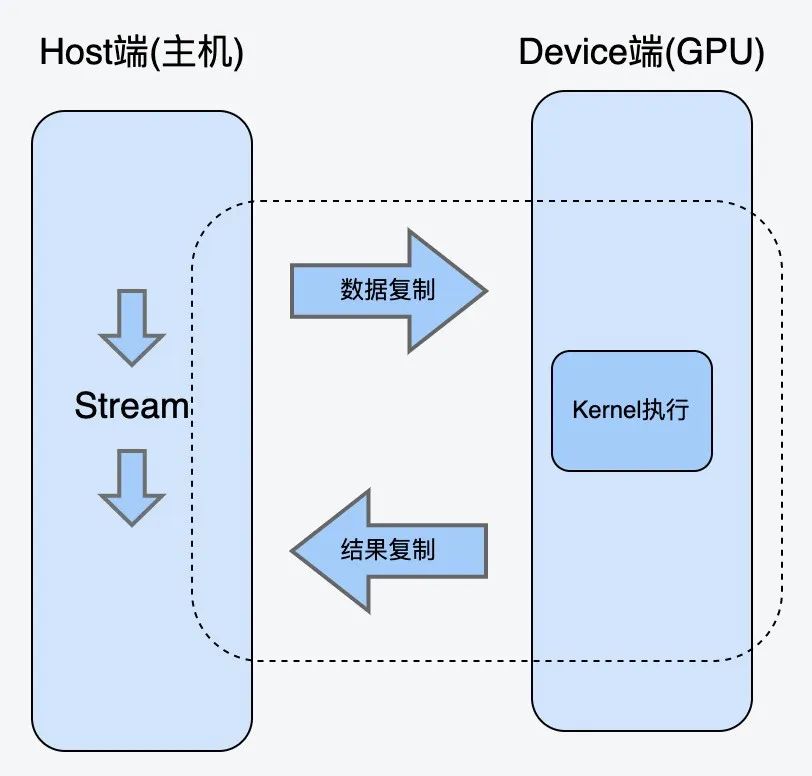
 CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。CUDA的架构中引入了主机端(host, cpu)和设备(device, gpu)的概念。CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成众多thread去并行执行。CUDA Stream流:Cuda stream是指一堆异步的cuda操作,他们按照host代码调用的顺序执行在device上。典型的CUDA代码执行流程:a.将数据从Host端copy到Device端。b.在Device上执行kernel。c.将结果从Device段copy到Host端。以上流程也是模型在GPU推理的过程。在执行的过程中还需要绑定CUDA Stream,以流的形式执行。
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。CUDA的架构中引入了主机端(host, cpu)和设备(device, gpu)的概念。CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成众多thread去并行执行。CUDA Stream流:Cuda stream是指一堆异步的cuda操作,他们按照host代码调用的顺序执行在device上。典型的CUDA代码执行流程:a.将数据从Host端copy到Device端。b.在Device上执行kernel。c.将结果从Device段copy到Host端。以上流程也是模型在GPU推理的过程。