本文用于对之前openCV知识点学习的复习及实践。要求达到以下效果:

本项目本质上就是进行模板匹配。
注:为多用到所学知识,为了加深理解多加了些步骤,实际上本项目可以很简单就能完成。
模板:
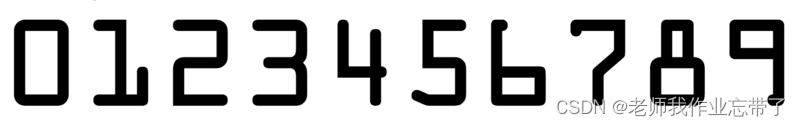
实际上:第二步我们可以直接将返回值倒序,得到对应0-9的正向拐点坐标列表,对其直接外接矩形切片即可。

银行卡中呢有很多的干扰项,或者说是没用的地方,因为我们需要的只是中间的那一块数字。我们不直接选中的话,思路如下:
注:上述过程有很大优化的空间,这样做是为了加深理解,具体可看代码部分。
略
ret, dst = cv2.threshold(src, thresh, maxval, type)
ret, dst: 返回阈值、输出图。
src: 输入图,只能输入单通道图像,通常来说为灰度图。
thresh: 阈值。
maxval: 当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值。
type:二值化操作的类型,包含以下5种类型:
cv2.THRESH_BINARY 超过阈值部分取maxval(最大值),否则取0
cv2.THRESH_BINARY_INV , THRESH_BINARY的反转
cv2.THRESH_TRUNC 大于阈值部分设为阈值,否则不变
cv2.THRESH_TOZERO 大于阈值部分不改变,否则设为0
cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
cv2.findContours(img,mode,method)
method:轮廓逼近方法
cv2.drawContours(draw_img, refCnts, -1, (0, 0, 255), 2)
refCnts = contours.sort_contours(refCnts, method="left-to-right")[0]
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
import cv2
import numpy as np
from imutils import contours # 排序操作,也可以不用。def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0) # 按键结束
cv2.destroyAllWindows()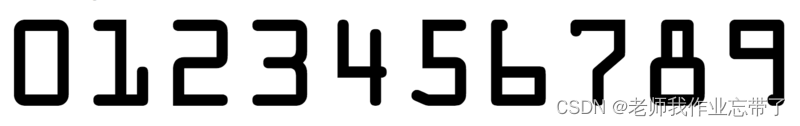
# 读取模板图像
img = cv2.imread('ocr_a_reference.png')
# 转换为灰度图 也可读取时直接转换
ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值图像
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]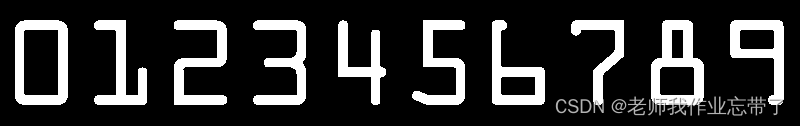
# 轮廓检测
refCnts, hierarchy = cv2.findContours(ref, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
'''
draw_img = img.copy()
cv2.drawContours(draw_img, refCnts, -1, (0, 0, 255), 2) # 第0个轮廓是9 第1个轮廓是8......
cv_show('draw_img',draw_img)
'''
# 排序(倒序操作) 得到正序0-9的轮廓
refCnts = sorted(refCnts,key=lambda b: b[0][0][0], reverse=False)
digits = {}
# 遍历每一个轮廓
for (i, c) in enumerate(refCnts):
# 计算外接矩形并且resize成合适大小
(x, y, w, h) = cv2.boundingRect(c)
roi = ref[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
# 每一个数字对应每一个模板,此时模板中的10个数字分别被保存到了字典中
digits[i] = roi
# 初始化卷积核
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
# 读入银行卡
image = cv2.imread('./images/credit_card_01.png')
set_width = 300 # 自己设定 这里我统一了宽度
rate = set_width/image.shape[:2][1]
image = cv2.resize(image,(0,0),fx=rate,fy=rate)# 同样也可以在第一步完成
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
# ksize=-1相当于用3*3的
gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
gradX = np.absolute(gradX) # 绝对值,白-黑 黑-白
# 或者写为 cv2.convertScaleAbs(sobelx)
# 归一化处理
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
# gradX与最小值之间的距离占区间长度的几分之几
gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))
gradX = gradX.astype("uint8")
# 闭运算 把银行卡卡号那里弄模糊
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
# 二值化,用于之后轮廓检测。
thresh = cv2.threshold(gradX, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# 再来一个闭操作
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)

threshCnts, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
'''
cur_img = image.copy()
cv2.drawContours(cur_img, threshCnts, -1, (0, 0, 255), 3)
cv_show('img', cur_img)
'''
locs = []
# 遍历轮廓
for (i, c) in enumerate(threshCnts):
# 计算矩形
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
# 选择合适的区域,根据实际任务来,这里的基本都是四个数字一组
if ar > 2.5 and ar < 4.0:
if (w > 40 and w < 55) and (h > 10 and h < 20):
# 符合的留下来
locs.append((x, y, w, h))
# 将符合的这四组轮廓按x从左到右排序
locs = sorted(locs, key=lambda x: x[0])output = []
# 遍历每一个轮廓中的数字
for (i, (gX, gY, gW, gH)) in enumerate(locs):
groupOutput = []
# 根据坐标提取每一个组
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
cv_show('group', group)
# 预处理
group = cv2.threshold(group, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('group', group)
# 计算每一组的轮廓
# group_,
digitCnts, hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
# 就是个排序 真正的顺序我们都知道,可以自己用sort函数
digitCnts = contours.sort_contours(digitCnts,
method="left-to-right")[0]
# 计算每一组中的每一个数值
for c in digitCnts:
# 找到当前数值的轮廓,resize成合适的的大小
(x, y, w, h) = cv2.boundingRect(c)
roi = group[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
cv_show('roi', roi)
# 计算匹配得分
scores = []
# 在模板中计算每一个得分 字典digits记录了模板0-9
for (digit, digitROI) in digits.items():
# 模板匹配
result = cv2.matchTemplate(roi, digitROI,
cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
# 得到最合适的数字,这里用的匹配方法对应得分越大越好。
groupOutput.append(str(np.argmax(scores)))
# 画出来
cv2.rectangle(image, (gX - 5, gY - 5),
(gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)
cv2.putText(image, "".join(groupOutput), (gX, gY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
# 得到结果
output.extend(groupOutput)
print("Credit Card #: {}".format("".join(output)))
# cv_show("Image", image)Credit Card #: 4000123456789010
我去掉了图片展示,直接输出文本结果。
import cv2
import numpy as np
from imutils import contours # 排序操作,也可以不用。
# 绘图展示
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 读取一个模板图像
img = cv2.imread('ocr_a_reference.png', )
# 灰度图
ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值图像
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]
# 轮廓检测
refCnts, hierarchy = cv2.findContours(ref, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 排序(倒序操作) 得到正序0-9的轮廓
refCnts = sorted(refCnts, key=lambda b: b[0][0][0], reverse=False)
digits = {}
# 遍历每一个轮廓
for (i, c) in enumerate(refCnts):
# 计算外接矩形并且resize成合适大小
(x, y, w, h) = cv2.boundingRect(c)
roi = ref[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
# 每一个数字对应每一个模板,此时模板中的10个数字分别被保存到了字典中
digits[i] = roi
# 初始化卷积核
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
# 读入银行卡
image = cv2.imread('./images/credit_card_01.png')
# 统一大小,这里建议让它变小一点,处理像素少一点,后面闭运算让其模糊也方便一些。
set_width = 300 # 自己设定 这里我统一了宽度
rate = set_width / image.shape[:2][1]
image = cv2.resize(image, (0, 0), fx=rate, fy=rate)
# 转为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 礼帽,突出更明亮的区域
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
# 梯度运算,这里使用Sobel算子,只进行了x方向计算。前面的礼帽操作是的我们梯度运算结果更干净些。
# ksize=-1相当于用3*3的
gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
gradX = np.absolute(gradX) # 绝对值,白-黑 黑-白
# 或者写为 cv2.convertScaleAbs(sobelx)
# 归一化处理
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
# gradX与最小值之间的距离占区间长度的几分之几
gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))
gradX = gradX.astype("uint8")
# 闭运算 把银行卡卡号那里弄模糊
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
# 二值化,用于之后轮廓检测。
thresh = cv2.threshold(gradX, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# 再来一个闭操作
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)
# 轮廓检测
threshCnts, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
locs = []
# 遍历轮廓
for (i, c) in enumerate(threshCnts):
# 计算矩形
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
# 选择合适的区域,根据实际任务来,这里的基本都是四个数字一组
if ar > 2.5 and ar < 4.0:
if (w > 40 and w < 55) and (h > 10 and h < 20):
# 符合的留下来
locs.append((x, y, w, h))
# 将符合的这四组轮廓按x从左到右排序
locs = sorted(locs, key=lambda x: x[0])
# 遍历这四组数
output = []
# 遍历每一个轮廓中的数字
for (i, (gX, gY, gW, gH)) in enumerate(locs):
groupOutput = []
# 根据坐标提取每一个组
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
# 预处理
group = cv2.threshold(group, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# 计算每一组的轮廓
# group_,
digitCnts, hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
# 就是个排序 真正的顺序我们都知道,可以自己用sort函数
digitCnts = contours.sort_contours(digitCnts,
method="left-to-right")[0]
# 计算每一组中的每一个数值
for c in digitCnts:
# 找到当前数值的轮廓,resize成合适的的大小
(x, y, w, h) = cv2.boundingRect(c)
roi = group[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
# 计算匹配得分
scores = []
# 在模板中计算每一个得分 字典digits记录了模板0-9
for (digit, digitROI) in digits.items():
# 模板匹配
result = cv2.matchTemplate(roi, digitROI,
cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
# 得到最合适的数字,这里用的匹配方法对应得分越大越好。
groupOutput.append(str(np.argmax(scores)))
# 画出来
cv2.rectangle(image, (gX - 5, gY - 5),
(gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)
cv2.putText(image, "".join(groupOutput), (gX, gY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
# 得到结果
output.extend(groupOutput)
print("Credit Card #: {}".format("".join(output)))很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在