查阅了一些FPGA图像处理的资料,总结出了获得3×3图像矩阵的方法主要有下面这几种。(1)用移位寄存器IP核;(2)用2个或者3个ram实现;(3)用2个或者3个fifo实现。我这边是使用vivado作为开发环境,quartus中有专门的IP核可以实现图像数据的缓存,但是vivado中的移位寄存器只可以缓存一行,而且最多缓存1088个,如下图所示。而且缓存数据很多时,会出现缓存数量不准确的现象,大家可以自己去试试。因此在vivado中推荐使用fifo或者ram来实现。
利用时序图软件绘制了用fifo实现的移位寄存器的时序图,这边大致介绍下每个信号的作用。
clk:时钟信号
rst_n:复位信号,低有效
clken:数据有效信号,高有限
shiftin:数据输入信号
wren1:fifo1的写使能
data_count1:fifo1的数据计数
rden1:fifo1的读使能
dout:fifo1的数据输出
wren2:fifo2的写使能
data_count2:fifo2的数据计数
rden2:fifo2的读使能
taps1x:前前一行数据
taps0x:前一行数据
shift_in_dy2:第一行数据
clken_dy2:输出数据使能信号
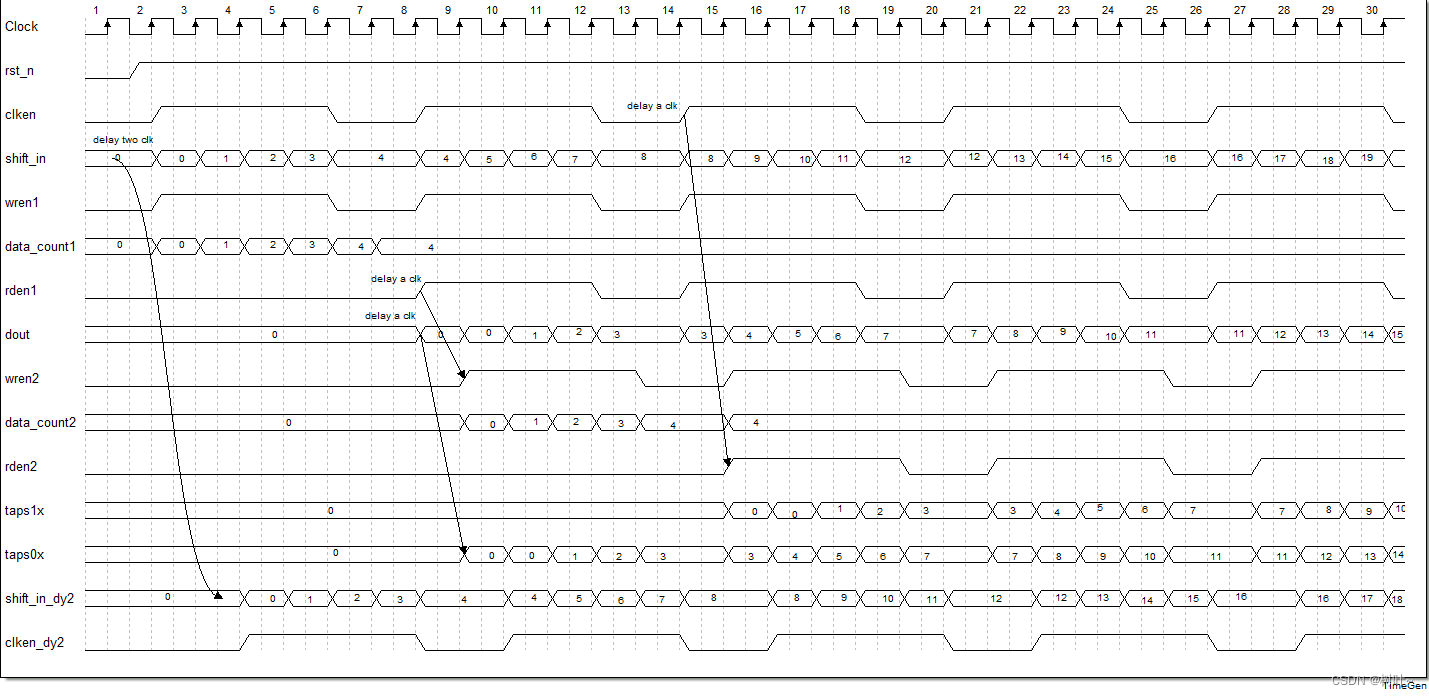
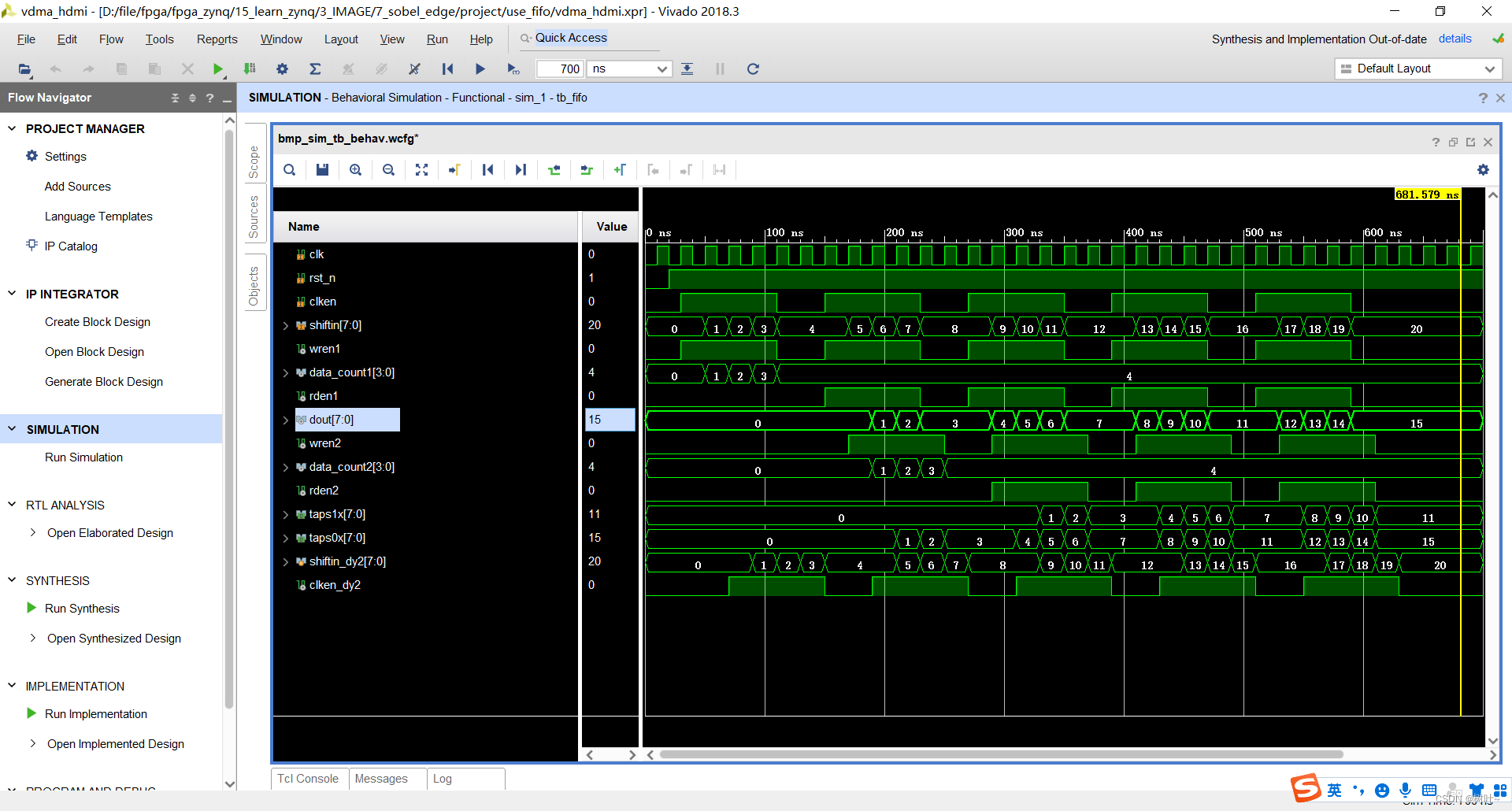
然后时序图我假设每个fifo的深度是16,然后fifo每行缓存的数据是4个。当rst_n拉高后,clken是输入数据有效时刻,shift_in是输入数据。wren1和clken同步,把数据写到fifo1,data_count1开始计数。当计数满4个且clken为高电平时,rden1拉高开始从fifo1中读出数据,dout是从fifo1中读出的数据。wren2比rden1延迟一个时钟周期拉高,将fifo1中输出的数据写入到fifo2中。这是data_count2对fifo2中数据计数。当数据满足4个并且在clken_dy(clken延迟一个周期)为高时rden2有效,将fifo2中的数据读出。shift_in_dy2将输入信号延迟两个周期,clken_dy2将clken延迟两个周期以完成输出信号的同步。
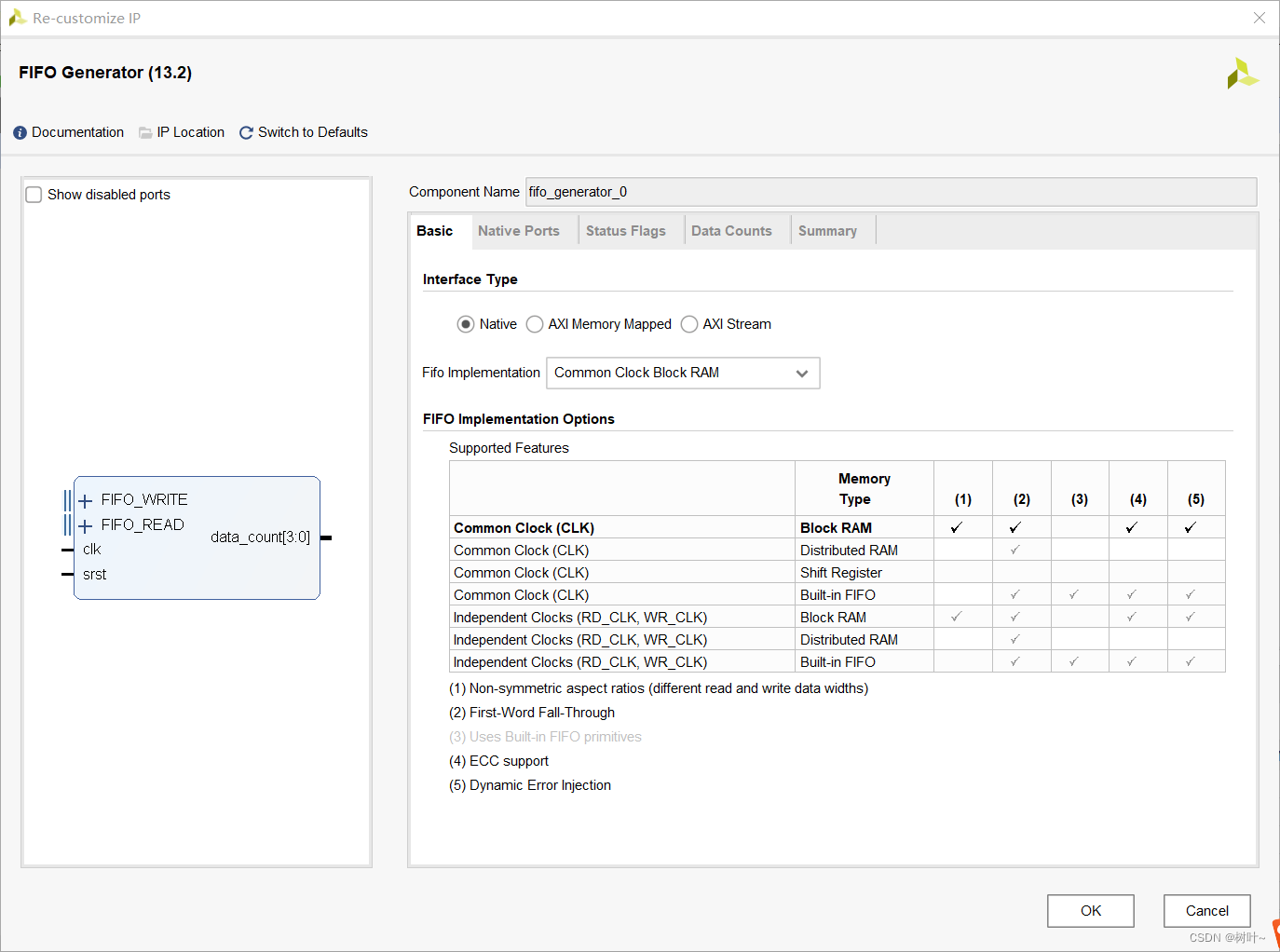
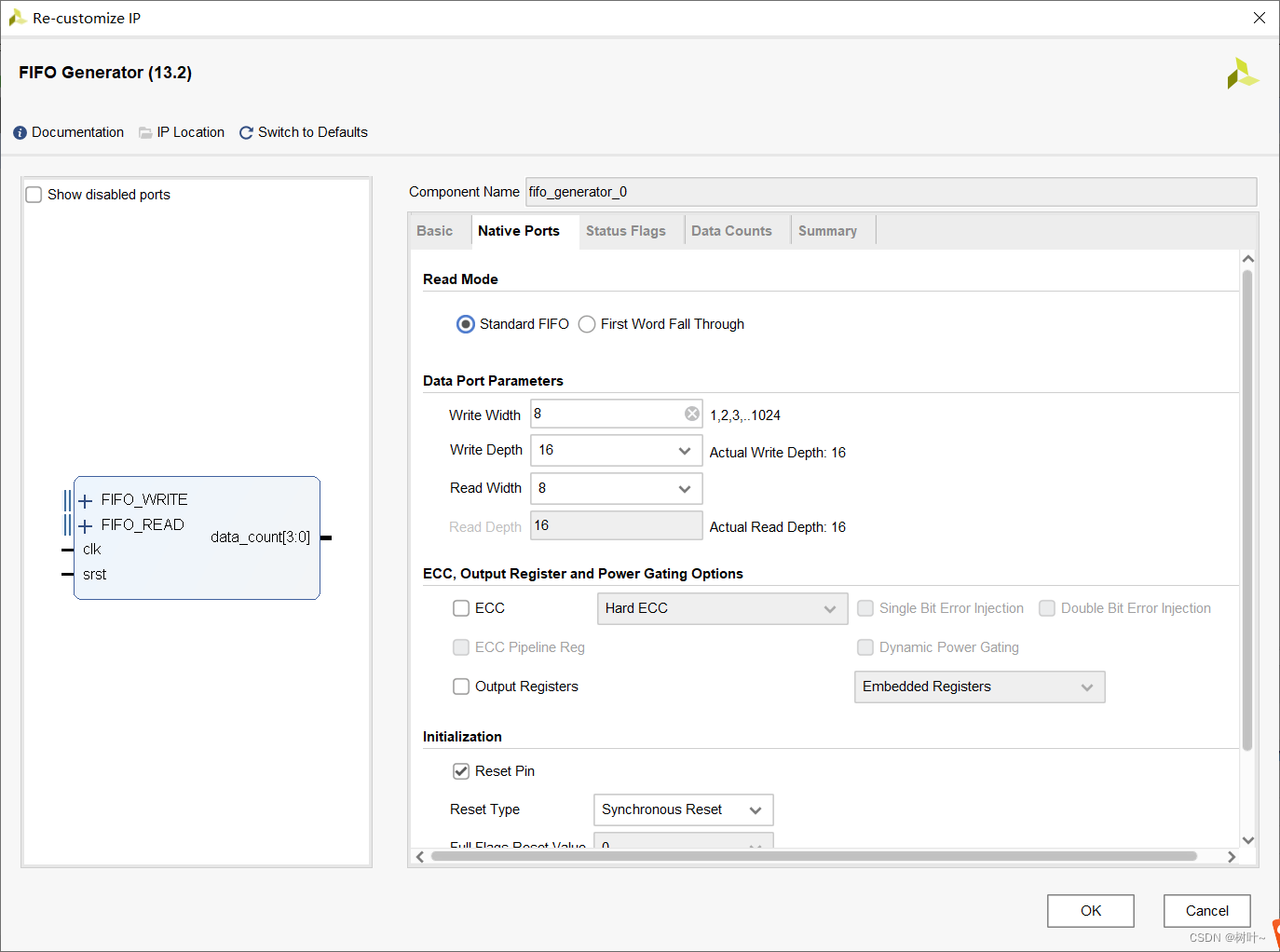
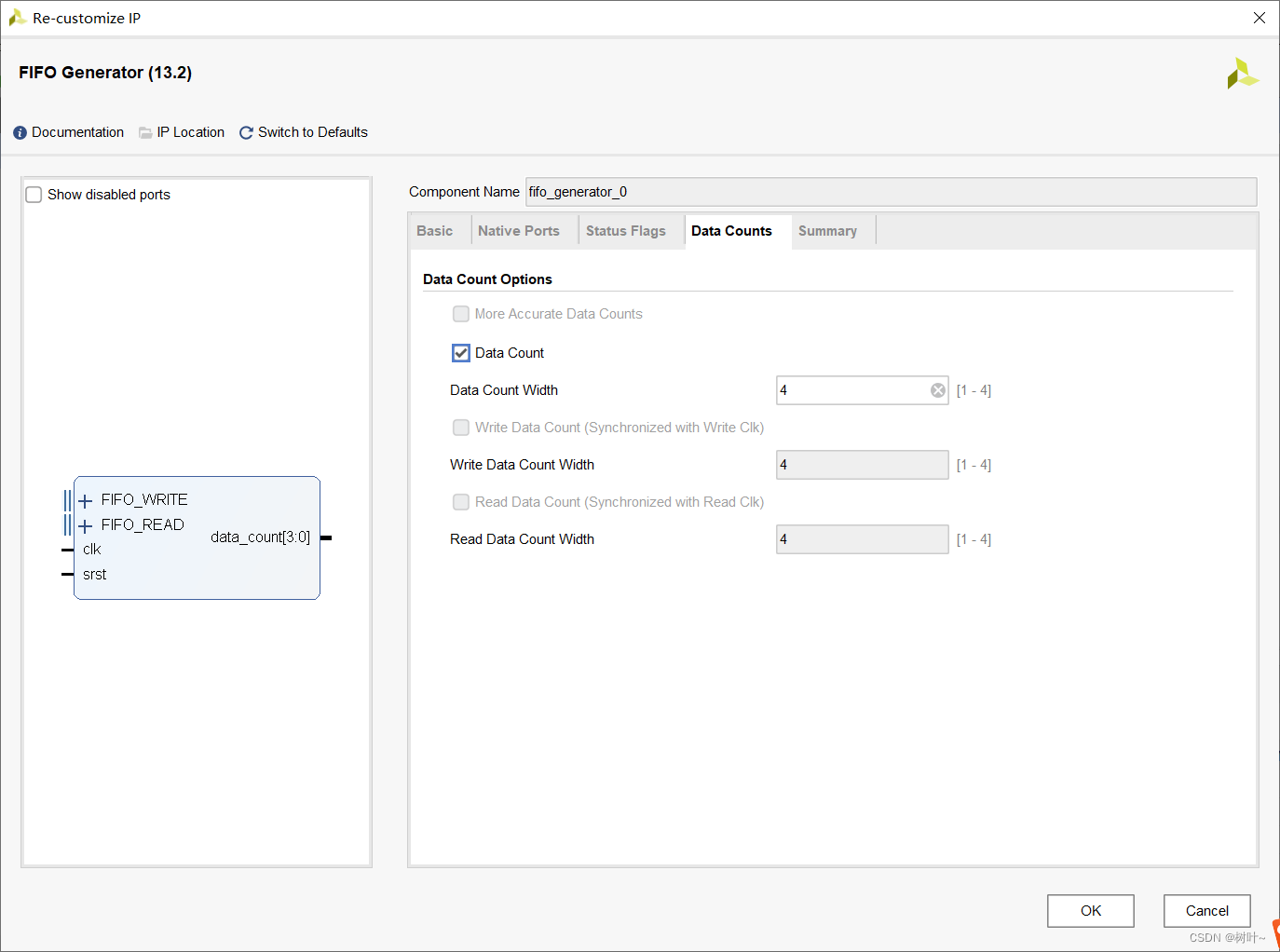
为了实现上述时序图的功能,首先需要例化一个fifo,例化过程如下图。选择同步fifo,然后设置位宽位深,打开fifo数据计数,其他默认即可。
根据时序图编写的verilog代码以及tb文件代码如下所示。
module line_shift_fifo_8bit(
input clk,
input rst_n,
input clken,
input [7:0] shiftin,
output [7:0] taps0x,
output [7:0] taps1x
);
reg clken_dy;
wire wren1;
wire rden1;
wire wren2;
reg wren2_dy;
wire rden2;
wire [7:0] dout;
reg [7:0] taps0x_dy;
wire [3:0] data_count1;
wire [3:0] data_count2;
//delay a clock, because read1 is quicker than write2
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
wren2_dy<=1'b0;
end
else wren2_dy<=rden1;
end
//delay a clock, make write2 and read 2 at same time
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
clken_dy<=1'b0;
end
else clken_dy<=clken;
