Java为每一个基本数据类型提供了对应的一个包装类。包装类是一个类,这样Java就可以在包装类中提供常用的方法等供我们使用。
java并不是纯面向对象的语言,java语言是一个面向对象的语言,但是java中的基本数据类型却不是面向对象的,但是我们在实际使用中经常将基本数据类型转换成对象,便于操作,比如,集合的操作中,这时,我们就需要将基本类型数据转化成对象!
基本数据类型和对应包装类的对应关系为:
| 基本数据类型 | 包装类 |
|---|---|
| byte | Byte |
| boolean | Boolean |
| short | Short |
| char | Character |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
包装类的功能基本类似本文就以Integer为例子演示。
public static void main(String[] args) {
Integer i = 10;
}
public static void main(String[] args) {
Integer i = new Integer(10);
Integer i2 = new Integer("11");
}
public static void main(String[] args) {
Integer i = Integer.valueOf(10);
Integer i2 = Integer.valueOf("11");
}
| 方法 | 解释 |
|---|---|
| static Integer valueOf(int i) | 把int转换转换成Integer对象返回 |
| static Integer valueOf(String s) | 把字符串转换转换成Integer对象返回 要求字符串的内容必须为纯数字 |
| static int parseInt(String s) | 把字符串转换转换成int返回 要求字符串的内容必须为纯数字 |
public static void main(String[] args) {
Integer i = Integer.valueOf(10);
Integer i2 = Integer.valueOf("11");
int num = Integer.parseInt("123");
System.out.println(num);
}
结果:

在JDK1.5中就增加了自动装箱和自动拆箱。主要是让基本数据类和对应的包装类进行自动的转换,方便我们的使用。
自动装箱就是基本数据类型可以自动转换为对应的包装类。例如:
Integer i = 10;
int num = 20;
Integer i2 = num;
自动拆箱就是包装类可以自动转换为基本数据类型。例如:
Integer i = new Integer(10);
int num = i;
例:
Integer num = 10;
//进行计算时隐含的有自动拆箱
System.out.println(num--);
下面说点稍微难点的,是稍微
//在-128~127 之外的数
Integer num1 = 297; Integer num2 = 297;
System.out.println("num1==num2: "+(num1==num2));
// 在-128~127 之内的数
Integer num3 = 97; Integer num4 = 97;
System.out.println("num3==num4: "+(num3==num4));
结果:
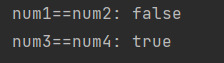
打印的结果是:
num1num2: false
num3num4: true
很奇怪吧:这就归结于java对于Integer与int的自动装箱与拆箱的设计,是一种模式:叫享元模式(flyweight)
为了加大对简单数字的重利用,java定义:在自动装箱时对于值从–128到127之间的值,它们被装箱为Integer对象后,会存在内存中被重用,始终只存在一个对象
而如果超过了从–128到127之间的值,被装箱后的Integer对象并不会被重用,即相当于每次装箱时都新建一个 Integer对象;明白了吧
以上的现象是由于使用了自动装箱所引起的,如果你没有使用自动装箱,而是跟一般类一样,用new来进行实例化,就会每次new就都一个新的对象;
这个的自动装箱拆箱不仅在基本数据类型中有应用,在String类中也有应用,比如我们经常声明一个String对象时:
String str = "sl";
//代替下面的声明方式
String str = new String("sl");
如图片失效等情况请参阅公众号文章:https://mp.weixin.qq.com/s/5tr-KUiVNJz0LbeEuTAw_A
欢迎关注我的公众号:愚生浅末,一起学习交流。
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.
Java的Collections.unmodifiableList和Collections.unmodifiableMap在Ruby标准API中是否有等价物? 最佳答案 使用freeze应用程序接口(interface):Preventsfurthermodificationstoobj.ARuntimeErrorwillberaisedifmodificationisattempted.Thereisnowaytounfreezeafrozenobject.SeealsoObject#frozen?.Thismethodretur