文章目录
阻塞队列本质上还是一种队列, 和普通队列一样, 遵循先进先出, 后进后出的规则, 但阻塞队例相比于普通队列的特殊之处在于阻塞队列的阻塞功能, 主要基于多线程使用.
基于阻塞队列的阻塞特性是可以实现 “生产者消费者模型” 的, 那么什么是生产者消费者模型呢?
还是用生活中的例子来解释, 这不还有半个月就要过年了, 大年当晚我们会吃年夜饭, 饺子就是年夜饭当中的一份主食, 那么要想吃到饺子, 最好就是一家人在一起把饺子包好, 简单来讲包饺子的步骤有: 擀饺子皮+包饺子.
有下面两种包饺子方式 :
其实第二种包饺子方式就是生产者消费者模型的运用, 擀饺子皮的那个人就是生产者, 其他负责包饺子的人就是消费者, 放饺子皮的盖帘就相当于阻塞队列, 如果擀饺子皮的人擀的太慢生产的饺子皮供不上使用, 不一会盖帘上没皮了, 包饺子的人就得等一会儿再包; 如果擀饺子的人擀的太快了, 包的速度跟不上擀的速度, 盖帘上放满了饺子皮, 擀饺子皮的人就得等一会儿再擀.
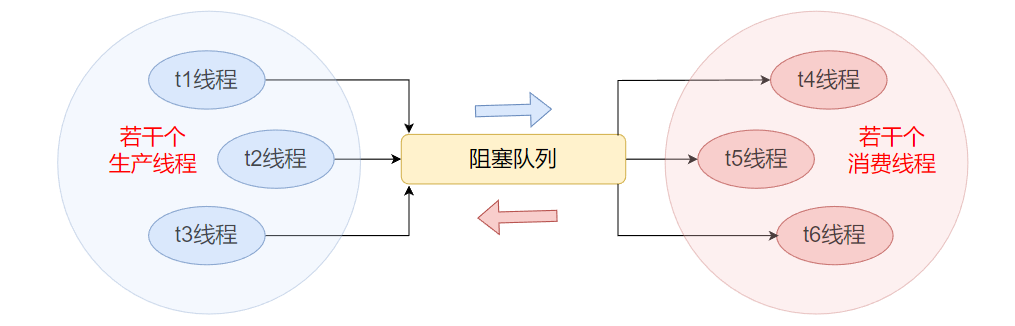
生产者消费者模型能够给程序带来两个非常重要的好处, 一是可以实现实现了发送方和接收方之间的 “解耦” , 二是可以 “削峰填谷” , 保证系统的稳定性, 具体理解如下:
在服务器相互调用的场景中假设有两个服务器A(请求服务器), B(应用服务器), A把请求转发给B处理, B处理完了把结果反馈给A, 这种情况下, A和B之间的耦合是比较高的, A要调用B, A 务必要知道B的存在, 如果B挂了, 很容易引起A的bug, 再比如再加一个C服务器, 此时也需要对A修改不少代码, 就需要针对A重新修改代码, 重新测试, 重新发布, 重新部署等, 这就非常麻烦了.
