SAP WM高阶之上架策略P(Storage Unit Type)
SAP WM模块的上架策略P(Storage Unit Type,也叫Pallet),在项目实践中也比较常用。一些企业里货架比较大,同一个Storage bin上可以放置不同类型的托盘若干个。对于此种场景,SAP系统有提供标准上架策略P方便业务人员做上架。
本文就是展示如何使用上架策略P。
1, 存储类型Z04, 上架策略为 P (Storage Unit Type)。
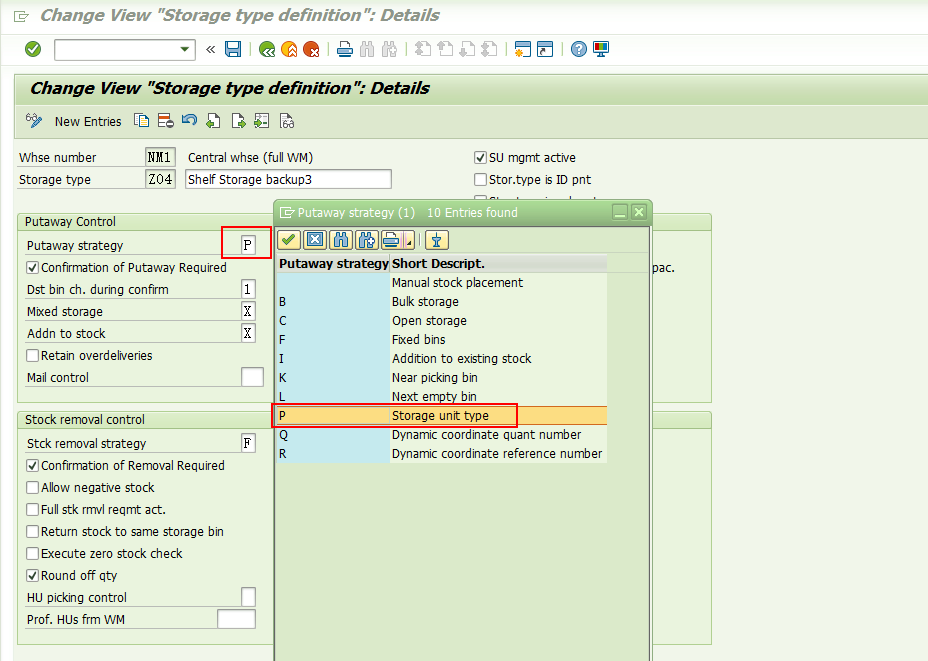
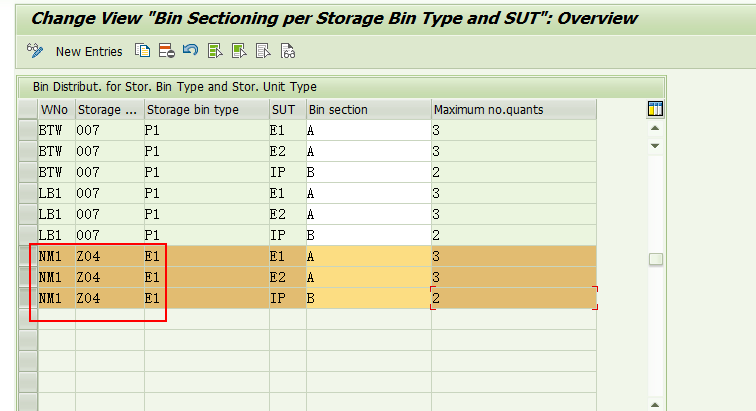
2,上架策略P相关的配置。
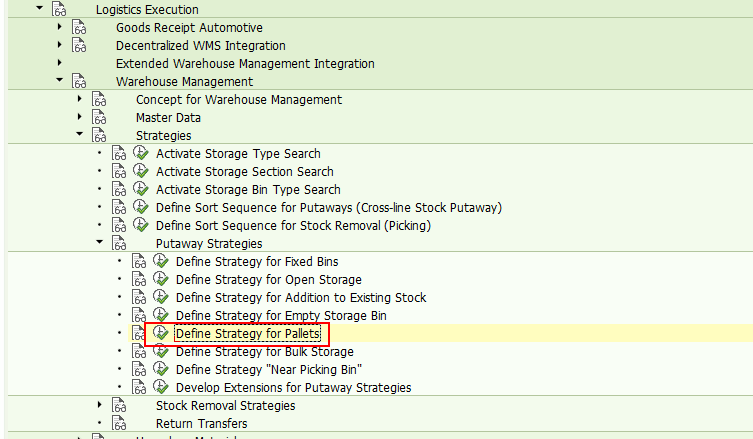
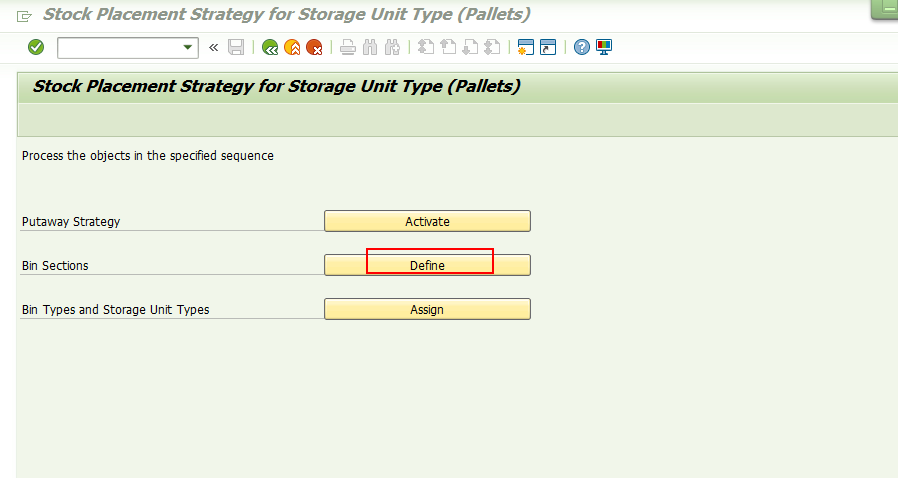

这个配置的意思是存储类型Z04分成2块不同货架区域,A区域和B区域,A区域里每个货架上可以存放三个托盘,B区域里每个货架上可以存放2个托盘。
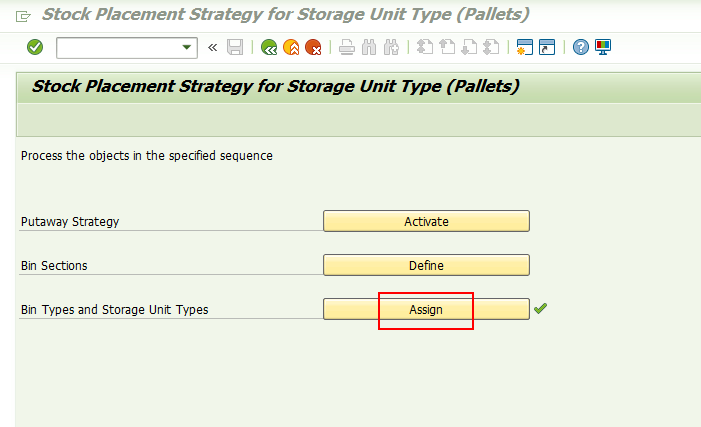
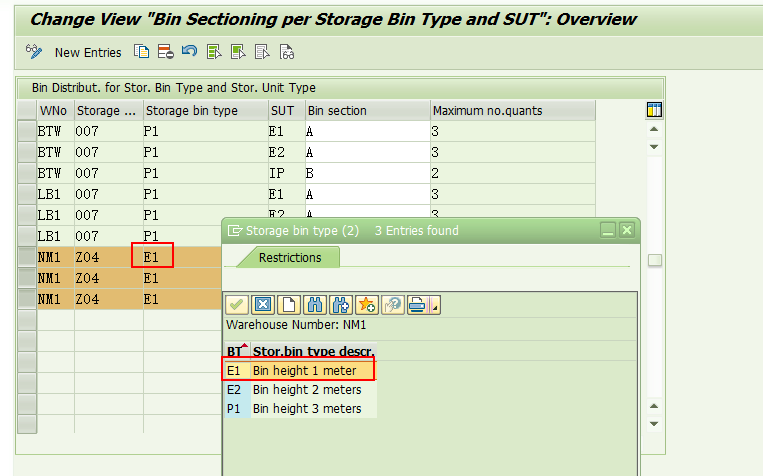
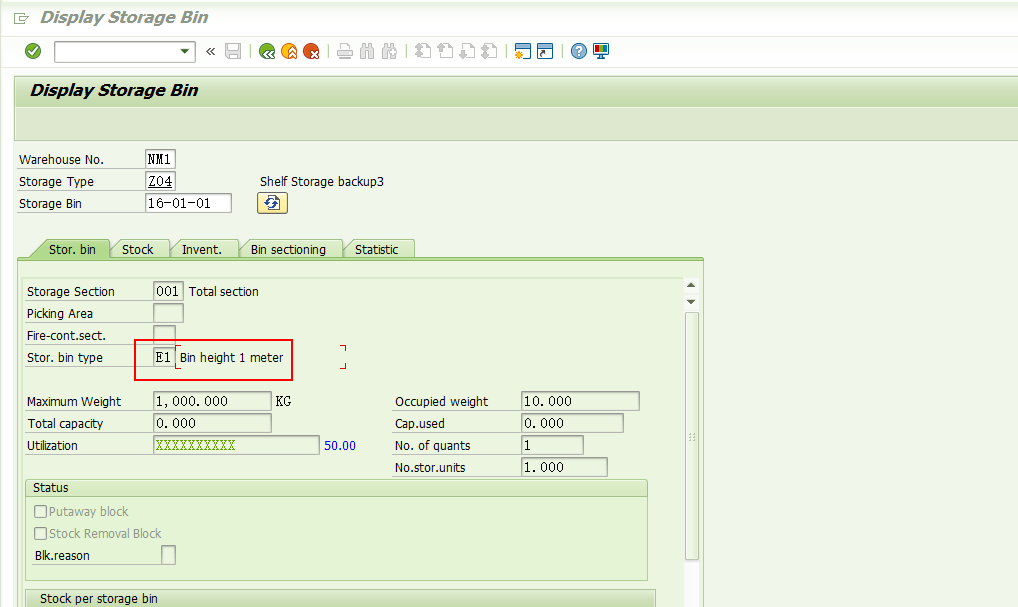
Storage bin type E1,
Storage Unit type E1/E2/IP,
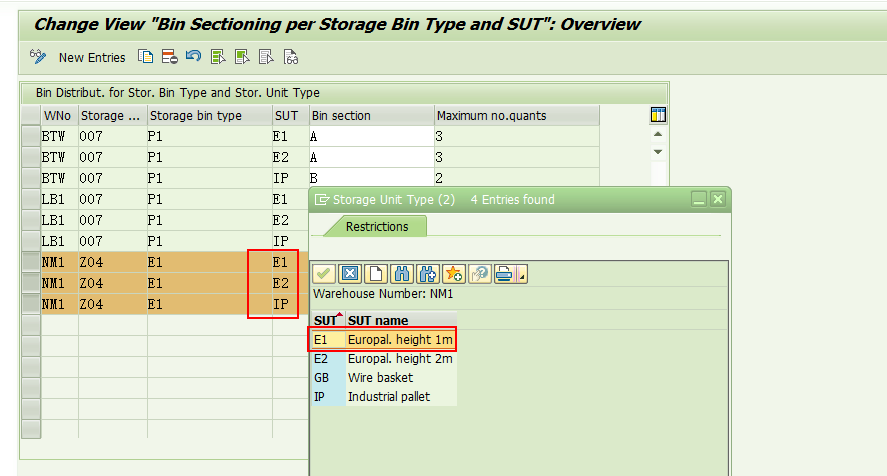
这个配置项的意思是在Z04存储类型里E1类型的货架区域,如果能存放E1/E2类型托盘,则最多可以存放3个;如果存放IP类型的托盘,最多存放2个托盘。
3, 存储类型Z04下已经创建了很多storage bin.
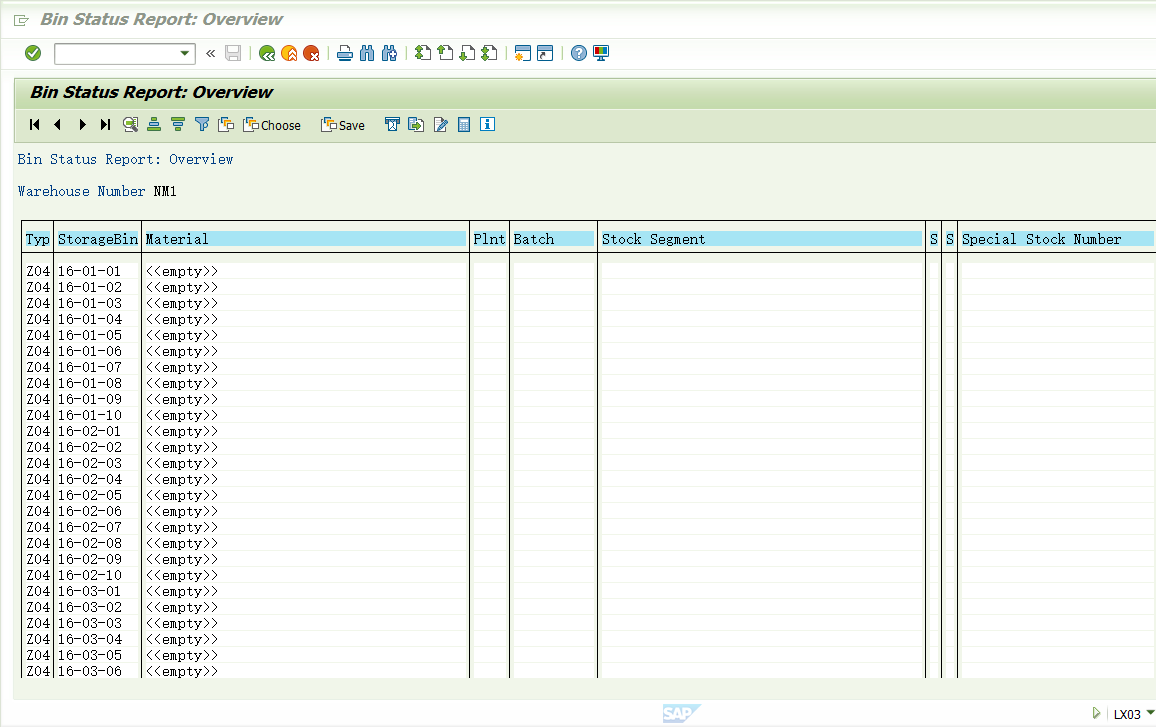
每个storage bin都有指定bin type,
4, 物料792主数据设置。
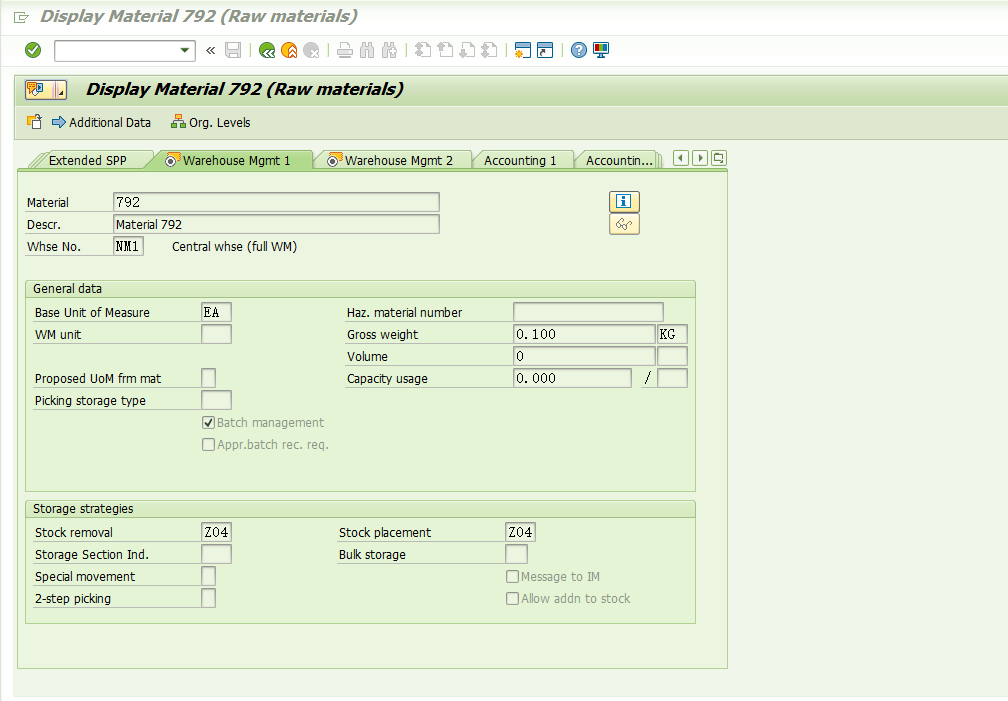
Stock placement indicator Z04. 该物料收货会上架到Z04存储类型,下架的话则会从Z04存储类型下架。
该物料的采购订单,
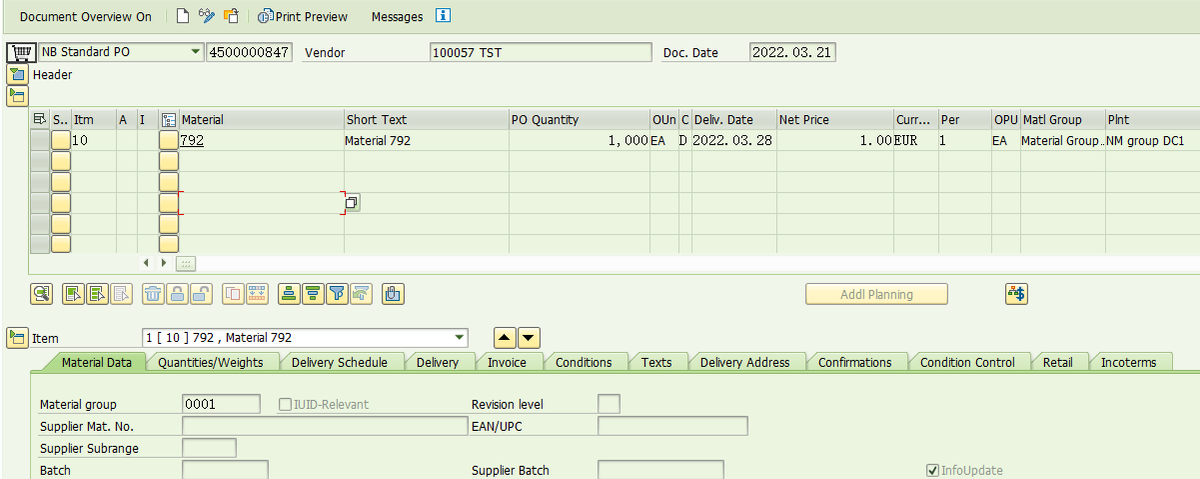
5, 执行事务代码MIGO,对该采购订单执行收货, 过账后完成WM层面的操作。
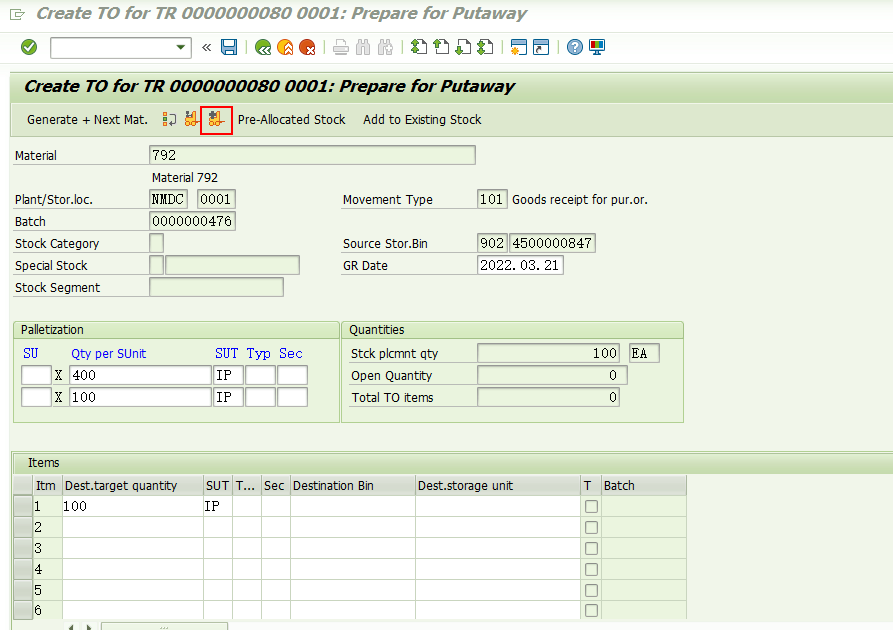
前台执行的方式来创建上架的TO单据,
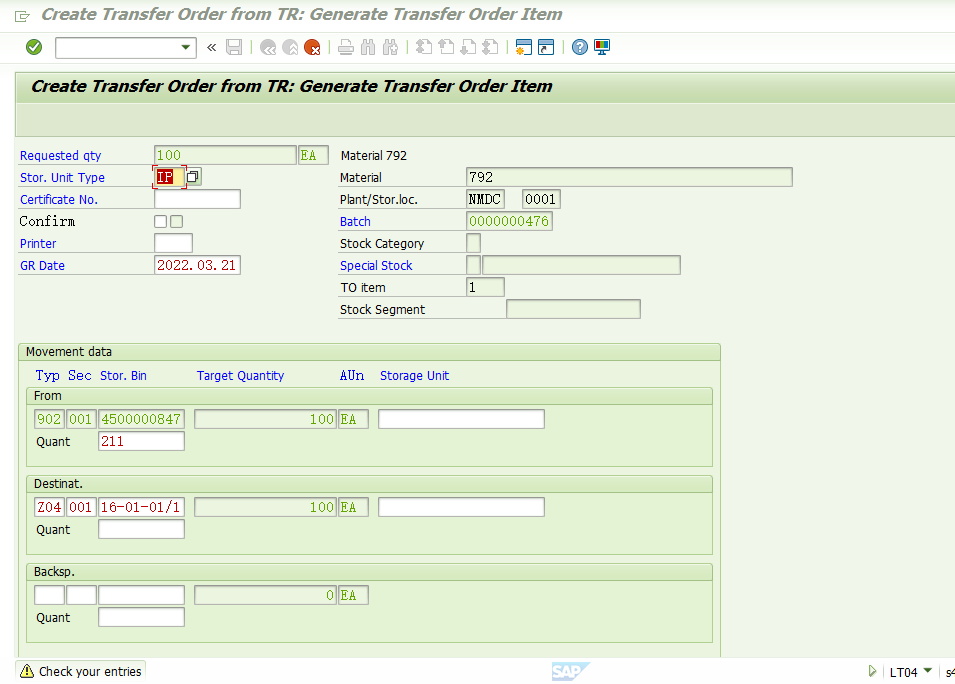
回车,
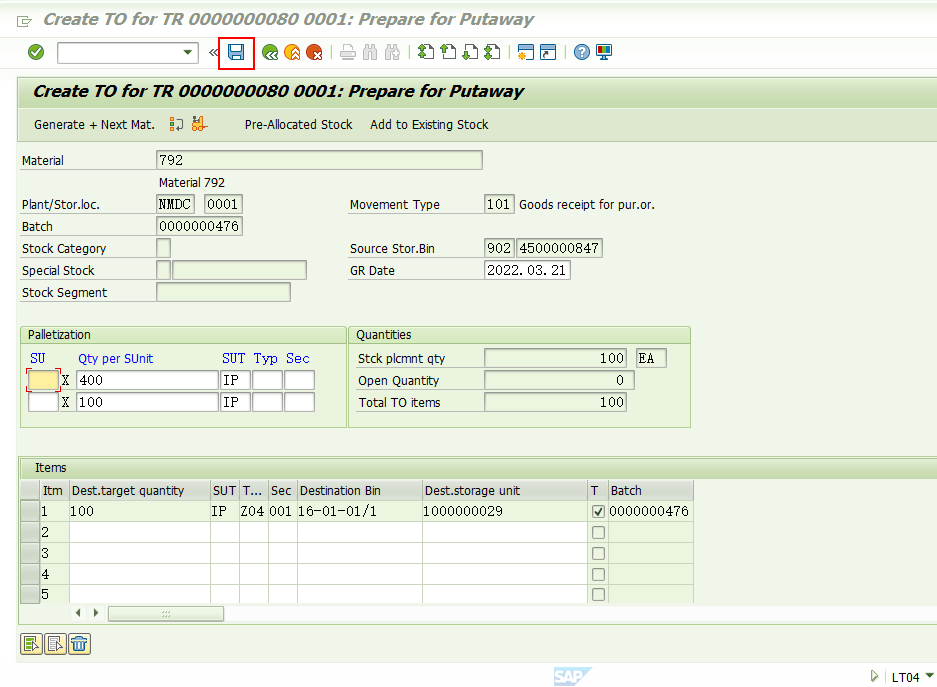
保存,
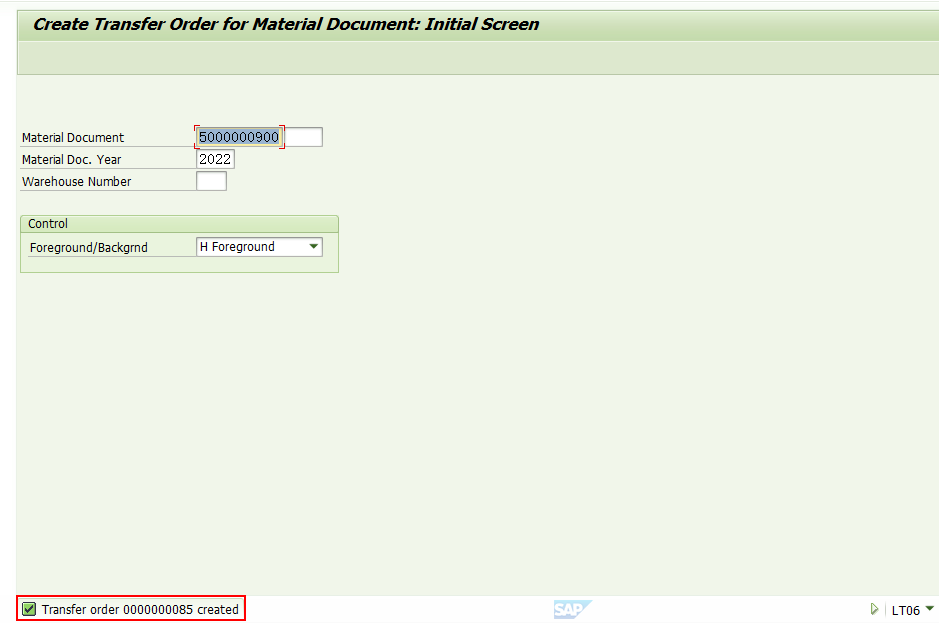
TO单85被创建好了,后续完成TO单据的确认。
注:本文基于SAP S4/HANA 1909系统上。
-完-
写于2022-3-21。
在学习Python之后,我现在正在尝试学习Ruby,但我在将这段代码转换为Ruby时遇到了问题:defcompose1(f,g):"""Returnafunctionh,suchthath(x)=f(g(x))."""defh(x):returnf(g(x))returnh我必须使用block来翻译吗?或者Ruby中是否有类似的语法? 最佳答案 您可以使用Ruby中的lambda执行此操作(我在这里使用的是1.9stabby-lambda):compose=->(f,g){->(x){f.(g.(x))}}所以compose是一个返
我想使用两种不同的protect_from_forgery策略构建一个Rails应用程序:一种用于Web应用程序,一种用于API。在我的应用程序Controller中,我有这行代码:protect_from_forgerywith::exception为了防止CSRF攻击,它工作得很好。在我的API命名空间中,我创建了一个继承self的应用程序Controller的api_controller,它是API命名空间中所有其他Controller的父类,我将上面的代码更改为:protect_from_forgery:null_session.遗憾的是,我在尝试发出POST请求时遇到错误:“
我在阅读有关.each迭代器的Ruby问题,有人说如果更高阶的迭代器更适合该任务,则使用.each可能会产生代码味道。Ruby中的高阶迭代器是什么?编辑:我提到的StackOverflow答案的作者JörgWMittag提到他是要编写更高级别的迭代器,但他还解释了下面的内容。 最佳答案 哎呀。我的意思是更高级别的迭代器,而不是更高阶的迭代器。当然,每个迭代器都是高阶的。基本上,迭代是一个非常低级的概念。编程的目的是与团队中的其他利益相关者交流意图。“初始化一个空数组,然后遍历另一个数组,并将该数组的当前元素添加到第一个数组中(如果该
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
我正在开发一个将XML发布到某些网络服务的小型应用程序。这是使用Net::HTTP::Post::Post完成的。但是,服务提供商建议使用重新连接。类似于:第一个请求失败->2秒后重试第二个请求失败->5秒后重试第三次请求失败->10秒后重试...这样做的好方法是什么?简单地在循环中运行以下代码,捕获异常并在一定时间后再次运行?或者还有其他聪明的方法吗?也许Net包甚至有一些我不知道的内置功能?url=URI.parse("http://some.host")request=Net::HTTP::Post.new(url.path)request.body=xmlrequest.con
我有这个原始文本:________________________________________________________________________________________________________________________________PosCarCompetitor/TeamDriverVehicleCapCLLapsRace.TimeFastest...Lap16JasonClementsJasonClementsBMWM33200109:48.571030:57.3228*242DavidSkillenderDavidSkillenderHo
现在已经为此奋斗了一段时间,不确定为什么它不起作用。要点是希望将Devise与LDAP结合使用。除了身份验证外,我不需要做任何事情,所以除了自定义策略外,我不需要使用任何东西。我根据https://github.com/plataformatec/devise/wiki/How-To:-Authenticate-via-LDAP创建了一个据我所知,一切都应该正常工作,除了每当我尝试运行服务器(或rake路由)时,我得到一个NameErrorlib/devise/models.rb:88:in`const_get':uninitializedconstantDevise::Models:
我正在使用Grape和Rails创建RESTAPI。我有基本的架构,我正在寻找“清理”东西的地方。其中一个地方是错误处理/处理。我目前正在为整个API修复root.rb(GRAPE::API基类)文件中的错误。我格式化它们,然后通过rack_response发回错误。一切正常,但root.rb文件变得有点臃肿,所有错误都被修复,其中一些有需要完成的特殊解析。我想知道是否有人制定了一个好的错误处理策略,以便可以将其移出到它自己的模块中,并使root.rb(GRAPE::API基类)相当精简。我很想创建一个错误处理模块并为每种类型的错误定义方法,例如...moduleAPImoduleEr
我正在开发一个利用twitteroauth的应用程序,但在试图弄清楚如何测试twitteroauth时遇到了障碍。特别是尝试使用Cucumber和Webrat/Selenium来测试功能——注册/登录过程中的某些步骤在用户是否授予对应用程序的oauth访问权限等方面表现不同。有没有人在他们的RubyonRailsCucumber功能(或与此相关的任何其他测试框架)中成功模拟或stub部分或全部TwitterOAuth系统?任何帮助将不胜感激。 最佳答案 OP已经一年多了,但我最近发现这篇关于使用TwitterAuth和Cucumbe
目前我正在处理Rails4项目,现在我必须链接/连接另一个应用程序(不是sso,而是用于访问API),比如example.com。(注意example.com使用三足式oauth安全架构)搜索后发现必须要实现omniouth策略。为此我引用了this关联。根据Strategy-Contribution-Guide我能够完成设置和请求阶段,您可以在此处找到我的示例代码。require'multi_json'require'omniauth/strategies/oauth2'require'uri'moduleOmniAuthmoduleStrategiesclassMyAppStrat