目录:导读
常见的接口:
http api接口:是走http协议,通过路径来区分调用的方法,请求报文都是key-value形式的,返回报文一般都是json串,有get和post等方法,这也是最常用的两种请求方式。可以使用的工具有postman、jmeter、apifox、loadrunner等;
python接口自动化测试:https://www.bilibili.com/video/BV16G411x76E/
webService接口:是走soap协议通过http传输,请求报文和返回报文都是xml格式的,我们在测试的时候都用通过工具才能进行调用,测试。可以使用的工具有SoapUI、jmeter、loadrunner等;
对于软件测试而言,有几个大体的发展方向:功能,接口,UI,性能。
对于有一定基础测试经验的软件测试从业者来说,接口肯定是最好的方向
阅读完此文我就会告知你原因
接下来我将从下面三个方面来阐述:
1、为什么对于初学者来说,接口是最好的进阶方向?
2、接口学习可以分为哪三个阶段?
3、接口学习的三个阶段分别学什么?
接口测试最好的方向
为什么对于有一定基础测试经验的软件测试从业者来说,接口是最好的方向?
目前项目实现方式,绝大多数都是采用前后端分离,所以功能都需要通过接口来完成,所以接口测试应用广泛,必不可少;
相对于功能、UI、性能测试而言,接口学习的性价比更高;
相对于功能测试,接口测试之后可以选择实现自动化,方便回归;
相对于UI测试,要么是考虑手动测试,要么是考虑自动化。如果是UI自动化的话,在项目还处于开荒期,迭代比较快且内容更替比较大的情况下,UI自动化的性价比是很低的;
相对于性能测试,它的学习基础就是接口测试;
