更多的是对SV基础语法的巩固,以及对验证功能点提取,覆盖率收集的学习。一些提供的代码和分析可能有误,也请阅读该文的小伙伴积极提出问题,一起进步。
RTL代码获取:
TB代码获取:
FIFO在硬件上是一种地址依次自增的Simple Dual Port RAM,按读数据和写数据工作的时钟域是否相同分为同步FIFO和异步FIFO,其中同步FIFO是指读时钟和写时钟为同步时钟,常用于数据缓存和数据位宽转换;异步FIFO通常情况下是指读时钟和写时钟频率有差异,即由两个异步时钟驱动的FIFO,由于读写操作是独立的,故常用于多比特数据跨时钟域处理。
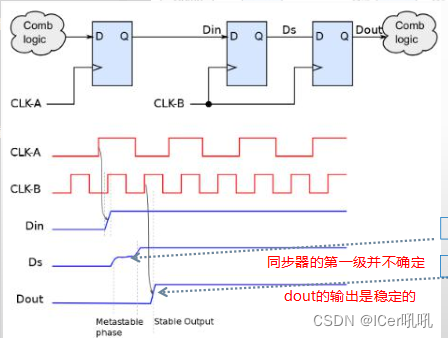
异步fifo用于在不同的时钟域(clock domain)之间安全地传输数据。而同步FIFO主要是解决数据传输速率匹配问题;因此,异步fifo需要进行同步(synchronize)处理;一般来讲,我们可以采用同步器(由2FF组成)对单bit的信号进行同步操作。注意,这里的打拍是针对单bit信号而已的。
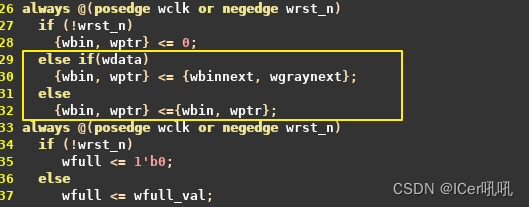
但是,二进制数的自增一位变化位数不仅仅是一位,所以在同步的过程中我们使用的格雷码或者独热码,由于独热码占位较多,所以格雷码被广泛应用。在使用格雷码的同时,还需要注意fifo的深度必须是2^n,具体原因后边将展开解释。
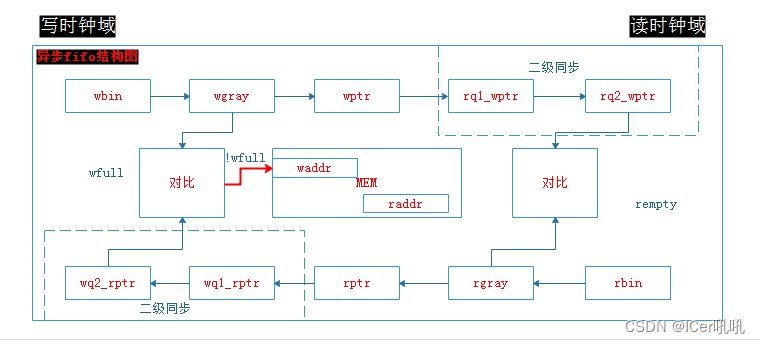
由结构图可知,异步FIFO主要划分两个时钟域
写时钟域:
always@(posedge wclk); if(wclken && !wfull) mem[waddr]<=wdata;,表示只要MEM非满且写使能有效,即可往MEM写数据;而wfull_val =(wgraynext=={~wq2_rptr[ADDRSIZE:ADDRSIZE-1],wq2_rptr[ADDRSIZE-2:0]}); 表示读写指针之间的位移等于FIFO的最大深度,至于gray码高2bit相反原因下面详解。
读时钟域:
assign rdata<=mem[raddr];,表示只要MEM 有数据,即可往MEM读数据(此处加上rempty的判断会更好);而rempty_val = (rgraynext==rq2_wptr); 表示读指针追上写指针,即MEM内没有数据。
FIFO的宽度(datasize):即FIFO一次读写操作的数据位;
FIFO的深度(depth):指的是FIFO可以存储多少个N位的数据(如果宽度为N)。
满标志(wfull):FIFO已满或将要满时由FIFO的状态电路送出的一个信号,以阻止FIFO的写操作继续向FIFO中写数据而造成溢出(overflow)。
空标志(rempty):FIFO已空或将要空时由FIFO的状态电路送出的一个信号,以阻止FIFO的读操作继续从FIFO中读出数据而造成无效数据的读出(underflow)。
读时钟(rclk):读操作所遵循的时钟,在每个时钟沿来临时读数据。
写时钟(wclk):写操作所遵循的时钟,在每个时钟沿来临时写数据。读使能(rcin):读操作有效,允许从fifo mem中读取数据。
写使能(wcin):写操作有效,允许向fifo mem中写入数据。读指针(rptr):每读出一个数据。读指针加1,始终指向当前要读出的数据的位置。
写指针(wptr):每写入一个数据。写指针加1,始终指向下一次将要写入的数据的位置。
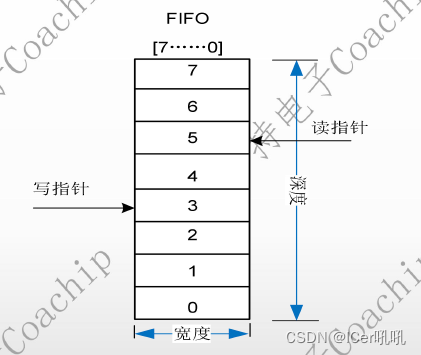
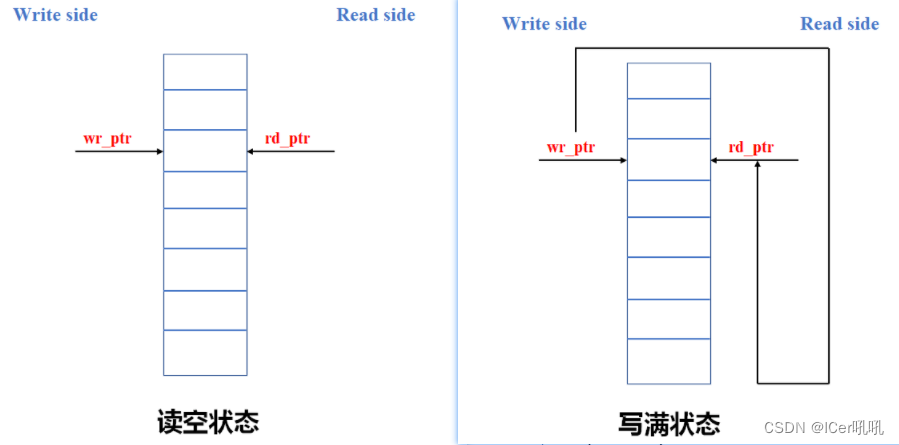
读空状态可以理解为读地址指针追上写地址指针
实现代码:rempty_val = (rgraynext==rq2_wptr);
写满状态可以理解为写地址指针再次追上读地址指针
实现代码:wfull_val =(wgraynext=={~wq2_rptr[ADDRSIZE:ADDRSIZE-1],wq2_rptr[ADDRSIZE-2:0]});
满标志判断,gray码高2bit相反分析:
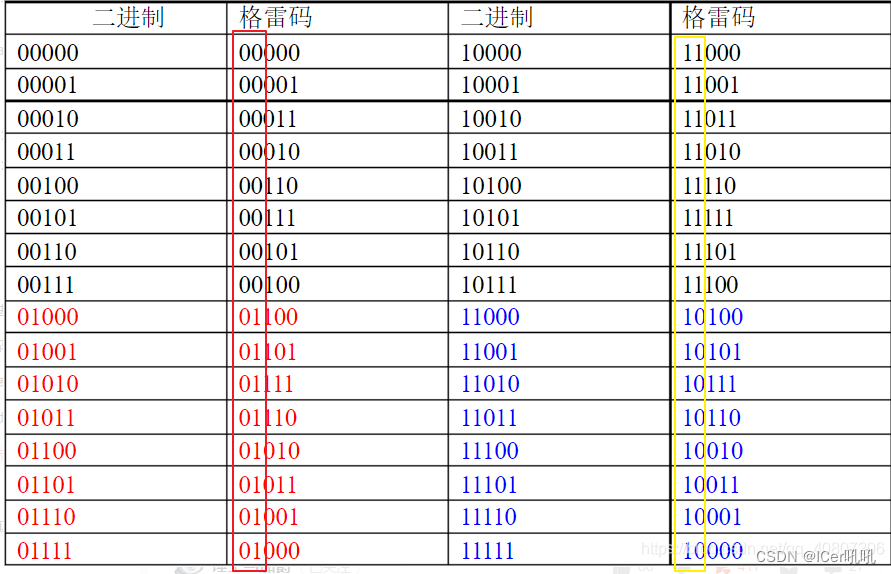
细心的小伙伴应该可以发现,上面在提到写满时,说的是写指针再次追上读指针,也就是说,写满时,写指针比读指针多走一圈,为了便于区分,将地址位宽从4 bit拓宽到5 bit,因此此时的写指针地址可以认为是11010
11010的格雷码是10111, 01010的格雷码是01111,对比两个格雷码是不是可以发现,此时高两位相反,低两位相同,这便是格雷码下写满的判断条件;
空/满标志处理细节:
▷ 把读、写指针都额外增加1bit,假如FIFO的深度为8,理论上指针位只需要[2:0]。为了能够正确甄别空、满,需要将指针都扩展到[3:0]。
▷ 其中额外引入的最高位[3],用于辅助甄别是否已经发生了回环(wrap around)的情形。当指针计满FIFO的深度,折回头重新开始时,最高位MSB加1,其它位清0。
▷ 如果读写指针的最高位不同,就意味着写指针速度快,并已经多完成一次回环。
▷ 如果两个指针的最高位相同,就意味着双方完成了相同次数的回环。

两种计数方法对比:
普通二进制计数
数据同步问题:> 1 bit,从一个clock domain到另一个clock domain,由于亚稳态现象的出现,会导致数据出错;
极端情形:所有的数据位都变化;格雷码计数
每次当从一个值变化到
相邻的一个值时,有且仅有一位发生变化;
- 由于格雷码的这种特性,我们就可以通过简单的synchronizer对指针(多位宽)进行同步操作了,而不用担心由于发生亚稳态而出现数据错误的情形(前边有解释);
- 对于2的整数次幂的FIFO,采用格雷码计数器; 接近2的整数次幂的FIFO, 采用接近2的幂次方格雷码修改实现;如果这两种都满足不了,就设计一种查找表的形式实现。所以,一般采用2的幂次方格雷码实现FIFO,会浪费一些地址空间,但可以简化控制电路;
需要注意:格雷码计数器适用于地址范围空间为2的整数次幂的FIFO,例如8, 16, 32, 64…
二进制码转格雷码只需将二进制码字整体右移一位,最高位补0,再与原先的码字按位做异或操作(如下图)
实现代码:rgraynext = (rbinnext>>1)^rbinnext;
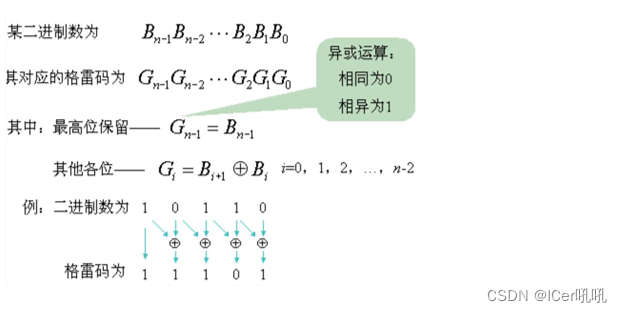
格雷码转二进制码,将格雷码的最高位作为二进制的最高位,将格雷码次高位与二进制码最高位异或运算,得到二进制码次高位,以此类推(如图)。

module fifo1 #(parameter DSIZE = 8, parameter ASIZE = 4)
(input [DSIZE-1:0] wdata,
input winc,wclk,wrst_n,
input rinc,rclk,rrst_n,
output[DSIZE-1:0] rdata,
output wfull,
output rempty
);
wire [ASIZE-1:0] waddr,raddr;
wire [ASIZE:0] wptr,rptr,wq2_rptr,rq2_wptr;
sync_r2w sync_r2w (.rptr(rptr),
.wclk(wclk),
.wrst_n(wrst_n),
.wq2_rptr(wq2_rptr)
);
sync_w2r sync_w2r (.wptr(wptr),
.rclk(rclk),
.rrst_n(rrst_n),
.rq2_wptr(rq2_wptr)
);
rptr_empty #(ASIZE) rptr_empty(.rclk(rclk),
.rrst_n(rrst_n),
.rinc(rinc),
.rq2_wptr(rq2_wptr),
.raddr(raddr),
.rempty(rempty),
