目录
三、DBeaver 连接clickhouse 用csv文件导入数据
ClickHouse是近年来备受关注的开源列式数据库(DBMS),主要用于数据联机分析(OLAP)领域,于2016年开源。
端口问题,HTTP协议(默认端口8123);TCP (Native)协议(默认端口号为9000),Python里的clickhouse_driver用的tcp端口9000,DBeaver使用的是HTTP协议所以可以使用8123端口。
(1)我们首先需要安装第三方库clickhouse_driver,

(2)完整代码:使用clickhouse_driver 包中的Client类,其中需要修改的参数有host,user,password,
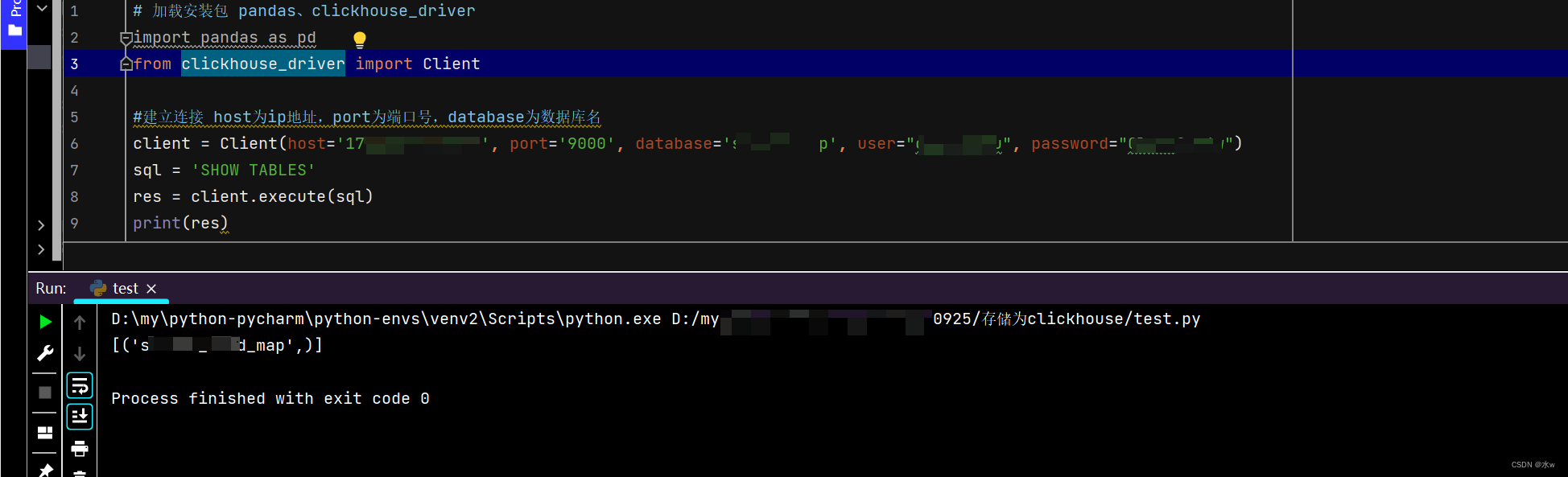
from clickhouse_driver import Client
client = Client(host='127.0.0.1',port='9000',user=clickhouse_user ,password=clickhouse_pwd)
sql = 'select * from db_name.tb_name limit 0, 1000'
ans = client.execute(sql)
前提:Clickhouse客户端工具为dbeaver,首先需要安装连接工具Dbeaver。
Dbeaver安装教程地址:DBeaver安装与使用教程(超详细安装与使用教程)_多喝清晨的粥的博客-CSDN博客_dbeaver安装配置
(1)打开Dbeaver,通过操作界面菜单中“数据库”创建配置新连接,如下图所示,选择并下载ClickHouse驱动(默认不带驱动),
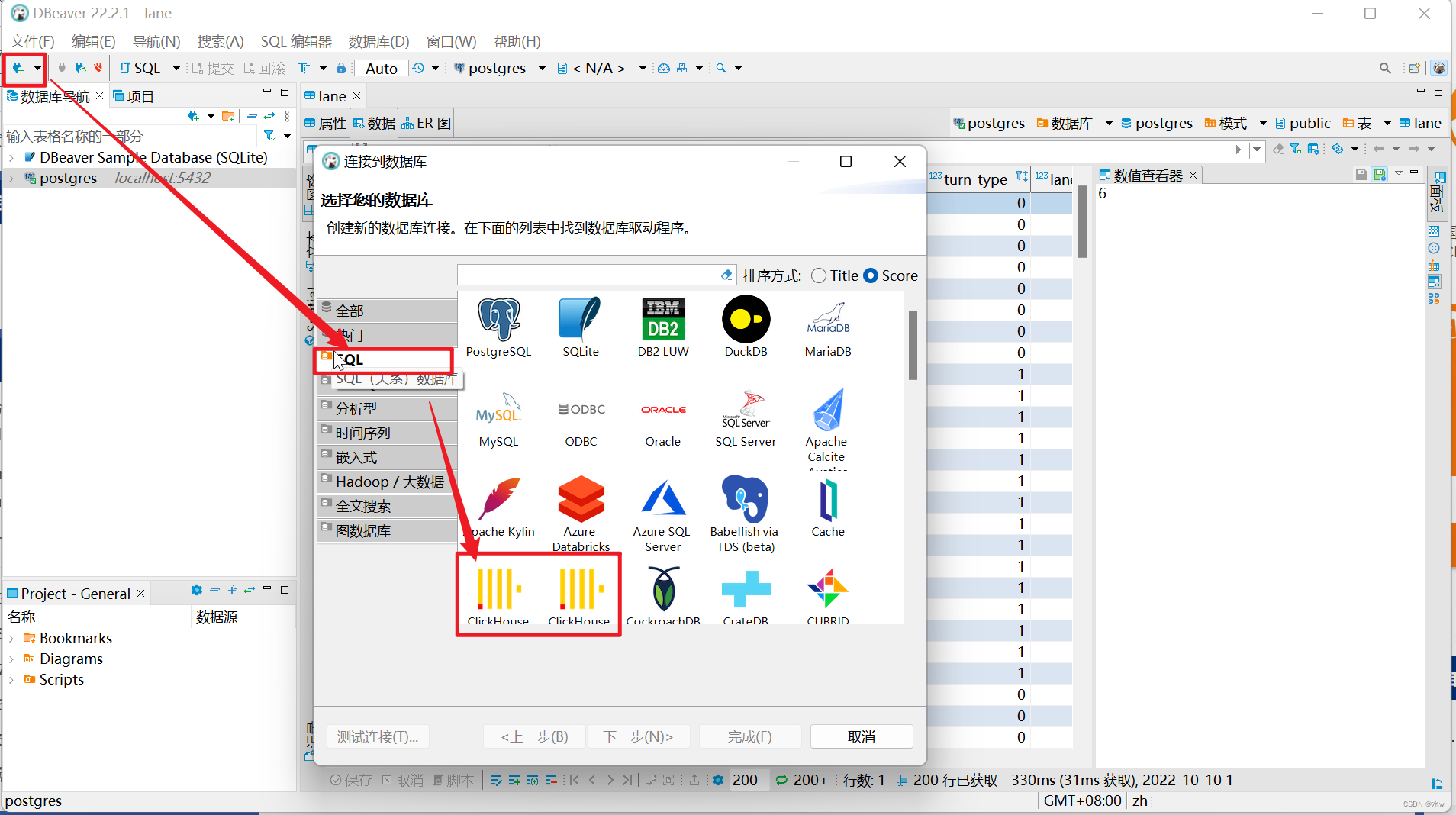
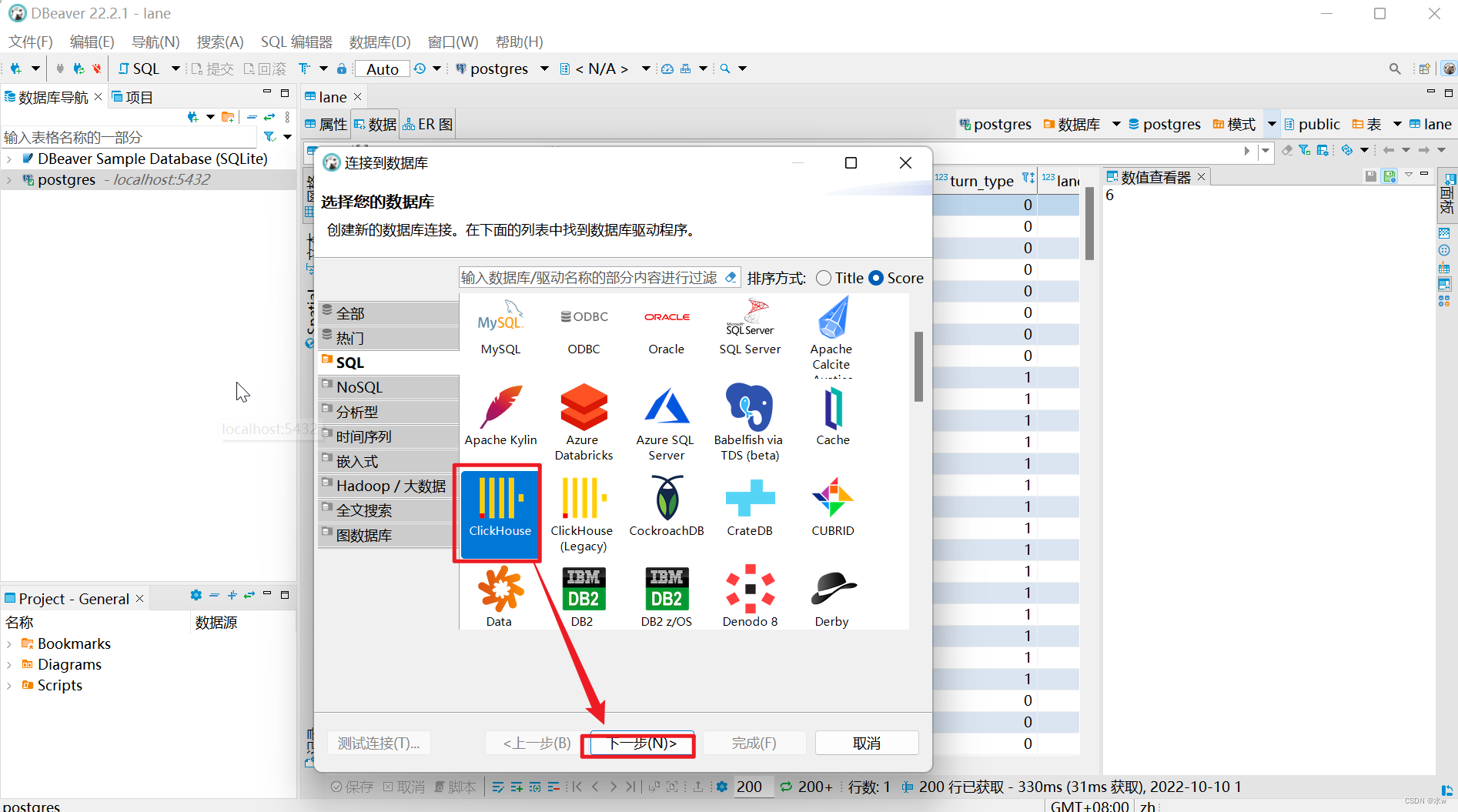
(2)填写基础配置
DBeaver配置是基于Jdbc方式,一般默认URL和端口如下:
jdbc:clickhouse://192.168.17.61:8123
如下图所示。在是用DBeaver连接Clickhouse做查询时,有时候会出现连接或查询超时的情况,这个时候可以在连接的参数中添加设置socket_timeout参数来解决问题。
