目录
第一次写这类文章,如有不当之处,欢迎大家批评指正!感谢wwd同学的指正!
推荐使用Vivado + ModelSim 或 Quartus Ⅱ + ModelSim,这基本上就可以完成大部分工程。
推荐一个Verilog练习网站:HDLBits
目前主流的HDL(Hardware Description Language)有VHDL和Verilog。VHDL语法比较严谨;而Verilog类似C语言,风格相对自由。本质上,语言之间其实并不存在优劣之分,只有适合与否。如果你有一定的C语言基础,不妨先学习Verilog,毕竟谁不想轻松的度过语法适应期呢?不过呢,当你掌握一门语言之后,最好还是了解一下另一门语言,毕竟搬砖也是一项技术活!
相信大家或多或少有利用C语言或其它软件语言进行编程,程序是顺序执行的。但是HDL语言描述的是硬件电路,而硬件电路是并行处理的,这一转变或许会成为许多初学者的绊脚石。因此我们在学习语法的同时要做到心中有电路,而不仅仅是一串代码。那么,怎么判断代码描述的电路是否正确呢?写完一段代码后,多花一些精力对比实际逻辑电路(切忌偷懒哦),必要时可以做一些仿真,条件允许的话,可以在实验板上做一些测试。假以时日,代码与电路定会成为相伴而行的“老夫妻”。
可实现为硬件电路的语法称为可综合语法;不能实现到硬件电路中,却常常可作为仿真验证的高层次语法称为行为级语法。这一区分,使得入门的难度降低了许多,因为可综合语法只是一个很小的子集,或许当你完成一个实际系统设计时,你会惊奇的发现也就十几条语法。
行为级语法很无奈的说:“要不你试试用我做仿真吧。”

值得注意的是,本篇将只会对基本语法进行简单的介绍。详细的讲解带来的多半是困倦,实战中踩下的每一个坑都将促使你成长。那么,让我们开始一段新的学习之旅吧!
下面是一些常用的RTL级的Verilog语法及其简单的用法描述。我们可以将Verilog与C语言类比记忆,但是,一定要牢记Verilog描述的是并行处理的硬件电路。请注意,代码示例中的<>符号是为了标识中文,并无其它特殊含义。
该语法在每一个Verilog文件中都会出现,是一个相对固定的用法,格式如下:
module module_name(<端口信号列表>...);
<逻辑代码>...
endmodule
值得注意的是,module_name是模块的名称,可以是数字、下划线和字母的组合。为了后续维护方便,尽量利用模块英文名称的缩写命名或者根据用途差分模块命名。端口信号列表中应当罗列出该模块所有的输入/输出端口信号名。
我么可以将硬件电路分为许多的部分,每个部分完成指定的功能,也就是我们前面提到的module。很显然,不同的module之间需要通过信号线连接。对于某一个module来说,这些信号便可以分为输入(input)信号、输出(output)信号和双向(inout)信号。
你肯定还没有忘的是:你可以在module语法的端口信号列表中声明该模块用于与外部接口的信号。你将会面临两个选择:
具体如下:
// 1. 在端口信号列表中直接声明输入输出类型。
module module_name(input clk, input rst_n, output [7:0] data_out);
<逻辑代码>...
endmodule
// 2. 在逻辑代码部分声明端口的输入输出类型。
module module_name(clk, rst_n, data_out);
input clk;
input rst_n;
output [7:0] data_out;
...
endmodule
第一个和第二个声明均表示1bit的输入信号端口,而第三个表示8bits的名称为data_out的输出信号。另外,对于我来说,我更加习惯于第一种选择,即在端口信号列表中直接声明输入输出类型,因此之后的例子都将以第一种方式呈现。
parameter主要用来声明一些常量(虽说是常量,但可以利用defparam修改,我们可以先不考虑),使得模块移植和升级变得更加方便,同时,可读性大大提高。反正我才不想因为一个参数的修改去翻看我那又臭又长的代码!
仍然以前面的代码为例:
// 2. 在逻辑代码部分声明端口的输入输出类型。
module module_name(clk, rst_n, data_out);
input clk;
input rst_n;
output [7:0] data_out;
parameter PERIOD = 1000000;
endmodule
可以看到,此处我采用大写字母进行参数定义,这是为了与普通内部信号进行区分,另外,参数命名时仍然建议体现参数的含义。
这是一个比较重要的概念。累了的话,大可以休息一下,再接着战斗。其实是我累了,哈哈哈哈哈。
如下图RTL电路所示,在时钟上升沿到来时,reg将会锁存最新的输入数据,而wire就是这两个reg之间的直接连线。

值得注意的是:作为 input 或 inout 的信号端口只能是wire类型,而output则可以是wire也可以是reg。
一些常见用法如下:
// 定义一个wire信号
wire <变量名>;
// 给一个定义的wire信号直接连接赋值
wire <变量名> = <常量或变量赋值>;
// 这实际上等价于如下形式:
wire <变量名>;
assign <变量名> = <常量或变量赋值>;
// 定义一个多bit的wire信号
wire [<最高位>,<最低位>] <变量名>;
// 定义一个reg信号
reg <变量名>
// 对reg信号赋初值
// 这与前面所说的wire信号赋值是不同的
// wire的赋值将在右边操作数发生变化时便重新执行
reg <变量名> = <初始值>
// 定义一个多bit的reg信号
reg [<最高位>,<最低位>] <变量名>;
// 定义一个赋初值的多bit的reg信号
reg [<最高位>,<最低位>] <变量名> = <初始值>;
// 定义一个二维的多bit的reg信号,可以想象成一个矩阵
reg [<最高位>,<最低位>] <变量名> [<最高位>,<最低位>];
这其实很好理解,就类似与C语言中的“{ }”。主要有两种形式:
// 含有命名的begin语句
begin : <块名>
// 逻辑
end
// 基本的begin语句
begin :
// 逻辑
end
这与C语言也是非常类似的,但是我们仍然需要特别注意硬件电路是并行执行的。那么,该语法应该对应到什么样的电路呢?直接举个例子吧。
// 以下代码实现了在clk上升沿到来时,输出两个输入中的较小值
module test(
input din1,
input din2,
input clk,
output reg dout
);
always@(posedge clk)
begin
if(din1 < din2)
dout <= din1;
else if(din1 > din2)
dout <= din2;
else
dout <= dout;
end
endmodule
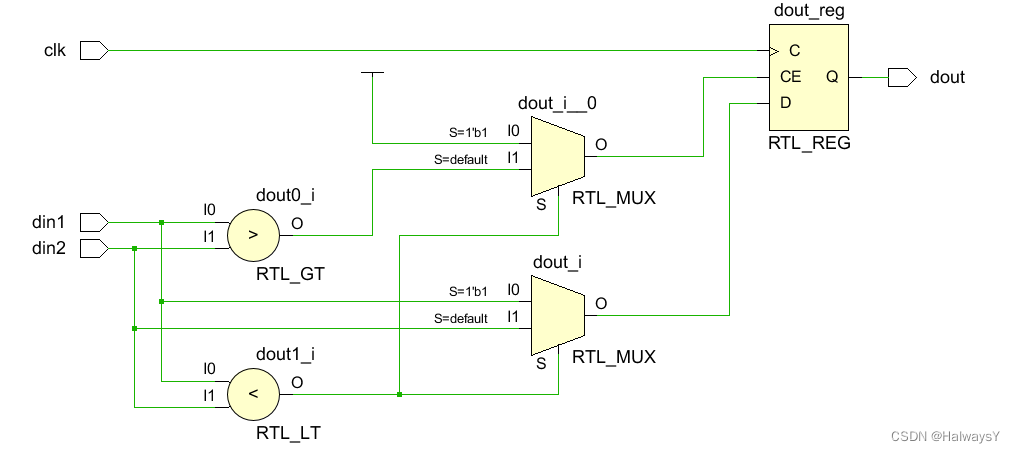
相对应的RTL级电路如图所示,我们可以发现if…else语句可通过多路复用器实现,并实现并行计算。同时,我们还可以发现,两个复用器的控制信号均为RTL_LT的输出,这是由于上述代码中的小于判断具备更高的优先级。大家可以自行与C语言中的if…else语句作一个比较,相信大家会对并行执行与顺序执行有更加深入的理解。
case语句与if…else的硬件实现并没有什么本质不同。与C语言中类似的是:若分支较多则可以考虑采用case语法,原因何在?将上述代码做一些修改,并查看其RTL级电路:
module test(
input din1,
input din2,
input clk,
output reg dout
);
wire temp;
assign temp = (din1<din2);
always@(posedge clk)
begin
case(temp)
1'b1:dout <= din1;
1'b0:dout <= din2;
default:dout <= dout;
endcase
end
endmodule
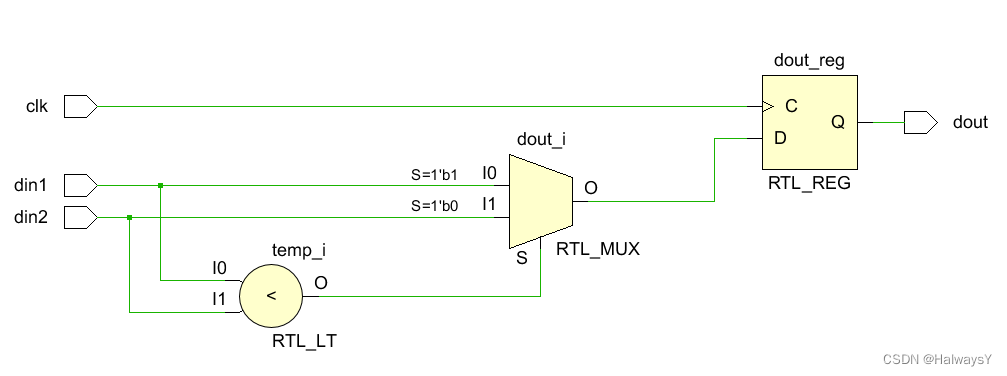
我们发现使用case语句占用的资源变少了,这是因为case语句中的各分支不具有优先级。
因此,如果你的设计中对各分支条件并没有优先级的要求,完全可以考虑采用case语句;反之,if…else语句将会成为较优选择。
for循环用的比较少,且结构与C语言类似,其示例如下:
for{<变量名> = <初始值>; <判断表达式>; <变量名> = <新值>}
begin
<具体逻辑>
end
读者可以尝试编写一段简单的for循环代码,并查看其RTL级电路。
为了便于理解,我们可以将task与C语言中的子函数类比。task中也可以有input、output 和 inout端口作为出入口参数,并可以实现时序控制。值得注意的是:C语言子函数可以有返回值,而task是没有返回值的。但其出口参数可以实现参数返回,类似于C语言中的指针。基本用法如下:
task <task_name>
// 可选声明部分,例如localparam
begin
// 具体逻辑
end
endtask
在这里依然是简要介绍,将在具体实例中展示其具体用法。
assign,按照我浅薄的知识理解,我们可以把等号两边的信号用导线相连接,这与你在现实中拿导线把两个端口连接起来没有区别,这便是赋值的概念。也因此,这样的连接跟时序无关,只要电压的值改变了另一端的值也会同时改变,这便是连续的概念。所以只能利用assign对wire类型变量进行赋值,而不能对reg变量赋值。用法如下:
assign <wire变量名> = <变量或常量>;
对于“?:”,这本质上就是一个简单的if…else语句。区别在于:“?:”主要用在组合逻辑中(可搭配assign使用),而if…else时常用在时序逻辑中。例如:
assign dout = (din1>din2)?din1:din2;
我们可以看看其RTL级电路与(6)有什么区别?
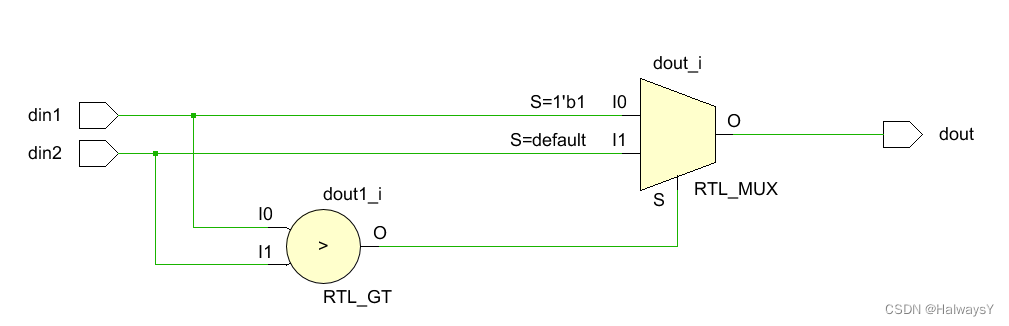
可以发现该电路与(6)中case语句对应的电路仅相差了一个触发器,这说明“?:”语句也不具有优先级。另外,虽然只相差一个触发器,但实现的功能却相差甚远,读者可自行思考(可考虑赋值的时刻)。
用法如下:
always@(<敏感表>)
begin
<具体逻辑>
end
敏感表可以为电平、边沿(上升沿posedge/下降沿negedge),也可以是“ * ”,这代表所有输入信号。
一般来说,如果敏感表为电平,则表示电平发生变化时,将执行此块逻辑;如果敏感表中有边沿信号,将在到达指定边沿时执行逻辑,因此多为时序逻辑。
各种逻辑操作符、移位操作符、算术操作符大多是可综合的。如下所示:
+ //加
- //减
! //逻辑非
~ //取反,注意与!区别
& //位与
~& //与非
| //位或
~| //或非
^ //异或
^~ //同或
~^ //同或
* //乘,是否可综合需要看综合工具
/ //除,是否可综合需要看综合工具,一般要求除数为整数,且为2的指数
% //取模
<< //逻辑左移
>> //逻辑右移,高位补零
< //小于
<= //小于等于
> //大于
>= //大于等于
== //逻辑相等,仅能判断0与1是否相等,若存在高阻态或不定态,则结果为不定态。若存在不定态或高阻态,在仿真中可以考虑使用全等符号===,但其不可综合。
!= //逻辑不等,可与==类比
&& //逻辑与
|| //逻辑或
{} //位拼接符,可将两个或多个信号的某些位拼接起来进行运算。
“=”和“<=”分别表示阻塞和非阻塞赋值,将在后续实例中进一步介绍。
可综合语法只是Verilog中很小的一个子集,硬件设计的精髓是用最简单的语句描述最复杂的硬件。因此,对于做RTL级设计来说,掌握好上面这些基本语法是非常非常重要的!
下一篇将谈谈代码风格与书写规范,这一问题并没有标准答案,但好的代码风格和书写规范可以有效的提高FPGA设计的效率。
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
在Ruby类中,我重写了三个方法,并且在每个方法中,我基本上做同样的事情:classExampleClassdefconfirmation_required?is_allowed&&superenddefpostpone_email_change?is_allowed&&superenddefreconfirmation_required?is_allowed&&superendend有更简洁的语法吗?如何缩短代码? 最佳答案 如何使用别名?classExampleClassdefconfirmation_required?is_a
可能已经问过了,但我找不到它。这里有2个常见的情况(对我来说,在编程Rails时......)用ruby编写是令人沮丧的:"astring".match(/abc(.+)abc/)[1]在这种情况下,我得到一个错误,因为字符串不匹配,因此在nil上调用[]运算符。我想找到的是比以下内容更好的替代方法:temp="astring".match(/abc(.+)abc/);temp.nil??nil:temp[1]简而言之,如果不匹配,则简单地返回nil而不会出错第二种情况是这样的:var=something.very.long.and.tedious.to.writevar=some
我正在学习Ruby的基础知识(刚刚开始),我遇到了Hash.[]method.它被引入a=["foo",1,"bar",2]=>["foo",1,"bar",2]Hash[*a]=>{"foo"=>1,"bar"=>2}稍加思索,我发现Hash[*a]等同于Hash.[](*a)或Hash.[]*一个。我的问题是为什么会这样。是什么让您将*a放在方括号内,是否有某种规则可以在何时何地使用“it”?编辑:我的措辞似乎造成了一些困惑。我不是在问数组扩展。我明白了。我的问题基本上是:如果[]是方法名称,为什么可以将参数放在括号内?这看起来几乎——但不完全是——就像说如果你有一个方法Foo.d
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?
这个问题在这里已经有了答案:WhatisRuby'sdouble-colon`::`?(12个答案)关闭8年前。什么是::?@song||=::TwelveDaysSong.new
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl
我使用Jekyll运行博客,并认为我会解决RedcarpetMarkdown解释器,因为它是developedandusedbyGitHub.好吧,我只是碰巧遇到了一个错误,去检查问题,然后foundthis.Maintainersays,"Asyouprobablyhavenoticed(harharharhar)Idon'thavetimetomaintainRedcarpetanymore.It'snotapriorityforme(IfindMarkdownthoroughlyboring)andit'snotapriorityforGitHub,becausewenolong