.rptr(rptr)
);
wptr_full #(ASIZE) wptr_full(.wq2_rptr(wq2_rptr),
.wclk(wclk),
.wrst_n(wrst_n),
.winc(winc),
.wfull(wfull),
.waddr(waddr),
.wptr(wptr)
);
fifomem #(DSIZE,ASIZE) fifomem (.wdata(wdata),
.waddr(waddr),
.raddr(raddr),
.wclken(winc),
.wfull(wfull),
.wclk(wclk),
.rdata(rdata)
);
endmodule
module fifomem #(parameter DATASIZE = 8,parameter ADDRSIZE = 4) //mem data word width,number od mem address bits
(input [DATASIZE-1:0] wdata,
input [ADDRSIZE-1:0] waddr,raddr,
input wclken, wfull, wclk,
output[DATASIZE-1:0] rdata);
`ifdef VENDORRAM
//instantiation of a vendor's dual-port RAM
vendor_ram mem(.dout(rdata),
.din(wdata),
.waddr(waddr),
.raddr(raddr),
.wclken(wclken),
.wclken_n(wfull),
.clk(wclk)
);
`else
//RTL verilog mem model
localparam DEPTH = 1<<ADDRSIZE;
reg [DATASIZE-1:0] mem [0:DEPTH-1];
assign rdata<=mem[raddr];
always@(posedge wclk);
if(wclken && !wfull)
mem[waddr]<=wdata;
`endif
endmodule
module rptr_empty #(parameter ADDRSIZR = 4)
(input rclk,rrst_n,rinc,
input [ADDRSIZR-1:0] rq2_wptr,
output[ADDRSIZR-1:0] raddr,
output reg rempty,
output reg [ADDRSIZR:0] rptr
);
reg [ADDRSIZR:0] rbin;
wire[ADDRSIZR:0] rgraynext, rbinnext;
wire rempty_val;
//mem read-address pointer
assign raddr = rbin[ADDRSIZR-1:0];
assign rbinnext = rbin + (rinc & ~rempty);
assign rgraynext = (rbinnext>>1)^rbinnext;
//--------------------------------------------------------
//fifo empty when the next rptr == synchronized wptr or on reset
//--------------------------------------------------------
assign rempty_val = (rgraynext==rq2_wptr);
//-----------------------
//GRAYSTYLE2 pointer
//-----------------------
always@(posedge rclk or negedge rrst_n)
if(!rrst_n)
{rbin,rptr} <= 0;
else
{rbin,rptr} <= {rbinnext,rgraynext};
always@(posedge rclk or negedge rrst_n)
if(!rrst_n)
rempty<=1'b1;
else
rempty<=rempty_val;
endmodule
module wptr_full #(parameter ADDRSIZE = 4)
(input [ADDRSIZE:0] wq2_rptr,
input wclk,wrst_n,winc,
output reg wfull,
output [ADDRSIZE-1:0] waddr,
output reg [ADDRSIZE:0] wptr
);
reg [ADDRSIZE:0] wbin;
reg [ADDRSIZE:0] wbinnext,wgraynext;
wire wfull_val;
//mem write-address pointer
assign waddr = wbin[ADDRSIZE-1:0];
assign wbinnext = wbin + (winc & ~wfull);
assign wgraynext = (wbinnext>>1) ^ wbinnext;
//--------------------------------------------
assign wfull_val =(wgraynext=={~wq2_rptr[ADDRSIZE:ADDRSIZE-1],wq2_rptr[ADDRSIZE-2:0]});
//GRAYSTYLE2 pointer
always@(posedge rclk or negedge wrst_n)
if(!wrst_n)
{wbin,wptr} <= 0;
else
{wbin,wptr} <= {wbinnext,wgraynext};
always@(posedge rclk or negedge wrst_n)
if(!wrst_n)
wfull<= 1'b0;
else
wfull<= wfull_val;
endmodule
module sync_r2w #(parameter ADDRSIZE = 4)
(input [ADDRSIZE:0] rptr,
input wclk,wrst_n,
output reg [ADDRSIZE:0] wq2_rptr
);
reg [ADDRSIZE:0] wq1_rptr;
always@(posedge wclk or negedge wrst_n)
if(!wrst_n)
{wq2_rptr,wq1_rptr} <= 0;
else
{wq2_rptr,wq1_rptr} <= {wq1_rptr,rptr};
endmodule
module sycn_w2r #(parameter ADDRSIZE = 4)
(input [ADDRSIZE:0] wptr,
input rclk, rrst_n,
output[ADDRSIZE:0] rq2_wptr
);
reg [ADDRSIZE:0] rq1_wptr;
always@(posedge rclk or negedge rrst_n)
if(!rrst_n)
{rq2_wptr,rq1_wptr} <= 0;
else
{rq2_wptr,rq1_wptr} <= {rq1_wptr,wptr};
endmodulebug1:wdata没有数据写入时,只要写指针循环一圈后,wfull就会拉高,此时实际上没有数据写入,fifo实际为空;
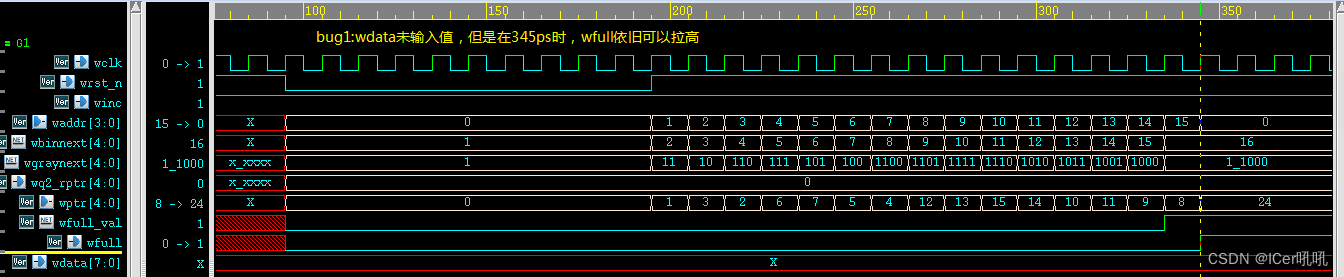
原因分析:主要是在waddr 和wptr 设置为自增形式,没有考虑wdata的因素,所以将wdata加入作为判断即可
代码定位:
此处添加了对wdata的判断,只有wdata有数据是,写指针以及写地址才会加1.
dubug后代码:

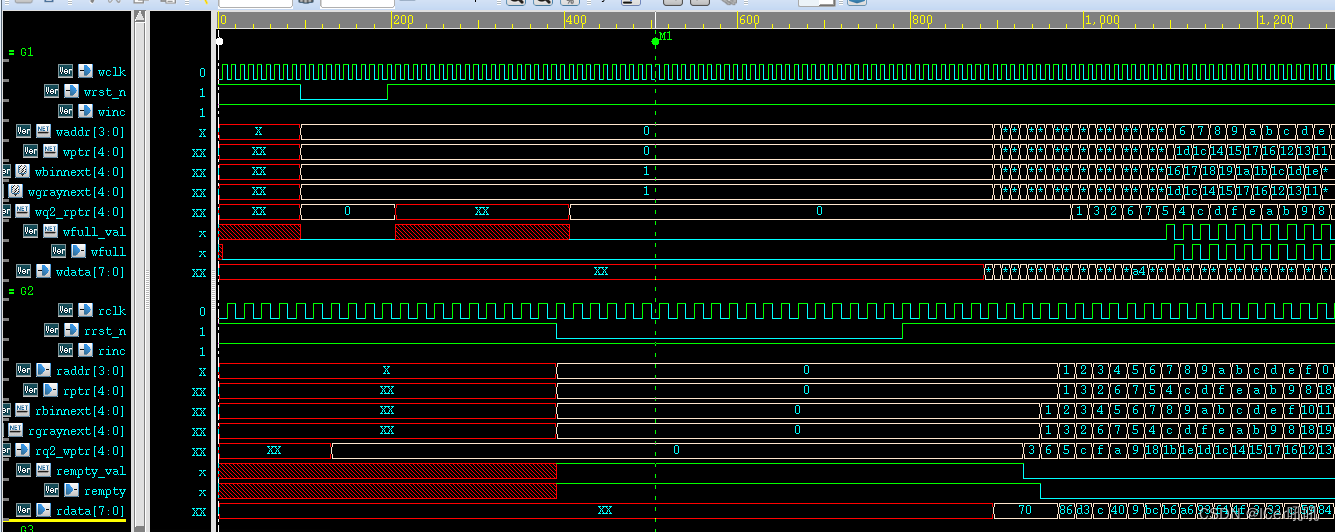
bug2: 在winc拉高的前提下,当wrst_n和rrst_n在拉低过程中没有交集时,在后边即使二者都拉高,且wdata有值,fifo依然不会读入数据,显示为不定态;
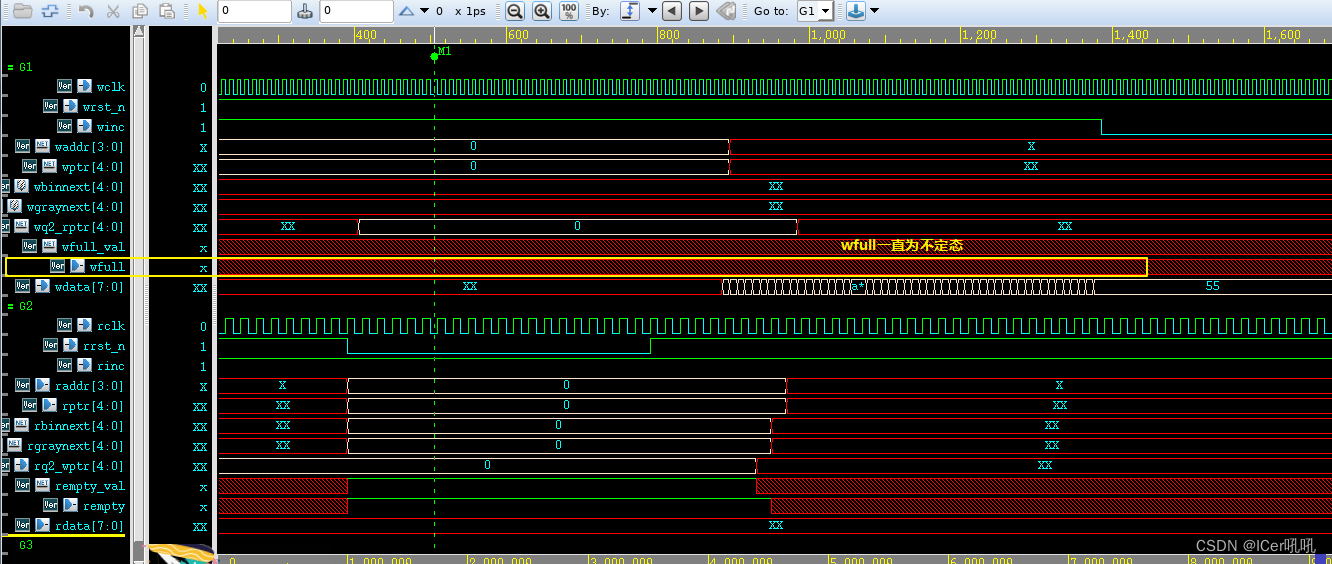
原因分析:从代码的分析中不难发现,当wrst_n拉高后,wfull取决于wgraynext的状态,换句话说,如果wgraynext为不定态,那wfull就是不定态;而wgraynext又取决于wfull的状态,这样就形成了一个闭环,所以需要有一个值提前初始化,打破这种闭环。
代码定位:
加入了对wdata的判断,如果有wdata写入,就认为fifo非空,接下来判断是否为空。
(前些日子突然有小伙伴问我这个问题,后来仔细研究一番发现有一种更简单的修改方法,将wfull_val赋值变量语句中的“=="改为”===“,问题就解决了。
wfull_val =(wgraynext=={~wq2_rptr[ADDRSIZE:ADDRSIZE-1],wq2_rptr[ADDRSIZE-2:0]})
wfull_val =(wgraynext==={~wq2_rptr[ADDRSIZE:ADDRSIZE-1],wq2_rptr[ADDRSIZE-2:0]})
期待大家向我提问哦!
