摘要
对于java的kafka集成,一般选用springboot集成kafka,但可能由于对接方kafka老旧、kafka不安全等问题导致kafak版本与spring版本不兼容,这个时候就得自己根据kafka客户端api集成了。
一、springboot集成kafka
具体官方文档地址:https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/
1、加入依赖,spring-boot-starter-web和spring-kafka 的版本号可以看它们依赖的spring版本是否一致,这里pom依赖如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.7.9</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.9.6</version>
</dependency>2、添加application.yml配置,具体如下:
server:
port: 8087
spring:
mvc:
pathmatch:
matching-strategy: ant_path_matcher
kafka:
bootstrap-servers: 192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094
consumer:
properties:
group:
id: boot-kafka
3、发送消息,由于KafkaTemplate是自动装配的,所以只要在spring的bean里注入KafkaTemplate发送消息即可,具体如下:
package com.longqi.bootkafka.controller;
import com.longqi.bootkafka.entity.MessageParam;
import com.longqi.bootkafka.entity.Wrapper;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiParam;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.validation.Valid;
/**
* <p>
* 测试 前端控制器
* </p>
* @author LongQi
* @since 2021-06-23
*/
@Slf4j
@RestController
@RequestMapping("/test")
@Api(value = "TestController", tags = {"测试 API"})
public class TestController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
private Boolean isSend = true;
@PostMapping("/kafka/sendMessage")
@ApiOperation(httpMethod = "POST", value = "发送kafka告警消息", response = Wrapper.class)
public Wrapper sendKafkaMessage(@Valid @ApiParam("参数") @RequestBody MessageParam param) {
kafkaTemplate.send(param.getTopic(), param.getMessage());
return Wrapper.ok(true);
}
}这里用参数{"message": "asd54a6d46a4ds","topic": "device-alarm-test"}进行测试,会报如下日志:
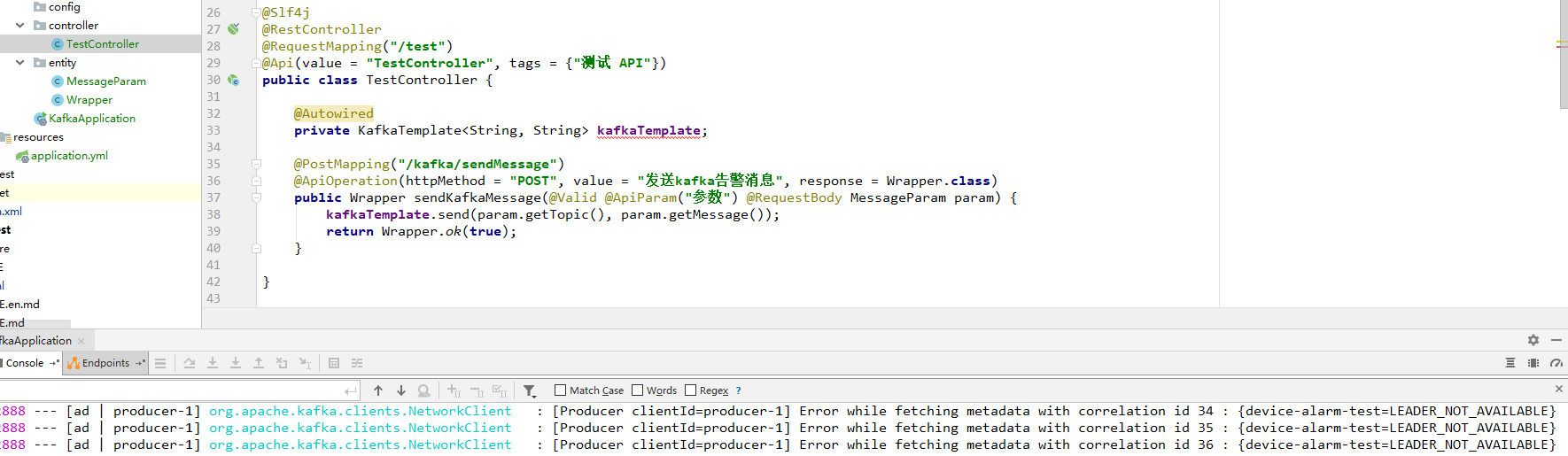
发现会报警告:[Producer clientId=producer-1] Error while fetching metadata with correlation id 34 : {device-alarm-test=LEADER_NOT_AVAILABLE},获取主题元数据错误,这个可以忽略,查找元数据失败,kafka默认会自动创建主题的,后续再次发送消息,是不会报这个错误的。
查看可视化工具EFAK,发现主题device-alarm-test是自动创建成功,分区数是kafka的集群配置service.properties里配置的分区9,具体如下:
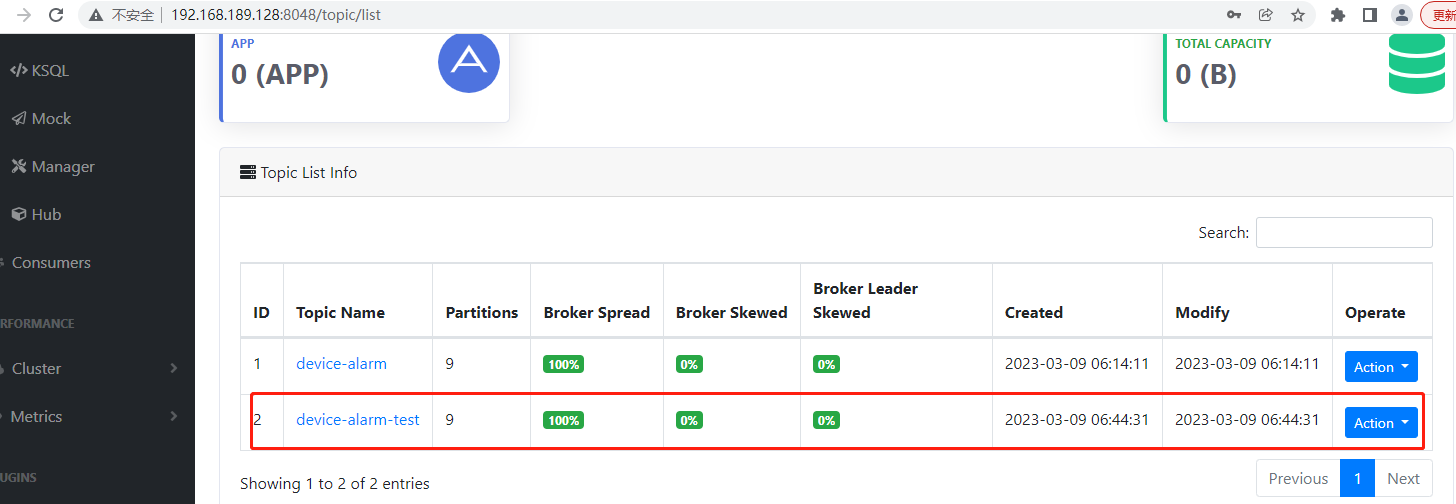