在执行的过程中还需要绑定CUDA Stream,以流的形式执行。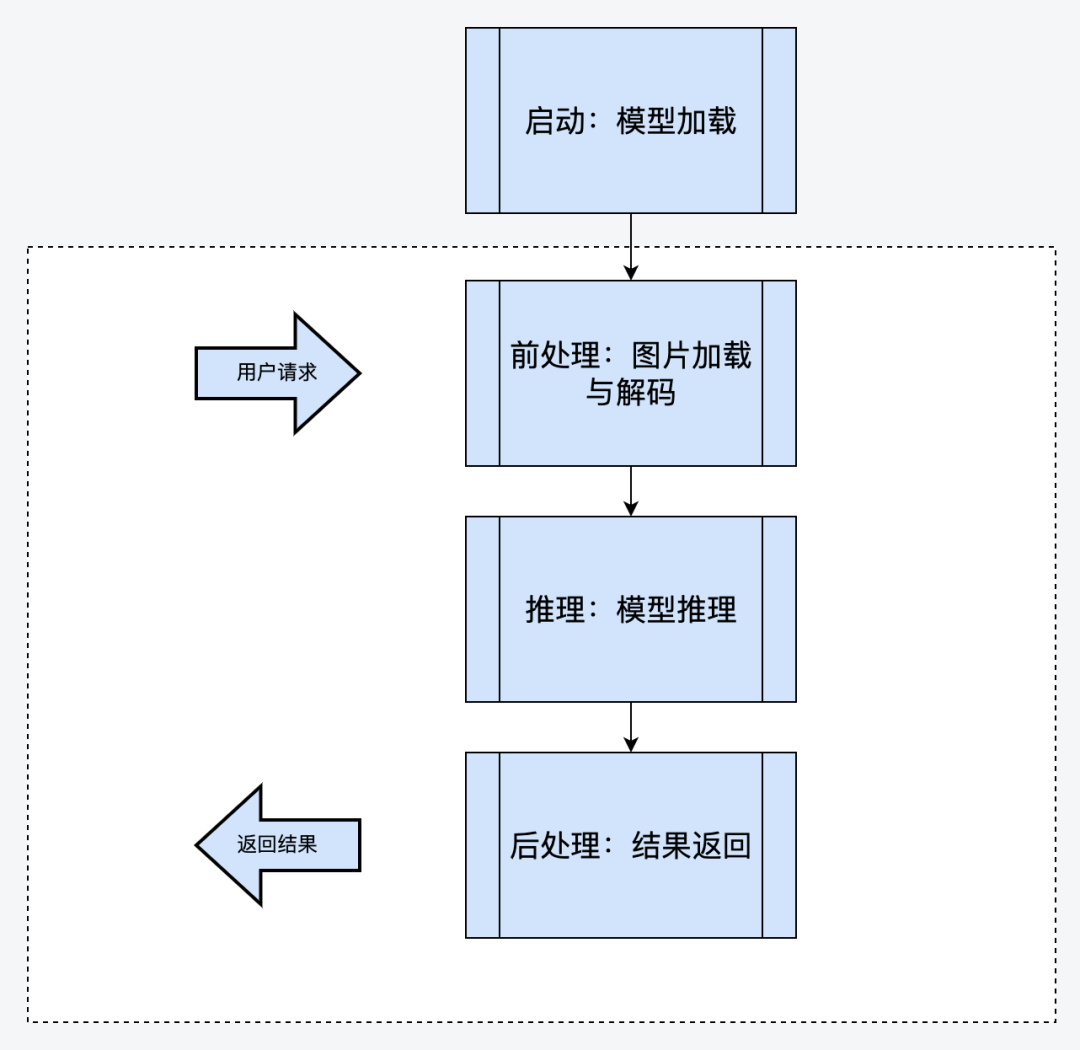 以上架构是传统推理服务的常用架构。这种架构的优势是代码写起来比较通俗易懂。但是在性能上有很大的弊端,所能承载的QPS比较低。我们用了几个CV模型去压测,极限QPS也一般不会超过4。
以上架构是传统推理服务的常用架构。这种架构的优势是代码写起来比较通俗易懂。但是在性能上有很大的弊端,所能承载的QPS比较低。我们用了几个CV模型去压测,极限QPS也一般不会超过4。| 推理服务框架类型 | QPS | 耗时 | GPU使用率 |
| 传统推理服务(多线程) | 4.5 | 1.05s | 2% |
| 自研框架(6CPU进程+1GPU进程) | 27.43 | 437ms | 12% |
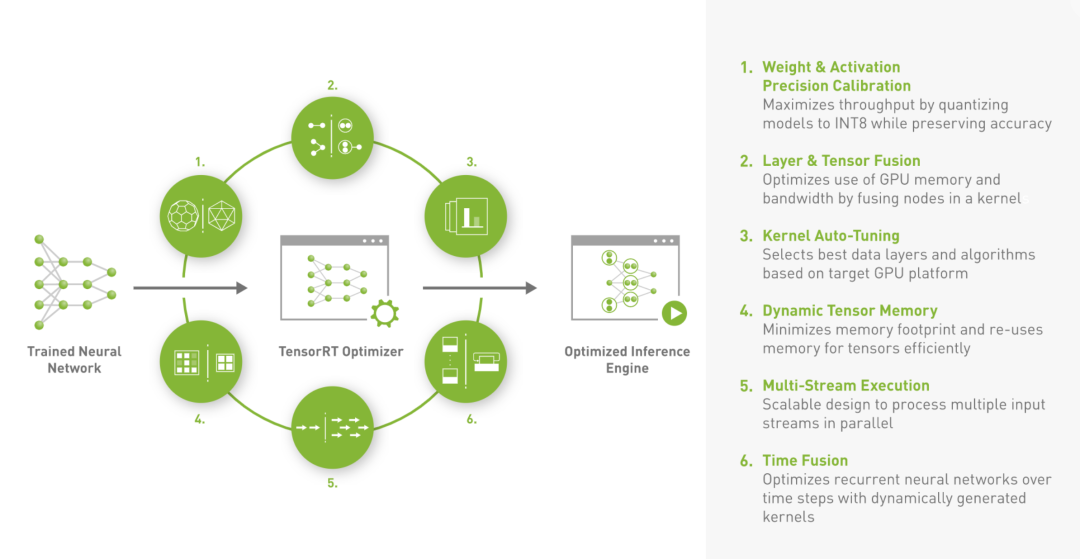 TensorRT是由英伟达公司推出的一款用于高性能深度学习模型推理的软件开发工具包,可以把经过优化后的深度学习模型构建成推理引擎部署在实际的生产环境中。TensorRT提供基于硬件级别的推理引擎性能优化。下图为业界最常用的TensorRT优化流程,也是当前模型优化的最佳实践,即pytorch或tensorflow等模型转成onnx格式,然后onnx格式转成TensorRT进行优化。
TensorRT是由英伟达公司推出的一款用于高性能深度学习模型推理的软件开发工具包,可以把经过优化后的深度学习模型构建成推理引擎部署在实际的生产环境中。TensorRT提供基于硬件级别的推理引擎性能优化。下图为业界最常用的TensorRT优化流程,也是当前模型优化的最佳实践,即pytorch或tensorflow等模型转成onnx格式,然后onnx格式转成TensorRT进行优化。 其中TensorRT所做的工作主要在两个时期,一个是网络构建期,另外一个是模型运行期。a.网络构建期 i.模型解析与建立,加载onnx网络模型。 ii.计算图优化,包括横向算子融合,或纵向算子融合等。 iii.节点消除,去除无用的节点。 iv.多精度支持,支持FP32/FP16/int8等精度。 v.基于特定硬件的相关优化。b.模型运行期 i.序列化,加载RensorRT模型文件。提供运行时的环境,包括对象生命周期管理,内存显存管理等。以下是我们基于 VisualTransformer模型进行的TensorRT优化前后的性能评测报告:
其中TensorRT所做的工作主要在两个时期,一个是网络构建期,另外一个是模型运行期。a.网络构建期 i.模型解析与建立,加载onnx网络模型。 ii.计算图优化,包括横向算子融合,或纵向算子融合等。 iii.节点消除,去除无用的节点。 iv.多精度支持,支持FP32/FP16/int8等精度。 v.基于特定硬件的相关优化。b.模型运行期 i.序列化,加载RensorRT模型文件。提供运行时的环境,包括对象生命周期管理,内存显存管理等。以下是我们基于 VisualTransformer模型进行的TensorRT优化前后的性能评测报告:| 类别 | Pytorch | Onnx | TensorRT-fp32 | TensorRT-fp16 |
| 平均耗时 | 20ms | 15ms | 7ms | 3.5ms |
| 精度变化 | 精度不变 | 精度不变 | 精度不变 | 精度稍有损失,误差均值与方差在0.003内 |
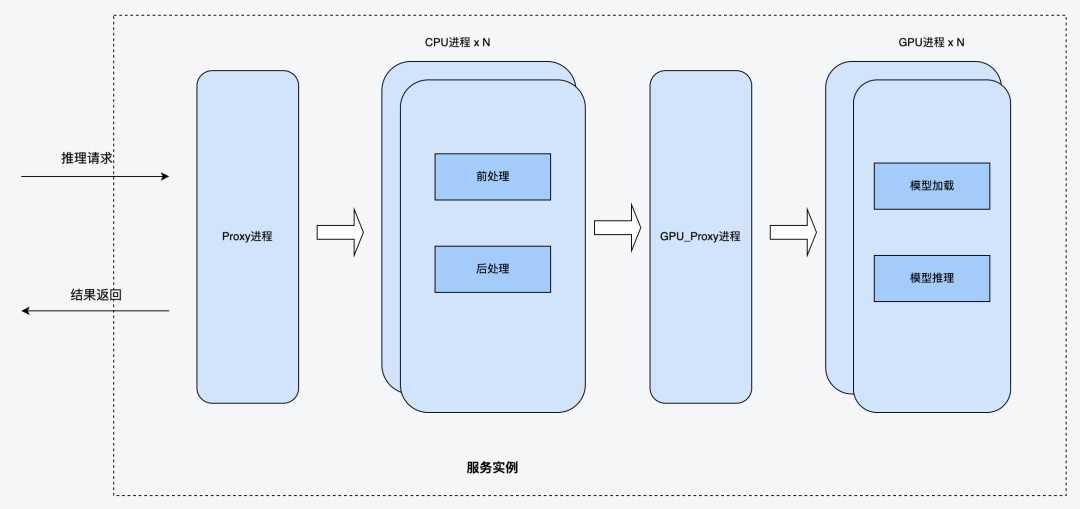
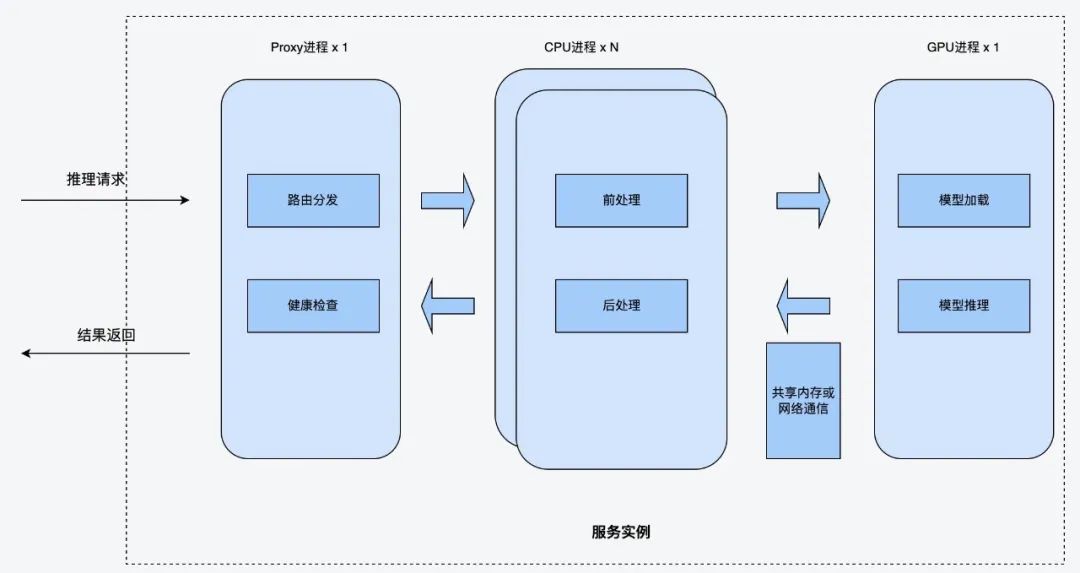 方案设计的思路是GPU逻辑与CPU逻辑分离到两个进程,其中CPU进程主要负责CPU相关的业务逻辑,GPU进程主负责GPU相关推理逻辑。同时拉起一个Proxy进程做路由转发。(1)Proxy进程Proxy进程是系统门面,对外提供调用接口,主要负责路由分发与健康检查。当Proxy进程收到请求后,会轮询调用CPU进程,分发请求给CPU进程。(2)CPU进程CPU进程主要负责推理服务中的CPU相关逻辑,包括前处理与后处理。前处理一般为图片解码,图片转换。后处理一般为推理结果判定等逻辑。CPU进程在前处理结束后,会调用GPU进程进行推理,然后继续进行后处理相关逻辑。CPU进程与GPU进程通过共享内存或网络进行通信。共享内存可以减少图片的网络传输。(3)GPU进程GPU进程主要负责运行GPU推理相关的逻辑,它启动的时候会加载很多模型到显存,然后收到CPU进程的推理请求后,直接触发kernel lanuch调用模型进行推理。该方案对算法同学提供了一个Model类接口,算法同学不需要关心后面的调用逻辑,只需要填充其中的前处理,后处理的业务逻辑,既可快速上线模型服务,自动拉起这些进程。该方案把CPU逻辑(图片解码,图片后处理等)与GPU逻辑(模型推理)分离到两个不同的进程中。可以解决Python GIL锁带来的GPU Kernel launch调度问题。
方案设计的思路是GPU逻辑与CPU逻辑分离到两个进程,其中CPU进程主要负责CPU相关的业务逻辑,GPU进程主负责GPU相关推理逻辑。同时拉起一个Proxy进程做路由转发。(1)Proxy进程Proxy进程是系统门面,对外提供调用接口,主要负责路由分发与健康检查。当Proxy进程收到请求后,会轮询调用CPU进程,分发请求给CPU进程。(2)CPU进程CPU进程主要负责推理服务中的CPU相关逻辑,包括前处理与后处理。前处理一般为图片解码,图片转换。后处理一般为推理结果判定等逻辑。CPU进程在前处理结束后,会调用GPU进程进行推理,然后继续进行后处理相关逻辑。CPU进程与GPU进程通过共享内存或网络进行通信。共享内存可以减少图片的网络传输。(3)GPU进程GPU进程主要负责运行GPU推理相关的逻辑,它启动的时候会加载很多模型到显存,然后收到CPU进程的推理请求后,直接触发kernel lanuch调用模型进行推理。该方案对算法同学提供了一个Model类接口,算法同学不需要关心后面的调用逻辑,只需要填充其中的前处理,后处理的业务逻辑,既可快速上线模型服务,自动拉起这些进程。该方案把CPU逻辑(图片解码,图片后处理等)与GPU逻辑(模型推理)分离到两个不同的进程中。可以解决Python GIL锁带来的GPU Kernel launch调度问题。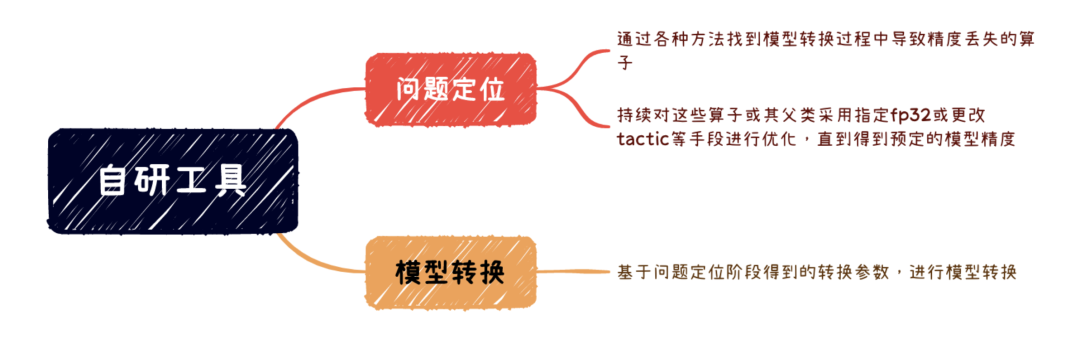
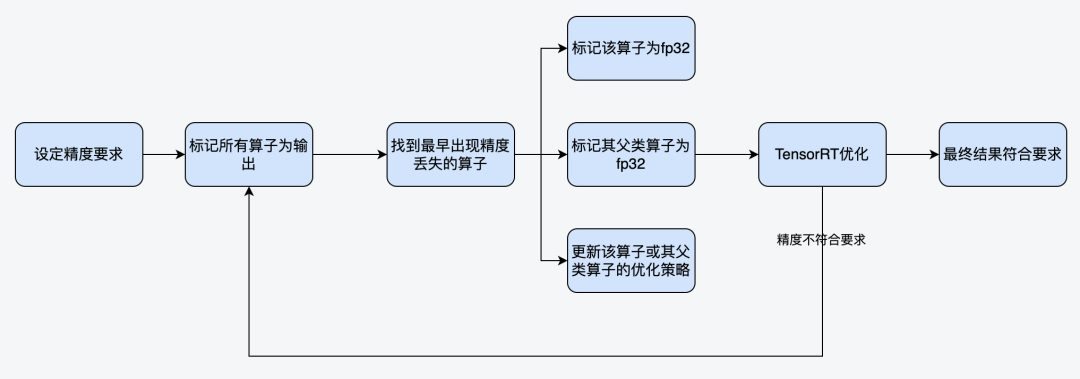 主要工作流程为:(1)设定模型转换精度要求后,标记所有算子为输出,然后对比所有算子的输出精度。(2)找到最早的不符合精度要求的算子,对该算子进行如下几种方式干预。
主要工作流程为:(1)设定模型转换精度要求后,标记所有算子为输出,然后对比所有算子的输出精度。(2)找到最早的不符合精度要求的算子,对该算子进行如下几种方式干预。| 配置项 | 解释 |
| FP32_LAYERS_FOR_FP16 | 开启FP16模式下,哪些算子需要额外开启FP32。 |
| TRT_EXCLUDE_TACTIC | TensorRT算子需要忽略的tactic策略。(tactic可参考TensorRT相关资料) |
| atol | 相对误差 |
| rtol | 绝对误差 |
| check-error-stat | 误差的计算方法包括:mean, median, max |
 比如线上某个模型,经过TensorRT优化后,显存由原来的2.4G降低到只需要1.2G。为此我们申请了5G显存,配置GPU进程为复制4份,共需要4.8G显存。这样存充分利用5G显存,达到原来一个模型的4倍的算力,充分利用GPU的算力资源。
比如线上某个模型,经过TensorRT优化后,显存由原来的2.4G降低到只需要1.2G。为此我们申请了5G显存,配置GPU进程为复制4份,共需要4.8G显存。这样存充分利用5G显存,达到原来一个模型的4倍的算力,充分利用GPU的算力资源。我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它:
关于如何使用git设置类似Dropbox的服务,您有什么建议吗?您认为git是解决此问题的合适工具吗?我在考虑使用git+rush解决方案,你觉得怎么样? 最佳答案 检查这个开源项目:https://github.com/hbons/SparkleShare来自项目的自述文件:Howdoesitwork?SparkleSharecreatesaspecialfolderonyourcomputer.Youcanaddremotelyhostedfolders(or"projects")tothisfolder.Theseprojec