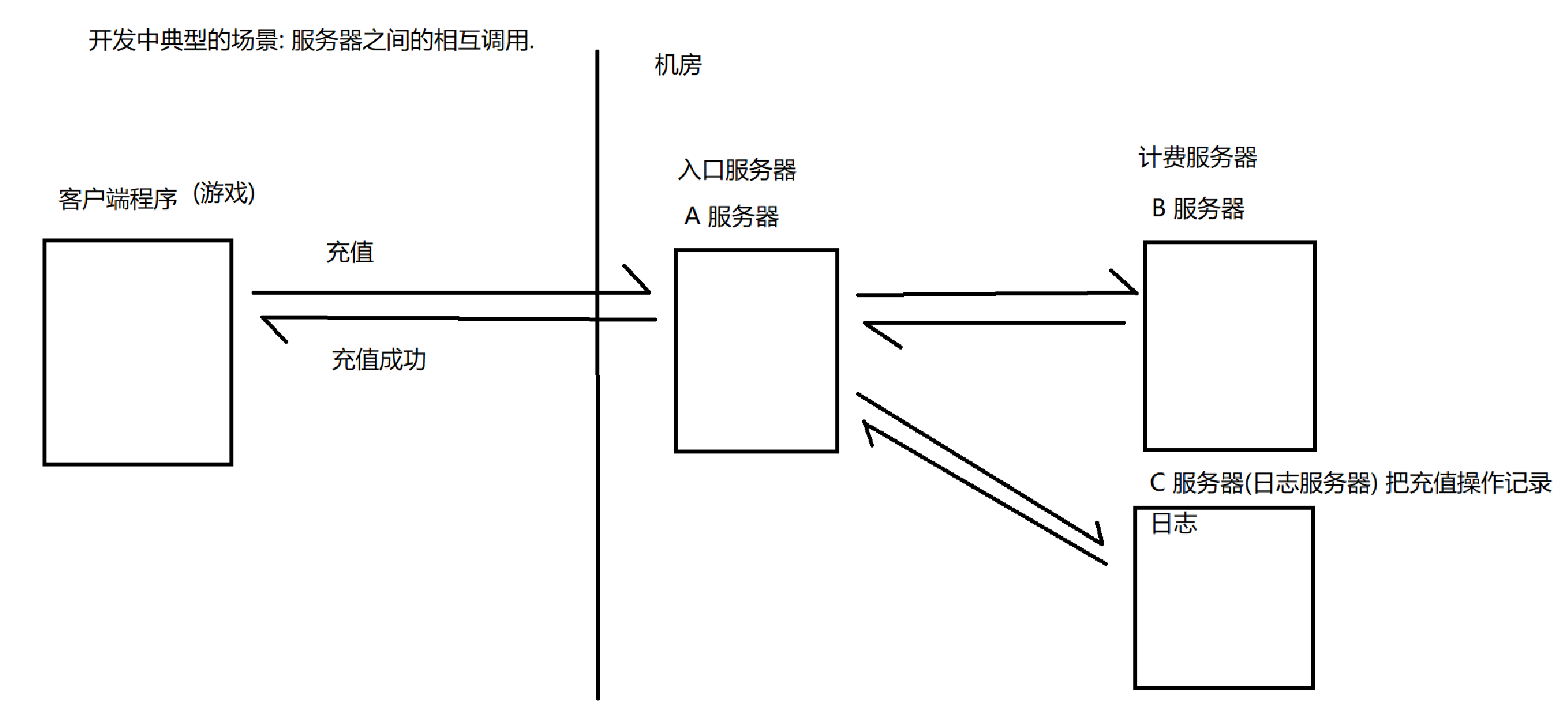
而针对上述场景, 使用生产者消费者模型就可以有效的降低耦合,
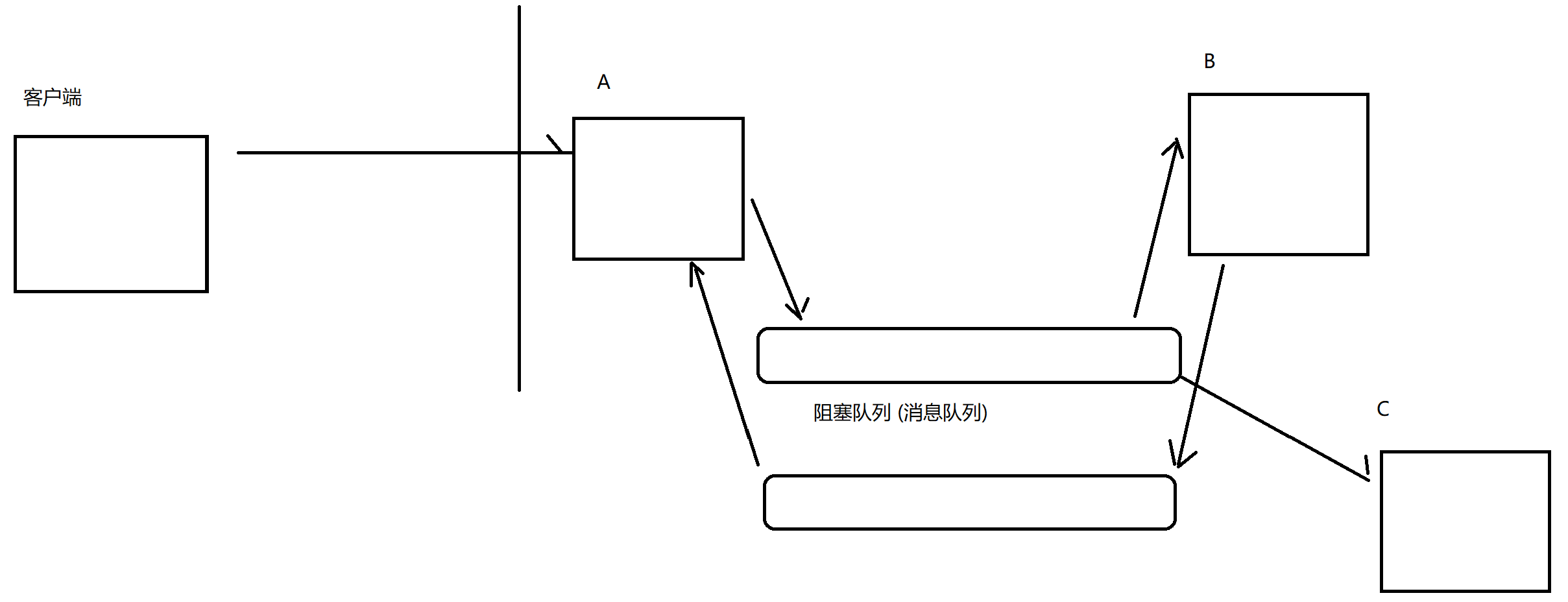
A和B之间通过一个阻塞队列来通信, 此时A是不知道B的, A只知道队列, 也就是说A的代码中没有任何一行代码和B相关; 同样的, B也是不知道A的, B也是只知道队列, B的代码中,也没有任何一行代码和A相关.
如果B挂了, 对于A没有任何影响, 因为队列还是正常的, A仍然可以给队列插入元素, 如果队列满就先阻塞等待; 同样如果A挂了, 也对于B没啥影响, 队列是正常的B就仍然可以从队列取元素, 如果队列空了, 也就阻塞等待就好了; 也就是说, AB任何一方挂了不会对对方造成影响, 同时, 新增一个C来作为消费者, 对于A来说仍然是无感知的.
“削峰填谷” 可以联想三峡大坝的水库, 三峡大坝的水库,

如果上游水多了, 三峡大坝就会关闸蓄水, 此时就相当于由三峡大坝承担了上游的冲击, 对下游起到了很好的保护左右, 这就是 “削峰” 作用; 如果上游水少了, 三峡大坝开闸放水, 有效保证下游的用水情况, 避免出现干旱灾害, 这就是 “填谷” 作用.
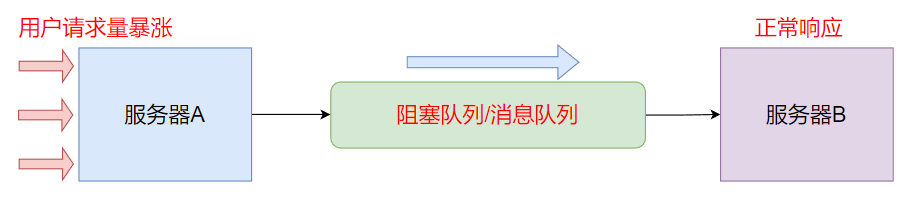
而在服务器开发中, 上游就是用户发送的请求, 下游就是一些执行具体业务的服务器, 用户发多少请求这是不可控的, 有的时候请求多, 有的时候请求少, 而如果没有使用生产者消费者模型, A服务器用户请求暴涨, 此时如果没有充分的准备, B服务器来不及响应一下没抗住, 就可能会挂掉.
但是, 如果使用生产者消费者模型, 那么即使A服务器请求暴涨, 也不会影响到B, 这是因为A请求暴涨后, 用户的请求都被打包到阻塞队列中(如果阻塞队列有界, 则会引起队列阻塞, 不会影响到B), B可以从阻塞队列中取出元素以合适的速度来处理这些请求, 这就是 “削峰填谷” 的作用了.
Java标准库也提供了阻塞队列的标准类, 常用的有下面几个:
阻塞队列类的核心方法:
| 方法 | 解释 |
|---|---|
| void put(E e) throws InterruptedException | 带有阻塞特性的入队操作方法 |
| E take() throws InterruptedException | 带有阻塞特性的出队操作方法 |
| boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException | 带有阻塞特性的入队操作方法, 并且可以设置最长等待时间 |
| E poll(long timeout, TimeUnit unit) throws InterruptedException | 带有阻塞特性的出队操作方法, 并且可以设置最长等待时间 |
注意 : 其他一些重载的offer, poll等普通队列方法也是支持使用的, 但是这些方法就不带有阻塞功能了.
代码示例:
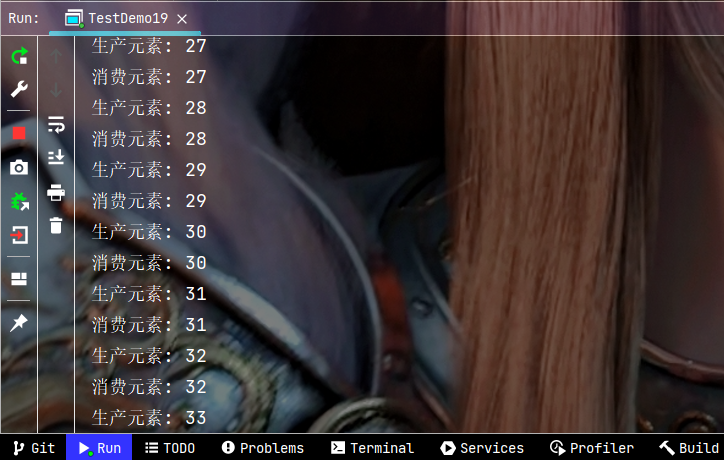
下面的代码是基于标准库的阻塞队列简单实现的生产者消费者模型.
public class TestDemo19 {
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>();
//消费者线程
Thread customer = new Thread(() -> {
while (true) {
try {
Integer result = blockingQueue.take();
System.out.println("消费元素: " + result);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
customer.start();
//生产者线程
Thread producer = new Thread(() -> {
int count = 0;
while (true) {
try {
blockingQueue.put(count);
System.out.println("生产元素: " + count);
count++;
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
producer.start();
}
}
执行结果:
要实现一个阻塞队列, 需要先实现一个普通的循环队列, 循环队列是基于数组实现的, 这里最重要的是如何将队列为空状态与满状态区分开来, 对于这里的实现不懂得可以看看看我前面博客中关于循环队列的内容, 这里就是不做过多的赘述了 : 队列与集合Queue,Deque的理解和使用 , 用栈实现队列,用队列实现栈,设计循环队列 , 阻塞队列最核心的就是出队和入队操作, 所以我们这里重点实现这两个方法, 代码如下:
//普通的循环队列
class MyBlockingQueue {
//存放元素的数数组
private int[] items = new int[1000];
//队头指针
private int head = 0;
//队尾指针
private int tail = 0;
//记录队列元素的个数
private int size = 0;
//入队操作
public void put (int val) {
if (size == items.length) {
//队列满了
return;
}
items[tail++] = val;
//等价于 tail %= items.length
if (tail >= items.length) {
tail = 0;
}
size++;
}
//出队操作
public Integer take() {
int resulet = 0;
if (size == 0) {
//队列空了
return null;
}
resulet = items[head++];
//等价于 head %= elem.length
if (head >= items.length) {
head = 0;
}
size--;
return resulet;
}
}
首先要实现的阻塞队列在大多数情况下是在多线程情况下使用的, 所以要考虑线程安全问题, 上面循环队列的代码take与put方法都有写操作, 直接加锁即可.
