Kaggle实战入门:泰坦尼克号生还预测
泰坦尼克号(Titanic),又称铁达尼号,是当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”的美誉,被称为“世界工业史上的奇迹”。1912年4月10日,她在从英国南安普敦出发,驶往美国纽约的首次处女航行中,不幸与一座冰山相撞,1912年4月15日凌晨2时20分左右,船体断裂成两截,永久沉入大西洋底3700米处,2224名船员及乘客中,逾1500人丧生。
而以此事件为背景的《泰坦尼克号》则是成为了电影史上的传奇,该片由詹姆斯•卡梅隆执导,莱昂纳多•迪卡普里奥、凯特•温斯莱特领衔主演。在中国大陆上映的时间是1998年4月,虽然时隔25年,泰坦尼克号也已沉没111年,但每当影片主题曲my heart will go on中悠扬的苏格兰风笛声响起时,每个人都会再次被带回那艘奥林匹克级的豪华邮轮。
机器学习领域,著名的数据科学竞赛平台kaggle的入门经典也是以泰坦尼克号事件为背景。该问题通过训练数据(train.csv)给出891名乘客的基本信息以及生还情况,通过训练数据生成合适的模型,并根据另外418名乘客的基本信息(test.csv)预测其生还情况,并将生还情况以要求的格式(gender_submission.csv)提交,kaggle会根据你的提交情况给出评分与排名。
import pandas as pd
file = r'datasets/train.csv'
data = pd.read_csv(file)
加载数据完成后,可使用内置方法对数据进行探查,初步认识数据。
data.head(5) #查看前5行数据:data.iloc[:5] 或者 data.loc[:5]
输出

data.info() #查看整体信息
输出
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
可以看出,数据共有11个字段,其中Age有714个非空值,而Cabin仅有204个非空值。每个字段含义如下:
| 字段名 | 字段含义 |
|---|---|
| PassengerId | 乘客ID |
| Pclass | 客舱等级 |
| Name | 乘客姓名 |
| Sex | 性别 |
| Age | 年龄 |
| SibSp | 兄弟姐妹、配偶 |
| Parch | 父母与子女 |
| Ticket | 船票编号 |
| Fare | 票价 |
| Cabin | 客舱号 |
| Embarked | 登船港口 |
data.Pclass.unique() #查看字段的取值情况
输出
array([3, 1, 2])
data.Pclass.value_counts() #查看字段取值的统计值
输出
3 491
1 216
2 184
Name: Pclass, dtype: int64
特征工程(Feature Engineering)极其重要,特征的选择与处理直接影响到模型效果。实际中,特征工程很多时候是依赖业务经验的。
通过数据探查,可以发现该数据包含以下几类属性
(1)统计分析各属性与生还结果的相关性
针对Sex、Pclass、Embarkd与Survived的关系,可使用crosstab函数(或groupby函数)分别进行聚合统计,计算相应的百分比以实现归一化,并做图。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] #Mac系统设置中文显示
plt.rcParams['axes.unicode_minus'] = False
fig = plt.figure()
fig.set(alpha=0.65) # 设置图像透明度
ax1=fig.add_subplot(131)
ax2=fig.add_subplot(132)
ax3=fig.add_subplot(133)
cou_Sex = pd.crosstab(data.Sex,data.Survived)
#或者用counts_Sex = data.groupby(['Sex','Survived']).size().unstack
cou_Sex.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
cou_Sex.rename({'female':'F','male':'M'},inplace=True)
pct_Sex = cou_Sex.div(cou_Sex.sum(1).astype(float),axis=0) #归一化
pct_Sex.plot(kind='bar',stacked=True,title=u'不同性别的生还情况',ax=ax1)
cou_Pclass = pd.crosstab(data.Pclass,data.Survived)
cou_Pclass.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Pclass = cou_Pclass.div(cou_Pclass.sum(1).astype(float),axis=0)
pct_Pclass.plot(kind='bar',stacked=True,title=u'不同等级的生还情况',ax=ax2,sharey=ax1)
cou_Embarked = pd.crosstab(data.Embarked,data.Survived)
cou_Embarked.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Embarked = cou_Embarked.div(cou_Embarked.sum(1).astype(float),axis=0)
pct_Embarked.plot(kind='bar',stacked=True,title=u'不同登录点生还情况',ax=ax3,sharey=ax1)
输出

可直观的看出生还情况受性别(女性乘客生还概率较高)、客舱等级(一等舱乘客生还概率较高)、登船港口(C港口登船乘客生还概率较高)的影响。
针对数值属性的Age、Fare,可使用cut函数将其离散化后,再进行统计分析。
fig = plt.figure()
fig.set(alpha=0.65) # 设置图像透明度
ax1=fig.add_subplot(121)
ax2=fig.add_subplot(122)
bins=[0,14,30,45,60,80]
cats=pd.cut(data.Age.as_matrix(),bins) #Age离散化
data.Age=cats.codes
cou_Age = pd.crosstab(data.Age,data.Survived)
cou_Age.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Age = cou_Age.div(cou_Age.sum(1).astype(float),axis=0)
pct_Age.plot(kind='bar',stacked=True,title=u'不同年龄的生还情况',ax=ax1)
bins=[0,15,30,45,60,300]
cats=pd.cut(data.Fare.as_matrix(),bins) #Fare离散化
data.Fare=cats.codes
cou_Fare = pd.crosstab(data.Fare,data.Survived)
cou_Fare.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Fare = cou_Fare.div(cou_Fare.sum(1).astype(float),axis=0)
pct_Fare.plot(kind='bar',stacked=True,title=u'不同票价的生还情况',ax=ax2,sharey=ax1)

可直观的看出年龄越小生还概率越高、票价越高生活概率越高(-1表示缺失值)。
(2)计算相关系数分析各属性与生还结果的相关性
使用corr函数计算属性
a
a
a和
b
b
b之间的相关性
r
(
a
,
b
)
r(a,b)
r(a,b),corr函数默认使用Person系数,取值在
[
−
1
,
1
]
[-1,1]
[−1,1]之间。
def dataProcess(data): #定义数据预处理函数
mapTrans={'female':0,'male':1,'S':0,'C':1,'Q':2} #属性值转换
data.Sex=data.Sex.map(mapTrans)
data.Embarked=data.Embarked.map(mapTrans)
data.Embarked=data.Embarked.fillna(data.Embarked.mode()[0]) #使用众数填充
data.Age=data.Age.fillna(data.Age.mean()) #均值填充缺失年龄
data.Fare=data.Fare.fillna(data.Fare.mean()) #均值填充缺失Fare
return data
data = pd.read_csv(file)#载入数据
data = dataProcess(data)#处理数据
data.iloc[:,1:].corr()['Survived']#计算相关系数
输出
Survived 1.000000
Pclass -0.338481
Sex -0.543351
Age -0.069809
SibSp -0.035322
Parch 0.081629
Fare 0.257307
Embarked 0.106811
Name: Survived, dtype: float64
可以看出Survived与Pclass、Sex、Fare、Embarked相关性较大。
使用seaborn库的热力图可视化展示:
import seaborn as sns #导入seaborn绘图库
sns.set(style='white', context='notebook', palette='deep')
sns.heatmap(data.iloc[:,1:].corr(),annot=True, fmt = ".2f", cmap = "coolwarm")
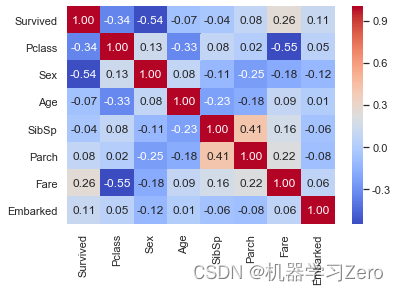
通过上述分析,选择[‘Pclass’, ‘Sex’, ‘Age’, ‘Fare’, ‘Embarked’]作为特征,通过自定义的process函数对数据进行预处理,其中使用map方法将Sex、Embarked映射为数值,并用fillna方法填充Embark、Age、Fare的缺失值。
构建决策树模型,并使用fit方法完成模型的训练。
feature =['Pclass','Sex','Age','Fare','Embarked']
X = data[feature] #选择特征
y = data.Survived #标签
from sklearn.tree import DecisionTreeClassifier as DT
clf = DT() #建立模型
clf.fit(X,y) #训练模型
可使用准确率(score方法)和混淆矩阵(metrics.confusion_matrix方法)对模型进行评估。
print('%.3f' %(clf.score(X,y))) #准确率
输出
0.980
from sklearn import metrics
metrics.confusion_matrix(y, clf.predict(X)) #混淆矩阵
输出
array([[546, 3],
[ 15, 327]])
加载test.csv文件的数据,进行处理,并使用predict方法预测,将生成的结果文件在Kaggle页面点击Submit Predictions进行提交,Kaggle会给出准确率和排名。
data_sub = pd.read_csv(r'datasets/test.csv') #加载测试数据
data_sub = dataProcess(data_sub) #处理测试数据
X_sub = data_sub[feature] #提取测试数据特征
y_sub = clf.predict(X_sub) #使用模型预测数据标签
result = pd.DataFrame({'PassengerId':data_sub['PassengerId'].as_matrix(), 'Survived':y_sub}) #形成要求格式
result.to_csv(r'D:\[DataSet]\1_Titanic\submission.csv', index=False) #输出至文件
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记