命名实体识别
与自动分词、词性标注一样,命名实体识别也是自然语言处理的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体。由于这些命名实体数量不断增加,通常不可能在词典中穷尽列出,且其构成方法具有各自的规律性,因此,通常把对这些词的识别在词汇形态处理(如汉语切分)任务中独立处理,称为命名实体识别( Named Entities Recognition,NER )。
NER 研究的命名实体一般分为3大类(实体类、时间类和数字类)和7小类(人名、地名、组织机构名、时间、日期、货币和百分比)。
命名实体识别当前并不是一个大热的研究课题,因为学术界部分认为这是一个已经解决了的问题,但是也有学者认为这个问题还没有得到很好地解决,原因主要有:
中文的命名实体识别与英文的相比,挑战更大,目前常遇到的问题有:
命名实体识别目前主要有三类方法:
条件随机场是在给定观察的标记序列下,计算整个标记序列的联合概率,而 HMM 则是在给定当前状态下,定义下一个状态的分布;条件随机场的具体定义为:
设X=(X 1 ,X 2 ,X 3 ,…,X n )和Y=(Y 1 ,Y 2 ,Y 3 ,…Y m )是联合随机变量,若随机变量 Y 构成一个无向图G=(V,E)表示的马尔可夫模型,则其条件概率分布P(Y∣X)称为条件随机场(简称 CRF),P(Yv∣X,Y w ,w =v)=P(Y v∣X,Y w ,w−v)其中w−v表示图G=(V,E)中与结点 v 有边连接的所有节点,w 不等于 v 表示结点 v 以外的所有结点。
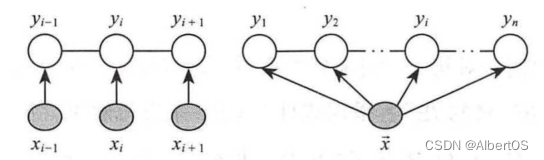
若在给定随机变量序列 X 的条件下,随机变量序列 Y 的条件概率分布P(Y∣X)构成条件随机场,且满足马尔可夫性,此时,称P(Y∣X)为线性链的条件随机场,简称 CRF,线性链条件随机场的结构图如图1所示。
HMM 与 CRF 的联系区别如下表所示:
| HMM | CRF | |
|---|---|---|
| 概率图类型 | 概率有向图 | 概率无向图 |
| 模型类别 | 生成模型 | 判别模型 |
| 求解过程 | 可能是局部最优 | 可以全局最优 |
| 处理方面 | 每个状态依赖上一个状态 | 依赖于当前状态的周围节点状态 |
作为一个免费的开放源码库,Spacy 使 Python 中的高级自然语言处理(NLP)变得更加简单方便。
Spacy 为 python 中的命名实体识别提供了一个非常有效的统计系统,它可以将标签分配给连续的令牌组。它提供了一个默认模型,可以识别各种命名或数字实体,其中包括公司名称、位置、组织、产品名称等。除了这些默认实体之外,Spacy 还可以通过训练模型以用新的被训练示例更新,将使模型可以任意类添新的命名实体,进行识别。
Stanford NER 是一个命名实体 Recognizer,用 Java 实现。它提供了一个默认的训练模型,主要用于识别组织、人员和位置等实体。除此之外,还提供针对不同语言和环境训练的各种模型。
斯坦福 NER 因为线性链条件随机场(CRF)序列模型已经在软件中实现,所以也被称为 CRF(条件随机场)分类器。我们可以使用自己的标注数据集为各种应用程序训练自己的自定义模型。
中文姓名一般由二字或三字组成,第一字为姓氏字(复姓为前两字),其后的一到两个汉字为名用字。统计表明,中文姓名在用字上也有一定规律:一方面某些字频频出现在姓名中,如在姓氏用字中,虽然姓氏辞典中列举了几千个姓氏字,但目前实际使用的不过几百个,而张、王、李、赵、刘5个姓竟占了32%;另一方面,某些字又从不被用作姓名用字,如最、仅、 紧、以、且等字。
根据这一特性,首先从一个含有1万多个人名的数据库中抽取303个姓用字和1047个名用字,形成系统的知识源;然后根据姓名的构成原则制定了一组姓名构成规则集,其中的规则以姓氏字驱动。由于中文姓名的构成是严格遵守构成规则的,因而本文将姓名构成规则定义为一组必须匹配的严格规则。

中文姓名在文本中不是孤立存在的,其依存的上下文信息具有一定的特点:
前置信息:姓名的前端多冠有对人的职业、职务及与说话人的关系的称谓,如“这是上海市副市长刘振元日前在与上海旅游记者协会座谈时介绍的。”、“我和妻子秦润英都是双目失明的盲人。”等。在上述句子中的“市长”和“妻子”就是人名“刘振元”和“秦润英”的前置提示信息。
后置信息:姓名的后端多随有对此人的职业、职务及与说话人的关系的称谓,如“我国著名学者彭明教授访问前苏联时将书稿复印件全文带回。”,这里的“教授”就成为人名“彭明”的后置提示信息。
提示动词:某些动词多随在姓名和人称代词后,如“说、指出、告诉、通知…”,可充分利用这些词的提示作用。
HanLP 是由一系列模型与算法组成的工具包,目标是普及自然语言处理在生产环境中的应用。HanLP 具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点;
提供词法分析(中文分词、词性标注、命名实体识别)、句法分析、文本分类和情感分析等功能。
HanLP 已经被广泛用于 Lucene、Solr、ElasticSearch、Hadoop、Android、Resin 等平台,有大量开源作者开发各种插件与拓展,并且被包装或移植到 Python、C#、R、JavaScript 等语言上去。 基于深度学习的 HanLP2.0 已于2020年初发布,面向下一个十年的前沿 NLP 技术,与 1.x 相辅相成,平行发展。
在 python 环境下使用 Hanlp 可以通过安装 pyhanlp 来导入:
pip install pyhanlp # 安装 pyhanlp 库
from pyhanlp import HanLP # 使用前导入 HanLP工具
在 Hanlp 工具中,主要使用的是 HMM 算法对人名进行识别,在对人名进行识别时,我们可以通过以下方式:
text =input()
segment = HanLP.newSegment().enableNameRecognize(True); # 构建人名识别器
result = segment.seg(text) # 对text文本进行人名识别
print(result) # 输出结果
比如,我们输入的文本为张三在吃苹果,输出的结果则为 [张三/nr, 在/p, 吃苹果/nz],人名识别的结果中,包含着各个词的识别结果,我们可以根据各个词的识别结果得知哪些词属于人名。常见标注的具体意义如下:
| 代码 | 意义 |
|---|---|
| nr | 人名 |
| n | 名词 |
| v | 动词 |
| p | 介词 |
| g | 语素词 |
| h | 前接部分 |
from pyhanlp import HanLP
text =input()
# 任务:完成对 text 文本的人名识别并输出结果
segment = HanLP.newSegment().enableNameRecognize(True); # 构建人名识别器
result = segment.seg(text) # 对text文本进行人名识别
print(result) # 输出结果
测试输入
张三今天没来上课
实际输出
[张三/nr, 今天/t, 没来/v, 上课/vi]
中文地名是指由汉字表示的中国地名及外国地名,从信息处理的角度出发,我们把中文地名定义为基本地名和复合地名构成的二级体系。基本地名是地名的最小成词单位,对应于人脑中存储地名的最小单位:它是人们对具有特定方位、地域范围的地理实体赋予的专有名称。作为地名的原子类型,基本地名满足指称性、非类指性(专门性)、词汇性、开放性等命名实体特征并具有指位性的功能特征。
典型的基本地名由“命名成分+通名”构成,命名成分是所指的标志符,不可缺省,如“江苏省”的“江苏”,“佛罗里达州”的“佛罗里达”;通名标识了所指单位的大小级别或类别,当命名成分已另有所指或为单字时常不可缺省,如“江苏路”中的“路”,“蓟县”的“县”。
基本地名通过合理组合形成复合地名。这里“合理”的意思是组合后形成的新地名有且只有一个所指,如“江苏省南京市”。复合地名是一个意义单位,相邻基本地名是否存在单向的领属关系是能否组合为一个复合地名的关键。因此,让计算机正确地识别、分析和理解复合地名有赖于基本地名的识别和基本地名之间关系的识别。

在 Hanlp 开发工具中,对地名识别主要采取的是 HMM 算法,在实际开发过程中,我们可以通过以下方式进行地名识别:
text =input()
segment = HanLP.newSegment().enablePlaceRecognize(True); # 构建地名识别器
result = segment.seg(text) # 对text文本进行地名识别
比如,我们输入文本中国是个好地方,可以得到地名识别的结果为[中国/ns, 是/vshi, 个/q, 好/a, 地方/n],与人名识别类似,地名识别器根据对句子的理解为各个词都做了标注,其中标注为 ns 的词即为地名。
在 Hanlp 中,目前标准分词器都默认关闭了地名识别,用户需要手动开启;这是因为消耗性能,其实多数地名都收录在核心词典和用户自定义词典中;在生产环境中,能靠词典解决的问题就靠词典解决,这是最高效稳定的方法;对命名实体识别要求较高的用户可以使用感知机词法分析器。
from pyhanlp import HanLP
text =input()
# 任务:完成对 text 文本的地名识别并输出结果
segment = HanLP.newSegment().enablePlaceRecognize(True); # 构建地名识别器
result = segment.seg(text) # 对text文本进行地名识别
print(result)
测试输入
中国是个好地方
实际输出
[中国/ns, 是/vshi, 个/q, 好/a, 地方/n]
注:ns即是识别为地名的名词
【1】自然语言处理
【2】命名实体识别(NER)综述
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
在我让另一个人重做我的前端UI之前,我的Rails应用程序运行平稳。我已经尝试解决此错误3天了。这是错误:Nosuchfileordirectory-identifyExtractedsource(aroundline#59):575859606162@post=Post.find(params[:id])authorize@postif@post.update_attributes(post_params)flash[:notice]="Postwasupdated."redirect_to[@topic,@post]else{"utf8"=>"✓","_method"=>"patc
我在尝试使用Nokogiri构建XML文档时遇到了一个小问题。我想将我的元素之一称为“文本”(请参阅下面粘贴代码的最底部)。通常,要创建一个新元素,我会执行类似以下的操作xml.text--但它似乎是.text是Nokogiri已经用来做其他事情的方法。因此,当我写这行时xml.textNokogiri没有创建名为的新元素但只是写了意味着成为元素内容的文本。我怎样才能让Nokogiri实际制作一个名为的元素??builder=Nokogiri::XML::Builder.newdo|xml|xml.TEI("xmlns"=>"http://www.tei-c.org/ns/1.0"