//线程安全的循环队列
class MyBlockingQueue {
//存放元素的数数组
private int[] items = new int[1000];
//队头指针
private int head = 0;
//队尾指针
private int tail = 0;
//记录队列元素的个数
private int size = 0;
//入队操作
public void put (int val) {
synchronized (this) {
if (size == items.length) {
//队列满了
return;
}
items[tail++] = val;
//等价于 tail %= items.length
if (tail >= items.length) {
tail = 0;
}
size++;
}
}
//出队操作
public Integer take() {
int resulet = 0;
synchronized (this) {
if (size == 0) {
//队列空了
return null;
}
resulet = items[head++];
//等价于 head %= elem.length
if (head >= items.length) {
head = 0;
}
size--;
return resulet;
}
}
}
然后就是实现阻塞效果了, 主要是使用wait和notify实现线程的阻塞等待.
入队时, 队列满了需要使用wait方法使线程阻塞, 直到有元素出队队列不满了再使用notify通知线程执行.
出队时, 队列为空也需要使用wait方法使线程阻塞, 直到有新元素入队再使用notify通知线程执行.
代码如下:
class MyBlockingQueue {
//存放元素的数数组
private int[] items = new int[1000];
//队头指针
private int head = 0;
//队尾指针
private int tail = 0;
//记录队列元素的个数
private int size = 0;
//入队操作
public void put (int val) throws InterruptedException {
synchronized (this) {
if (size == items.length) {
//队列满了,阻塞等待
this.wait();
}
items[tail++] = val;
//等价于 tail %= items.length
if (tail >= items.length) {
tail = 0;
}
size++;
//唤醒因队列空造成的阻塞wait
this.notify();
}
}
//出队操作
public Integer take() throws InterruptedException {
int resulet = 0;
synchronized (this) {
if (size == 0) {
//队列空了,阻塞等待
this.wait();
}
resulet = items[head++];
//等价于 head %= elem.length
if (head >= items.length) {
head = 0;
}
size--;
//唤醒因队列满造成的阻塞wait
this.notify();
return resulet;
}
}
}
上述代码已经基本实现了阻塞队列的功能, 但不够完善, 这里的代码再改良一下把判断队列满或者空的wait部分的代码, 把if改成while是更好的, 为什么这样写呢?
我们思考当代码中当wait被唤醒的时候, 此时if的条件一定就不成立了吗?
具体来说, 思考put方法中的wait被唤醒, 往下执行是要要求,队列不满但是wait被唤醒了之后, 队列一定是不满的嘛? 其实当前代码中是不会出现这样的问题的, 但是稳妥起见, 最好的办法就是wait唤醒之后再判定一下条件是否满足, 而且Java标准库当中就是建议这么写的.

