最近在linux下搭建了一套ELK环境,ELK简单来说,ElasticSearch 作为搜索引擎存储数据,Logstash 负责收集数据并输出给ElasticSearch ,Kibana 可以理解为elasticsearch的显示面板。
本文搭建的ELK环境,主要用来收集应用系统的日志,是单机版;如果想升级成集群版,可以将ElasticSearch 部署成集群,哪个服务器需要采集数据就安装Logstash, 显示面板Kibana可以只安装在一个服务器节点即可。
由于ElasticSearch 需要 JDK 环境,所以要提前安装好 JDK 。另外,可能jdk的安装路径各有不同,所以可以提前给jdk建立一个软连接 (否则elasticSearch启动时会报错)。
which java

如果结果不是上图显示,可以执行一下命令
ln -s 执行which java所显示的路径 /usr/bin/java
通常 ElasticSearch 及kibana 都是不用root去启动的,所以这里创建一个新用户 ES。
useradd es
passwd es
创建完用户之后,要对其进行授权。下面的 elk安装 ,我专门建了一个 文件夹,然后将该文件夹授权给ES用户,如果操作过程中不小心忘了赋权限,执行不了启动命令,就再授权一下。
[root@ELK-slave home]# cd /usr/local/
[root@ELK-slave local]# mkdir elk
[root@ELK-slave local]# chown -R es:es /usr/local/elk
下面进行安装 ,注意一点,3个软件这里都是通过安装包进行部署的,要注意版本的一致性。下面安装时,可切换到 es用户。
在 /usr/local/elk/ 下建立 es文件夹,下载安装包,并解压
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz

解压完成后,修改配置文件。配置中要指定数据和日志路径,所以我提前建好文件夹。

修改config目录下的elasticsearch.yml文件,加入以下内容(单机配置)
cluster.name: es
node.name: node-1
path.data: /usr/local/elk/es/data
path.logs: /usr/local/elk/es/log
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.179.129"]
cluster.initial_master_nodes: ["node-1"]
http.cors.enabled: true
http.cors.allow-origin: "*"
配置完成后,执行启动命令
nohup ./elasticsearch > /usr/local/elk/es/run.log 2>&1 &

查看运行日志,并访问对应的链接,http://192.168.179.129:9200/
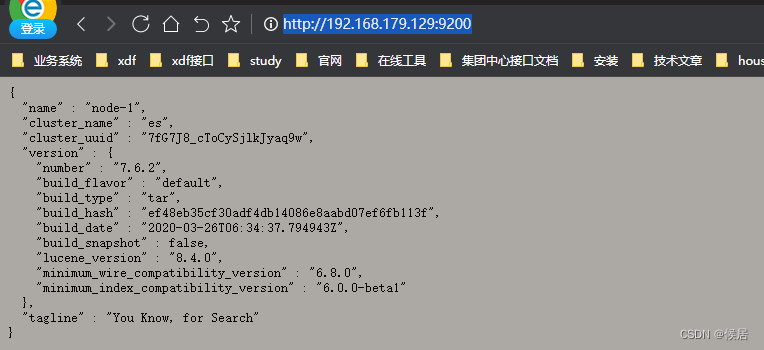
到这里,就启动成功了。
其实在启动时,可能会报虚拟内存不足、最大文件数太小等问题,所以如果启动失败,可以进行以下配置
1.切换root用户 ,编辑 limits.conf (vi /etc/security/limits.conf),末尾加入以下内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
2.切换root用户,修改 sysctl.conf (vi /etc/sysctl.conf),加入如下配置
vm.max_map_count=655360
并执行以下命令,使配置生效。
sysctl -p
完成上述配置后,切换到es用户,重新启动。
在 /usr/local/elk/ 下建立 logstash文件夹,下载安装包,并解压
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.6.2.tar.gz