debug后代码:
由于篇幅受限,验证代码详解请点此链接
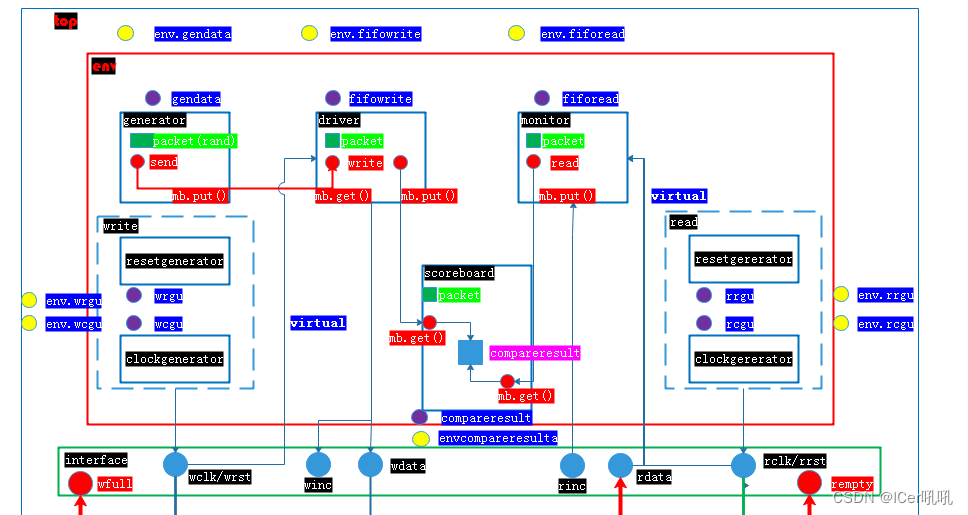
功能类:
- 一、时钟测试点提取:
- read/write相同时钟和不同时钟同时读写;
- Read时钟快,write时钟慢,同时读写;
- Read时钟慢,write时钟快,同时读写;
- 大比例时钟时正常工作:1)write时钟频率是read的4倍,同时读写;2).write时钟频率是read的1/4倍,同时读写.
- 二、复位测试点提取:
- read端口reset测试;
- Write端口reset测试;
- 先reset read端口,在reset write端口;
- 先reset write端口,在reset read端口;
- 同时将read和write 进行reset。
- 三、其他功能测试点提取:
- 基本的写功能验证;
- 基本的读功能验证;
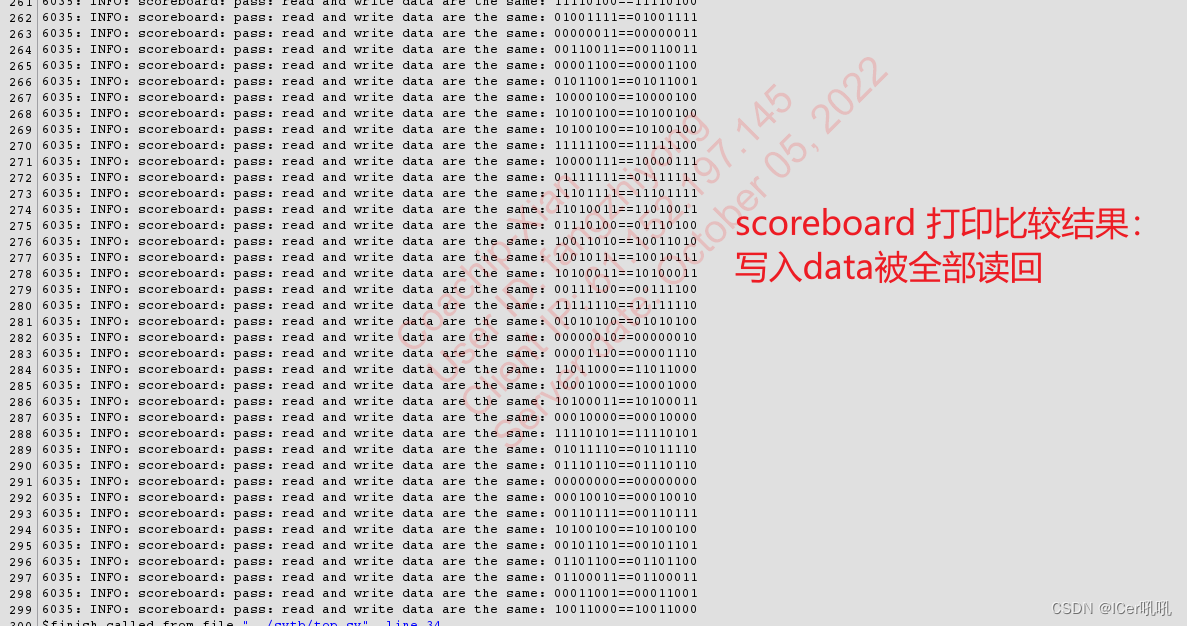
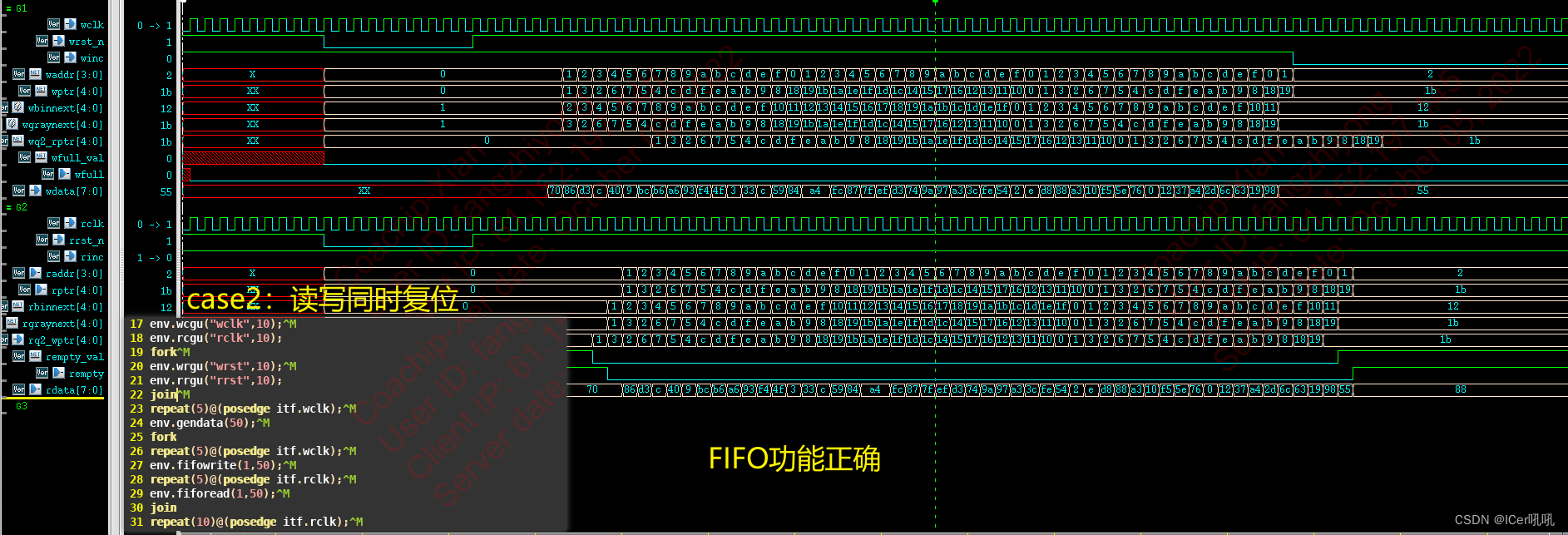
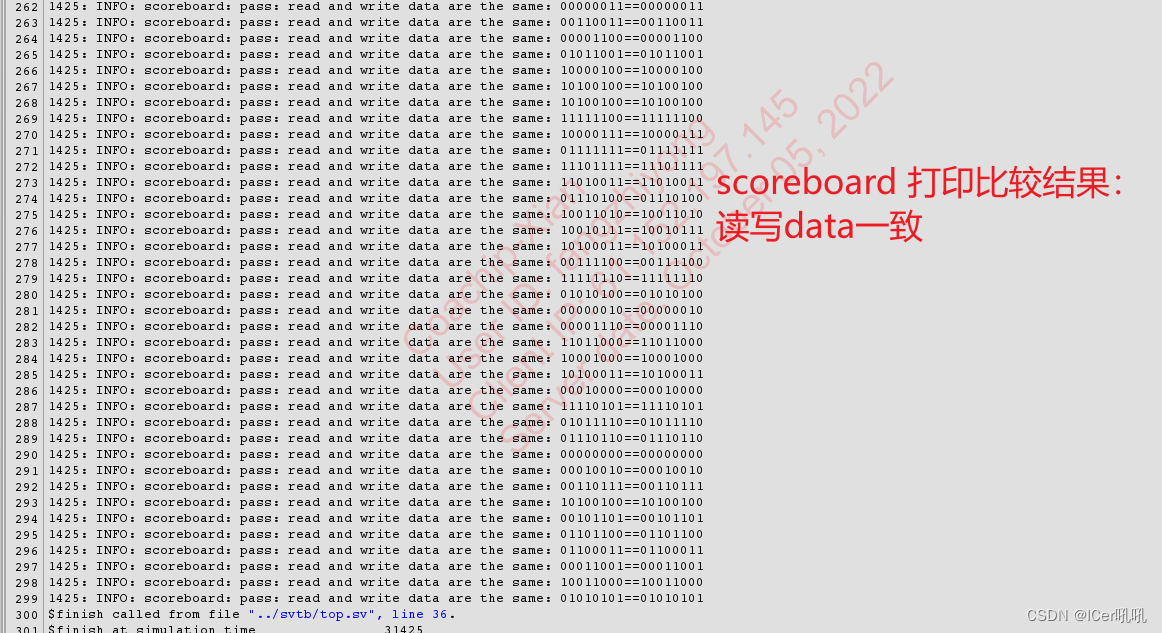
- 读写功能同时进行的验证;
接口类:
- 一、Clk验证点提取:
验证不同频率下功能点是否正确;
- 二、Reset验证点提取:
验证不同时刻reset,功能是否正确;
- 三、寄存器接口验证:
验证寄存器访问是否正确;
- 四、串行接口:
验证发送接收是否符合预期;
- 五、中断接口:
验证产生中断触发条件,中断输出以及中断清除是否符合预期;
场景类:
- 一、验证收发功能:
验证是否可以正常接收发送数据,是否符合通信协议;
异常类:
- 空状态下读;
- 满状态下写。
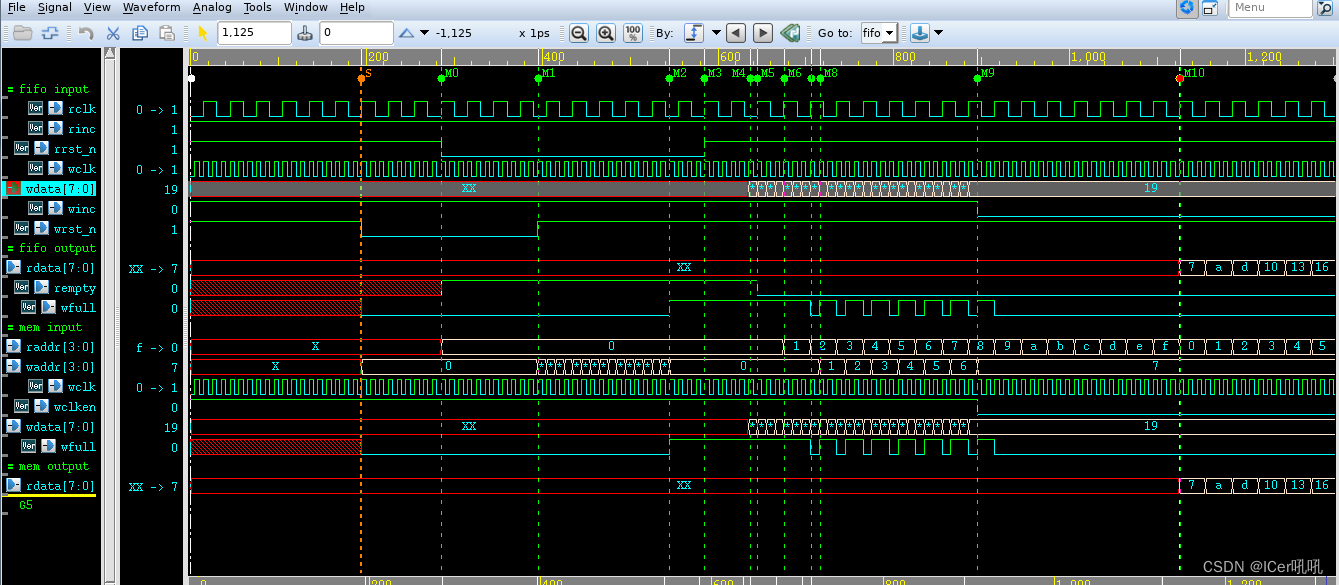
S: if(!wrst_n) {wbin,wptr} <= 0; if(!wrst_n) wfull<= 1'b0;
M0: if(!rrst_n) {rbin,rptr} <= 0; if(!rrst_n) rempty<=1'b1;
M1: wrst_n拉高,{wbin,wptr} <= {wbinnext,wgraynext}; wfull<= wfull_val;注意waddr=wbin,
