
🏆今日学习目标:
🍀SpringCloud五大核心组件
✅创作者:林在闪闪发光
⏰预计时间:30分钟
🎉个人主页:林在闪闪发光的个人主页🍁林在闪闪发光的个人社区,欢迎你的加入: 林在闪闪发光的社区
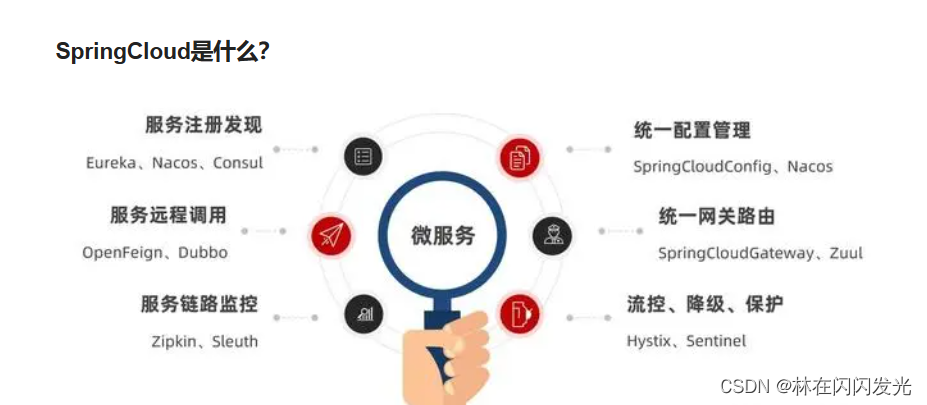

SpringCloud五大组件:
1、注册中心组件(服务治理):Netflix Eureka;
2、负载均衡组件:Netflix Ribbon,各个微服务进行分摊,提高性能;
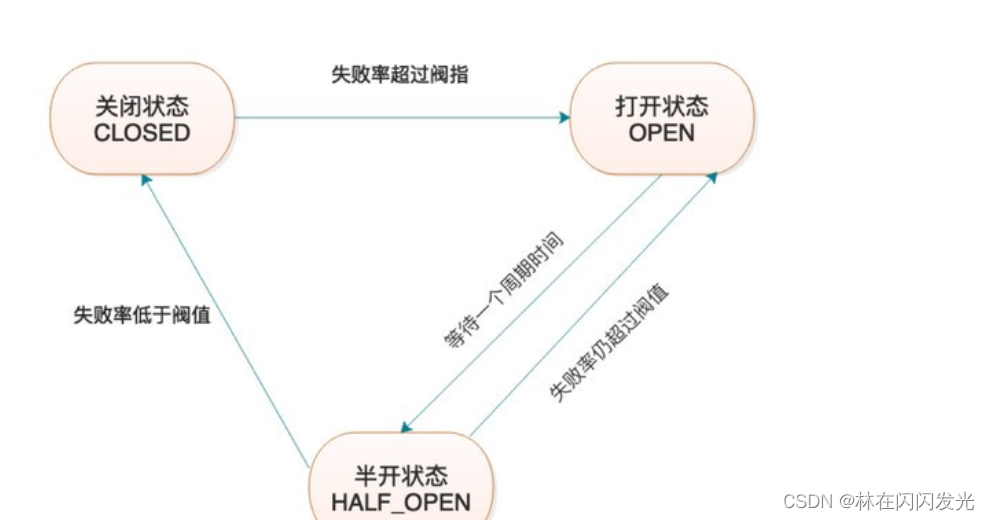
3、熔断器组件(断路器):Netflix Hystrix,Resilience4j ;保护系统,控制故障范围;
4、网关服务组件:Zuul,Spring Cloud Gateway;api网关,路由,负载均衡等多种作用;
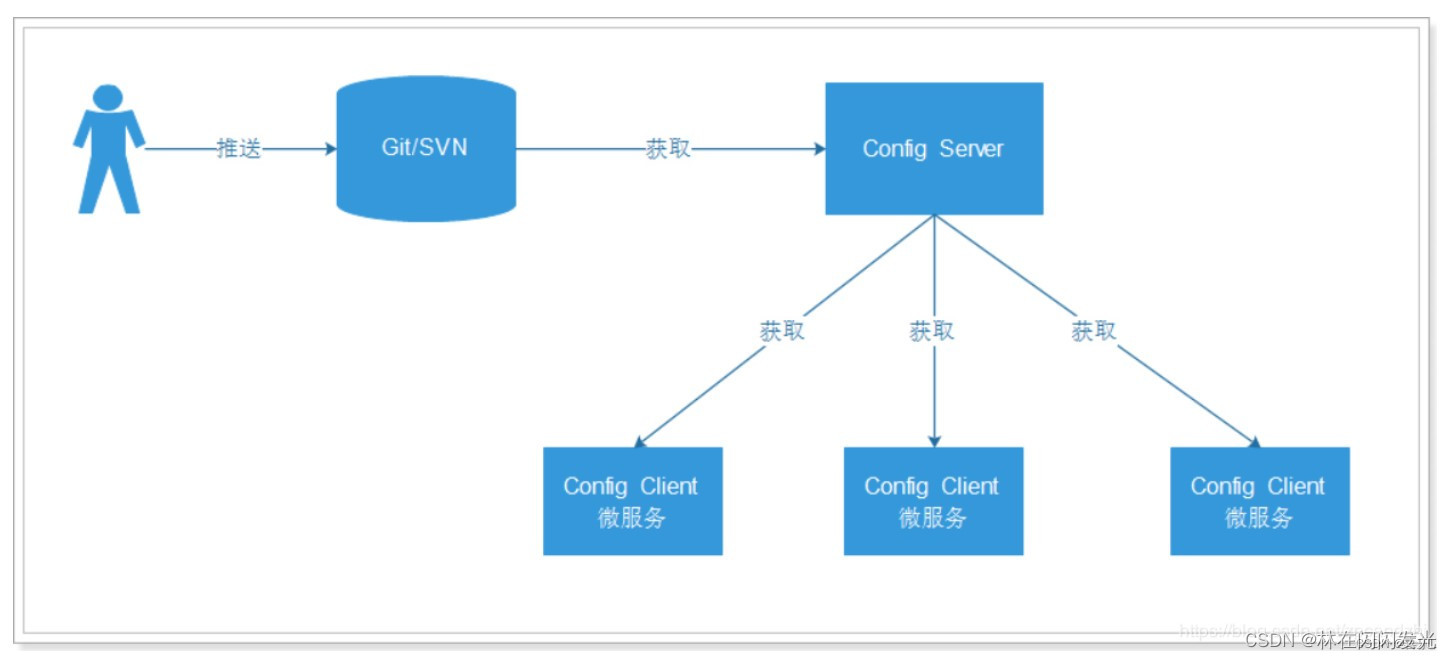
5、配置中心:Spring Cloud Config,将配置文件组合起来,放在远程仓库,便于管理;
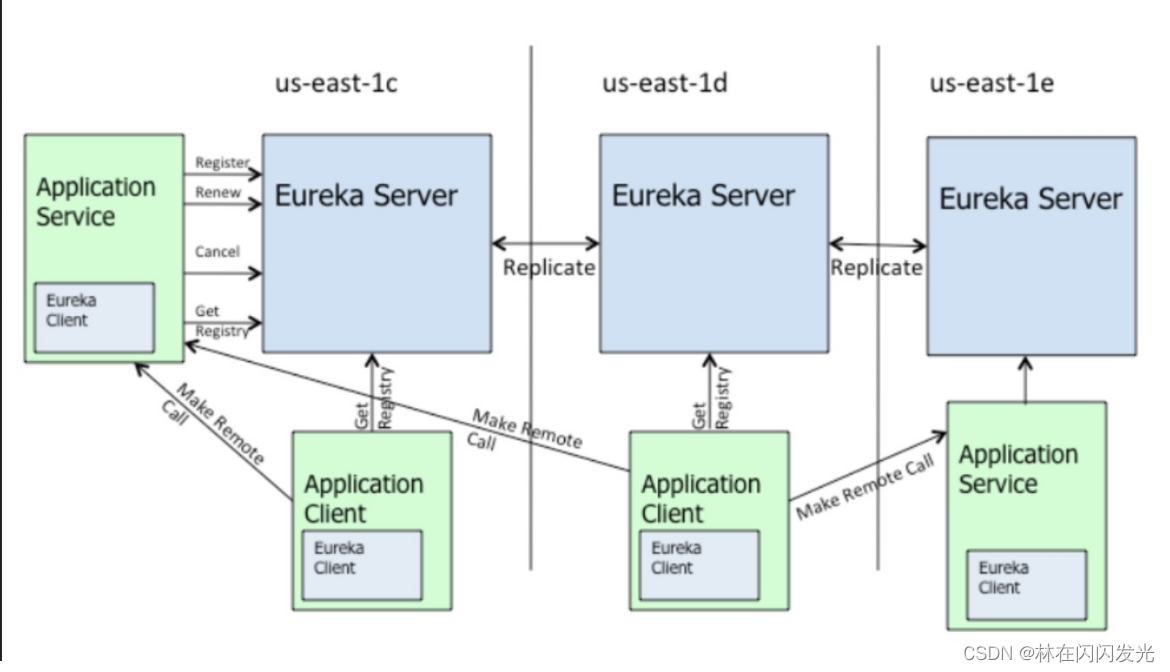
作用:
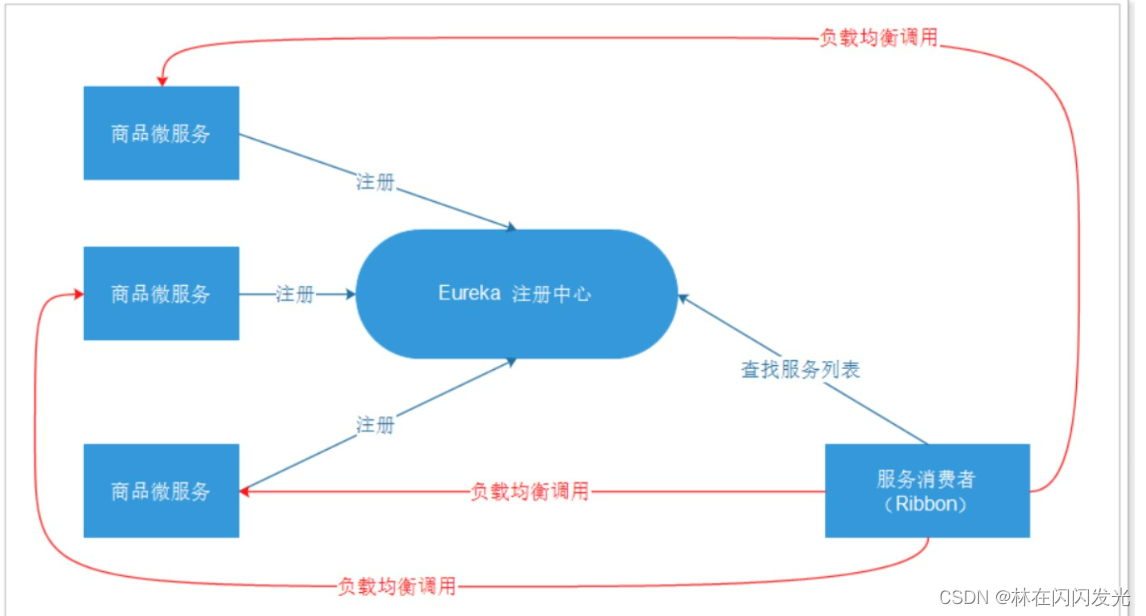
负载均衡策略:
简介:
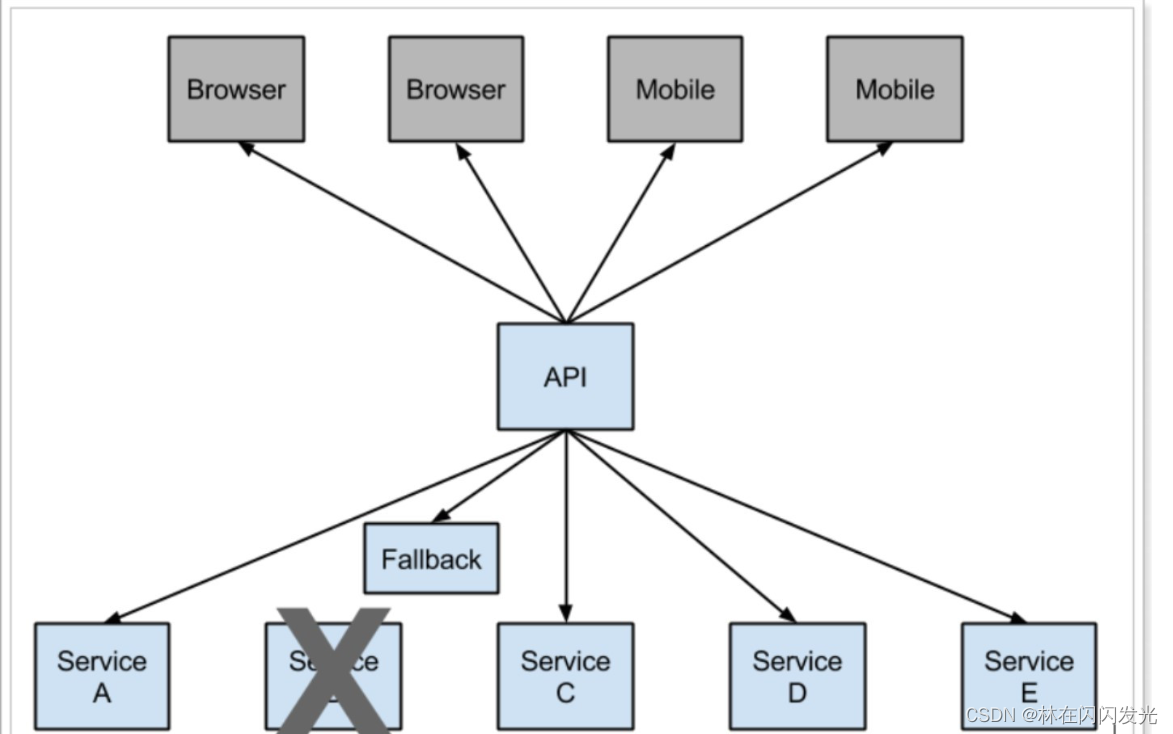
简介:
简介:
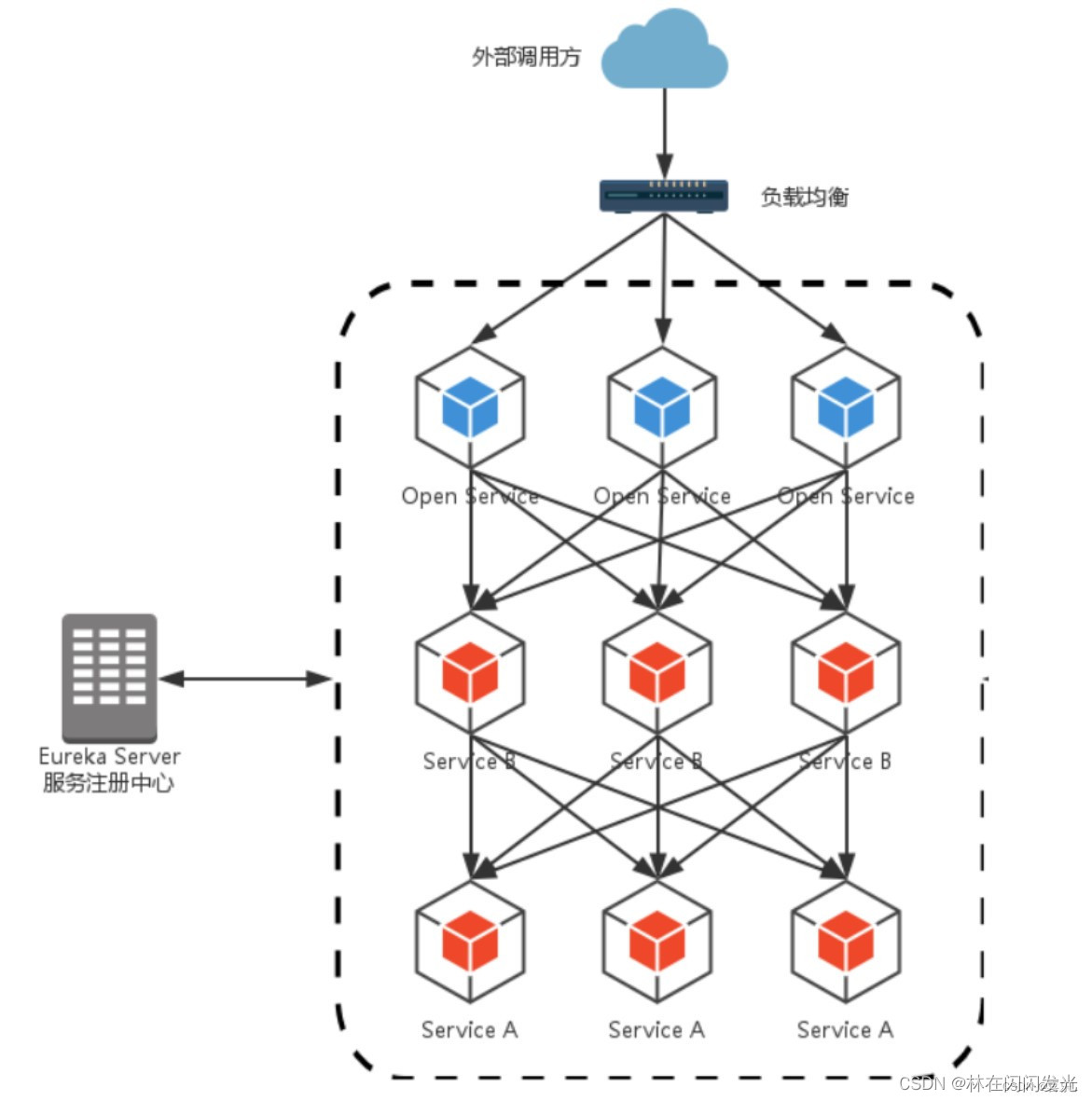
这种架构破坏了服务无状态特点:为了保证对外服务的安全性,我们需要实现对服务访问的权限控制,而 Open Service 的访问权限机制会贯穿并污染整个开放服务的业务逻辑,破坏了集群中 Rest Api 无状态的特点,从具体的开发来说,工作中除了要考虑实际业务逻辑之外,还要额外持续对接口的访问做权限处理;
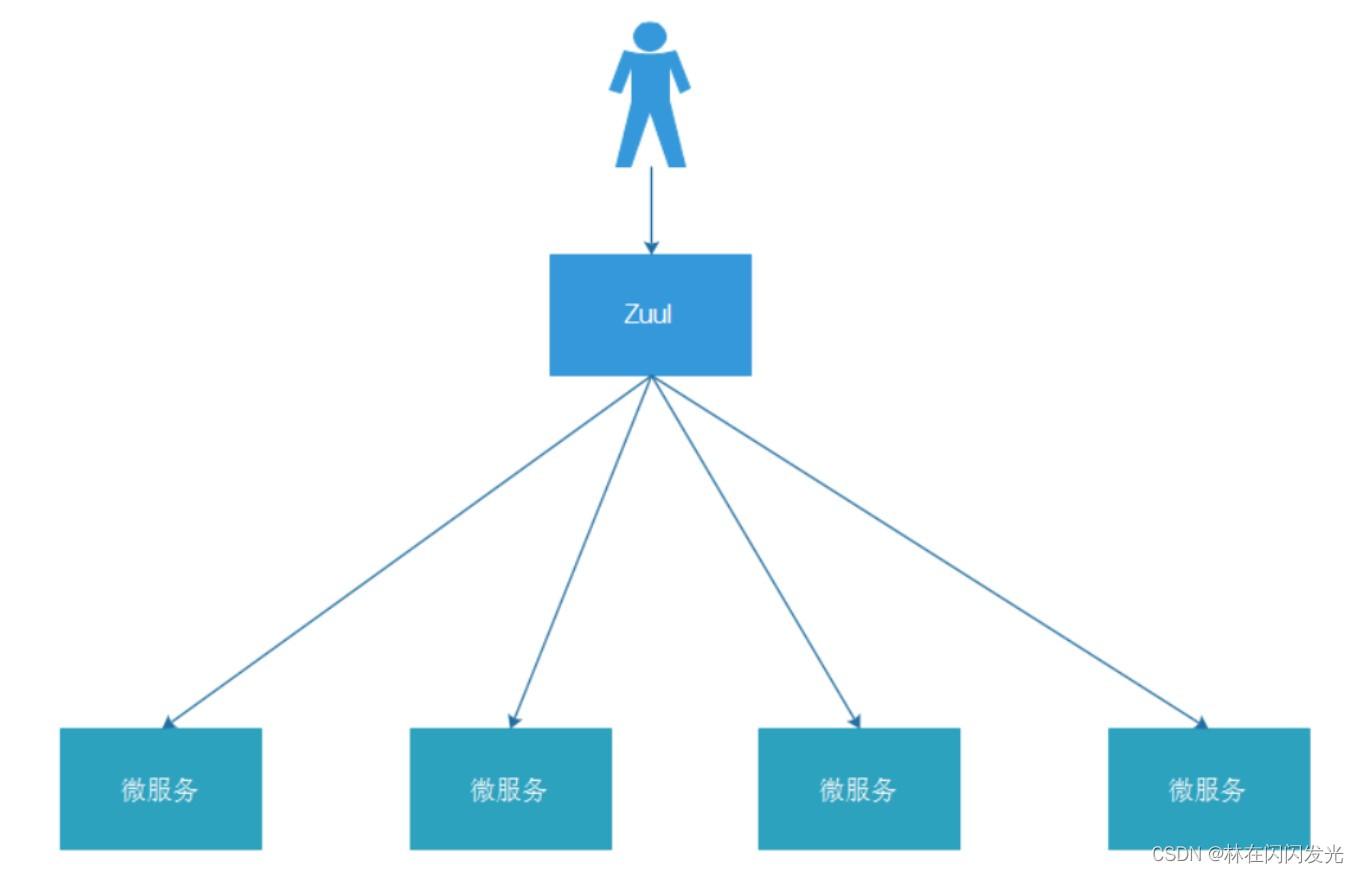
网关服务
将权限控制、日志收集从服务单元中抽离出去,最适合的地方是服务集群的最外端,我们需要一个功能更强大的负载均衡器,网关服务;
网关服务是微服务架构中不可或缺的一部分,它具备统一向外提供 Rest Api、服务路由、负载均衡、权限控制等功能,为微服务架构提供了门前保护,除了安全之外,还能让服务集群具备高可用性和测试性;
Zuul 是 NetFlix 开源的微服务网关,可以和 Eureka、Ribbon、Hystrix 等组件配合使用,其核心是一系列的过滤器;
简介:
配置加载顺序:

目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我经常将预配置的lambda插入可枚举的方法中,例如“map”、“select”等。但是“注入(inject)”的行为似乎有所不同。例如与mult4=lambda{|item|item*4}然后(5..10).map&mult4给我[20,24,28,32,36,40]但是,如果我制作一个2参数lambda用于像这样的注入(inject),multL=lambda{|product,n|product*n}我想说(5..10).inject(2)&multL因为“inject”有一个可选的单个初始值参数,但这给了我......irb(main):027:0>(5..10).inject
是否有self验证的问题列表。看着那个,我可以确定我知道。我应该复习一下。在学习的过程中,我列了一个这样的list,但它只包含我在某处听说过的项目。我需要一段时间才能找到新的东西。 最佳答案 以下是针对ruby和Rails的一些测试列表。证书名称:RubyonRails谁提供:oDeskIncorporation认证费用:免费网站:https://www.odesk.com/tests/985?pos=0证书名称:RubyonRails提供者:Techgig.com(TimesBusinessSolutionsLimited(T
我想覆盖store_accessor的getter。可以查到here.代码在这里:#Fileactiverecord/lib/active_record/store.rb,line74defstore_accessor(store_attribute,*keys)keys=keys.flatten_store_accessors_module.module_evaldokeys.eachdo|key|define_method("#{key}=")do|value|write_store_attribute(store_attribute,key,value)enddefine_met
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
目录SpringBootStarter是什么?以前传统的做法使用SpringBootStarter之后starter的理念:starter的实现: 创建SpringBootStarter步骤在idea新建一个starter项目、直接执行下一步即可生成项目。 在xml中加入如下配置文件:创建proterties类来保存配置信息创建业务类:创建AutoConfiguration测试如下:SpringBootStarter是什么? SpringBootStarter是在SpringBoot组件中被提出来的一种概念、简化了很多烦琐的配置、通过引入各种SpringBootStarter包可以快速搭建出一
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。我一直在Rails上做两个项目,它们运行良好,但在这个过程中重新发明了轮子,自来水(和热水)和止痛药,正如我随后了解到的那样,这些已经存在于框架中。那么基本上,正确了解框架中所有智能部分的最佳方法是什么,这将节省时间而不是自己构建已经实现的功能?从第1页开始阅读文档?是否有公开所有内容的特定示例应用程序?一个特定的开源项目?所有的rails交通?还是完全
假设我有一个函数defodd_or_evennifn%2==0return:evenelsereturn:oddendend我有一个简单的可枚举数组simple=[1,2,3,4,5]然后我用我的函数在map中运行它,使用一个do-endblock:simple.mapdo|n|odd_or_even(n)end#=>[:odd,:even,:odd,:even,:odd]如果不首先定义函数,我怎么能做到这一点?例如,#doesnotworksimple.mapdo|n|ifn%2==0return:evenelsereturn:oddendend#Desiredresult:#=>[
我是Ruby分析的新手,看起来像ruby-prof是一个受欢迎的选择。我刚刚安装了gem并调用了我的程序:ruby-prof./my-prog.rb但是,输出非常冗长,因为包含所有Ruby核心和标准库方法以及其他gem的分析数据。例如,前三行是:8.790.0110.0100.0000.0013343*String#%7.280.0780.0090.0000.0692068*Array#each4.930.0380.0060.0000.0321098*Array#map这对我来说不是什么有用的信息,因为我已经知道我的程序经常处理字符串和数组,并且大概已经对这些类进行了优化。我只关心我代
在以下示例中,我无法理解Ruby运算符的优先级:x=1&&y=2由于&&的优先级高于=,我的理解是类似于+和*运算符:1+2*3+4解析为1+(2*3)+4它应该等于:x=(1&&y)=2但是,所有Ruby源代码(包括内部语法解析器Ripper)都将其解析为x=(1&&(y=2))为什么?编辑[08.01.2016]让我们关注一个子表达式:1&&y=2根据优先规则,我们应该尝试将其解析为:(1&&y)=2这没有意义,因为=需要特定的LHS(变量、常量、[]数组项等)。但是既然(1&&y)是一个正确的表达式,那么解析器应该如何处理呢?我试过咨询Ruby的parse.y,但它太像意大利面条