jdbc:clickhouse://{host}:{port}[/{database}]?socket_timeout=600000
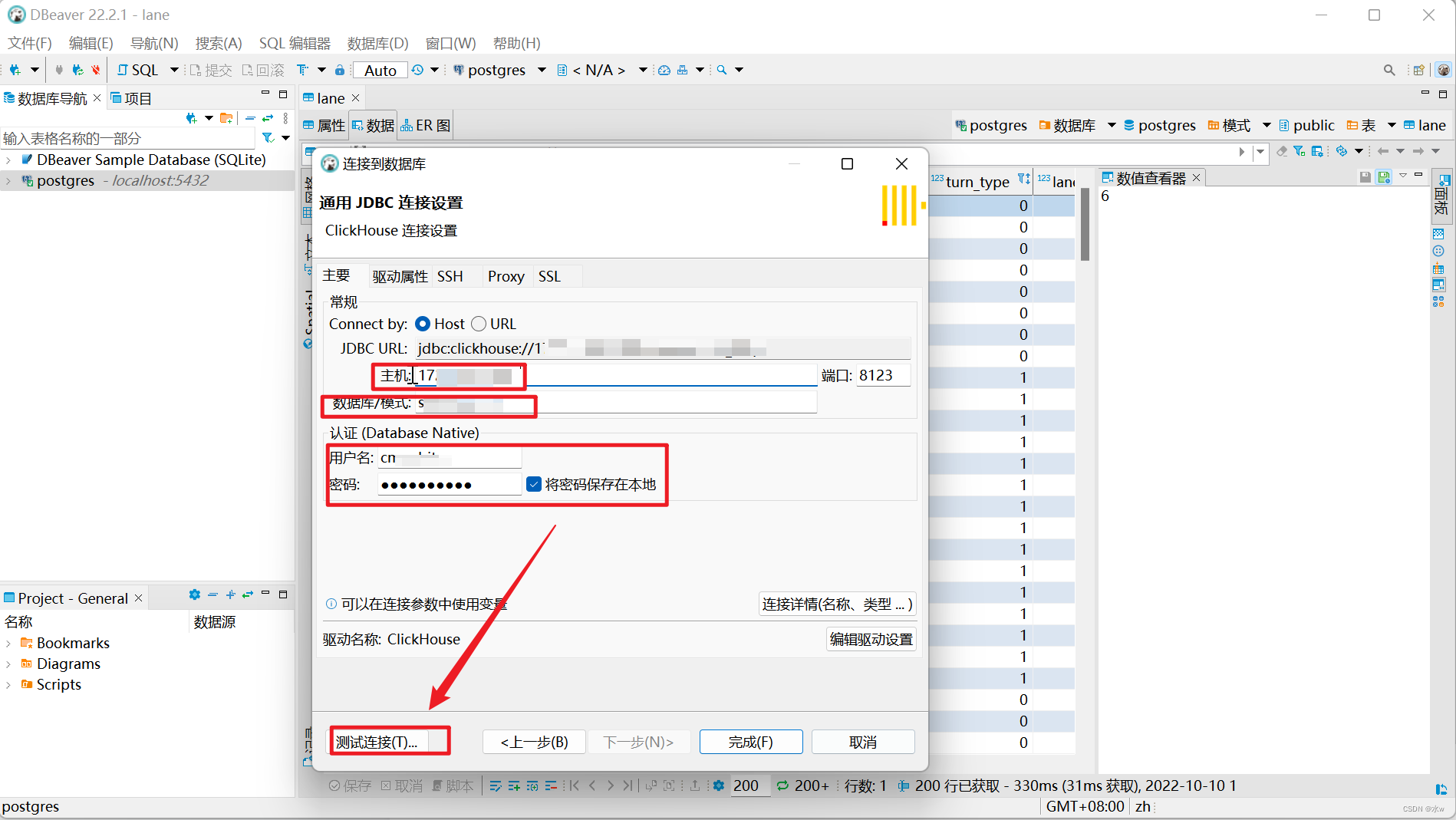
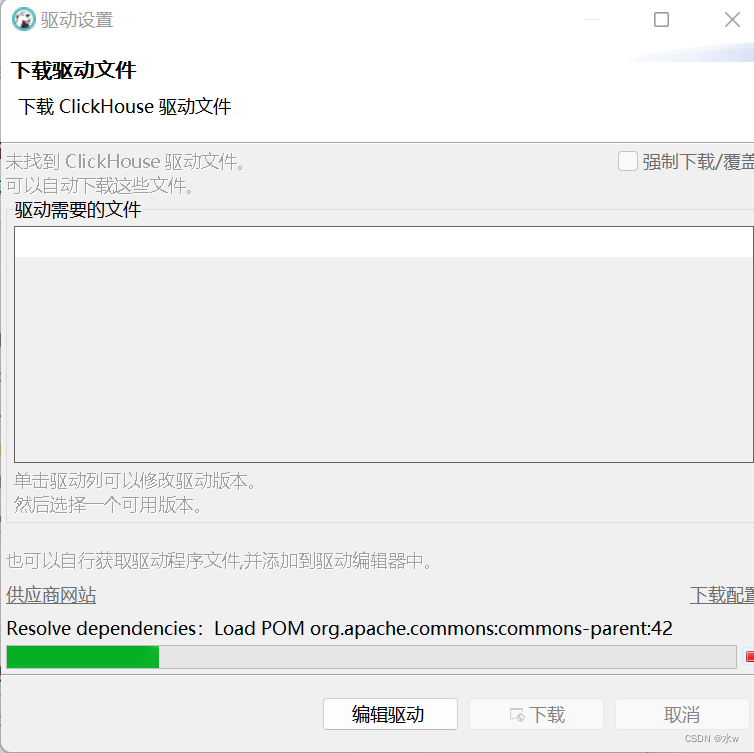
(3)测试连接,提示未安装驱动
到了这一步,说明连接配置信息填写完成,在弹出来的地方选择下载按钮,等它全部下载完驱动后即可测试连接。
如下图所示,开始下载驱动文件:
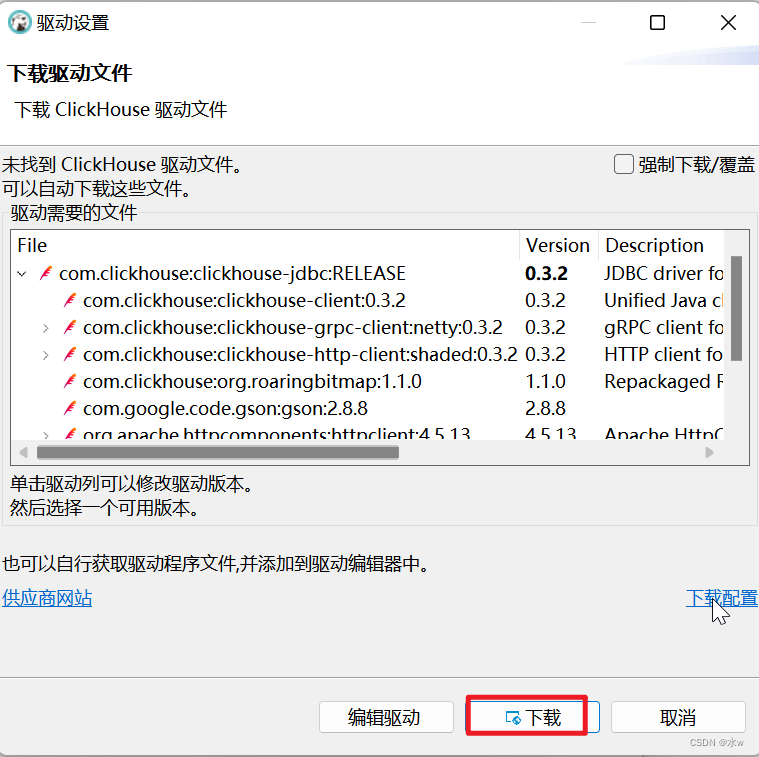
点击“下载”,
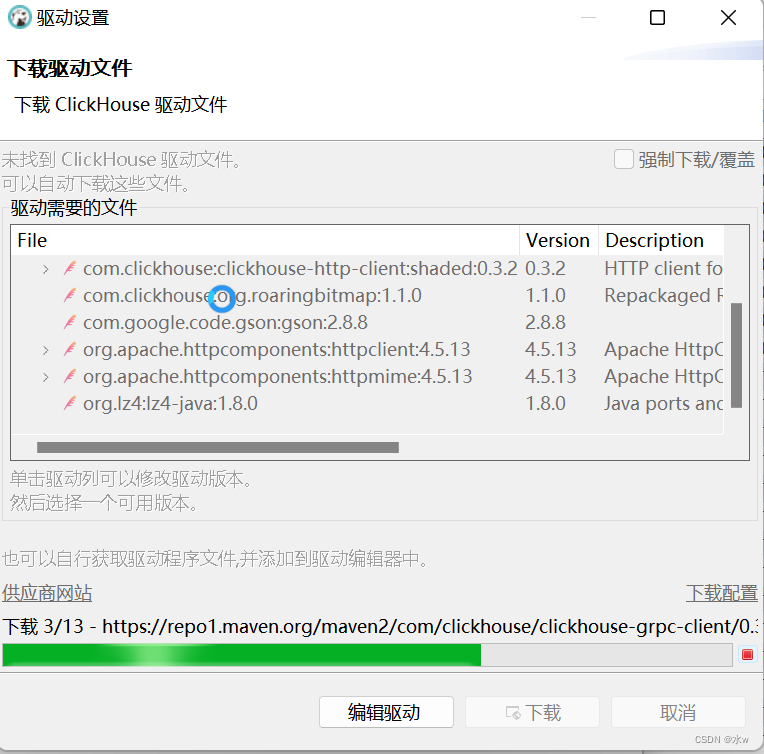
等待下载完成,
(4)再次测试连接,连接成功,
