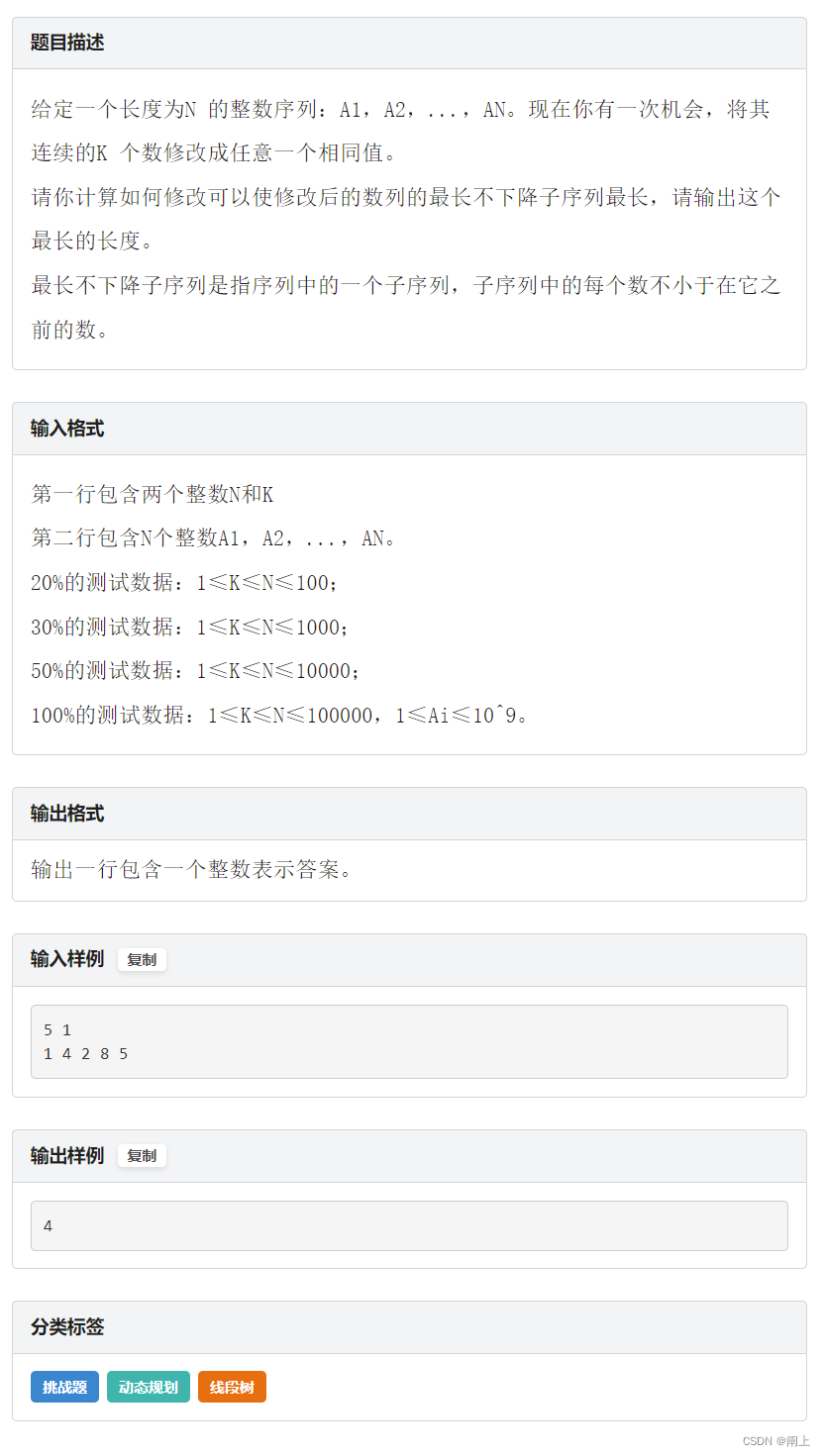
题意:
思路:
对于前 50% 的数据显然我们可以 dp 解决。从左到右维护每个位置 i 结尾的 最长不下降子序列,从右到左维护每个位置 i 结尾的 最长不上升子序列。最后枚举任意左右端点 i、j,中间大于等于 k 个数就更改这 k 数即可。
对于全部的数据,我们就得考虑优化 枚举 的过程 和 dp 转移的过程(这两过程都是 O ( n 2 ) O(n^2) O(n2) 的,尝试优化为 O ( n l o g n ) O(nlog_n) O(nlogn))。
列出 dp 的转移公式:
//朴素 n*n
for (int i = 1; i <= n; i++) {
dp[i] = 1;
for (int j = 1; j < i; j++)
if (z[j] < z[i])dp[i] = max(dp[i], dp[j] + 1);
}
可以发现每次从 [1、i - 1] 我们 找到比 z[i] 小的位置的 最大dp值 转移过来最好;
这就启发我们用权值线段树优化这个找的过程,把 循环 n 次 优化成 树中 l o g n log_n logn 的查询。
C o d e : Code: Code:
#include<bits/stdc++.h>
#include<unordered_map>
#include<unordered_set>
#define mem(a,b) memset(a,b,sizeof a)
#define cinios (ios::sync_with_stdio(false),cin.tie(0),cout.tie(0))
#define debug(x) cout<<"target is "<<x<<endl
#define forr(a,b,c) for(int a=b;a<=c;a++)
#define all(a) a.begin(),a.end()
#define oper(a) (operator<(const a& ee)const)
#define endl "\n"
#define ul (u << 1)
#define ur (u << 1 | 1)
using namespace std;
typedef long long ll;
typedef pair<int, int> PII;
const int N = 200010, M = 500010, MM = 110;
int INF = 0x3f3f3f3f, mod = 998244353;
ll LNF = 0x3f3f3f3f3f3f3f3f;
int n, m, k;
int z[N], dpl[N], dpr[N];
vector<int> vec;
int find(int x) { //离散化排序后二分查找元素位置
return lower_bound(all(vec), x) - vec.begin() + 1;
}
struct tree
{
int l, r, mx;
}tr[N << 2];
inline void pushup(int u) {
tr[u].mx = max(tr[ul].mx, tr[ur].mx);//维护max
}
void build(int u, int l, int r) {
if (l == r)tr[u] = { l,r,0 };
else {
tr[u] = { l,r,0 };
int mid = l + r >> 1;
build(ul, l, mid), build(ur, mid + 1, r);
}
}
void modify(int u, int d, int f) {
if (tr[u].l == d && tr[u].r == d) {
tr[u].mx = f;
}
else {
int mid = tr[u].l + tr[u].r >> 1;
if (mid >= d)modify(ul, d, f);
if (mid < d)modify(ur, d, f);
pushup(u);
}
}
int query(int u, int l, int r) {
if (tr[u].l >= l && tr[u].r <= r) {
return tr[u].mx;
}
else {
int mid = tr[u].l + tr[u].r >> 1;
int t = 0;
if (mid >= l)t = query(ul, l, r);
if (mid < r)t = max(t, query(ur, l, r));
return t;
}
}
void solve() {
cin >> n >> k;
forr(i, 1, n)cin >> z[i], vec.push_back(z[i]);
sort(all(vec));
vec.erase(unique(all(vec)), vec.end());
m = vec.size();
build(1, 1, m);
int ans = k;
//先用这个思想维护出从左到右 i 位置的最长不下降子序列
forr(i, 1, n) {
int t = find(z[i]);
int res = query(1, 1, t) + 1;
//从小于等于z[i]的区间中找 max(dpl值)
dpl[i] = res;
ans = max(ans, dpl[i]);
modify(1, t, res);
//同时更新此位置,维护此位置 max(dpl值)
}
build(1, 1, m);
//同样维护从右到左 i 位置的最长不上升子序列
for (int i = n; i; i--) {
int t = find(z[i]);
int res = query(1, t, m) + 1;
dpr[i] = res;
ans = max(ans, dpr[i]);
modify(1, t, res);
//但这里维护的同时要随时与 k 个前的 dpl[be] 取 max
int be = i - k - 1;
if (be >= 1) {
int tt = find(z[be]);
ans = max(ans, dpl[be] + k + query(1, tt, m));
//维护到此位置的权值线段树中,在比 z[be] 大的区间中找 max 值
//这样才能保证没有遗漏,因为中间可能不止空出 k 个数
}
}
//最后还有记录不连接两区间,直接加 k 的情况
for (int i = 1; i + k <= n; i++)
ans = max(ans, dpl[i] + k);
for (int i = n; i - k >= 1; i--)
ans = max(ans, dpr[i] + k);
cout << ans;
}
int main() {
cinios;
int T = 1;
forr(t, 1, T) {
solve();
}
return 0;
}
/*
8 2
5 6 100 99 98 97 7 8
//答案是 6
*/
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
假设我必须(小型到中型)阵列:tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]如何确定tokens是否以相同的顺序包含template的所有条目?(请注意,在上面的示例中,应忽略第一个“ccc”,从而由于最后一个“ccc”而导致匹配。) 最佳答案 这适用于您的示例数据。tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]po
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
3月26日,映宇宙(HK:03700,即“映客”)发布截至2022年12月31日的2022年度业绩财务报告。财报显示,映宇宙2022年的总营收为63.19亿元,较2021年同期的91.76亿元下降31.1%。2022年,映宇宙的经营亏损为4698.7万元,2021年同期则为净利润4.57亿元;期内亏损(净亏损)为1.68亿元,2021年同期的净利润为4.33亿元;非国际财务报告准则经调整净利润为3.88亿元,2021年同期为4.82亿元,同比下降19.6%。 映宇宙在财报中表示,收入减少主要是由于行业竞争加剧,该集团对旗下产品采取更为谨慎的运营策略以应对市场变化。不过,映宇宙的毛利率则有所提升
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
目录前言: 一、ASC分析代码实现二、 卡片分析代码实现三、 直线分析代码实现四、货物摆放分析代码实现小结:前言: 在刷题的过程中,发现蓝桥杯的题目和力扣的差别很大。让人有一种不一样的感觉,蓝桥杯题目偏向对于实际问题用编程去的解决,而力扣给人感觉很锻炼自己的编程思维,逻辑能力。两者结合去刷,相信会有不一样的收获。 一、ASC 已知大写字母A的ASCII码为65,请问大写字母L的ASCII码是多少?分析 这道题目看上去很简单,我们需确定自己计算的准确,所以我建议用编程去解决。代码实现publicclassTest8{publicstaticvoidmain(String[]args){Sy
我有一个存储JSON数据的列。当它处于编辑状态时,我不知道如何显示它。serialize:value,JSON=f.fields_for:valuedo|ff|.form-group=ff.label:short=ff.text_field:short,class:'form-control'.form-group=ff.label:long=ff.text_field:long,class:'form-control' 最佳答案 代替=f.fields_for:valuedo|ff|请使用以下代码:=f.fields_for:va
在RubyonRails中,如果数组为空,则具有序列化数组字段的模型将不会在.save()上更新,而它之前有数据。我正在使用:ruby2.2.1rails4.2.1sqlite31.3.10我创建了一个字段设置为文本的新模型:railsgmodel用户名:stringexample:text在我添加的User.rb文件中:serialize:example,Array我实例化了User类的一个新实例:test=User.new然后我保存用户以确保它正确保存:test.save()(0.1ms)begintransactionSQL(0.4ms)INSERTINTO"users"("cr
是否可以在使用YAML.load_file时强制Ruby调用初始化方法?我想调用该方法以便为我不序列化的实例变量提供值。我知道我可以将代码分解成一个单独的方法并在调用YAML.load_file之后调用该方法,但我想知道是否有更优雅的方法来处理这个问题。 最佳答案 我认为你做不到。由于您要添加的代码确实特定于要反序列化的类,因此您应该考虑在类中添加该功能。例如,让Foo成为您要反序列化的类,您可以添加一个类方法,例如:classFoodefself.from_yaml(yaml)foo=YAML::load(yaml)#editth