译者 | 朱先忠
审校 | 重楼
当前,多模式人工智能已经成为一个街谈巷议的热门话题。随着GPT-4的最近发布,我们看到了无数可能出现的新应用和未来技术,而这在六个月前是不可想象的。事实上,视觉语言模型对许多不同的任务都普遍有用。例如,您可以使用CLIP(Contrastive Language-Image Pre-training,即“对比语言-图像预训练”,链接:https://github.com/openai/CLIP)对看不到的数据集进行零样本图像分类;通常情况下,无需任何训练即可获得出色的表现。
同时,视觉语言模型也并不完美。在本文中,我们要探讨这些模型的局限性,强调它们可能失败的地方和原因。事实上,这篇文章是对我们最近将发表的论文的简短/高级描述,该论文计划将以ICLR 2023 Oral论文形式发表。如果您想查看本文有关完整的源代码,只需单击链接https://github.com/mertyg/vision-language-models-are-bows。
视觉语言模型利用视觉和语言数据之间的协同作用来执行各种任务,从而彻底改变了该领域。虽然目前已有的文献中已经引入了许多视觉语言模型,但CLIP(对比语言-图像预训练)仍然是最知名和最广泛使用的模型。
通过在同一向量空间中嵌入图像和标题,CLIP模型允许进行跨模式推理,使用户能够以良好的准确性执行诸如零样本图像分类和文本到图像检索等任务。并且,CLIP模型使用对比学习方法来学习图像和标题的嵌入。
对比学习使得CLIP模型可以通过在共享向量空间中最小化图像之间的距离来学习将图像与其相应的标题相关联。CLIP模型和其他基于对比的模型所取得的令人印象深刻的结果证明了这种方法是非常有效的。
对比度损失用于比较批次中的图像和标题对,并优化模型以最大化匹配图像-文本对的嵌入之间的相似性,并降低批次中其他图像-文本对之间的相似度。
下图展示了可能的批处理和训练步骤示例,其中:
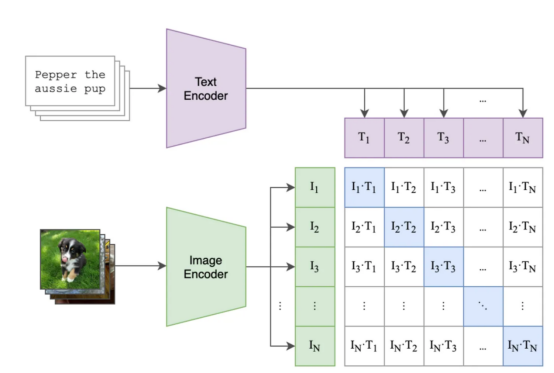
CLIP模型中的对比预训练(其中,蓝色方块是我们想要优化相似性的图像-文本对)
经过训练后,你应该可以生成一个可以在其中对图像和标题进行编码的有意义的向量空间。一旦为每个图像和每个文本嵌入了内容,你就可以做很多任务,比如看哪些图像更符合标题(例如,在2017年暑假相册中找到“dogs on the beach”(海滩上的狗)),或者找到哪个文本标签更像给定图片(例如,你有一大堆你的狗和猫的图像,你希望能够识别哪个是哪个)。
CLIP等视觉语言模型已成为通过集成视觉和语言信息来解决复杂人工智能任务的强大工具。他们将这两种类型的数据嵌入共享向量空间的能力在广泛的应用中带来了前所未有的准确性和出众表现。
我们所做的工作正是试图采取一些手段来回答这个问题。关于深度模型能否或者说能在多大程度上理解语言这个问题,当前还存在着重大的争论。在这里,我们的目标是研究视觉语言模型及其合成能力。
我们首先提出了一个新的数据集用来测试成分理解;这个新的基准被称为ARO(Attribution,Relations,and Order:属性、关系和顺序)。接着,我们探讨为什么对比损失在这种情况下可能是有限的。最后,我们为这个问题提出了一个简单但有希望的解决方案。
像CLIP(以及Salesforce最近推出的BLIP)这样的模型在理解语言方面做得怎么样呢?
我们收集了一组基于属性的合成标题(例如“the red door and the standing man”(红门和站着的人))和一组基于关系的合成标题(例如“the horse is eating the grass”(马在吃草))以及相匹配的图像。然后,我们生成替代后的虚假标题,比如“the grass is eating the horse”(草正在吃马)。模型们能找到正确的标题吗?我们还探讨了混排单词的效果:难道模型更喜欢非混排标题而不是混排标题吗?
我们为属性、关系和顺序(ARO)基准创建的四个数据集如下图所示(请注意,顺序部分包含两个数据集):

我们创建的不同数据集包括Relation、Attribution和Order。对于每个数据集,我们显示一个图像示例和不同的标题。其中,只有一个标题是正确的,模型必须识别出这个正确的标题。
视觉语言模型能找到与图像匹配的正确标题吗?这项任务似乎很容易,我们希望模型能够理解“马在吃草”和“草在吃草”之间的区别,对吧?我的意思是,谁见过草在吃东西?
好吧,可能是BLIP模型,因为它无法理解“马在吃草”和“草在吃草”之间的区别:

BLIP模型不理解“草在吃草”和“马在吃草”之间的区别(其中包含来自视觉基因组数据集的元素,图片由作者提供)
现在,让我们看看实验结果:很少有模型能在很大程度上超越理解关系的可能性(例如,eating——吃饭)。但是,CLIP模型在属性和关系的边缘方面略高于此可能性。这实际上表明视觉语言模型尚存在问题。
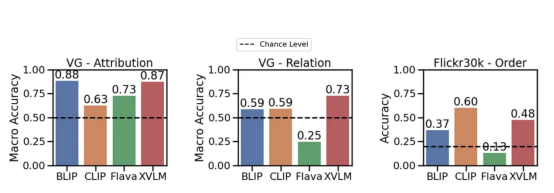
不同模型在属性、关系和顺序(Flick30k)基准上的性能。其中使用了CLIP、BLIP以及其他SoTA模型
这项工作的主要结果之一是,我们学习语言需要的可能不仅仅是标准的对比损失。这又是为什么呢?
让我们从头开始:视觉语言模型通常在检索任务中进行评估:取一个标题并找到它映射到的图像。如果你查看用于评估这些模型的数据集(例如,MSCOCO、Flickr30K),你会看到,它们通常包含用标题描述的图像,这些标题需要理解构图能力(例如,“the orange cat is on the red table”:橙色的猫在红色的桌子上)。那么,如果标题很复杂,为什么模型不能学习构图理解呢?
[说明]在这些数据集上进行检索并不一定需要对组成的理解。
我们试图更好地理解这个问题,并在打乱标题中单词的顺序时测试了模型在检索方面的性能。我们能找到标题“books the looking at people are”的正确图像吗?如果答案是肯定的;这意味着,不需要指令信息来找到正确的图像。

我们测试模型的任务是使用打乱的标题进行检索。即使我们打乱标题,模型也可以正确地找到相应的图像(反之亦然)。这表明检索任务可能过于简单,图片由作者提供。
我们测试了不同的乱序过程,结果是肯定的:即使使用不同的乱序技术,检索性能也基本上不会受到影响。
让我们再说一次:视觉语言模型在这些数据集上实现了高性能的检索,即使指令信息无法访问。这些模型可能表现得像一堆单词,其中顺序并不重要:如果模型不需要理解单词顺序才能在检索中表现良好,那么我们在检索中实际衡量的是什么?
既然我们知道存在问题,我们可能想寻找解决方案。最简单的方法是:让CLIP模型明白“猫在桌子上”和“桌子在猫身上”是不同的。
事实上,我们所建议的一种途径是通过添加专门为解决这个问题而制作的硬底片来改进CLIP训练。这是一个非常简单有效的解决方案:它需要对原始CLIP损失进行非常小的编辑,而不会影响总体性能(您可以在论文中阅读一些注意事项)。我们将此版本的CLIP称为NegCLIP。
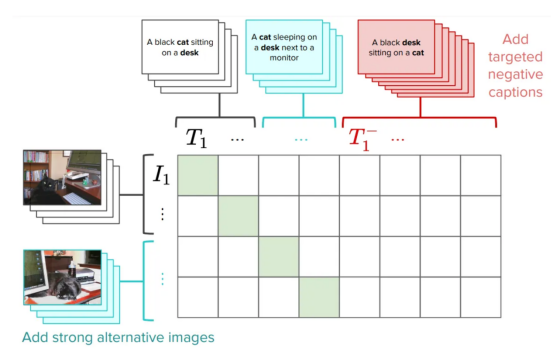
在CLIP模型中引入硬底片(我们添加了图像和文本硬底片,图片由作者提供)
基本上,我们要求NegCLIP模型将黑猫的图像放在“a black cat sitting on a desk”(坐在桌子上的黑猫)这句话附近,但远离句子“a black desk sitting on a cat”(坐在猫身上的黑色桌子)。注意,后者是通过使用POS标签自动生成的。
该修复的效果是,它实际上可以提高ARO基准的性能,而不会损害检索性能或检索和分类等下游任务的性能。有关不同基准的结果,请参见下图(有关详细信息,请参阅本文对应论文)。
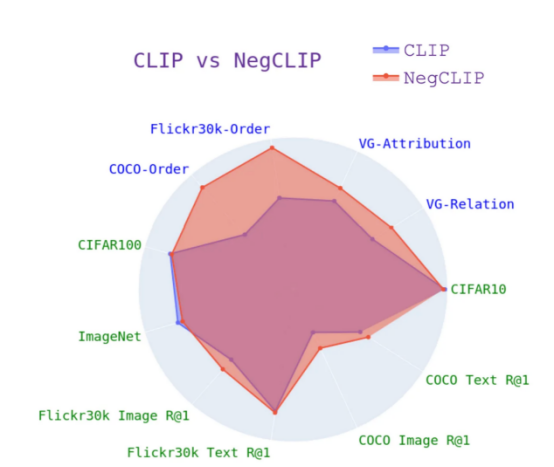
不同基准上的NegCLIP模型与CLIP模型。其中,蓝色基准是我们介绍的基准,绿色基准来自网络文献(图片由作者提供)
您可以看到,这里与ARO基准相比有了巨大的改进,在其他下游任务上也有了边缘改进或类似的性能。
Mert(论文的主要作者)在创建一个小型库来测试视觉语言模型方面做得很好。你可以使用他的代码来复制我们的结果,或者用新的模型进行实验。
下载数据集并开始运行只需要少数几行Python语言:
import clip
from dataset_zoo import VG_Relation, VG_Attribution
model, image_preprocess = clip.load("ViT-B/32", device="cuda")
root_dir="/path/to/aro/datasets"
#把 download设置为True将把数据集下载到路径`root_dir`——如果不存在的话
#对于VG-R和VG-A,这将是1GB大小的压缩zip文件——它是GQA的一个子集
vgr_dataset = VG_Relation(image_preprocess=preprocess,
download=True, root_dir=root_dir)
vga_dataset = VG_Attribution(image_preprocess=preprocess,
download=True, root_dir=root_dir)
#可以对数据集作任何处理。数据集中的每一项具有类似如下的形式:
# item = {"image_options": [image], "caption_options": [false_caption, true_caption]}此外,我们还实现了NegCLIP模型(其实际是OpenCLIP的一个更新副本),其完整代码下载地址是https://github.com/vinid/neg_clip。
总之,视觉语言模型目前已经可以做很多事情了。接下来,我们迫不及待地想看看GPT4等未来的模型能做什么!
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Your Vision-Language Model Might Be a Bag of Words,作者:Federico Bianchi
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search