可以看到,其中一个分区保存了这个消息,logsize变成了1,说明这个消息是发送成功的。另外也可以看到主题的各分区主备消息所在的节点是不一样的。
4、接收消息,接收消息也很简单,只要在spring的bean里使用KafkaListener注解即可,具体如下:

可视化工具也能看到该主题该消费者9个分区的消费情况,具体如下:

logSize为存入分区parttion消息数量,Offset为消费的偏移量(已消费的数量),Lag为未消费的数量(积压的数量),Owner为消费者,目前可以看到消费者为同一个,即只有1个线程在消费这9个分区的消息。
二、客户端集成kafka
直接使用kafka客户端,建议使用最新版的客户端,毕竟没有其他框架版本限制,能用最新的就用最新的,毕竟新的一般性能强也修复了bug。好比23年2月份出现的kafka安全漏洞:远程代码执行漏洞CVE-2023-25194,对现在最新版3.4.0无效,对以前大部分版本就有效。
1、添加依赖,具体如下:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.4.0</version>
</dependency>2、发送和消费消息,具体代码如下:
package com.longqi.bootkafka.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* @author LongQi
* @projectName boot-integration
* @description: kafka配置
* @date 2023/3/13 14:42
*/
public class KafkaConfig {
public static void main(String[] args) {
// 声明主题
String topic = "device-alarm-test";
// 创建消费者
Properties consumerConfig = new Properties();
consumerConfig.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094");
consumerConfig.put(ConsumerConfig.GROUP_ID_CONFIG,"boot-kafka");
consumerConfig.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
consumerConfig.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer kafkaConsumer = new KafkaConsumer(consumerConfig);
// 订阅主题并循环拉取消息
kafkaConsumer.subscribe(Arrays.asList(topic));
new Thread(new Runnable() {
@Override
public void run() {
while (true){
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(10000));
for(ConsumerRecord<String, String> record:records){
System.out.println(record.value());
}
}
}
}).start();
// 创建生产者
Properties producerConfig = new Properties();
producerConfig.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094");
producerConfig.put(ProducerConfig.CLIENT_ID_CONFIG,"boot-kafka-client");
producerConfig.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
producerConfig.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer<>(producerConfig);
// 给主题发送消息
producer.send(new ProducerRecord<>(topic, "hello,"+System.currentTimeMillis()));
}
}
最后可以看到打印消息如下:

成功接收到消息并打印
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我一直很高兴地使用DelayedJob习惯用法:foo.send_later(:bar)这会调用DelayedJob进程中对象foo的方法bar。我一直在使用DaemonSpawn在我的服务器上启动DelayedJob进程。但是...如果foo抛出异常,Hoptoad不会捕获它。这是任何这些包中的错误...还是我需要更改某些配置...或者我是否需要在DS或DJ中插入一些异常处理来调用Hoptoad通知程序?回应下面的第一条评论。classDelayedJobWorker 最佳答案 尝试monkeypatchingDelayed::W
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg