HTML 中的<span>标签被视为内联元素。它类似于 div 标记,但 div 标记特意用于块级元素,而 span 用于内联元素。它主要用于用户想要将内联元素分组到其代码结构中。HTML 中的 Span 标记用于通过使用元素类或 id 属性为特定内容提供样式。使用 HTML 文档中的 span 标记本身无法进行视觉更改。它用作 HTML 文档中的内联标记。在代码中使用 span 标记有助于减少代码和 HTML 属性。
定义 span 标记的语法如下:
语法:
<span class=""> Contents </span>
例:
<!DOCTYPE html>
<html>
<head>
<title>Span tag in HTML </title>
<style>
.demo {
color: blue;
font-size: 200%;
position: relative;
top: 5px;
}
</style>
</head>
<body>
<p><span class="demo">O</span>Pride make us artificial and Humility make us real.</p>
<p>True fact about life </p>
</body>
</html>输出:

下面是一些用于应用<span>样式的属性。具体如下:
下面给出了 html 中 span 标记的示例:
示例 #1
代码:
<!DOCTYPE html>
<html>
<head>
<title>HTML Span Tag</title>
</head>
<style>
.imgdemo {
padding-left:25px;
background:url(./Content/data/2.jpg) no-repeat top left;
display: inline-block;
height: 150px;
width: 150px;
}
</style>
<body>
<!-- span tags with inline style/css -->
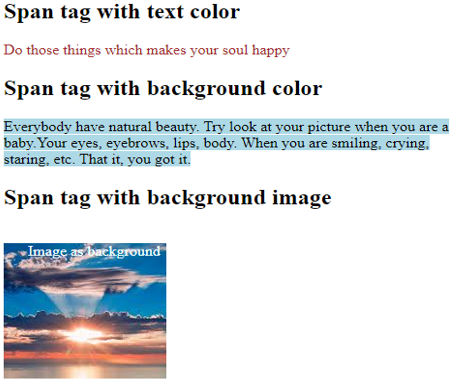
<h2>Span tag with text color</h2>
<span style="color:brown;">
Do those things which makes your soul happy </span>
<br>
<h2> Span tag with background color</h2>
<span style="background-color:lightblue;">
Everybody have natural beauty. Try look at your picture when you are a baby. Your eyes, eyebrows, lips, body. When you are smiling, crying, staring, etc. That it, you got it.</span>
<br>
<h2> Span tag with background image</h2>
<br>
<span class="imgdemo" style="color: azure; font-size: 16px; font-display: block;">
Image as background</span>
</body>
</html>输出:
示例 #2
代码:
<!--Example 2-->
<!DOCTYPE html>
<html>
<head>
<title>HTML Span Tag</title>
</head>
<body>
<h2> Span tag Examples</h2>
<p>Good, Better, Best Never let it rest.
<span style="color:crimson;"> "Till your good is better and your better is best" </span></p>
<p>Everyday you have a choice -<span style="font-family: cursive; font-weight: 200; font- size: 18px;">
STAY THE SAME OR CHANGE </span>
</p>
<p>Whenever you see a successful person you only see the public glories, never the private sacrifices to reach them."<span style="background-color: aqua ; color:darkblue;">
"Opportunities don't happen, you create them" </span></p>
</body>
</html>输出:

示例 #3
代码:
<!DOCTYPE html>
<html>
<style>
.spandemo {
background:url(./Content/data/3.jpg) no-repeat top left;
display: inline-block;
padding-top: 20px;
width: 1800px;
height: 500px;
}
</style>
<body>
<h2> Span tag for image</h2> <br>
<span class="spandemo" style="color: aliceblue; font-weight: bold;">
<p> Nature always wears<br> Color of SPIRIT. </p> <br>
Heaven is under our feet <br>as well as over our heads <br>
<p> Deep in their roots,<br>all flowers Keep the light </p>
<p> My soul steers me<br> into nature's silence</p>
</span>
</body>
</html>输出:

从上述所有信息中,我们了解到HTML中的<span>标记用于为内联元素提供样式。可以对此样式属性进行分组,并以内联方式指定它们。Span标签主要用于在内联CSS的帮助下在我们的网页上排列结构部分和适当的布局部分。
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我试图使用yard记录一些Ruby代码,尽管我所做的正是所描述的here或here#@param[Integer]thenumberoftrials(>=0)#@param[Float]successprobabilityineachtrialdefinitialize(n,p)#initialize...end虽然我仍然得到这个奇怪的错误@paramtaghasunknownparametername:the@paramtaghasunknownparametername:success然后生成的html看起来很奇怪。我称yard为:$yarddoc-mmarkdown我做错了什么?
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
我正在使用Rails构建一个简单的聊天应用程序。当用户输入url时,我希望将其输出为html链接(即“url”)。我想知道在Ruby中是否有任何库或众所周知的方法可以做到这一点。如果没有,我有一些不错的正则表达式示例代码可以使用... 最佳答案 查看auto_linkRails提供的辅助方法。这会将所有URL和电子邮件地址变成可点击的链接(htmlanchor标记)。这是文档中的代码示例。auto_link("Gotohttp://www.rubyonrails.organdsayhellotodavid@loudthinking.
我正在学习http://ruby.railstutorial.org/chapters/static-pages上的RubyonRails教程并遇到以下错误StaticPagesHomepageshouldhavethecontent'SampleApp'Failure/Error:page.shouldhave_content('SampleApp')Capybara::ElementNotFound:Unabletofindxpath"/html"#(eval):2:in`text'#./spec/requests/static_pages_spec.rb:7:in`(root)'
我有一个div,它根据表单是否正确提交而改变。我想知道是否可以检查类的特定元素?开始元素看起来像这样。如果输入不正确,添加错误类。 最佳答案 试试这个:browser.div(:id=>"myerrortest").class_name更多信息:http://watir.github.com/watir-webdriver/doc/Watir/HTMLElement.html#class_name-instance_method另一种选择是只查看具有您期望的类的div是否存在browser.div((:id=>"myerrortes
我正在尝试将一个简单的CSV文件读入HTML表格以在浏览器中显示,但我遇到了麻烦。这就是我正在尝试的:Controller:defshow@csv=CSV.open("file.csv",:headers=>true)end查看:输出:NameStartDateEndDateQuantityPostalCode基本上我只获取标题,而不会读取和呈现CSV正文。 最佳答案 这最终成为最终解决方案:Controller:defshow#OpenaCSVfile,andthenreaditintoaCSV::Tableobjectforda
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
考虑一下:现在这些情况:#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2我需要用其他字符串输出URL。我如何保证&符号不会被转义?由于我无法控制的原因,我无法发送&。求助!把我的头发拉到这里:\编辑:为了澄清,我实际上有一个像这样的数组:@images=[{:id=>"fooid",:url=>"http://