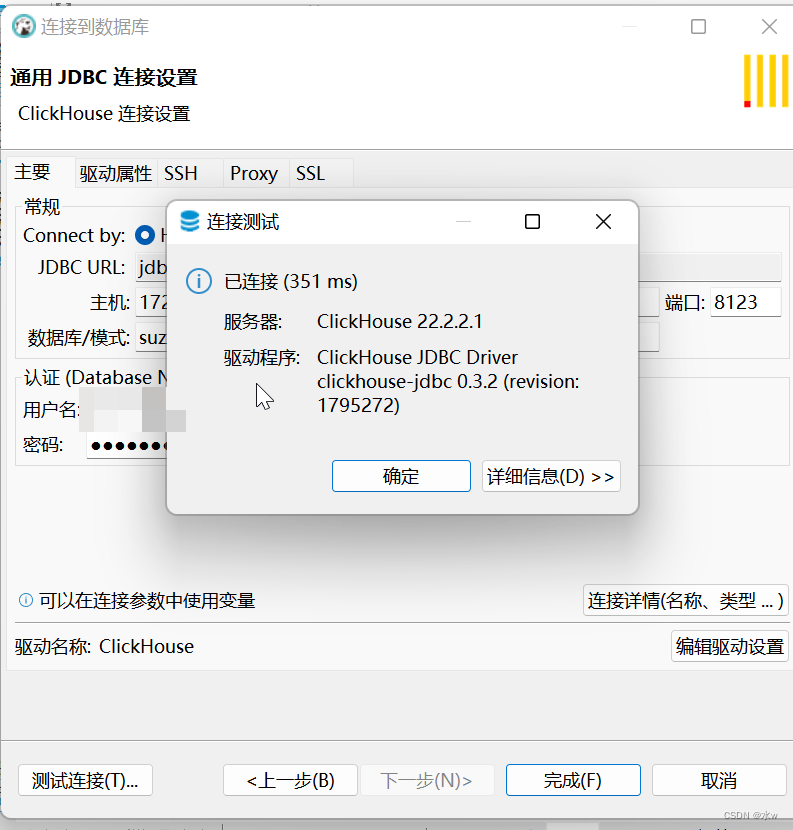
可以看到已经成功连接到了Clickhouse。
(1)右击,选择“新建列”,进行创建表,
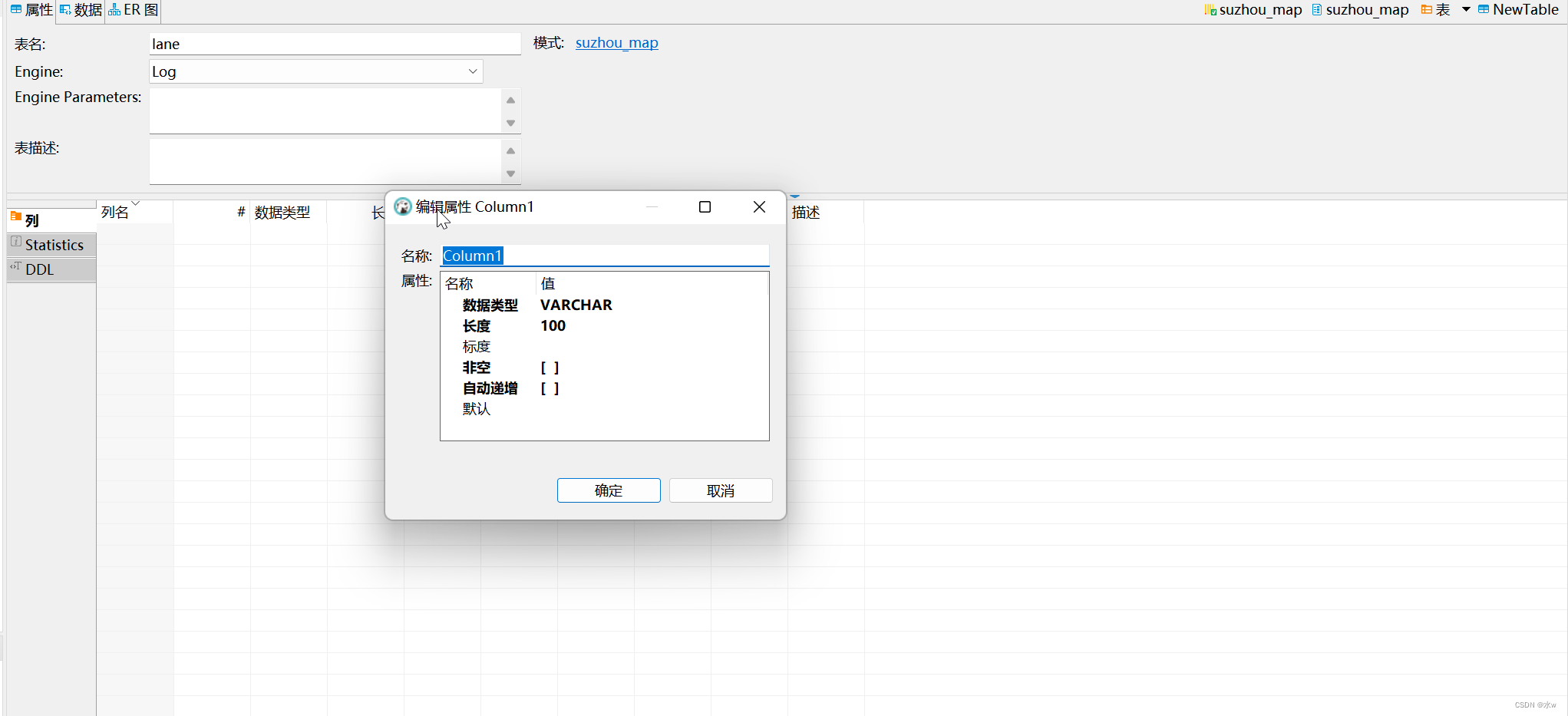
(2)或者使用代码进行创建表,
在sql编辑器中写入想要创建的表结构代码,
CREATE TABLE table_name (
node_id Int128,
node_name VARCHAR(100),
ll Int16,
ink VARCHAR(500),
onk VARCHAR(500),
fne VARCHAR(500),
tne VARCHAR(500)
) Engine = MergeTree()