wbinnext= wbin + (winc & ~wfull);此时,winc为高,wfull非空,所以接下来随着wclk的增加,waddr也会自加,直到wfull拉高为止,即M1-M2阶段;此时虽然为满,但内部没有数据;
M2:随着waddr的增加,当满足wfull<= wfull_val(full_val =(wgraynext=={~wq2_rptr[ADDRSIZE:
ADDRSIZE-1],wq2_rptr[ADDRSIZE-2:0]})时,wfull拉高;
M3:rrst_n拉高,由TB文件激励发送协议,repeat(5)@(posedge itf.wclk); nv.fifowrite(26);等待5个wclk时钟周期,开始发送激励,即M4;
M4:开始发送激励;
M5: rrst_n拉高后两个rclk时钟周期,{rq2_wptr,rq1_wptr} <= {rq1_wptr,wptr}; rq2_wptr= wptr,wptr为格雷码11000;此时rempty<=rempty_val (rempty_val = (rgraynext==rq2_wptr))结果为0;rempty拉低;
M6:写入数据后,随着rclk的增加,raddr开始自加,所以在M6 site raddr指针指向1,但是此时mem内部并没有数据,所以没有读回data;
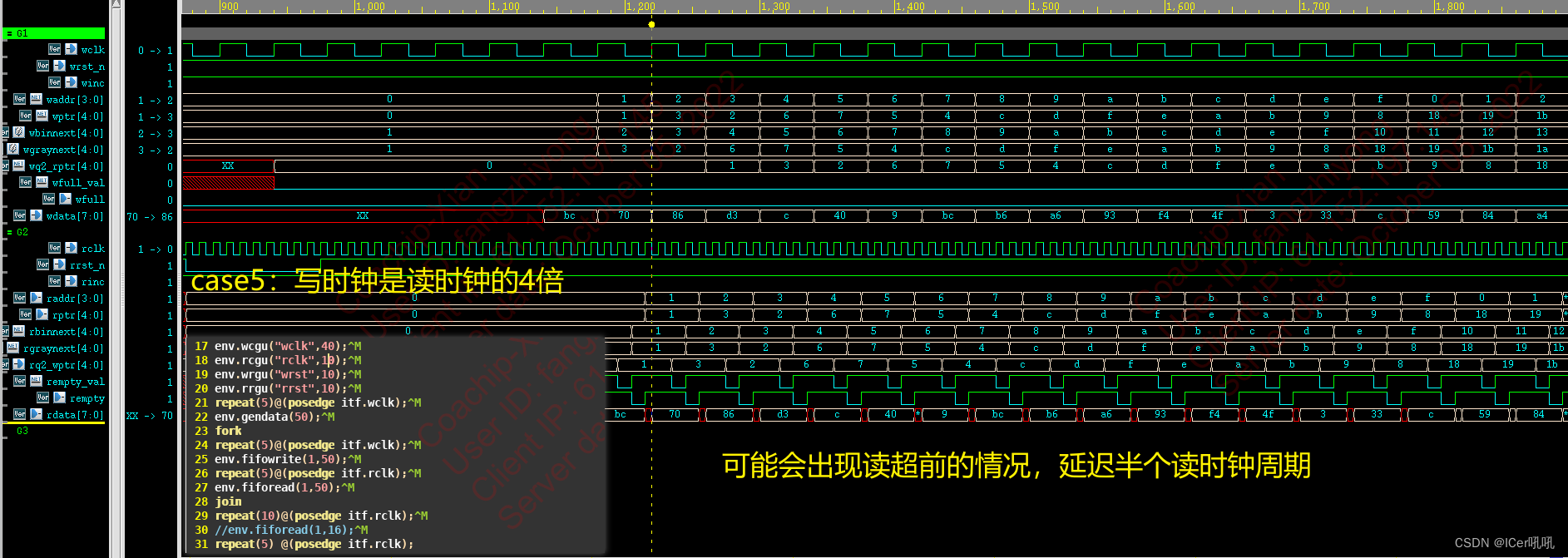
M7: rrst_n拉高两个rclk时钟周期后,理论上写入一个数据会被读走一个数据,但是由于wclk的频率是rclk的三倍,所以每次只能是前边的一个数据被写入mem中,但是由于此时写入addr是1,而此时raddr指针指向2,所以读不出数据,将一直保持读指针和写指针差一个地址单位,所以只有读指针循环一圈才可以读出数据,这也是M10读回data的原因;
M8:wfull拉低的时间为一个wclk周期;
M9:当所有的data写完,winc拉低,此时实际上mem中只有部分数据写入,其余数据丢失。
M10:等待raddr循环一个fifo深度,开始读回数据。
case1:读写相同时钟频率同时读写
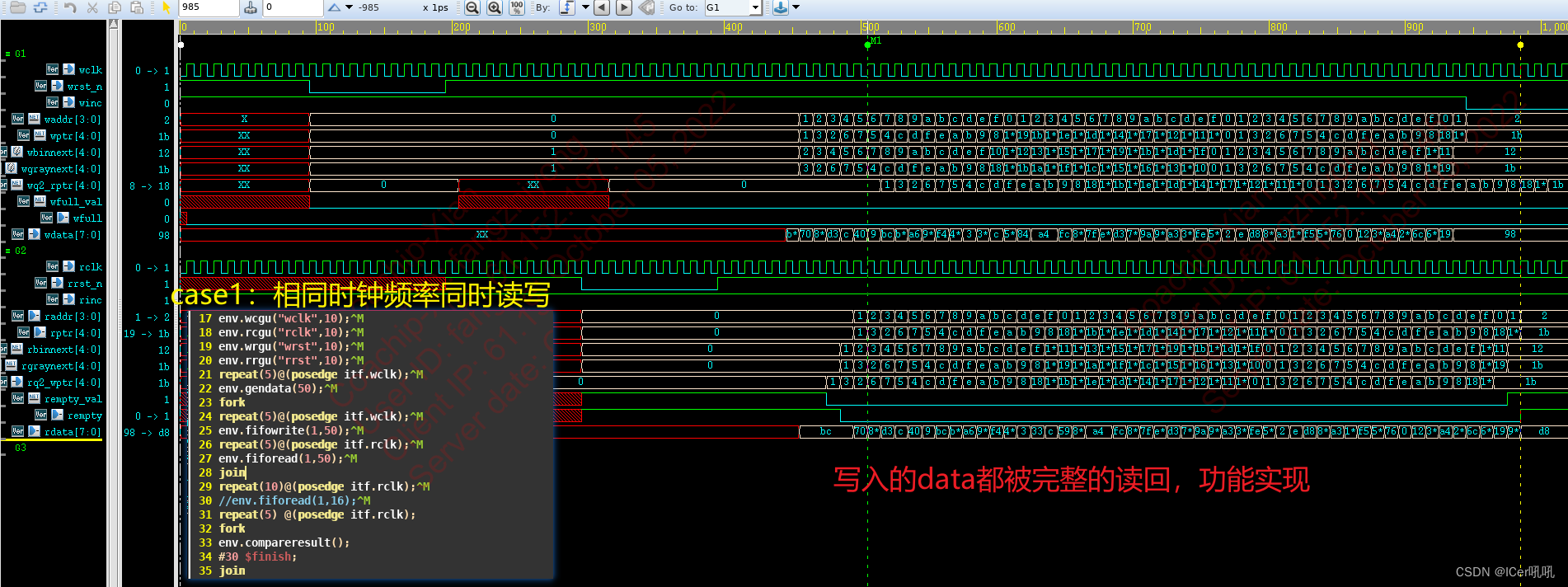

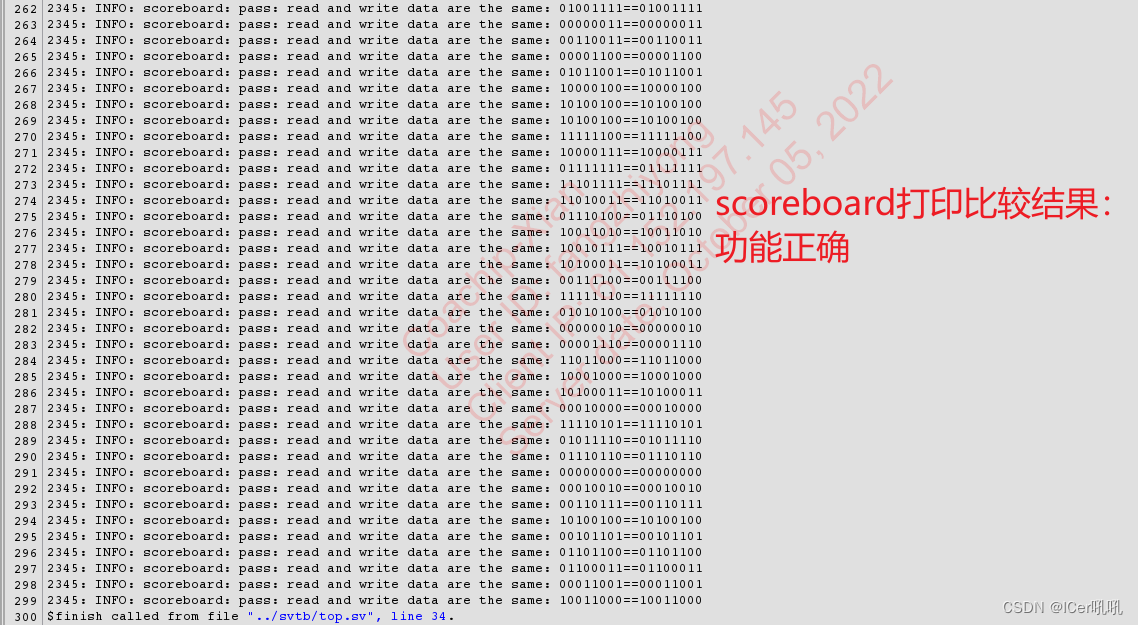
case2:读时钟快,写时钟慢,同时读写

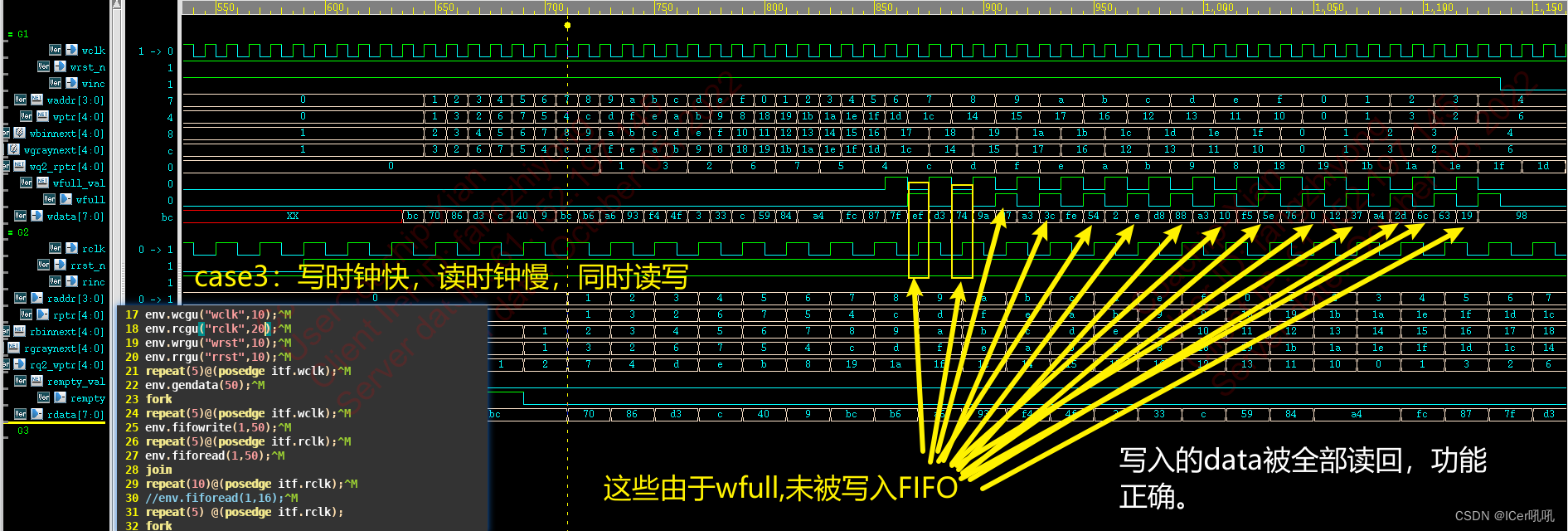
case3:读时钟慢,写时钟快,同时读写
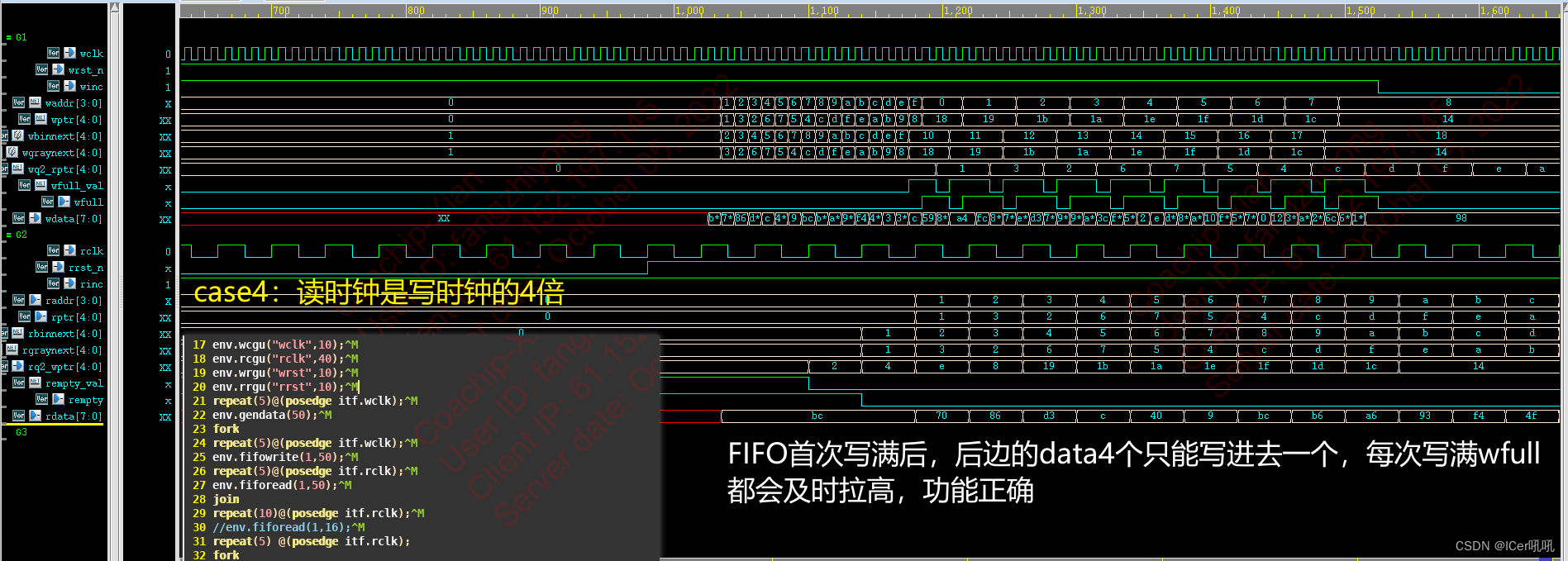
case4: 大比例时钟验证 write时钟频率是read的4倍,同时读写
case5: 大比例时钟验证 write时钟频率是read的1/4倍,同时读写
 2 复位功能点验证
2 复位功能点验证case1:先读复位再写复位

case2:读写同时复位
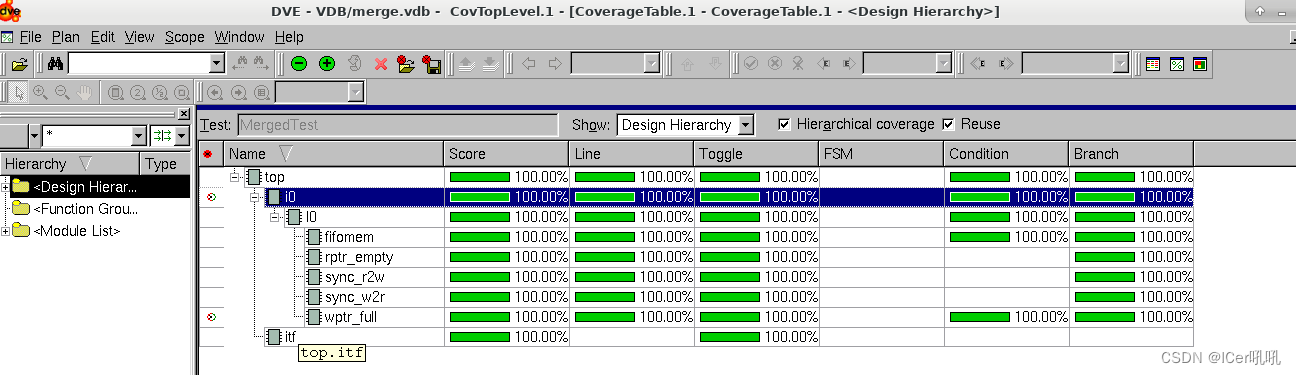
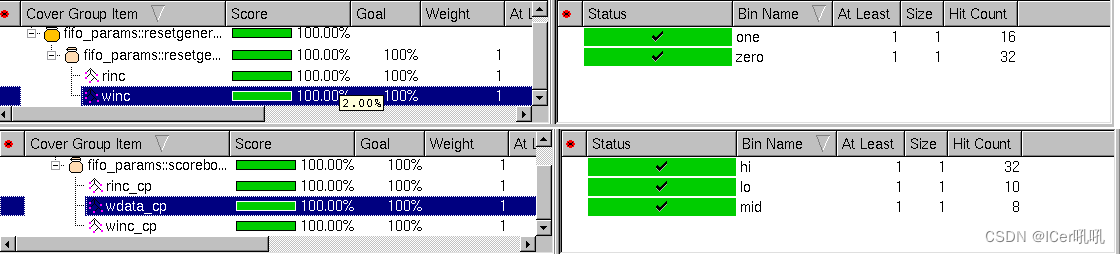
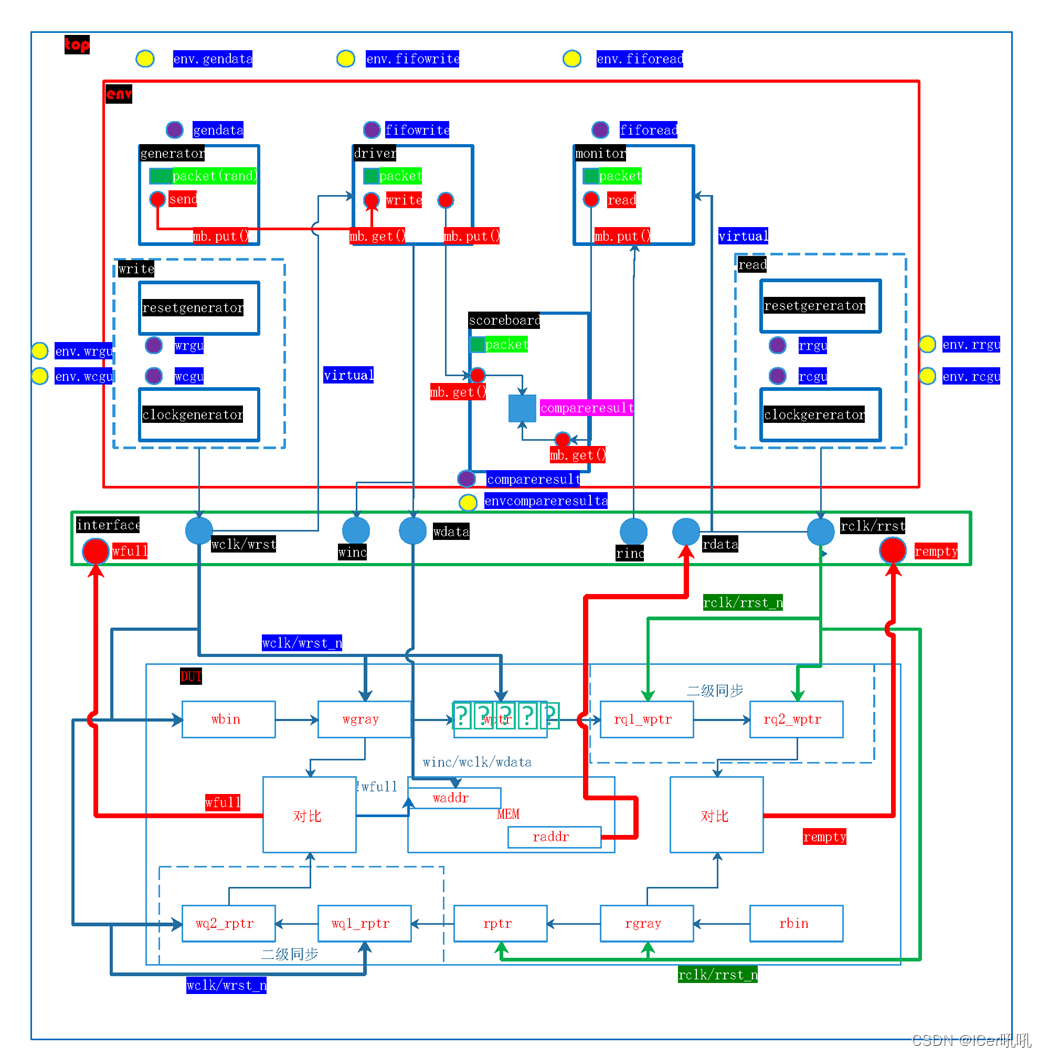
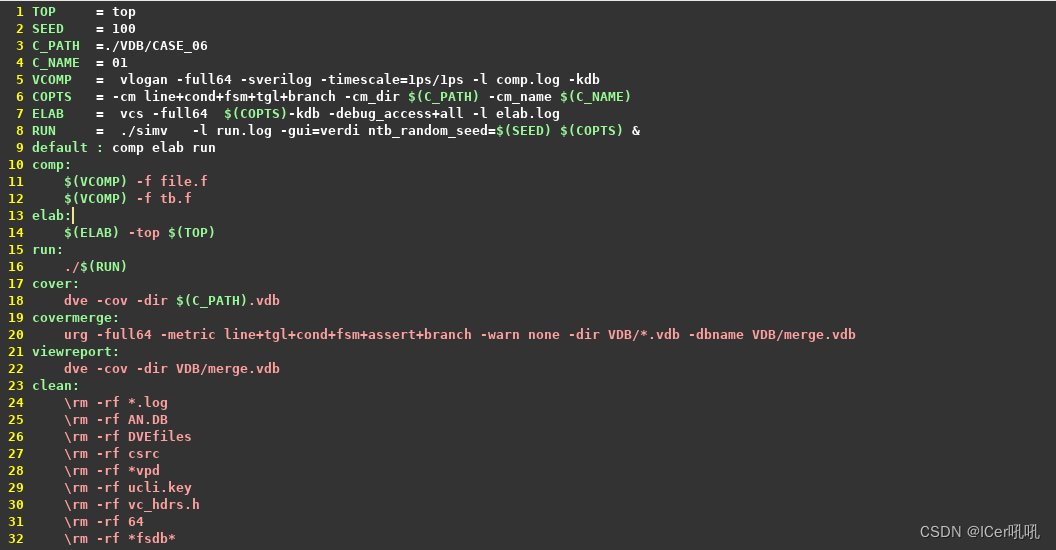
RTL代码详解:点此链接
TB代码详解:点此链接
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
我们开始使用Ruby开发新游戏项目。我们决定使用其中一种异步Ruby服务器,但我们无法决定选择哪一种。选项是:歌利亚抽筋+消瘦/彩虹rack-fiber_pool+rack+thin/rainbowseventmachine_httpserver它们似乎都在处理HTTP请求。Cramp还支持开箱即用的Websocket和服务器端事件。您知道这些服务器的优缺点吗? 最佳答案 我使用eventmachine_httpserver公开了一个RESTfulAPIinanEventMachine-basedIRCbot绝对不会推荐它用于任何严
我一直在研究ruby的并行/异步处理能力,并阅读了许多文章和博客文章。我查看了EventMachine、Fibers、Revactor、Reia等。不幸的是,我无法为这个非常简单的用例找到简单、有效(且非IO阻塞)的解决方案:File.open('somelogfile.txt')do|file|whileline=file.gets#(R)ReadfromIOline=process_line(line)#(P)Processthelinewrite_to_db(line)#(W)WritetheoutputtosomeIO(DBorfile)endend你看到了吗,我的小脚本正
我使用RubyEventMachines已经有一段时间了,我想我已经了解它的基础知识了。但是,我不确定如何高效地读取大文件(120MB)。我的目标是逐行读取文件并将每一行写入Cassandra数据库(对于MySQL、PostgreSQL、MongoDB等也应该如此,因为Cassandra客户端明确支持EM)。这个简单的片段会阻塞react器,对吗?require'rubygems'require'cassandra'require'thrift_client/event_machine'EM.rundoFiber.newdorm=Cassandra.new('RankMetrics',
一、RIPV2协议简介 RIP(RoutingInformationProtocol)路由协议是一种相对古老,在小型以及同介质网络中得到了广泛应用的一种路由协议。RIP采用距离向量算法,是一种距离向量协议。RIP-1是有类别路由协议(ClassfulRoutingProtocol),它只支持以广播方式发布协议报文。RIP-1的协议报文无法携带掩码信息,它只能识别A、B、C类这样的自然网段的路由,因此RIP-1不支持非连续子网(DiscontiguousSubnet)。RIP-2是一种无类别路由协议(ClasslessRoutingProtocol),支持路由标记,在路由策略中可根据路由标记对
目录1.1访问Cisco路由器的方法1.1.1通过Console口访问路由器1.1.2通过Telnet访问路由器1.1.3终端访问服务器1.2终端访问服务器配置命令汇总1.1访问Cisco路由器的方法 路由器没有键盘和鼠标,要初始化路由器需要把计算机的串口和路由器的Console口进行连接。访问Cisco路由器的方法还有Telnet、WebBrowser和网络管理软件(如CiscoWorks)等,本节讨论前2种。1.1.1通过Console口访问路由器 计算机的串口和路由器的Console口是通过反转线(Rollover)进行连接的,反转线的一端接在路由器的Console口上,另一
目录FIFO一.自定义同步FIFO1.1代码设计1.2Testbech1.3行为仿真***学习位宽计算函数$clog2()***$clog2()系统函数使用,可以不关注***分布式资源或者BLOCKBRAM二.异步FIFO2.1在FIFO判满的时候有两种方式:2.2异步FIFO为什么要使用格雷码2.2.1介绍格雷码2.2.2格雷码在异步FIFO中的应用2.2.2格雷码判满2.4二进制与格雷码之间的转换2.4.1二进制码转换为格雷码的方法2.4.2格雷码转换为二进制码的方法2.3实现框图2.5实现及仿真代码2.6仿真图验证2.7结论FIFO 这篇更多的是记录FIFO学习,参考了众多优秀的文章,
我在网络上阅读了大量关于不同版本的ruby和rails的线程安全和性能的资料,我想我现在已经很好地理解了这些内容。讨论中似乎奇怪地遗漏了如何实际部署异步Rails应用程序。当谈到应用程序中的线程和同步性时,人们希望优化两件事:以最少的RAM使用率利用所有CPU内核能够在之前的请求等待IO时处理新请求第1点是人们(正确地)对JRuby感到兴奋的地方。对于这个问题,我只是想优化第2点。假设这是我应用中唯一的Controller:classTheController"hello"enddefslowrender:text=>User.count.to_sendendfast没有IO,每秒
文章目录一、用户二、用户分类1、普通用户2、超级用户3、系统用户三、用户相关文件1、/etc/passwd文件2、/etc/shadow文件四、用户管理命令1、useradd2、adduser3、passwd4、usermod5、userdel一、用户Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户都必须先向系统管理员申请一个账号,然后以这个账号的身份进入系统。在Linux系统中,任何文件都属于某一特定用户,而任何用户都隶属于至少一个用户组。用户名(username):每个用户账号都拥有一个惟一的用户名和各自的口令。用户在登录时键入正确的用户名和口令后,就能够进入系