学好了接口测试,对于我们找一个比较好的工作,帮忙很大。是不是这样?
接口测试已经是现如今测试工程师的标配技能。如果只会功能测试,若再学一个接口测试,起步薪资就能达到13K+了,所以学接口测试的性价比非常高
所以你若要自学,至少要知道如何使用常见的接口测试工具(比如postman、jmeter、ApiPost、Apifox等)去进行接口测试
接口测试学习三个阶段
阶段一
了解接口测试相关的基础知识,达到的目标有两个:
1.能解读接口文档;
2.能编写接口测试用例
阶段二
学习使用工具完成接口测试,工具推荐Postman和Jmeter。对于新人,没有接触过接口测试的,我建议先学习使用Postman这种工具,因为它上手要比Jmeter友好很多
阶段三
学习使用代码完成接口测试,并且能搭建接口测试的自动化框架。这最后一个阶段,也可以说是接口测试从接口自动化测试的过渡阶段
虽然使用Postman或者Jmeter也能完成接口的自动化测试,但是如果你想要拿到月20k+的offer,代码这一块是无论如何都绕不过去的。
这里建议用python做自动化测试。现企业的主流
学习的三个阶段
第一阶段学习内容
这一个阶段,我们主要是了解接口测试的一些基础知识
包括下面这些:
了解接口及接口测试的概论
知道什么是接口,什么是接口测试,并且了解接口测试的原理和为什么要进行接口测试
理解Http协议
(1)了解Http协议的作用是什么,都有哪些特点
(2)理解URL,以及URL的组成部分
(3)理解Http协议的两个组成部分,Http请求和Http响应,掌握如何通过抓包Fiddler,谷歌的开发者工具,fiddler或者charles抓取接口,并且查看这两部分的内容
(4) 重点掌握Http请求的请求方法都要哪些
(5) 重点掌握常见的Http响应的状态码都有哪些,并且代表什么意思
了解接口规范,重点了解Restful接口风格
接口文档的解析
(1)明白接口文档的作用
(2) 知道接口文档都应该要包含哪些内容
最重要的,接口的测试用例编写。这里的重点是理解接口测试用例设计的思路和方法。
第二阶段学习内容
对于初学者而言,我建议以postman入手开始学习接口测试,因为它对于新手而言,比Jmeter友好太多了
基本上5天左右就能完成掌握,对一般遇到的接口进行测试一点问题都没有
对于Postman的学习可以从以下几个方面进行学习:
基本的设置
创建接口请求
设置请求方法
URL
在URL中设置参数
设置请求头
设置表单格式和JSON类型的请求体参数,能查看响应数据和响应的状态码
高级的用法
(1)进行接口测试用例的管理
(2)使用postman完成断言
(3) 使用Postman完成接口之前的数据关联
(4) 使用postman完成测试数据的参数化
(5) 学习使用请求的前置脚本
学习借助newman这个插件完成生成测试报告
第三阶段学习内容
接口测试的第三阶段,其实就可以理解为是接口的自动化测试了。目前在这个行业里面实现接口自动化,大部分就是两个方向,一个是JAVA,另外一个是Python。但是对于一个没有什么代码基础的不太友好。
这个阶段我强推Python,因为从学习Python到能实现接口自动化框架的搭建,最多一个月就能实现。而你要选择JAVA的话,一个月的时间,你连基础还没有学完
如果要学习Python进行接口自动化的话,可以分成以下几个步骤:
学习Python
Python的基础语法,如变量、函数和类,顺序、分支、循环;
python框架封装;
Python的单元测试框架,unittest和pytest
学习使用代码进行数据库的操作,工具包pymysql
学习使用代码,进行SQL语句的增,删,改,查;
学习使用代码,进行事务的手动提交
自行封装一个数据库的工具类
学习使用代码进行接口测试,学习工具包requests
学习借助unittest或者pytest搭建接口自动化框架
只要能完成这最后一个阶段,基本上接口测试这一块就通透了,想找一个20k+以上的工作就没有问题。最后的话,还可以继续学习Jmeter或者loadrunner来进行接口性能方面的测试。
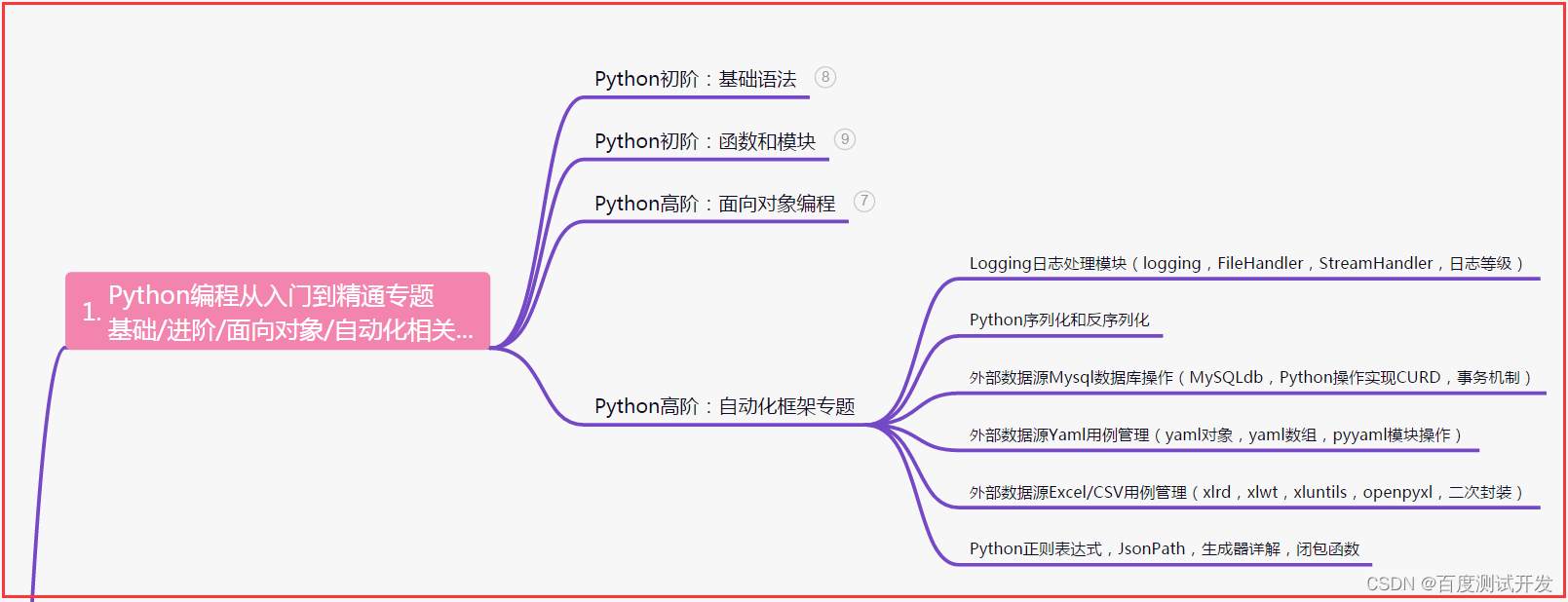
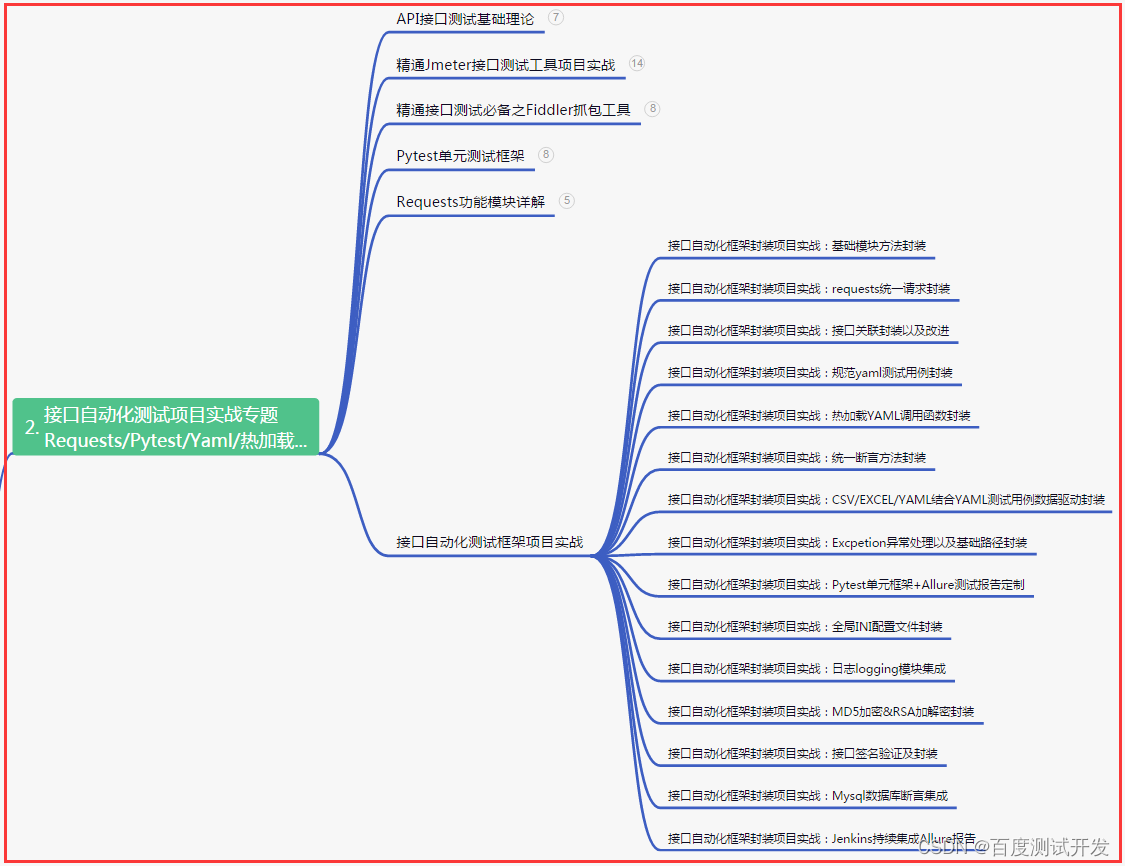
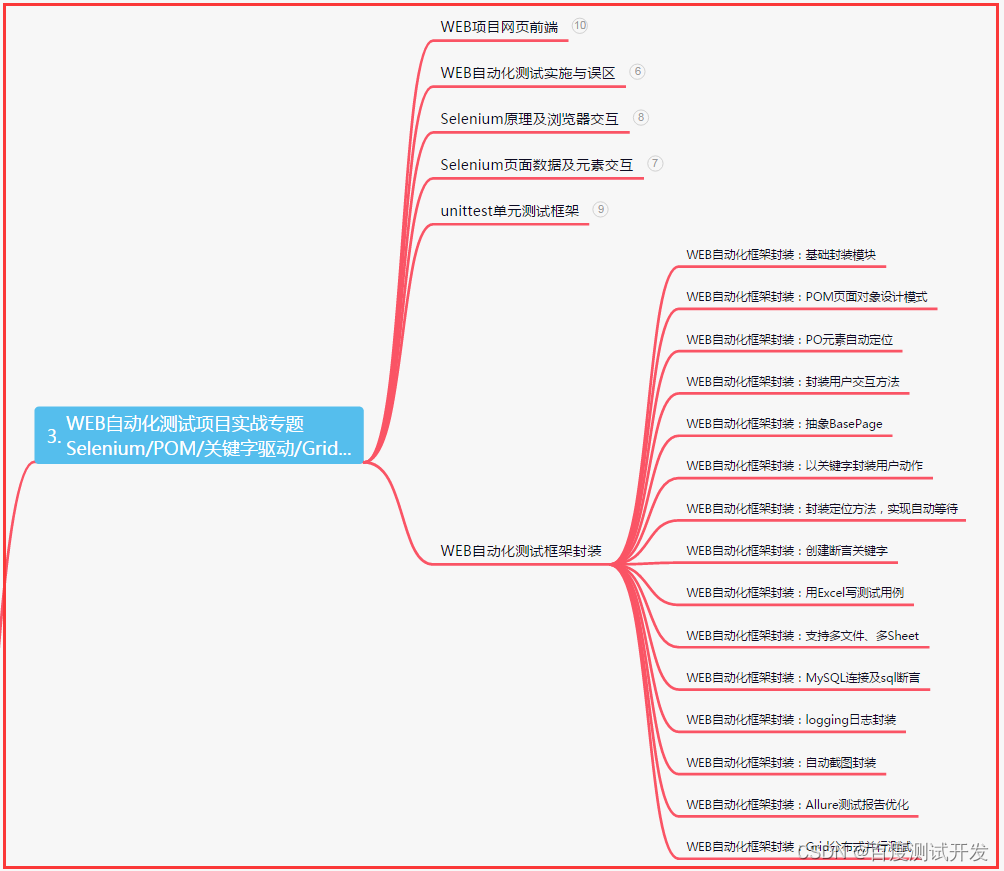
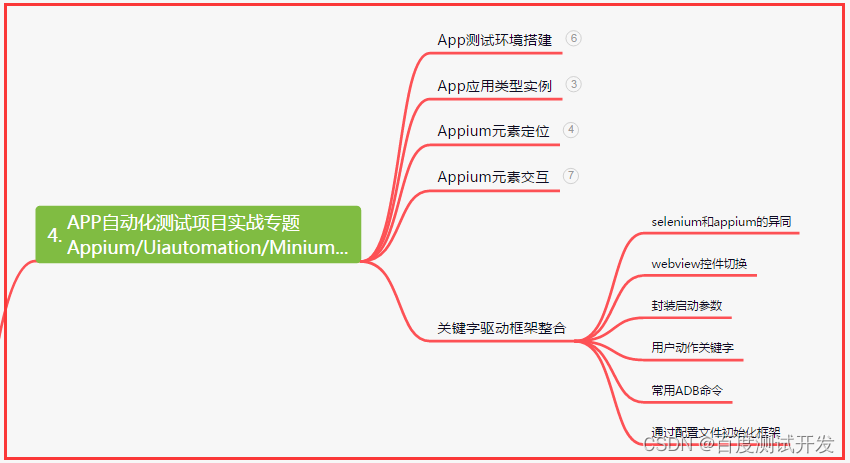
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |

过去的,让它过去,永远不要回顾;未来的,等来了时再说,不要空想;我们只抓住了现在,用我们现在的理想,做我们所应该做的。
相信自己,坚信自己的目标,去承受常人承受不了的磨难与挫折,不断去努力、去奋斗,成功最终就会是你的!
多数人在人潮汹涌的世间,白白挤了一生,从来不知道哪里才是他所想要到达的地方,而有目标的人却始终不忘记自己的方向,所以他能打开出路,走向成功。
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere