1.流水线编译过程,执行apk --update add --no-cache xxx
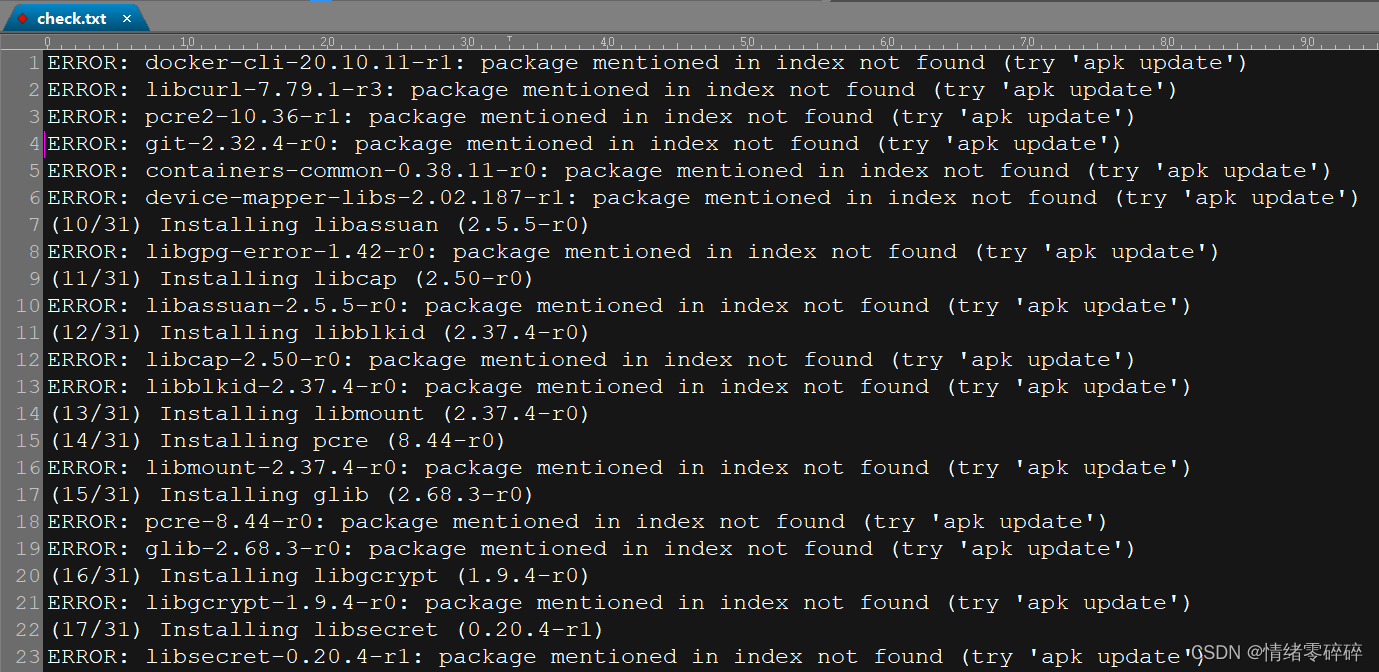
2.报错ERROR: xxx package mentioned in index not found (try 'apk update')
3.内网环境缺依赖包,需要从清华源下载对应的包,但是需要根据报错一个个找,一个个点击下载麻烦
4.一开始打算下载官网全部依赖,但是数量太大,而且频繁拉取容易反爬,改为根据报错信息存放到E:\download\check.txt,程序自动识别包名下载到对应目录
import urllib.request # url request
import re # regular expression
import os # dirs
import time
'''
url 下载网址
pattern 正则化的匹配关键词
Directory 下载目录
'''
'''
1.流水线编译过程,执行apk --update add --no-cache xxx
2.报错ERROR: xxx package mentioned in index not found (try 'apk update')
3.内网环境缺依赖包,需要从清华源下载对应的包,但是需要根据报错一个个找,一个个点击下载麻烦
4.一开始打算下载官网全部依赖,但是数量太大,而且频繁拉取容易反爬,改为根据报错信息存放到E:\download\check.txt,程序自动识别包名下载到对应目录
'''
def BatchDownload(url, pattern, Directory):
# 拉动请求,模拟成浏览器去访问网站->跳过反爬虫机制
headers = {'User-Agent',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'}
opener = urllib.request.build_opener()
opener.addheaders = [headers]
# 官网下载打开注释,获取网页内容
# content = opener.open(url).read().decode('utf8')
# 根据报错内容直接查询,官网下载注释
with open("E:\download\check.txt", "r") as f: # 打开文件
content = f.readlines() # 读取文件
content = str(content) # 转化为str方便正则匹配
content = content.replace(': ', '') # 利用两头字符串卡住关键词
# 构造正则表达式,从content中匹配关键词pattern
raw_hrefs = re.findall(pattern, content, 0)
# 官网下载打开注释,set函数消除重复元素
# list方便遍历,set去重,看情况选择
# hset = list(raw_hrefs)
# 创建本地文件夹存放依赖包,看情况选择
dir_name = 'E:\download\main'
if not os.path.isdir(dir_name):
os.makedirs(dir_name)
dir_name2 = 'E:\download\community'
if not os.path.isdir(dir_name2):
os.makedirs(dir_name2)
# 下载链接
for href in raw_hrefs:
# 之所以if else 是为了区别只有一个链接的特别情况
if (len(raw_hrefs) > 1):
# realhref = href.replace('href="', '') # 官网直接拉才有href字段
realhref = href.replace('ERROR', '').replace('package', '')
# main
link = url + realhref + '.apk'
filename = os.path.join(Directory, realhref + '.apk')
# community
url2 = "http://mirrors.tuna.tsinghua.edu.cn/alpine/v3.14/community/aarch64/"
link2 = url2 + realhref + '.apk'
Directory2 = 'E:\download\community'
filename2 = os.path.join(Directory2, realhref + '.apk')
# 因为依赖包下载地址不唯一,找不到依赖尝试其他地址
try:
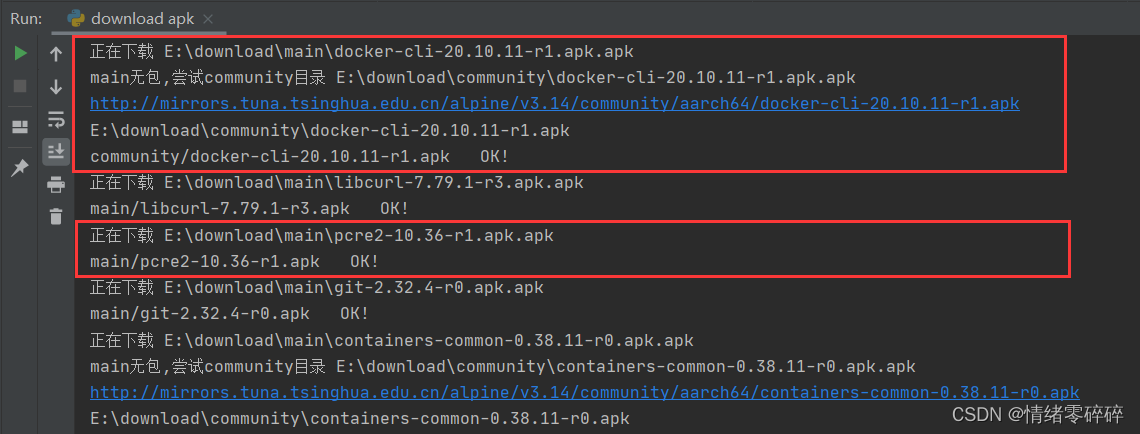
print("正在下载", filename + '.apk')
urllib.request.urlretrieve(link, filename)
except IOError:
print("main无包,尝试community目录", filename2 + '.apk')
urllib.request.urlretrieve(link2, filename2)
print("community/" + realhref + ".apk" + " OK!")
else:
print("main/" + realhref + ".apk" + " OK!")
else:
link = url + href
filename = os.path.join(Directory, href)
print("正在下载", filename + '.apk')
urllib.request.urlretrieve(link, filename)
print("成功下载!")
# 无sleep间隔,网站认定这种行为是攻击,反反爬虫
time.sleep(1)
# 官网直接下载全部依赖
# BatchDownload('https://mirrors.tuna.tsinghua.edu.cn/alpine/v3.14/community/aarch64/',r'\bhref\S*?.apk\b','E:\download')
# 根据缺包提示下载对应的依赖
BatchDownload('http://mirrors.tuna.tsinghua.edu.cn/alpine/v3.14/main/aarch64/', r'\bERROR\S*?package\b', 'E:\download\main')
支持将缺少依赖的报错信息存放到E:\download\check.txt,脚本会根据正则自动匹配包名(类似skopeo-1.3.1-r2.apk)下载到对应目录E:\download\xxx\
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht