ShardingSphere 支持两种方式来扩展自定义算法:SPI 和 ClassBased。CLASS_BASE实际上是已经实现了的SPI。
ClassBased需要我们实现StandardShardingAlgorithm接口。
首先创建一个springboot工程,并添加sharding-sphere依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.0</version>
</dependency>
新建一个类DemoAlgortihm并实现StandardShardingAlgorithm接口。
public class DemoAlgortihm implements StandardShardingAlgorithm<Integer> {
/**
* 精确查询分片执行接口
* @param availableTargetNames: 可用的分片名集合(分库就是库名,分表就是表名)
* @param preciseShardingValue: 分片键
* @return 分片名
*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Integer> preciseShardingValue) {
// availableTargetNames: 分片集合
// preciseShardingValue: 分片键值
String logicTableName = preciseShardingValue.getLogicTableName();
// 获取分片键value
Integer userIdL = preciseShardingValue.getValue();
// 实现 t_order$->{user_id % 2} BigInteger userId = BigInteger.valueOf(userIdL);
BigInteger result = userId.mod(new BigInteger("2"));
String key = logicTableName+""+result;
if (availableTargetNames.contains(key)) {
return key;
}
throw new UnsupportedOperationException("route: " + key + " is not supported, please check your config");
}
/**
* 范围查询分片算法(分片键涉及区间查询时会进入该方法进行分片计算)
* @param availableTargetNames
* @param rangeShardingValue
* @return 返回多个分片名
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Integer> rangeShardingValue) {
// 对于取模算法分片,无法确定查询区间里涉及的分片,因此直接返回所有路由
return availableTargetNames;
}
// 自定义算法参数
@Getter
private Properties props;
@Override
public void init(Properties properties) {
}
}
打包放在sharding-proxy的lib目录。注意打包时不能使用springboot插件进行打包,打包后包结构一定要如下所示,否则无法正确找到自定义算法。这种形式的打包并不会引入依赖,因此如果自定义算法需要引入其他jar包时,我们要手动把依赖的包也一并放到sharding-proxy的lib目录。
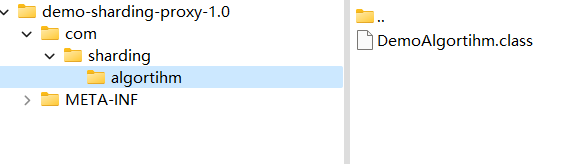
修改config-sharding.yaml文件添加数据分片规则
alg_hash_mod:
# type: HASH_MOD
# props:
# sharding-count: 2
type: CLASS_BASED
props:
strategy: standard # 我们实现的是StandardShardingAlgorithm接口,因此属于standard策略
# 自定义算法全限定类名
algorithmClassName: com.sharding.algortihm.DemoAlgortihm
完整配置文件
databaseName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:13307/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password: sunday
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password: sunday
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order${0..1}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: alg_mod
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: alg_hash_mod
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
keyGenerators:
snowflake:
type: SNOWFLAKE
shardingAlgorithms:
alg_mod:
type: MOD
props:
sharding-count: 2
alg_hash_mod:
# type: HASH_MOD
# props:
# sharding-count: 2
type: CLASS_BASED
props: # 算法参数,可以在下面自定义自己的参数,获取时通过自定义算法中的props对象获取。参数值仅支持字符串和数字,不支持对象、map等参数,对于map等参数可以按照字符串形式传入程序,然后通过JSON工具反序列化。
strategy: standard # 我们实现的是StandardShardingAlgorithm接口,因此属于standard策略
# 自定义算法全限定类名
algorithmClassName: com.sharding.algortihm.DemoAlgortihm
配置分片表后,并没有生成相应的分片表,需要连接上sharding-proxy,在proxy中执行建表语句,在创建逻辑表时分片表会被proxy自动按照配置的规则进行创建。
CREATE TABLE `t_order` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`order_no` varchar(30) DEFAULT NULL,
`user_id` bigint(20) DEFAULT NULL,
`amount` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=779468255126355969 DEFAULT CHARSET=utf8mb4;
INSERT INTO `sharding_db`.`t_order`(`id`, `order_no`, `user_id`, `amount`) VALUES (779468213359476737, '22', 22, 22.00);
INSERT INTO `sharding_db`.`t_order`(`id`, `order_no`, `user_id`, `amount`) VALUES (779468285585391617, '44', 44, 44.00);
INSERT INTO `sharding_db`.`t_order`(`id`, `order_no`, `user_id`, `amount`) VALUES (779468168534949888, '11', 11, 11.00);
INSERT INTO `sharding_db`.`t_order`(`id`, `order_no`, `user_id`, `amount`) VALUES (779468255126355968, '33', 33, 33.00);
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些