end
//delay a clock, taps0x_dy
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
taps0x_dy<=8'd0;
end
else taps0x_dy<=dout;
end
assign wren1= clken;
assign rden1= clken && (data_count1==4'd4);
assign wren2= wren2_dy;
assign rden2= clken_dy && (data_count2==4'd4);
assign taps0x=taps0x_dy;
fifo_generator_0 u_fifo_generator_0 (
.clk (clk), // input wire clk
.srst (~rst_n), // input wire srst
.din (shiftin), // input wire [7 : 0] din
.wr_en (wren1), // input wire wr_en
.rd_en (rden1), // input wire rd_en
.dout (dout), // output wire [7 : 0] dout
.full (), // output wire full
.empty (), // output wire empty
.data_count (data_count1) // output wire [3 : 0] data_count
);
fifo_generator_0 u_fifo_generator_1 (
.clk (clk), // input wire clk
.srst (~rst_n), // input wire srst
.din (dout), // input wire [7 : 0] din
.wr_en (wren2), // input wire wr_en
.rd_en (rden2), // input wire rd_en
.dout (taps1x), // output wire [7 : 0] dout
.full (), // output wire full
.empty (), // output wire empty
.data_count (data_count2) // output wire [3 : 0] data_count
);
endmodule
`timescale 1ns/1ns
module tb_fifo();
reg clk;
reg rst_n;
reg clken;
reg [7:0] shiftin;
wire [7:0] taps0x;
wire [7:0] taps1x;
reg [7:0] shiftin_dy1;
reg [7:0] shiftin_dy2;
wire clken_dy2;
reg [1:0] clken_dy_two;
always #10 clk=~clk;
initial begin
clk<=1'b0;
clken<=1'b0;
rst_n<=1'b0;
#20;
rst_n<=1'b1;
end
//these has a difference between zuse and fei zuse when simulation
initial begin
#30;
clken<=1'b1;
#80;
clken<=1'b0;
#40;
clken<=1'b1;
#80;
clken<=1'b0;
#40;
clken<=1'b1;
#80;
clken<=1'b0;
#40;
clken<=1'b1;
#80;
clken<=1'b0;
#40;
clken<=1'b1;
#80;
clken<=1'b0;
end
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
shiftin<=8'd0;
end
else if(clken==1'b1)begin
shiftin<=shiftin+1'b1;
end
else shiftin<=shiftin;
end
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
clken_dy_two<=2'd0;
end
else begin
clken_dy_two<={clken_dy_two[0],clken};
end
end
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
shiftin_dy1<=8'd0;
shiftin_dy2<=8'd0;
end
else begin
shiftin_dy1<=shiftin;
shiftin_dy2<=shiftin_dy1;
end
end
assign clken_dy2=clken_dy_two[1];
line_shift_fifo_8bit u_line_shift_fifo_8bit(
.clk ( clk ),
.rst_n ( rst_n ),
.clken ( clken ),
.shiftin ( shiftin ),
.taps0x ( taps0x ),
.taps1x ( taps1x )
);
endmodule
最后给出vivado的仿真结果如下图所示。可以对比timgen的时序图和仿真的结果,是完全一致的。
我这边是使用1024×768分辨率的屏幕,所以这边缓存数量选择1024个数据,改变一下fifo的深度为2048大于1024即可,然后代码中fifo技术改变位数,其他都不需要改动。
在之前的工程中用ram实现了矩阵生成的verilog代码,这边只需要将ram ip核改成fifo实现的就可以了。另外还需要注意的是,利用ram实现的缓存是只延迟了一拍,而用fifo实现的缓存则是消耗了两拍。所以最后给矩阵的数据是总共延迟了三拍,这点与之前不同。
module VIP_matrix_generate
(
input clk,
input rst_n,
input per_frame_vsync,
input per_frame_href,
input per_frame_clken,
input [7:0] per_img_Y,
output matrix_frame_vsync,
output matrix_frame_href,
output matrix_frame_clken,
output reg [7:0] matrix_p11,
output reg [7:0] matrix_p12,
output reg [7:0] matrix_p13,
output reg [7:0] matrix_p21,
output reg [7:0] matrix_p22,
output reg [7:0] matrix_p23,
output reg [7:0] matrix_p31,
output reg [7:0] matrix_p32,
output reg [7:0] matrix_p33
);
//wire define
wire [7:0] row1_data;
wire [7:0] row2_data;
wire read_frame_href ;
wire read_frame_clken;
//reg define
reg [7:0] row3_data;
reg [7:0] row3_data_dy;
reg [2:0] per_frame_vsync_r;
reg [2:0] per_frame_href_r;
reg [2:0] per_frame_clken_r;
assign read_frame_href = per_frame_href_r[1] ;
assign read_frame_clken = per_frame_clken_r[1];
assign matrix_frame_vsync = per_frame_vsync_r[2];
assign matrix_frame_href = per_frame_href_r[2] ;
assign matrix_frame_clken = per_frame_clken_r[2];
//present signal delay 2 clk
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
row3_data_dy<= 0;
row3_data <= 0;
end
else begin
if(per_frame_clken) begin
row3_data_dy <= per_img_Y ;
row3_data <= row3_data_dy;
end
else begin
row3_data_dy<= row3_data_dy;
row3_data <= row3_data;
end
end
end
line_shift_fifo_8bit u_line_shift_fifo_8bit(
.clk ( clk ),
.rst_n ( rst_n ),
.clken ( per_frame_clken ),
.shiftin ( per_img_Y ),
.taps0x ( row2_data ),
.taps1x ( row1_data )
);
//delay 3 tclk
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
per_frame_vsync_r <= 0;
per_frame_href_r <= 0;
per_frame_clken_r <= 0;
end
else begin
per_frame_vsync_r <= { per_frame_vsync_r[1:0], per_frame_vsync };
per_frame_href_r <= { per_frame_href_r[1:0], per_frame_href };
per_frame_clken_r <= { per_frame_clken_r[1:0], per_frame_clken };
end
end
//generate the 3X3 matrix
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
{matrix_p11, matrix_p12, matrix_p13} <= 24'h0;
{matrix_p21, matrix_p22, matrix_p23} <= 24'h0;
{matrix_p31, matrix_p32, matrix_p33} <= 24'h0;
end
else if(read_frame_href) begin
if(read_frame_clken) begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13, row1_data};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23, row2_data};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33, row3_data};
end
else begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33};
end
end
else begin
{matrix_p11, matrix_p12, matrix_p13} <= 24'h0;
{matrix_p21, matrix_p22, matrix_p23} <= 24'h0;
{matrix_p31, matrix_p32, matrix_p33} <= 24'h0;
end
end
endmodule
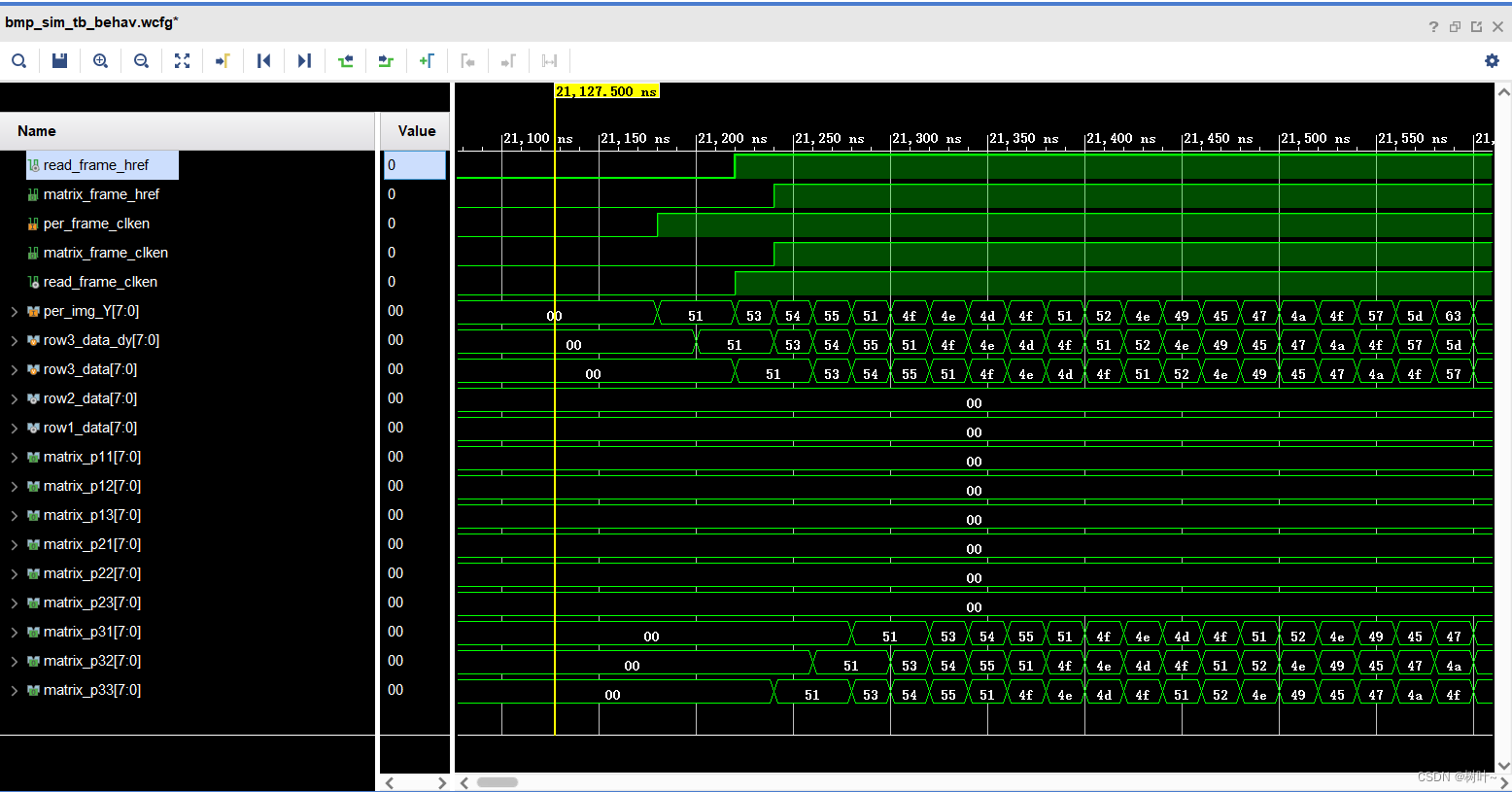
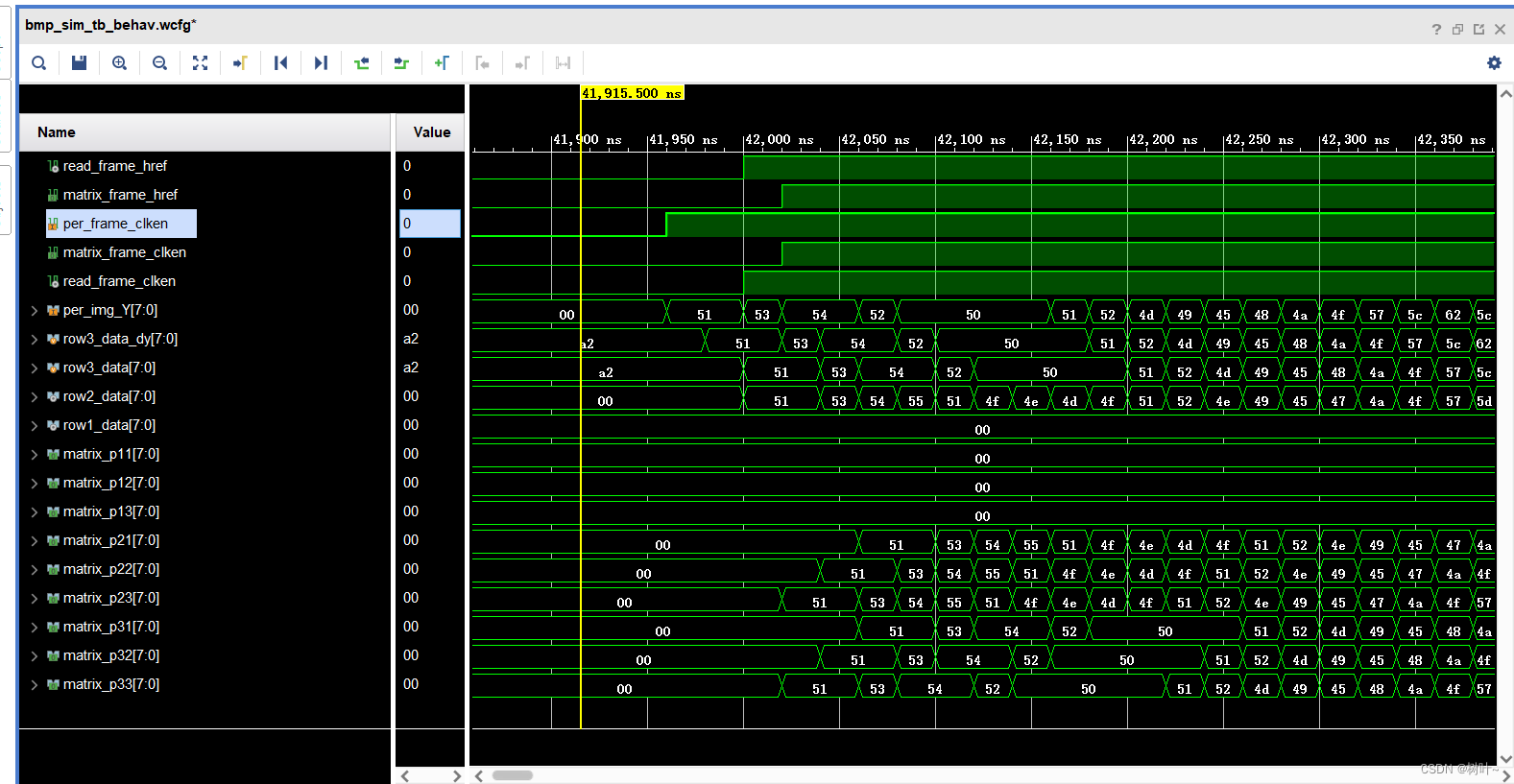
给出最后的仿真结果,可以看到数据缓存到row1、row2和row3中,之后在送到矩阵matrix中,具体细节不在阐述。
放上最后的结果图,原图是加了噪声的风景图,然后经过了rgb转灰度,sobel边缘检测后输出图像。


我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD