给定一个字符串 s,计算 s 的 不同非空子序列 的个数。因为结果可能很大,所以返回答案需要对 10^9 + 7 取余 。
字符串的 子序列 是经由原字符串删除一些(也可能不删除)字符但不改变剩余字符相对位置的一个新字符串。
"ace" 是 "abcde" 的一个子序列,但 "aec" 不是。示例 1:
输入:s = "abc"
输出:7
解释:7 个不同的子序列分别是 "a", "b", "c", "ab", "ac", "bc", 以及 "abc"。示例 2:
输入:s = "aba"
输出:6
解释:6 个不同的子序列分别是 "a", "b", "ab", "ba", "aa" 以及 "aba"。示例 3:
输入:s = "aaa"
输出:3
解释:3 个不同的子序列分别是 "a", "aa" 以及 "aaa"。提示:
1 <= s.length <= 2000s 仅由小写英文字母组成这个方法是一个acmer和我一起慢慢分析得出,大致过程就是动态规划。
设状态dp[i]: 以位置i结尾的子序列个数.如字符串“abc”
dp[0]=1,就一个a;dp[1]=2,以字符b结尾的子序列的数目:b、ab;dp[2]=4;c,ac,bc,abc;
abc的子序列个数为dp[0]+dp[1]+dp[2]=1+2+4=7;
如字符"aba"
dp[0]=1,a;dp[2]=2,b,ab;dp[3]=3,aa,ba,aba;
aba子序列的个数为dp[0]+dp[1]+dp[2]=1+2+3=6;
从上述分析可以得出,当字符串没有重复字符时,dp[i+1]=dp[i]+dp[i-1]+....+dp[0]+1;
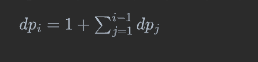
最后的子序列的个数:
但是当字符串中有重复子串的时候:
需要减去重复的值,并且更新i位置的dp[i]及之后的dp[i+1].....
如字符"aba"
dp[0]=1,a;
dp[2]=2,b,ab;
dp[3]=3=(4-1),aa,ba,aba,(a);
aba子序列的个数为dp[0]+dp[1]+dp[2]=1+2+3=6;
这我实现的不太好,使用了暴力方法进行遍历dp,更新dp,时间复杂度较高。
class Solution {
public int sum=0;
public int summ(int a[],int num)
{
int results=0;
for(int i=0;i<num;i++)
{
//System.out.println("遍历num:"+a[i]);
results=(int)((results+a[i])%(Math.pow(10,9)+7));
}
return results;
}
public int distinctSubseqII(String s) {
int results=0;
Map<Character,ArrayList<Integer>>map=new HashMap<Character,ArrayList<Integer>>();//数据结构
int leng=s.length();
int nums[] =new int[leng];
nums[0]=1;
double M=Math.pow(10,9)+7;
for(int i=0;i<s.length();i++)//获取是否重复的值
{
//ArrayList<Integer> list=new ArrayList<Integer>();
Character c=s.charAt(i);
boolean b = map.containsKey(c);
if(b)
{
//System.out.println("存在"+b);
ArrayList<Integer> value = map.get(c);
value.add(i);
}
else
{
ArrayList<Integer> value=new ArrayList<Integer>();
value.add(i);
map.put(c,value);
}
}
for(int i=1;i<s.length();i++)
{
sum=(int)((sum+nums[i-1])%(M));
nums[i]=(int)((sum+1)%(M));
}
sum=(int)((sum+nums[s.length()-1])%(M));
results=(int)sum;
int dif[]={0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
if(map.size() !=s.length() && map.size()!=1)
{
for(int x=0;x<s.length();x++)
{
int t=s.charAt(x)-'a';
if(dif[t]!=0)
{
nums[x]=(int)((nums[x]-dif[t])%(M));
if(nums[x]<0)
{
nums[x]+=(int)M;
}
int index=x;
sum=(int)((summ(nums,index+1))%(M));
while(index<(s.length()-1))//求新的dp
{
//Character key=s.charAt(index);
nums[index+1]=(int)((sum+1)%(M));
sum=(int)((sum+nums[index+1])%(M));
index++;
}
}
dif[t]=(int)((dif[t]+nums[x])%(M));
}
results=summ(nums,s.length());
}
else if(map.size() == 1)
results=s.length();
return results;
}
}
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
ValidPalindromeGivenastring,determineifitisapalindrome,consideringonlyalphanumericcharactersandignoringcases. [#125]Example:"Aman,aplan,acanal:Panama"isapalindrome."raceacar"isnotapalindrome.Haveyouconsiderthatthestringmightbeempty?Thisisagoodquestiontoaskduringaninterview.Forthepurposeofthisproblem
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.
RSpec似乎按顺序匹配方法接收的消息。我不确定如何使以下代码工作:allow(a).toreceive(:f)expect(a).toreceive(:f).with(2)a.f(1)a.f(2)a.f(3)我问的原因是a.f的一些调用是由我的代码的上层控制的,所以我不能对这些方法调用添加期望。 最佳答案 RSpecspy是测试这种情况的一种方式。要监视一个方法,用allowstub,除了方法名称之外没有任何约束,调用该方法,然后expect确切的方法调用。例如:allow(a).toreceive(:f)a.f(2)a.f(1)
假设我必须(小型到中型)阵列:tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]如何确定tokens是否以相同的顺序包含template的所有条目?(请注意,在上面的示例中,应忽略第一个“ccc”,从而由于最后一个“ccc”而导致匹配。) 最佳答案 这适用于您的示例数据。tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]po
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(
有没有办法在sinatra的beforedoblock中停止执行并返回不同的值?beforedo#codeishere#Iwouldliketo'return"Message"'#Iwouldlike"/home"tonotgetcalled.end//restofthecodeget'/home'doend 最佳答案 beforedohalt401,{'Content-Type'=>'text/plain'},'Message!'end如果你愿意,你可以只指定状态,这里有状态、标题和正文的例子
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
我从ui中得到日期范围为-approved_between"=>"2013-03-17-2013-03-18"我需要拆分此approved_start_date="2013-03-17"和approved_end_date="2013-03-18"...我希望使用它在mysql中查询,因为mysql中的日期格式是created_at:2012-07-2810:35:01.我正在做的是:approved=approved_between.split("")approved_start_date=approved[0]approved_end_date=approved[2]很确定这不是处