ORDER BY node_id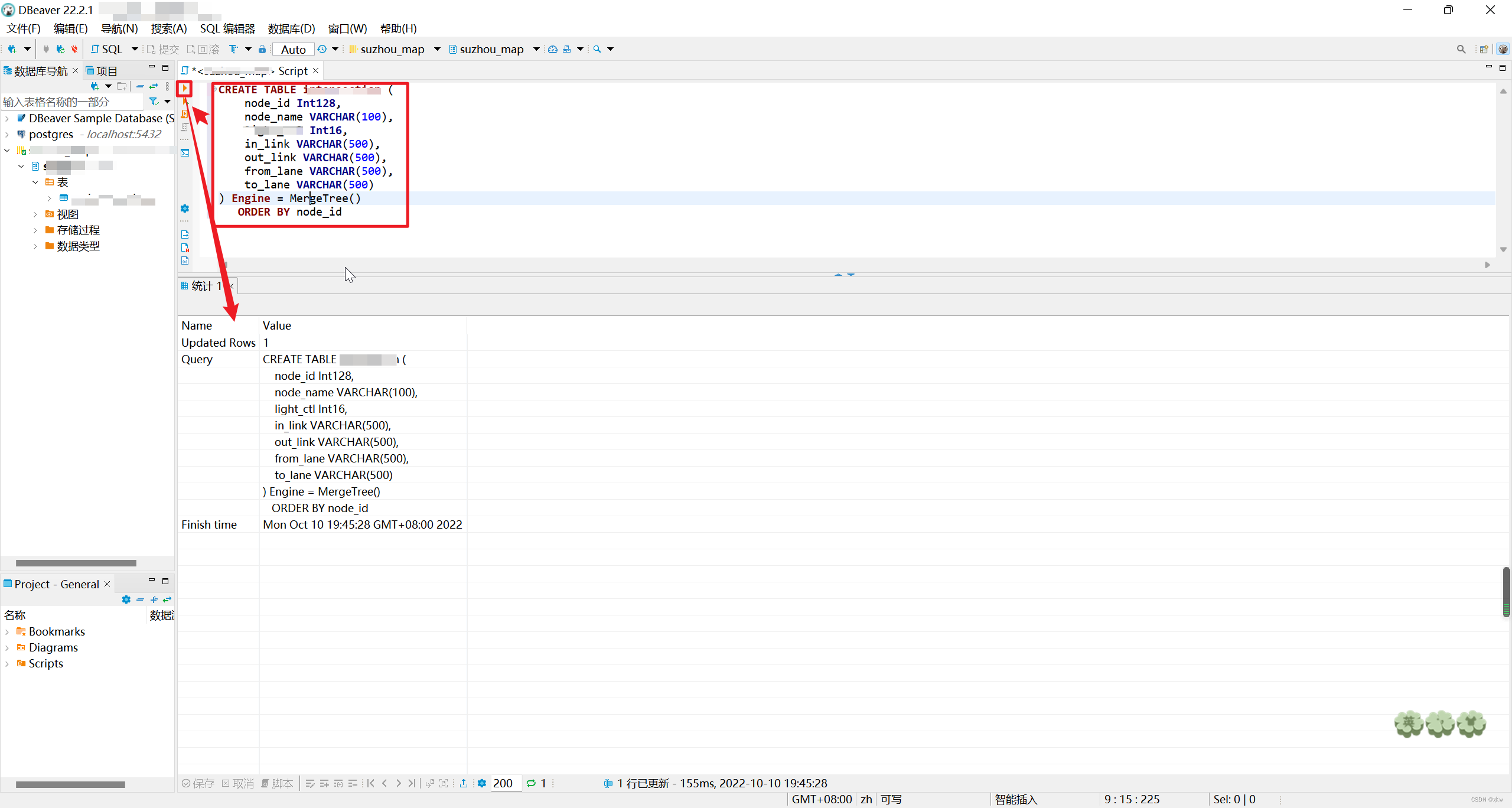
这样表就创建好了。
(1)先再需要导入的数据表中 插入几条数据 然后 导出 csv 格式的数据。【目的是为了查看导出的cxv 的数据是是什么格式, 我们导入也按照这个格式导入】
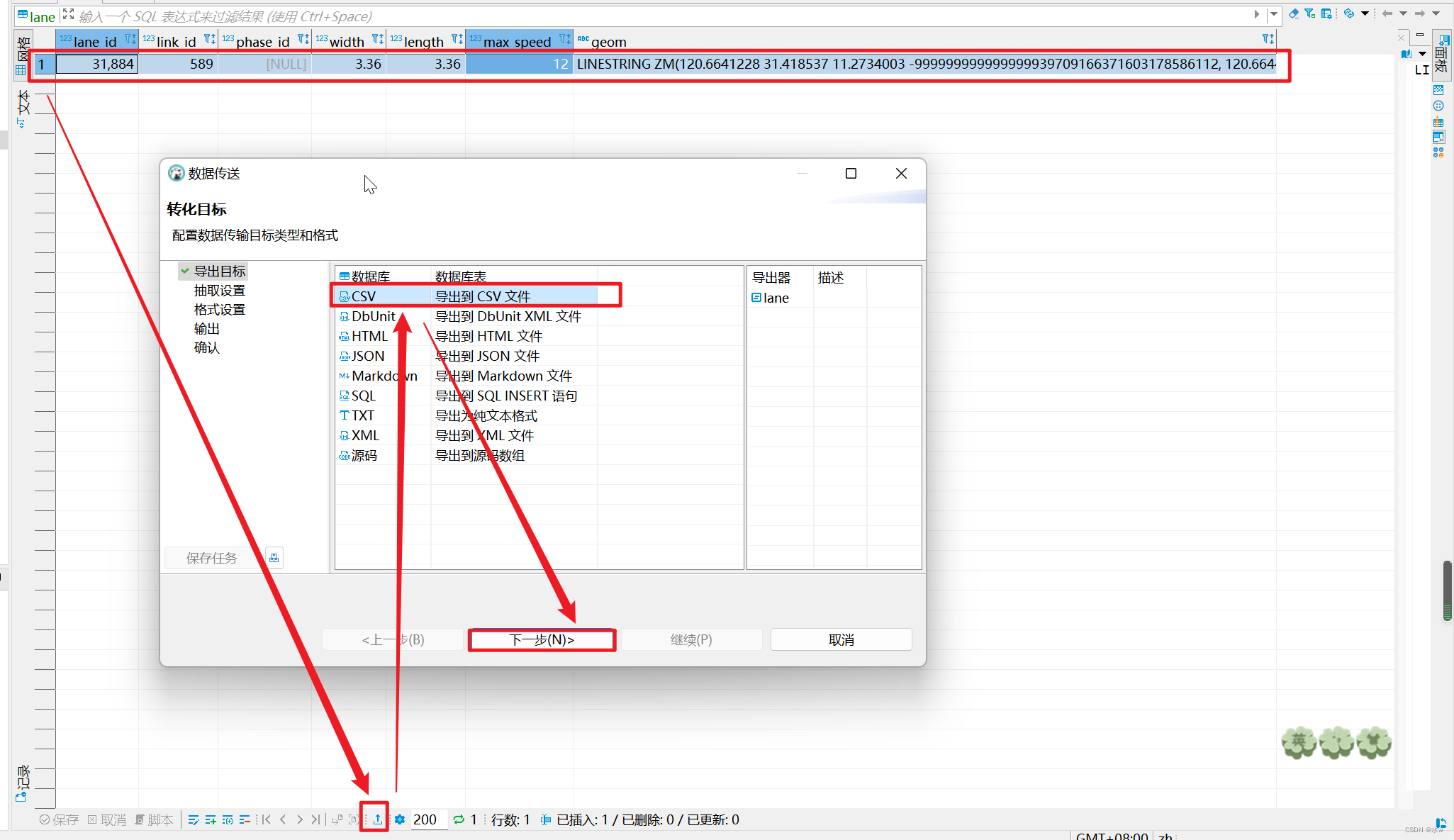
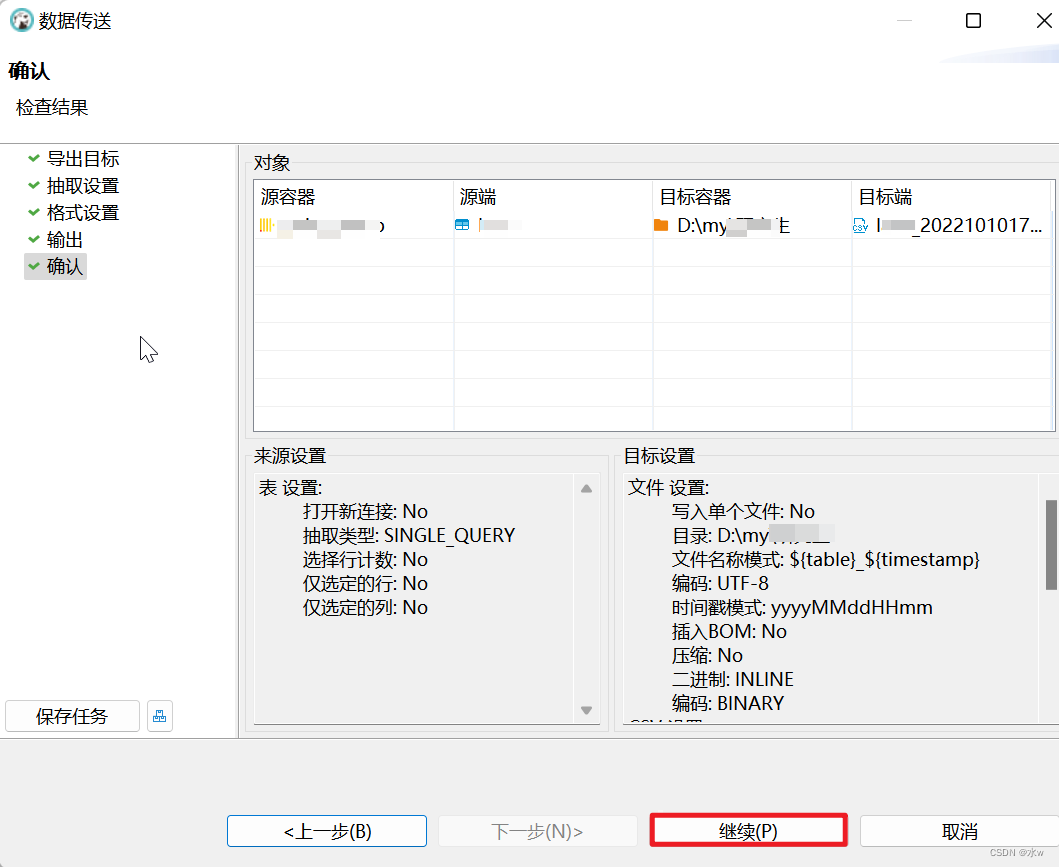
(2)再导出的表格中 加入我们需要导入的数据,格式和导出的数据格式保持一致。

(3)然后 通过csv 的方式导入数据到数据库表。
右击需要导入csv文件的表,选择“导入数据”,依次进行一下步骤,
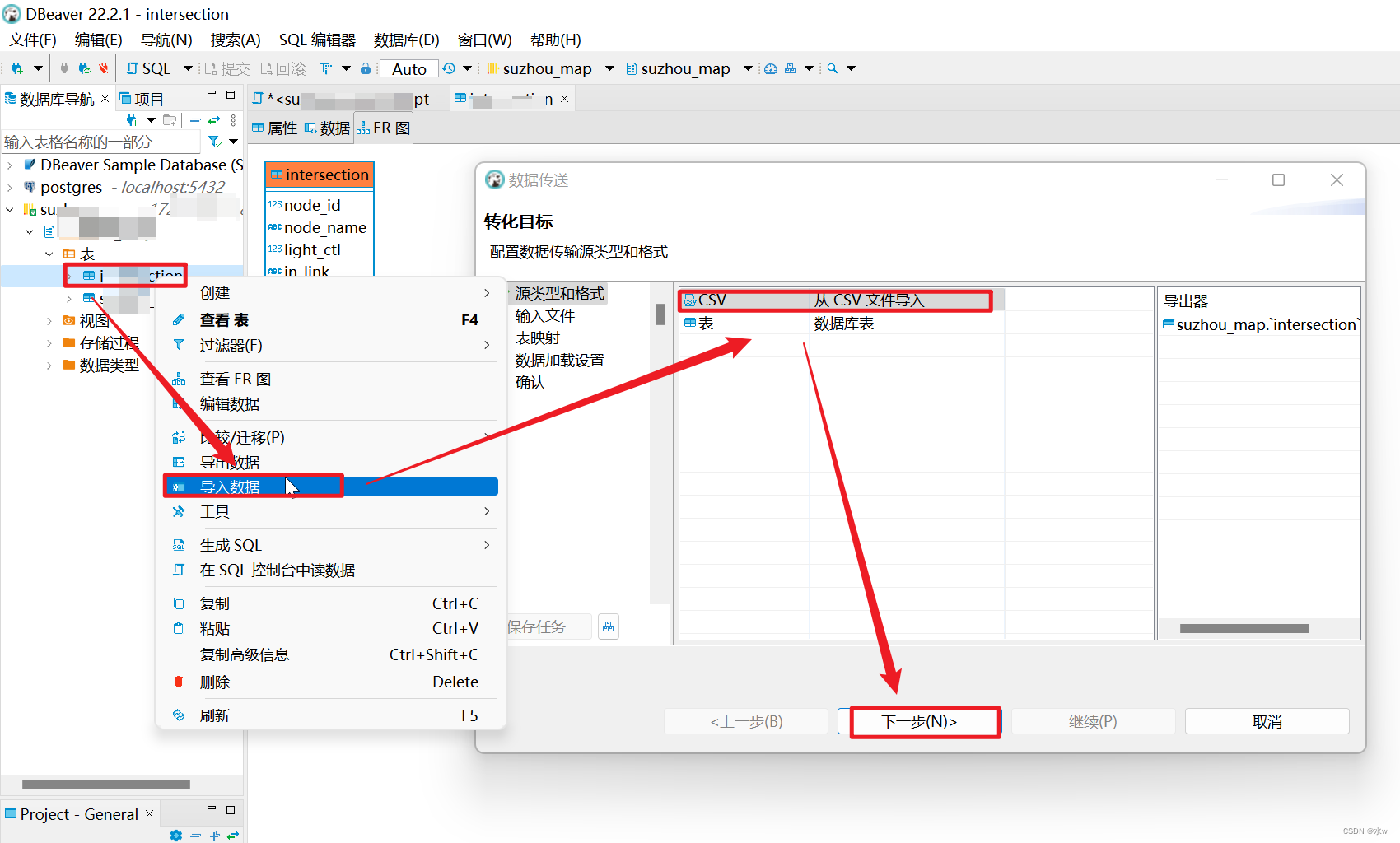
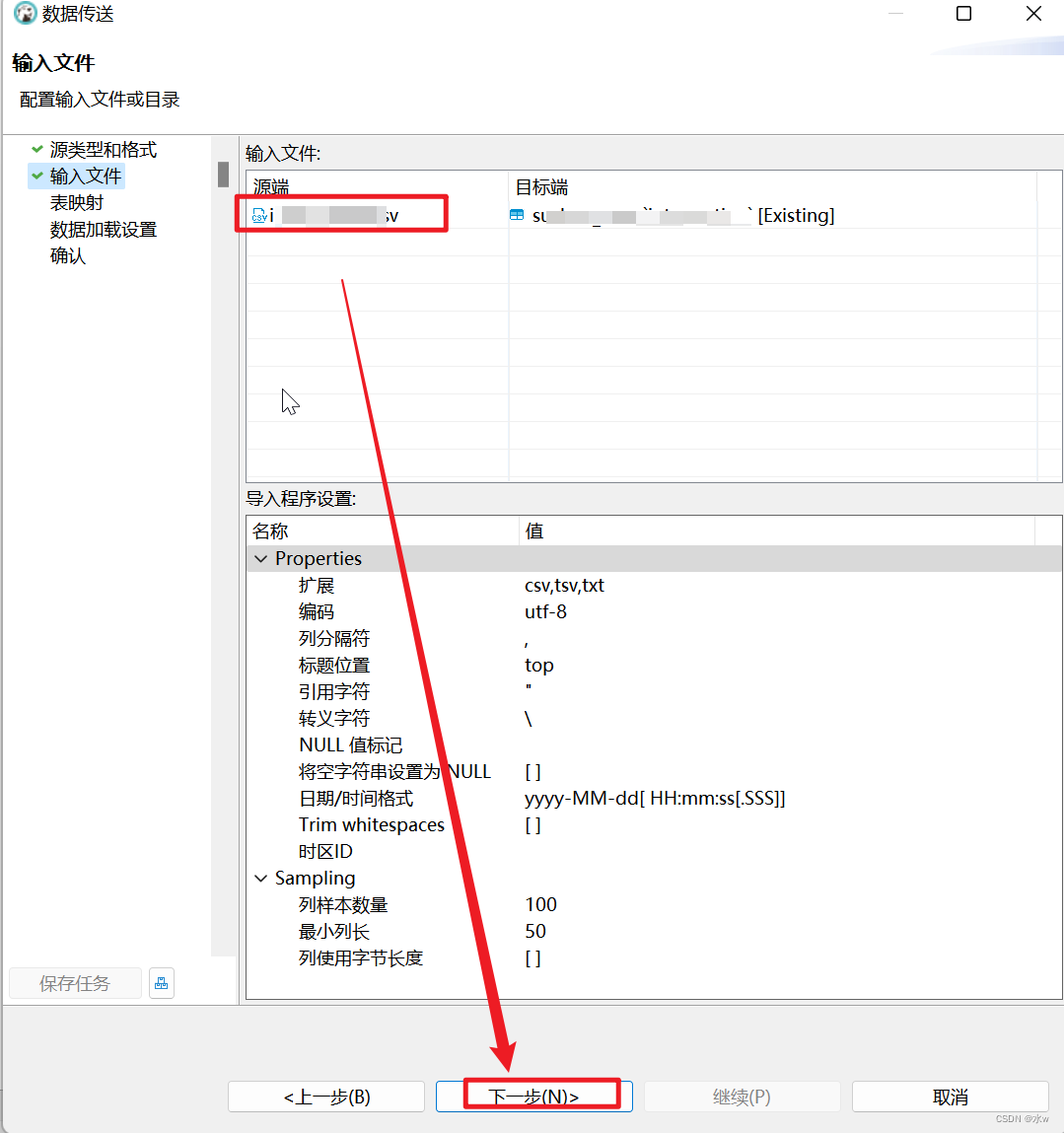
导入数据成功了。
clickhouse-client --databse="testdb" --query="INSERT INTO testdb.TEST_table FORMAT CSV" < /dataset/data.csv若出现问题,可以试一下 将FORMAT CSV 改为 FORMAT CSVWithNames
解决方法:将csv 表格文件用记事本打开 另存为的方式 保存新的文件 ,编码格式选择为为UTF-8 然后保存。 然后从新的修改编码格式之后的文件导入数据库表格, 中文乱码的问题就解决了。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
CSV.open(name,"r").eachdo|row|putsrowend我得到以下错误:CSV::MalformedCSVErrorUnquotedfieldsdonotallow\ror\n文件名是一个.txt制表符分隔文件。我是专门做的。我有一个.csv文件,我转到excel,并将文件保存为.txt制表符分隔的文件。所以它是制表符分隔的。CSV.open不应该能够读取制表符分隔的文件吗? 最佳答案 尝试像这样指定字段分隔符:CSV.open("name","r",{:col_sep=>"\t"}).eachdo|row|
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