logstash通过 input采集数据,output 输出数据,并且支持过滤功能。输入、输出都支持多种插件,如标准输入、文件输入、kafka 等,输出包括 elasticsearch 、文件,kafka等等。
为方便,先使用 标准输入输出查看下效果,进入bin目录,执行以下命令
./logstash -e 'input { stdin{} } output { stdout{} }'
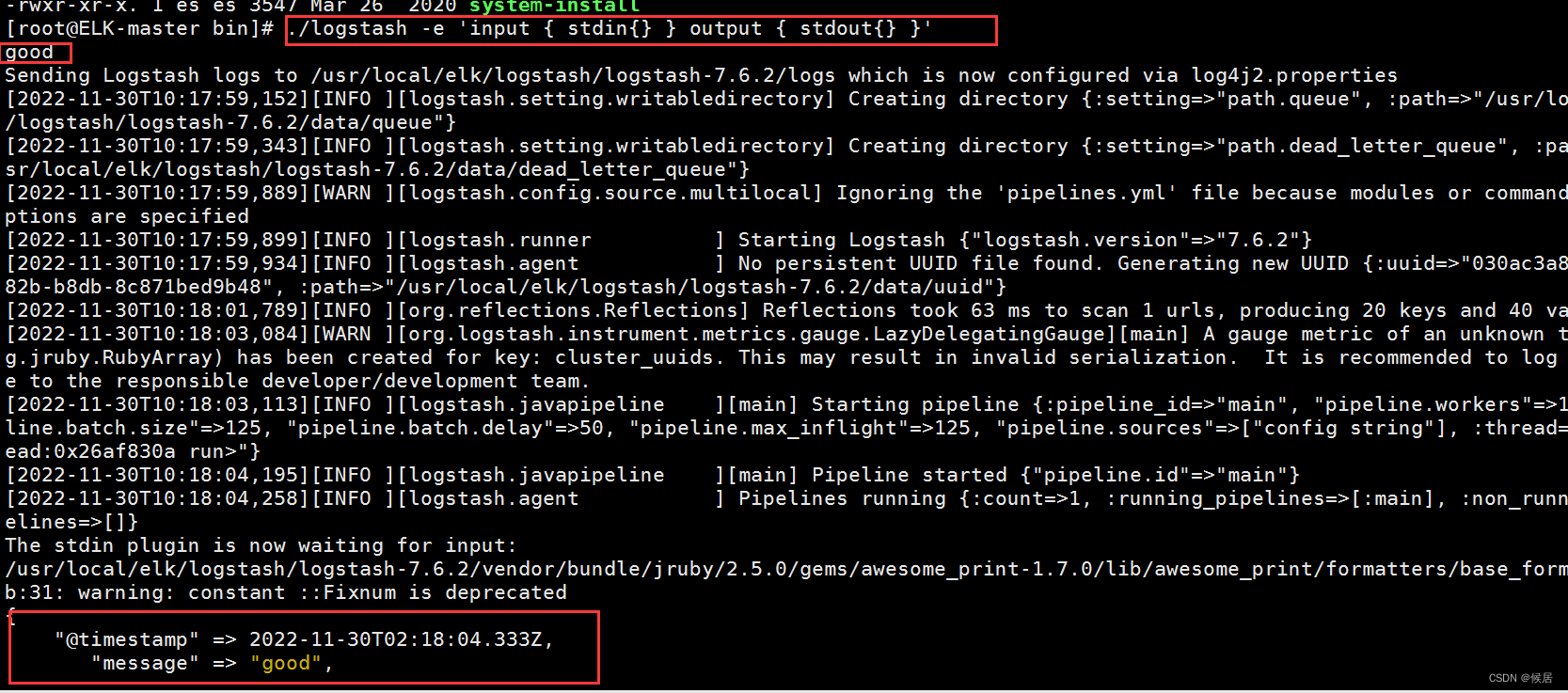
我们的目的是输出到 elasticsearch ,所以使用 标准输入,并输出到 elasticsearch 再测试一下
./logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.179.129:9200"] } }'
输入字符,然后查看对应的elasticsearch中是否存在

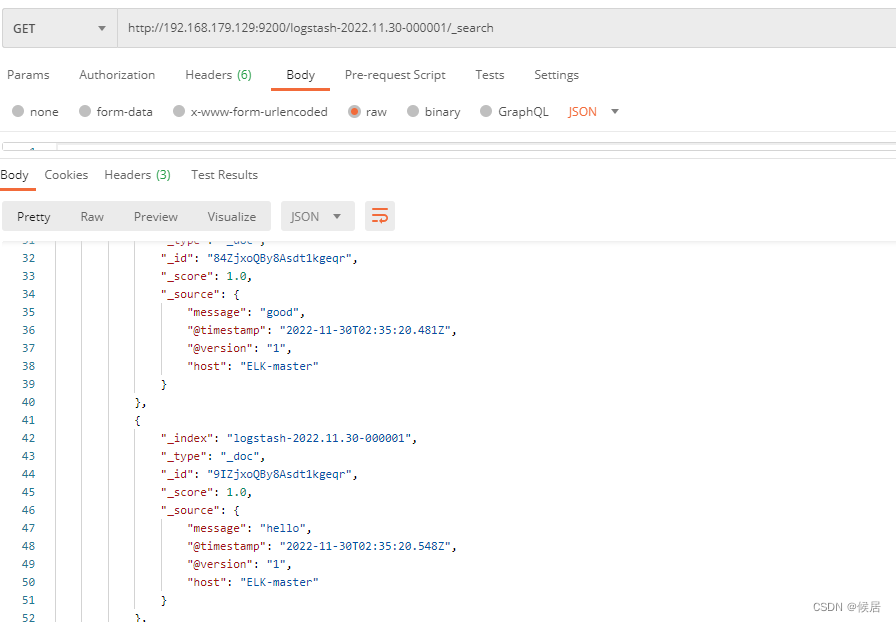
至此,说明logstash输出到 elasticsearch没有问题,这时可以进行正式配置了。logstash启动时,输入、输出的配置都通过配置文件来定义,进入config 目录,创建 springboot-logstash.conf文件。

这里要采集系统应用的日志,输入采用 文件方式,修改 springboot-logstash.conf 配置
input {
file {
path => "/usr/local/activity/info.log"
type => "activity"
start_position => "beginning"
}
file {
path => "/usr/local/activityapi/info.log"
type => "activityapi"
start_position => "beginning"
}
}
output {
if [type] == "activity" {
elasticsearch {
hosts => ["192.168.179.129"]
index => "activity-%{+YYYY.MM.dd}"
}
} else if [type] == "activityapi" {
elasticsearch {
hosts => ["192.168.179.129"]
index => "activityapi-%{+YYYY.MM.dd}"
}
}
}
执行启动命令
nohup ./logstash -f ../config/springboot-logstash.conf --config.reload.automatic 2>&1 &
不同的应用(activity、activityapi),建立了不同的索引,并以日为单位做分割,可以查看elasticsearch的索引情况
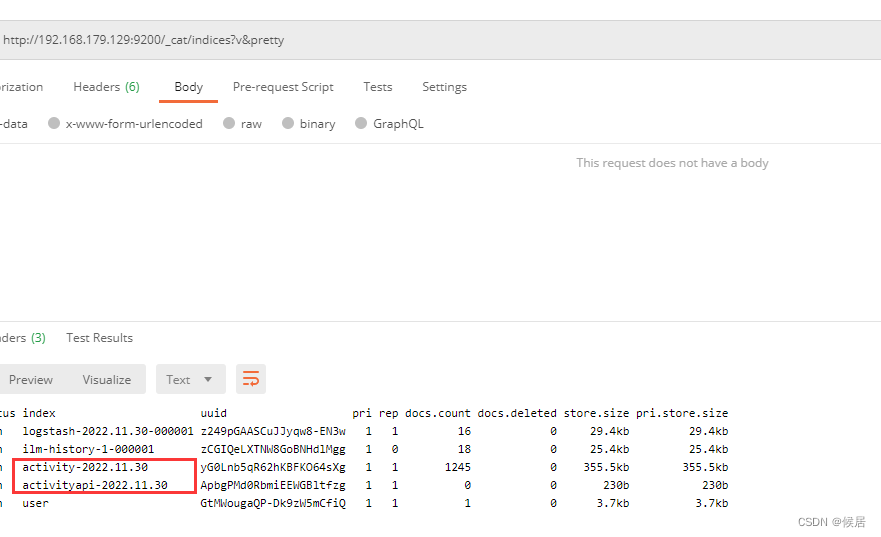
此时,logstash启动成功
在 /usr/local/elk/ 下建立 kibana文件夹,下载安装包,并解压
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz
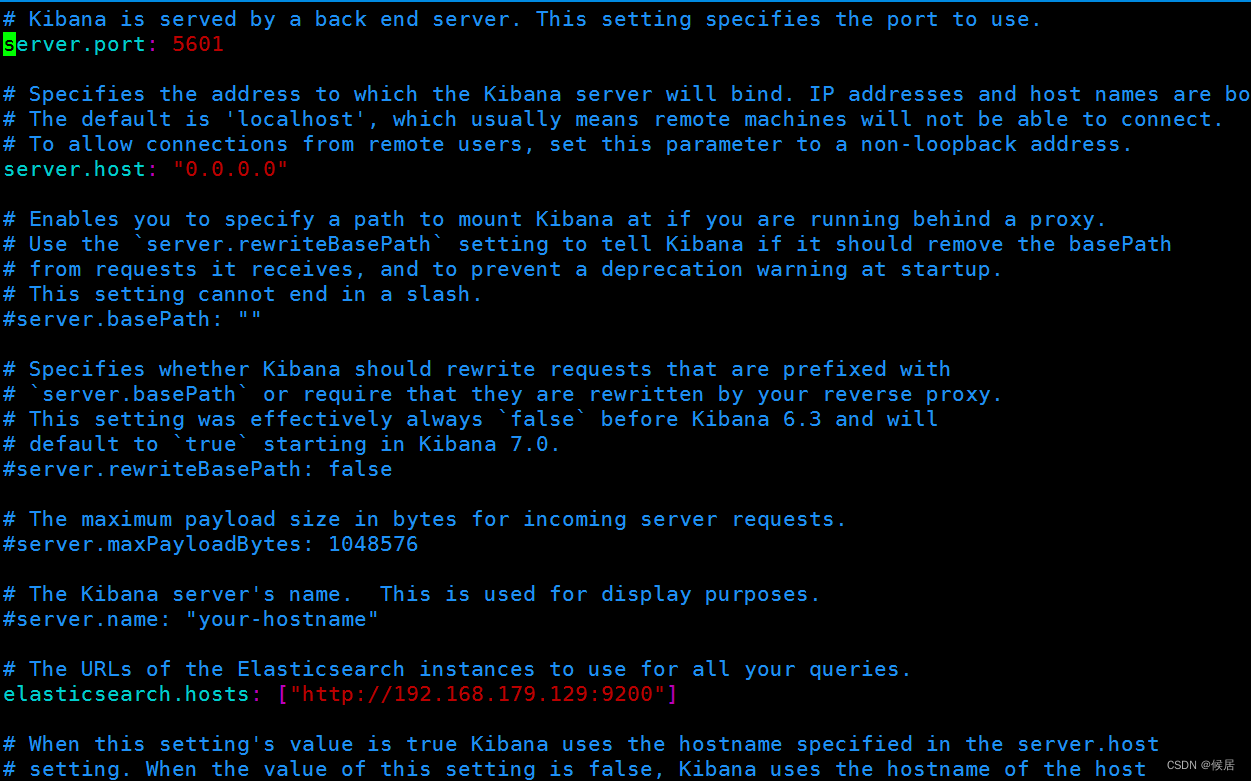
修改配置文件

server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.179.129:9200"]
然后启动即可,注意,不能使用root用户启动,切换到es用户
nohup ./kibana &

启动之后,访问 链接 http://192.168.179.129:5601/
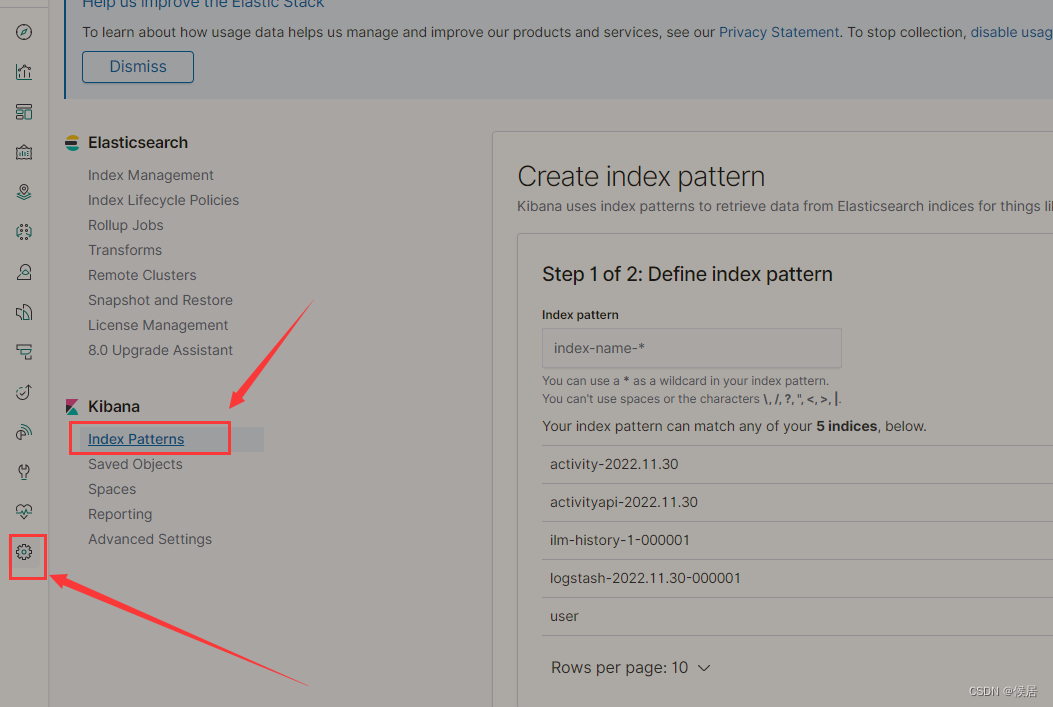
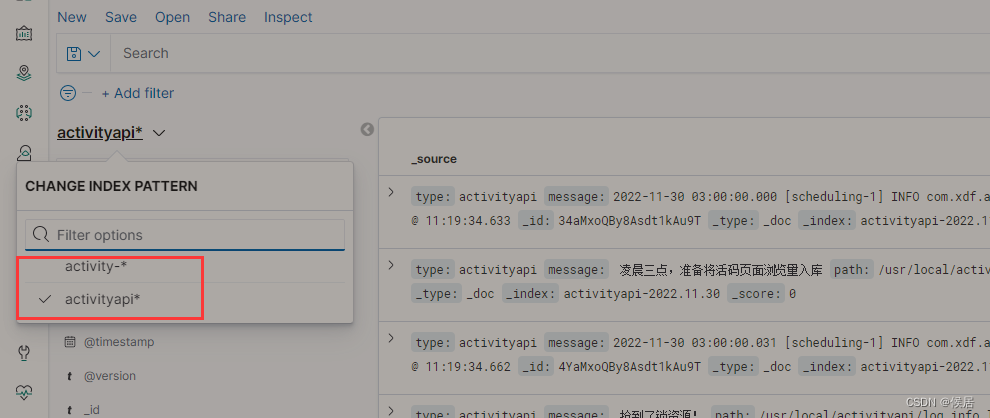
kibana安装之后,做一下配置就可以使用了,先找到管理页面,点击 Index Patterns
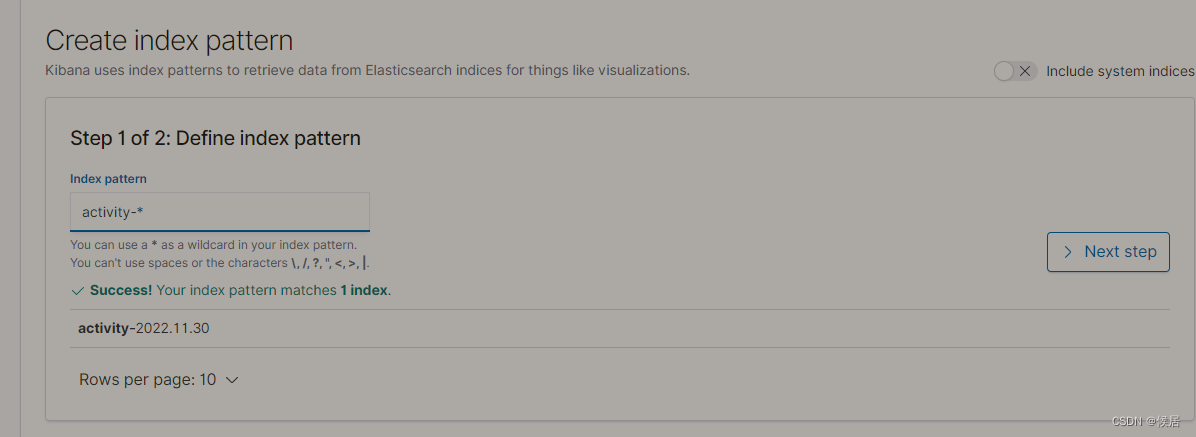
第一步,定义的 index pattern ,其实和 elasticsearch 对应的 index有关,比如上文中 activity 的日志,都是以 activity- 为前缀,我定义 activity-* ,就可以匹配对应的所有日期下的日志
第二步,点击保存

同理,我对 activityapi 也配置对应的 index pattern,activityapi* 。
然后点击discover版块,可以看到对应的数据

我们可以通过切换对应 的index pattern ,来查看相关的日志
这就相当于,有了一个实时可视化的tail -f 日志工具,并且支持内容搜索。

至此,单机版的ELK环境就搭建完成了。
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
我试图在rails中了解rubygems是如何变得可以自动使用的,而不是在使用required的文件中gem? 最佳答案 这是通过bundler/setup完成的:http://bundler.io/v1.3/bundler_setup.html.它在您的config/boot.rb文件中是必需的。简而言之,它首先将环境变量设置为指向您的Gemfile:ENV['BUNDLE_GEMFILE']||=File.expand_path('../../Gemfile',__FILE__)然后它通过要求bundler/setup将所有ge
从一开始,我就是一个Windows高手。我从MS-DOS开始。我安装了Windows2.1以及此后的所有Windows。现在,我家里有10台不同的Windows机器在运行,从Windows7Ultimate到各种版本的WindowsServer。我还没有完成Windows8,也不想去那里。我在服务器和各种软件方面都有UNIX经验,但它并不是我的首选环境。但是,我想我正在转换。我试图假装使用Cygwin和MSYS在Windows下运行UNIX。我的目的是搭建一个开发环境。两者都让我失望了。我花了比开发更多的时间来解决一系列技术问题。这是NotAcceptable。到目前为止,我的Ruby
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
我给自己买了一个新的8gigUSBkey,我正在寻找一个合适的解决方案来拥有一个可移植RoR环境来学习。我在谷歌上搜索了一下,发现了一些可能性,但我很想听听一些现实生活中的经历和意见。谢谢! 最佳答案 我喜欢InstantRails,非常容易使用,无需安装程序,也不会修改您的系统环境。 关于ruby-on-rails-可移植RubyonRails环境,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/q
在我的双语Rails4应用程序中,我有一个像这样的LocalesController:classLocalesController用户可以通过此表单更改其语言环境:deflocale_switcherform_tagurl_for(:controller=>'locales',:action=>'change_locale'),:method=>'get',:id=>'locale_switcher'doselect_tag'set_locale',options_for_select(LANGUAGES,I18n.locale.to_s)end这有效。但是,目前用户无法通过URL更改
我在跑Fastlane(适用于iOS的持续构建工具)以执行用于解密文件的自定义shell脚本。这是命令。sh"./decrypt.shENV['ENCRYPTION_P12']"我想不出将环境变量传递给该脚本的方法。显然,如果我将密码硬编码到脚本中,它就可以正常工作。sh"./decrypt.shmypwd"有什么建议吗? 最佳答案 从直接Shell中扩展假设这里的sh是一个faSTLane命令,它以给定的参数作为脚本文本调用shell命令:#asafastlanedirectivesh'./decrypt.sh"$ENCRYPTI
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
我有一个应用程序专门使用Facebook作为身份验证提供程序,并正确设置了生产模式的回调。为了让它工作,您需要为您的Facebook应用程序提供一个站点URL和一个用于回调的站点域,在我的例子中是http://appname.heroku.com和appname。heroku.com分别。问题是我的Controller设置为只允许经过身份验证的session,所以我无法在开发模式下查看我的应用程序,因为Facebook应用程序的域显然没有设置为本地主机。如何在不更改Facebook设置的情况下解决这个问题? 最佳答案 创建另一个域l