调整部分的代码如下:
//出队部分
while (size == items.length) {
//队列满了,阻塞等待
this.wait();
}
//入队部分
while (size == 0) {
//队列空了,阻塞等待
this.wait();
}
最后就是测试一下我们所写的这个阻塞队列了, 我们创建两个线程分别是消费者线程customer和生产者线程producer, 生产者生产数字, 消费者消费数字, 为了让执行结果中的阻塞效果明显一些, 我们可以使用sleep方法来控制一下生产者/消费者的生产/消费的频率, 这里我们让开始时生产的速度快一些, 消费的速度慢一些, 全部代码如下:
class MyBlockingQueue {
//存放元素的数数组
private int[] items = new int[1000];
//队头指针
private int head = 0;
//队尾指针
private int tail = 0;
//记录队列元素的个数
private int size = 0;
//入队操作
public void put (int val) throws InterruptedException {
synchronized (this) {
while (size == items.length) {
//队列满了,阻塞等待
this.wait();
}
items[tail++] = val;
//等价于 tail %= items.length
if (tail >= items.length) {
tail = 0;
}
size++;
//唤醒因队列空造成的阻塞wait
this.notify();
}
}
//出队操作
public Integer take() throws InterruptedException {
int resulet = 0;
synchronized (this) {
while (size == 0) {
//队列空了,阻塞等待
this.wait();
}
resulet = items[head++];
//等价于 head %= elem.length
while (head >= items.length) {
head = 0;
}
size--;
//唤醒因队列满造成的阻塞wait
this.notify();
return resulet;
}
}
}
public class Test {
public static void main(String[] args) {
//消费线程
MyBlockingQueue queue = new MyBlockingQueue();
Thread customer = new Thread(() -> {
while(true) {
try {
int result = queue.take();
System.out.println("消费元素: " + result);
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
customer.start();
//生产线程
Thread producer = new Thread(() -> {
int count = 0;
while (true) {
try {
queue.put(count);
System.out.println("生产元素: " + count);
count++;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
producer.start();
}
}
执行结果:
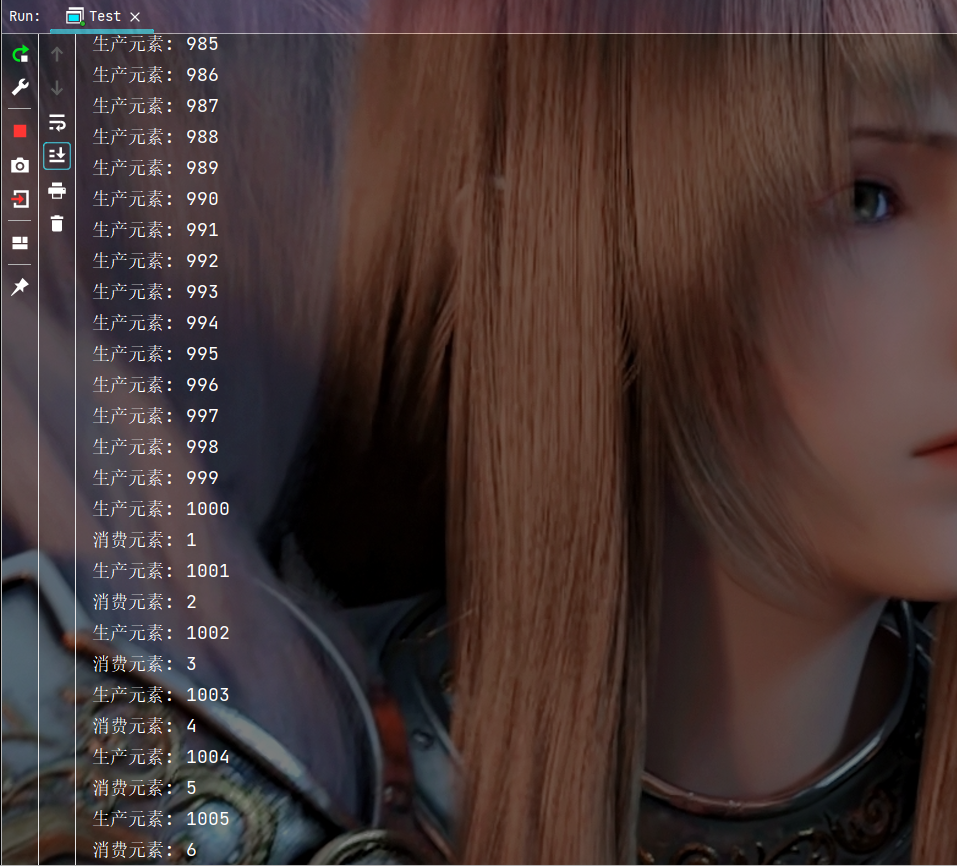
可以看到执行结果中因为生产者生产快, 消费者消费慢, 所以一开始生产者生产的速度是极快的, 当生产到阻塞队列满了之后生产者需要等待消费者消费后才能生产, 此时生产者的速度就跟消费者同步了.
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg