目录
三、servlet中与Cookie和Session相关的API
3.1 HttpServletRequest 类中的相关方法:
3.2 HttpServletResponse 类中的相关方法
我们知道,HTTP协议是一种无状态协议,这意味着每个HTTP请求都是独立的,服务器不会记住之前的任何请求,也不会记录当前请求与之前请求的关系。每个请求都是独立的、不相关的,服务器不会保留任何有关请求或响应的信息,也不会保存客户端的状态。
1.1 为什么HTTP协议是无状态的?
这是由于HTTP协议的工作机制决定的:客户端向服务器发起请求,服务器响应请求并返回相应的数据。在请求完成后,服务器会立即关闭连接,不会再保持连接状态,下一次请求需要重新建立连接。因此,服务器无法保存客户端的状态信息。
为了解决这个问题,Web应用程序通常使用一些技术来维护客户端状态,例如Cookie和Session。这些技术在客户端和服务器之间传递状态信息,使得应用程序能够跟踪每个客户端的状态,实现有状态的应用程序。
需要注意的是。虽然HTTP协议为无状态协议,但是与HTTP支持长连接不冲突。
长连接(也称为持久连接)是一种HTTP/1.1协议引入的技术,它允许客户端和服务器在一个TCP连接上发送多个HTTP请求和响应,而不需要为每个请求/响应都建立一个新的TCP连接。这种技术可以显著减少网络连接的建立和关闭开销,提高网络传输效率,同时也能够更好地支持HTTP协议的特性,如流式传输和分块传输编码等。
在长连接中,客户端和服务器之间的TCP连接在一个HTTP请求/响应完成后不会立即关闭,而是继续保持连接状态,等待下一个HTTP请求/响应。这样,当客户端发送下一个HTTP请求时,可以直接利用之前的TCP连接,不需要再进行TCP握手和挥手等操作,从而节省了网络资源和时间。
因此,虽然HTTP协议是无状态的,但是通过使用长连接技术,可以在保持无状态的前提下提高HTTP协议的效率和性能。需要注意的是,长连接需要服务器和客户端都支持,否则无法建立长连接。同时,长连接也可能会导致资源占用问题,因此需要合理使用和配置。
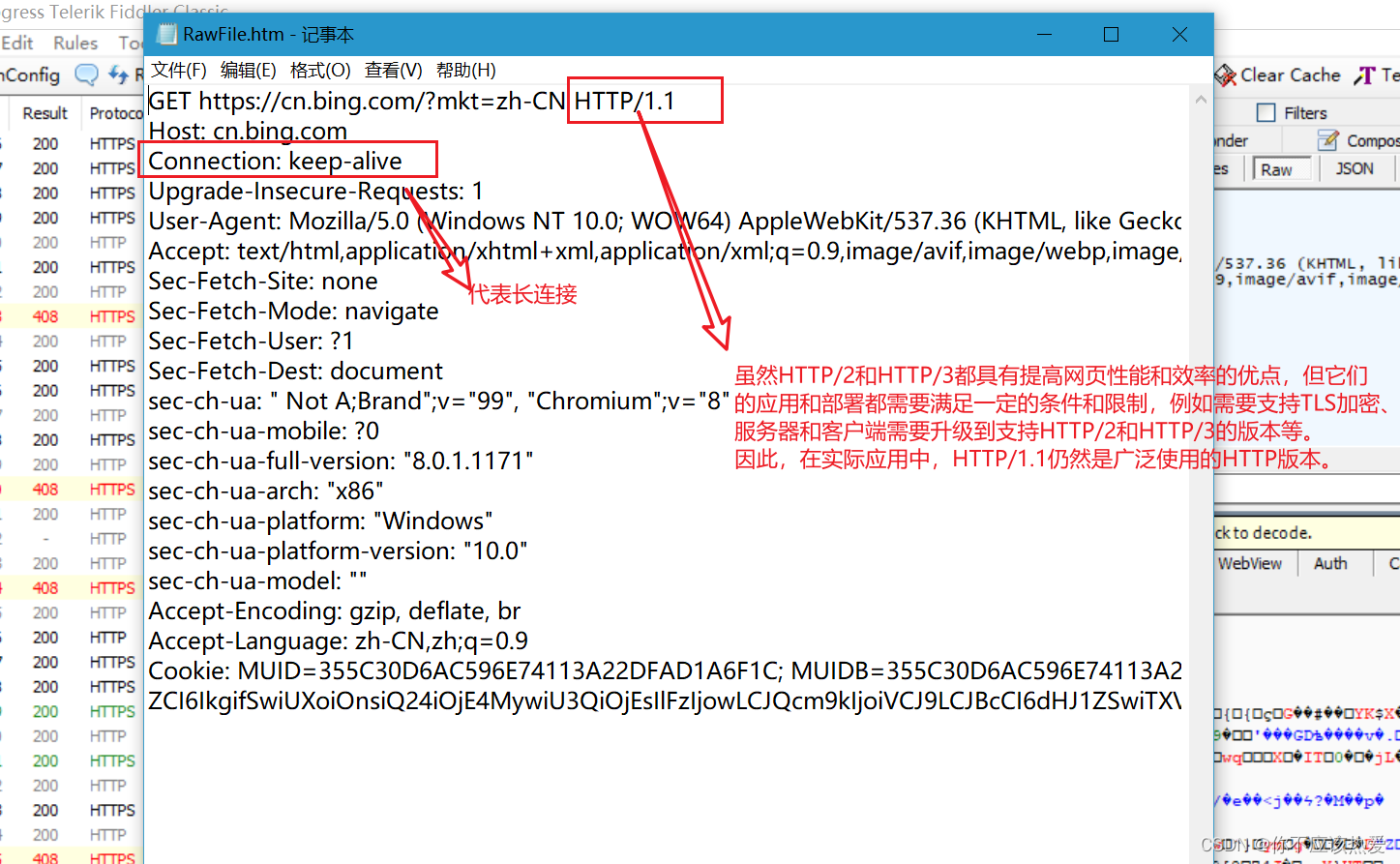
以下为浏览器请求BIng主页的抓包信息(Connection:keep-alive就为长连接的意思):
在HTTP/1.1中,如果客户端请求头中没有明确指定Connection头字段,那么服务器会默认使用长连接,即保持TCP连接处于打开状态,直到客户端或服务器明确要求关闭连接为止。这种方式可以减少每次请求和响应时建立和关闭TCP连接的开销,提高网络传输效率和性能。但需要注意的是,长连接并不是在所有情况下都适用,有时候也需要根据实际情况关闭连接。
1.2 在HTTP协议中流式传输和分块传输编码的区别
流式传输和分块传输编码都是HTTP协议中用于数据传输的技术,它们的区别如下:
数据分割方式不同:流式传输是将响应数据(如HTML,JSON等)按照一定的块大小进行分割,逐步发送到客户端;而分块传输编码是将数据分成若干个块(Chunk),每个块有独立的长度信息和数据内容,使用分块传输编码方式将数据分成多个块进行传输,每个块之间用一个CRLF(回车换行)分隔符分开。
响应方式不同:流式传输是一次性发送响应数据,客户端在接收到第一个数据块时就可以开始处理;而分块传输编码则是将响应数据分成多个块逐个发送,客户端需要在接收完所有块后再进行处理。
大小控制不同:流式传输中每个数据块的大小是固定的,由服务器决定;而分块传输编码中每个块的大小是不固定的,客户端需要通过读取长度信息来确定每个块的大小。
读取速度,应用场景不同:流式传输是在客户端接收到第一个数据块时就可以开始处理,而不必等待整个响应数据全部接收完毕。这种方式可以减少客户端等待时间,提高响应速度。流式传输常用于需要实时更新的数据场景,如股票行情、新闻快讯等。而分块传输编码客户端接收到每个块后,会先读取块的长度信息,再读取对应长度的数据内容。这种方式可以避免一次性传输大量数据造成的网络拥塞和连接中断,并且可以让客户端在接收到部分数据时就开始处理,从而提高传输效率和响应速度。
总之,流式传输和分块传输编码都可以提高HTTP数据传输的效率和响应速度,但应根据具体的场景和需求进行选择和使用。流式传输适用于需要实时更新的数据场景,如股票行情、新闻快讯等;而分块传输编码适用于需要传输大文件的场景,能够避免一次性传输造成的网络拥塞和连接中断。
上面我们说到,由于HTTP是无状态的,所以需要引入Cookie来解决这一问题。
Cookie允许服务器在客户端上存储少量的数据,例如:用户的身份,偏好,购物车信息等。以便在之后的HTTP请求中将该数据发送回服务器,通过Cookie,服务器可以识别和跟踪用户的身份和状态,从而提供更加个性化和定制化的服务。
回顾以下,Cookie是什么,从哪里来,发送到哪去,存储在哪?
Session(会话)是Web应用程序中的一个概念,它指的是一系列相关的HTTP请求和响应,通常用于在客户端和服务器之间维护一些状态信息。在一个会话中,服务器会创建一个唯一的Session ID(会话标识符),并将该Session ID发送给客户端浏览器。客户端在之后的每个HTTP请求中都会携带该Session ID,以便服务器能够识别并跟踪该客户端的身份和状态。
为了加深理解,我们来看一组登录流程:
 Session通常是基于Cookie实现的。具体来说,当服务器创建一个新的Session时,它会在响应头中添加一个Set-Cookie字段,其中包含了一个名为SESSIONID的Cookie值,该值就是新创建的Session ID。客户端在收到该响应时会将该Cookie值保存在浏览器中,并在之后的每个HTTP请求中发送回服务器。服务器在接收到每个HTTP请求时都会检查该请求中是否包含了有效的Session ID,如果存在则说明该请求属于某个已经创建的Session,服务器就可以根据该Session ID来识别和跟踪客户端的身份和状态。
Session通常是基于Cookie实现的。具体来说,当服务器创建一个新的Session时,它会在响应头中添加一个Set-Cookie字段,其中包含了一个名为SESSIONID的Cookie值,该值就是新创建的Session ID。客户端在收到该响应时会将该Cookie值保存在浏览器中,并在之后的每个HTTP请求中发送回服务器。服务器在接收到每个HTTP请求时都会检查该请求中是否包含了有效的Session ID,如果存在则说明该请求属于某个已经创建的Session,服务器就可以根据该Session ID来识别和跟踪客户端的身份和状态。
需要注意的是:Cookie是有存储期限的,越敏感的网站存储期限越短。
Cookie和Session是Web开发中常用的两种技术,用于在服务器和客户端之间保持状态信息。它们的区别如下:
存储位置不同:Cookie是存储在客户端的浏览器中的文本文件,而Session是存储在服务器端的内存中或者数据库中的键值对。
安全性不同:由于Cookie是存储在客户端中的,所以存在被窃取或者篡改的风险。而Session存储在服务器端,相对来说更加安全。
存储容量不同:Cookie的存储容量较小,通常为4KB左右,而Session的存储容量可以比较大,但会占用服务器的内存或者存储资源。
生命周期不同:Cookie可以设置过期时间,可以长期保存在客户端的浏览器中;而Session在用户关闭浏览器或者超过一定时间后,会自动销毁。
使用方式不同:Cookie是通过在服务器端发送HTTP响应头来设置的,客户端的浏览器会自动保存Cookie,下一次请求时会自动发送Cookie到服务器端。而Session需要在服务器端通过某种方式生成Session ID,并将Session ID存储在Cookie中或者URL参数中,客户端浏览器会将Session ID发送到服务器端,服务器根据Session ID来获取Session数据。
综上所述,Cookie和Session都可以用于在服务器和客户端之间保持状态信息,但它们的应用场景和特点有所不同,具体使用哪种技术要根据实际需求和安全要求来决定。
| 方法 | 描述 |
| HttpSession getSession() | 在服务器中获取会话. 参数如果为 true, 则当不存在会话时新建会话; 参数如果 为 false, 则当不存在会话时返回 null |
| Cookie[] getCookies() | 返回一个数组, 包含客户端发送该请求的所有的 Cookie 对象. 会自动把 Cookie 中的格式解析成键值对. |
| 方法 | 描述 |
| void addCookie(Cookie cookie) | 把指定的 cookie 添加到响应中. |
| 方法 | 描述 |
| Object getAttribute(String name) | 该方法返回在该 session 会话中具有指定名称的对象,如果没 有指定名称的对象,则返回 null. |
| void setAttribute(String name, Object value) | 该方法使用指定的名称绑定一个对象到该 session 会话 |
| boolean isNew() | 判定当前是否是新创建出的会话 |
每个 Cookie 对象就是一个键值对
| 方法 | 描述 |
| String getName() | 该方法返回 cookie 的名称。名称在创建后不能改变。(这个值是 Set Cooke 字段设置给浏览器的) |
| String getValue() | 该方法获取与 cookie 关联的值 |
| void setValue(String newValue) | 该方法设置与 cookie 关联的值。 |
第一步,约定前后端接口。
我们需要实现两套交互逻辑,一是登录跳转,二是获取主页。
登录跳转约定:
约定使用POST请求,响应采用302重定向。
package login;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86136
* Date: 2023-04-01
* Time: 18:53
*/
@WebServlet("/loginServlet")
public class LoginServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String username = req.getParameter("username");
String password = req.getParameter("password");
//因为这里我们主要是演示Cookie和Session,所以为了简化流程,并不将用户名和密码
//存入到数据库中,而是直接定死。约定用户名合法为 Jay 和 Lin
//密码合法为123。
if(!username.equals("Jay") && !username.equals("Lin")) {
//登录失败
System.out.println("用户名错误");
resp.sendRedirect("login.html");
return;
}
if (!password.equals("123")) {
//登录失败
System.out.println("密码错误");
resp.sendRedirect("login.html");
return;
}
//登录成功
//1.创建一个会话
HttpSession session = req.getSession(true);
//2.把当前的用户名保存在会话中
//void setAttribute(String var1, Object var2);
session.setAttribute("username",username);
//初始情况下设置登录次数
session.setAttribute("count",0);
//3.重定向到主页
resp.sendRedirect("indexServlet");
}
}
分析:
其中的getSession(true):判定当前请求是否已经有对应的会话(拿着来自客户端的请求中Cookie里的sessionId查一下),如果sessionId不存在,或者没有被查到,那么就创建一个新的会话,并插入到哈希表中。如果查到了,就直接返回查到的结果。
创建新的会话的流程如下:构造一个HttpSession对象,构造唯一的sessionId,把这个键值对插入到哈希表中,最后把sessionId设置到响应报文的Set-Cookie字段中,有服务器发送给浏览器。
获取主页约定:
采用GET请求,响应返回一个页面:
package login;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
@WebServlet("/indexServlet")
public class IndexServlet extends HttpServlet {
//因为通过浏览器是通过重定向来发送请求的,所以以下为doGet
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//需要先判定用户的登录状态
//如果用户没有登录,要求先登录,如果登录了,则根据 会话 中的用户名,来显示到页面上
//这个操作不会触发会话的创建
HttpSession session = req.getSession(false);
if (session == null) {
//未登录状态
System.out.println("用户未登录");
}
//已经登录,取出会话信息
String username = (String) session.getAttribute("username");
Integer cnt = (Integer) session.getAttribute("count");
//访问次数加1
cnt++;
//写回到会话中
session.setAttribute("count",cnt);
//构造页面
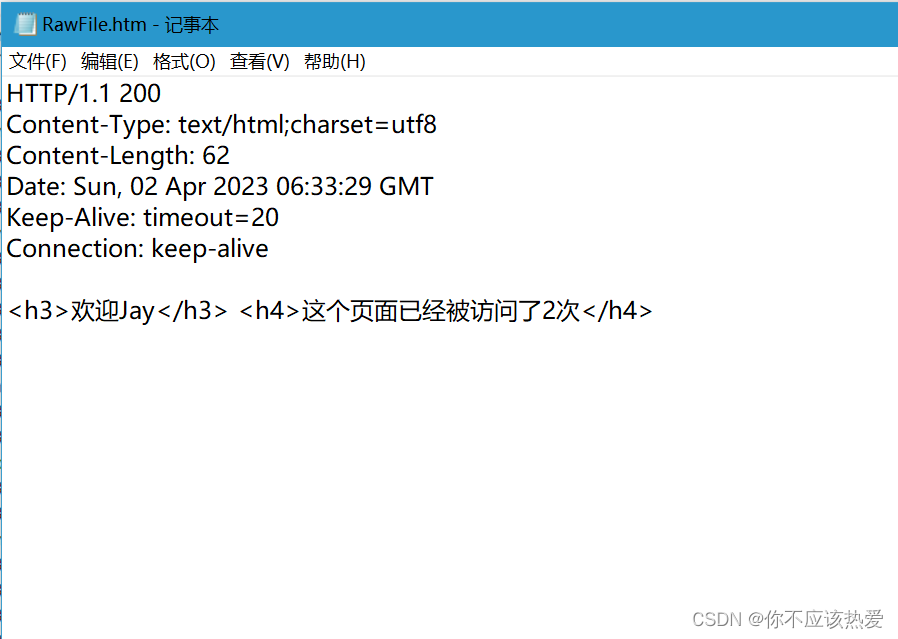
resp.setContentType("text/html; charset=utf8");
resp.getWriter().write("<h3>欢迎" + username + "</h3> <h4>这个页面已经被访问了"+cnt+"次</h4>");
}
}
第二步,编写前端交互页面
我们的重点是来学习登录的逻辑,因此登录的界面不需要很好看很复杂,只要能够有两个输入框和一个提交按钮让我们输入账号密码就行。目标页面如下:
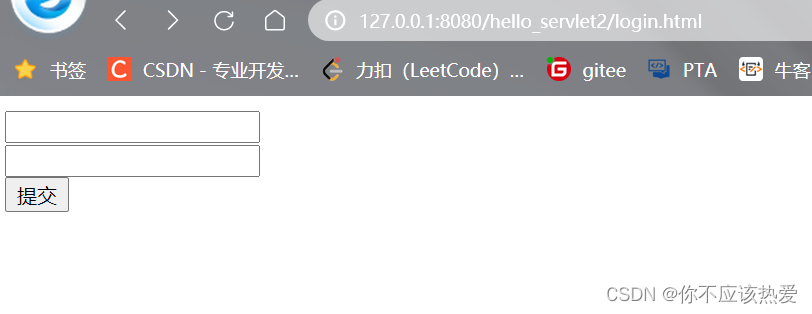
前面我们约定了登录的跳转采用post请求,由于场景很简单,我们直接使用form表单构造post请求就可以了:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form action="loginServlet" method="post">
<input type="text" name="username">
<br>
<input type="password" name="password">
<br>
<input type="submit" name="提交">
</form>
</body>
</html>其中input标签的name属性就对应键值对的key,输入的内容就对应键值对的value。
效果演示:
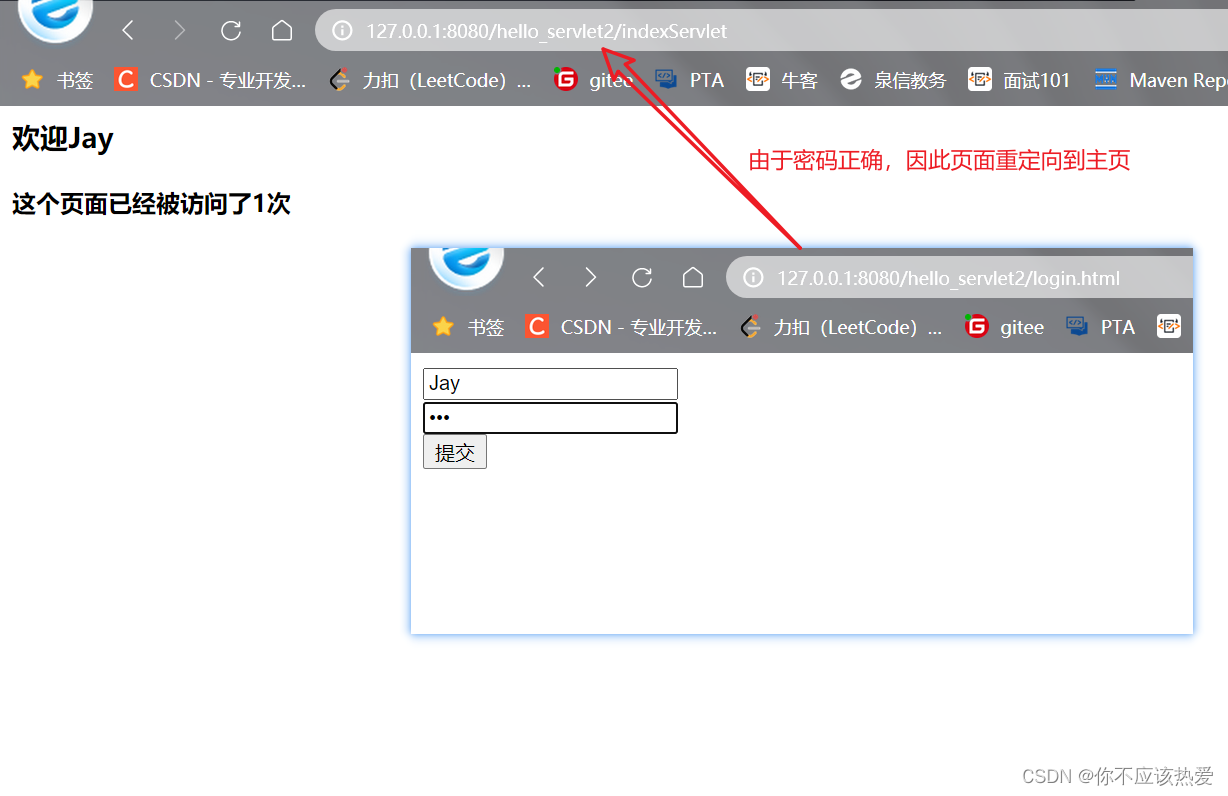
下面利用抓包结果来进一步加深理解:
第一次交互
请求部分:注意,第一次请求是没有Cookie的。
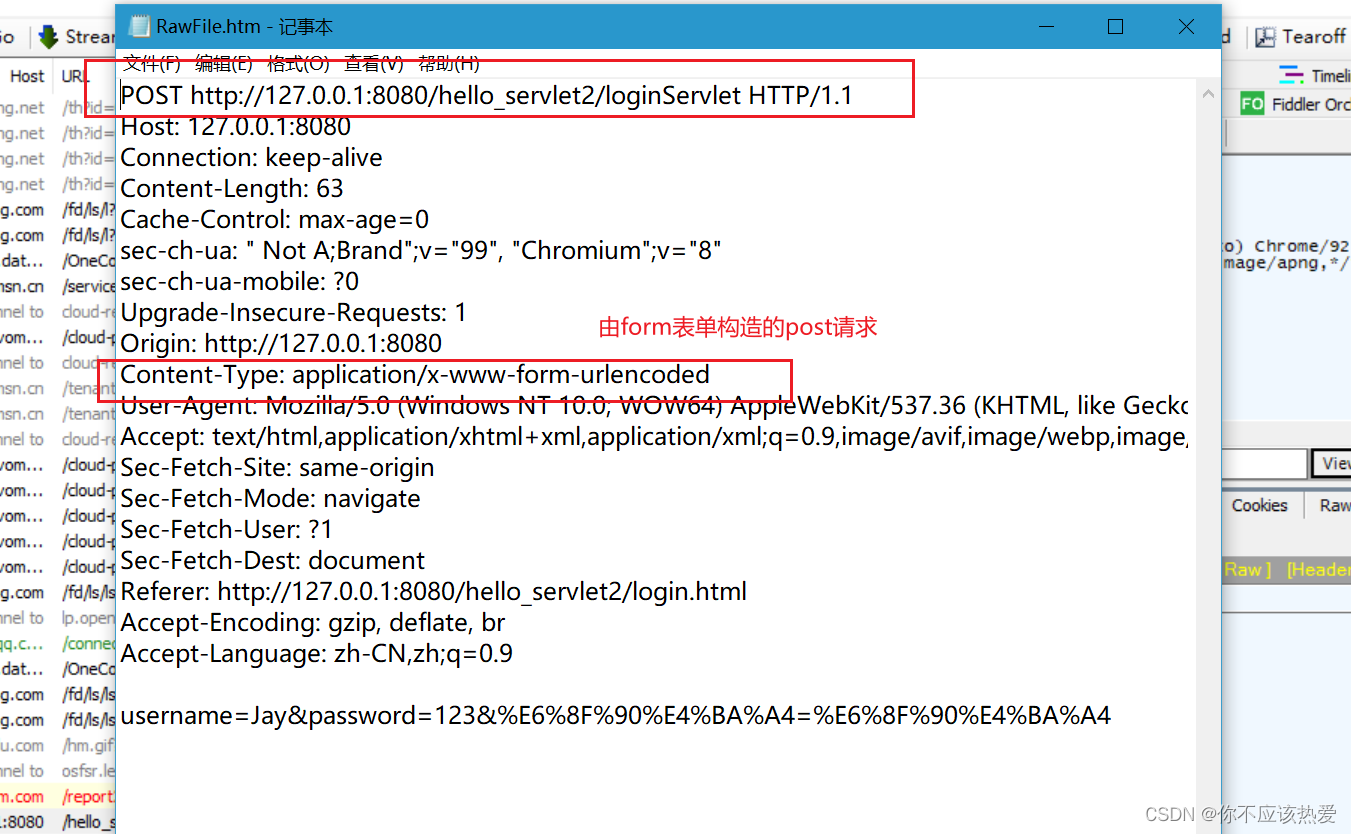
服务器返回给登录界面的响应部分:
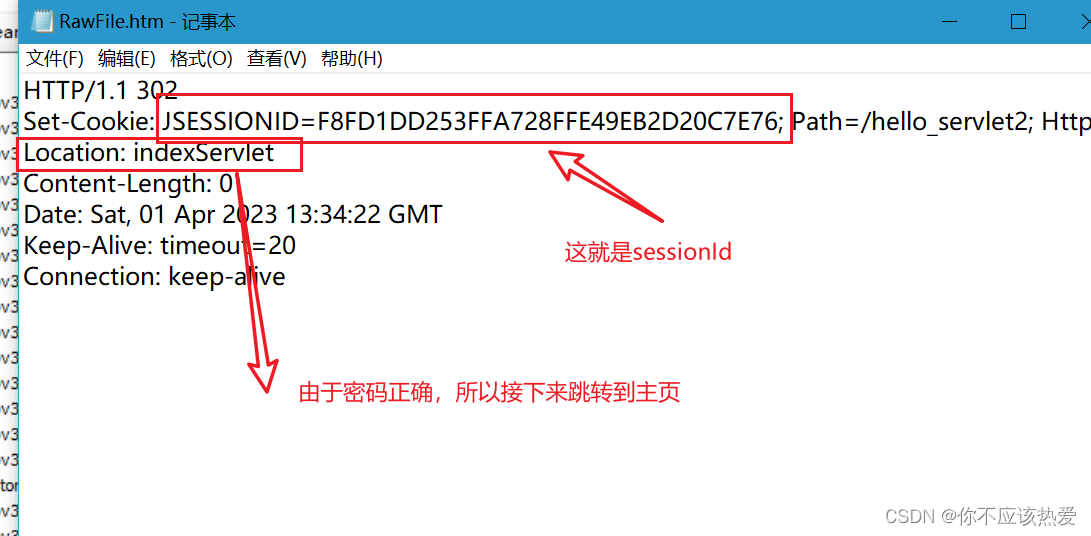
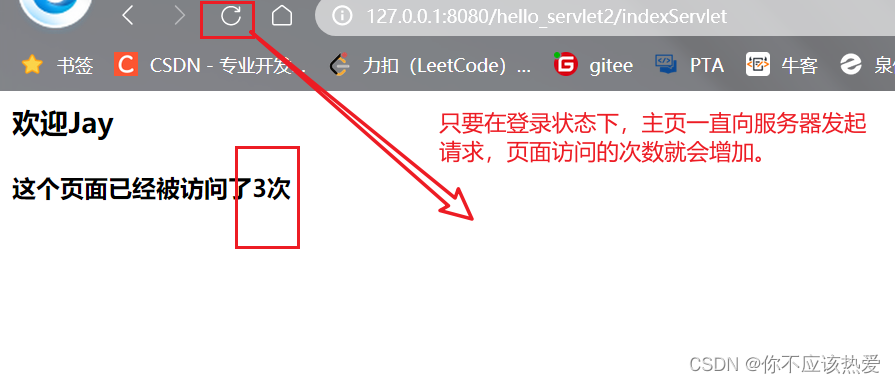
第二次交互
在登录状态下,主页向服务器发起访问请求:
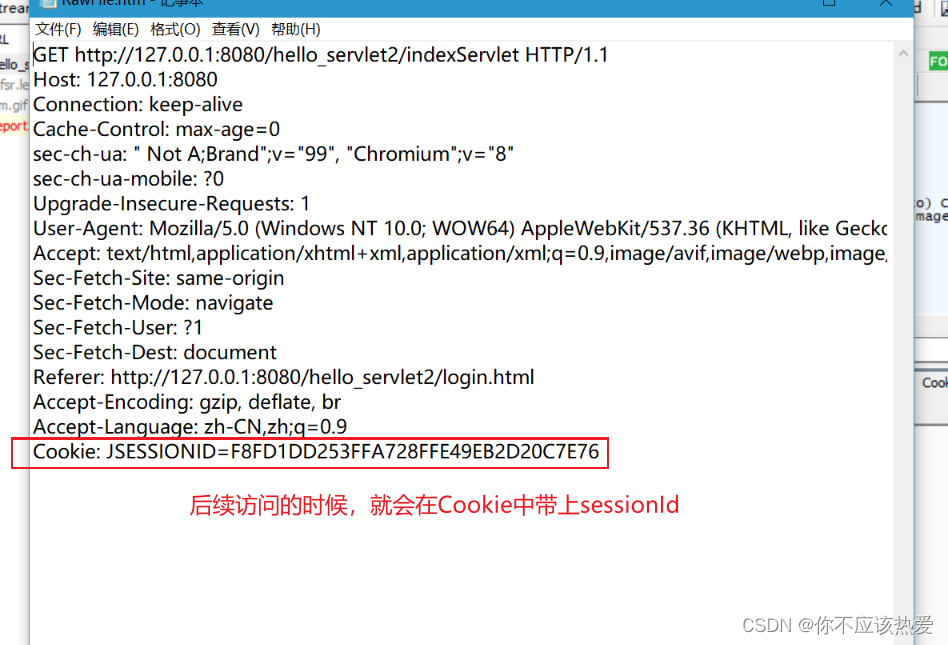
这个带有Cookie的get请求到达服务器的时候,Servlet会在getSession方法中根据sessionId来查询HttpSession对象:
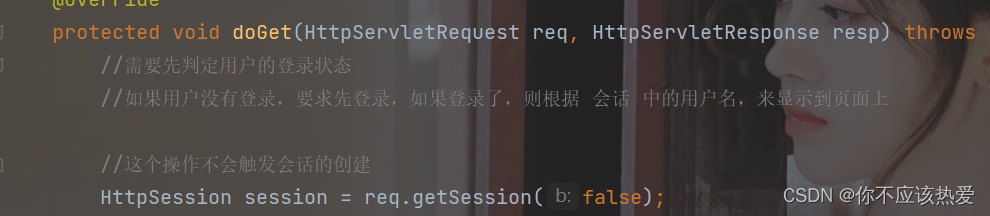
由于sessionId查的到,于是就返回信息。
服务器返回给浏览器的响应部分:
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的