事情起因很简单,同事对于我写的一个索引报了如下问题。出于学习目的排查下。

常见的ES集群有三种状态,如下:
如下图所示分别为green和red的样子。
GET /_cluster/health
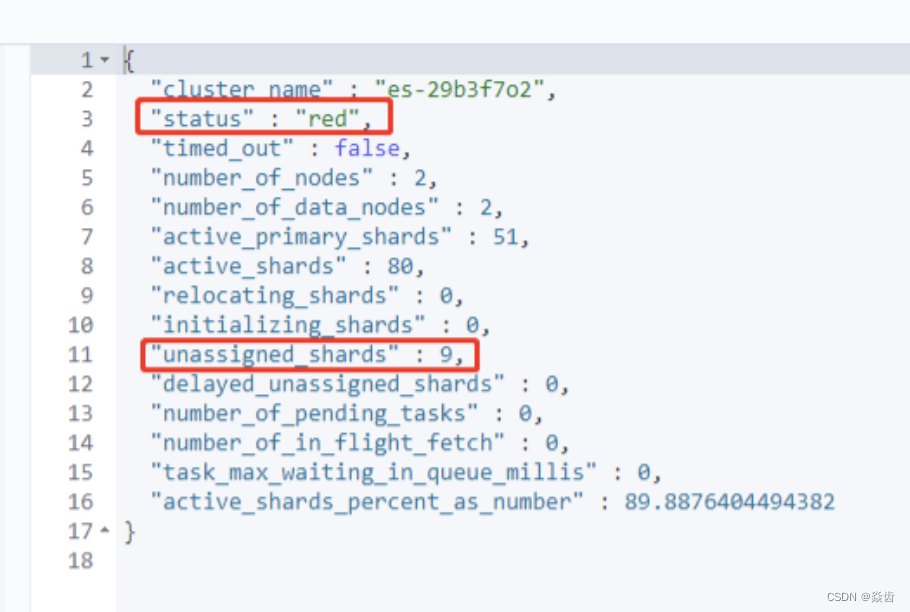
对于上述red的情况。需要重点关注unassigned_shards没有正常分配的分片。
方法一:查看所有索引状况,如下就是有问题的。右侧查找 red 关键词。
GET /_cat/indices
方法二:直接查看unassigned的shard。
查找 unassigned 关键词。
GET /_cat/shards
使用 Cluster Allocation Explain API ,返回集群为什么不分配分片的详细原因。
GET /_cluster/allocation/explain?pretty
curl -X GET "http://xxx.io:48888/_cluster/allocation/explain?pretty"这里简单列一下:
(1)磁盘满
the node is above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=95%], using more disk space than the maximum allowed [95.0%], actual free: [4.055101177689788%]解决:扩容磁盘或者删除数据
(2)分配文档超过最大限制
failure IllegalArgumentException[number of documents in the index cannot exceed 2147483519解决:向新索引中写入数据,并合理设置分片大小。
(3)主分片所在节点掉线
cannot allocate because a previous copy of the primary shard existed but can no longer be found on the nodes in the cluster解决:找到节点掉线的原因并重新其中节点加入集群,等待分片恢复。
(4)索引属性与节点属性不匹配
node does not match index setting [index.routing.allocation.require] filters [temperature:“warm”,_id:“comdNq4ZSd2Y6ycB9Oubsg”]解决:重新设置索引的冷热属性,和节点保持一致;若要修改节点属性,则需要重启节点。
(5)节点长时间掉线后再次加入集群,导致引入脏数据
cannot allocate because all found copies of the shard are either stale or corrupt解决:使用 reroute API
(6)未分配的分片太多,导致达到了分片恢复的最大阈值,其他分片需要排队等待
reached the limit of incoming shard recoveries [2], cluster setting [cluster.routing.allocation.node_concurrent_incoming_recoveries=2] (can also be set via [cluster.routing.allocation.node_concurrent_recoveries])解决:使用cluster/settings调大分片恢复的并发度和速度
Elasticsearch集群规划及性能优化实践(笔记)_ttldba的博客-CSDN博客
腾讯云Elasticsearch集群规划及性能优化实践_mb5fdb0a87e2fa1的技术博客_51CTO博客
(1)首先是查看节点冷热属性
GET _cat/nodeattrs?v&h=node,attr,value&s=attr:desc
curl -X GET "http://xxxx.io:48888/_cat/nodeattrs?v&h=node,attr,value&s=attr:desc"

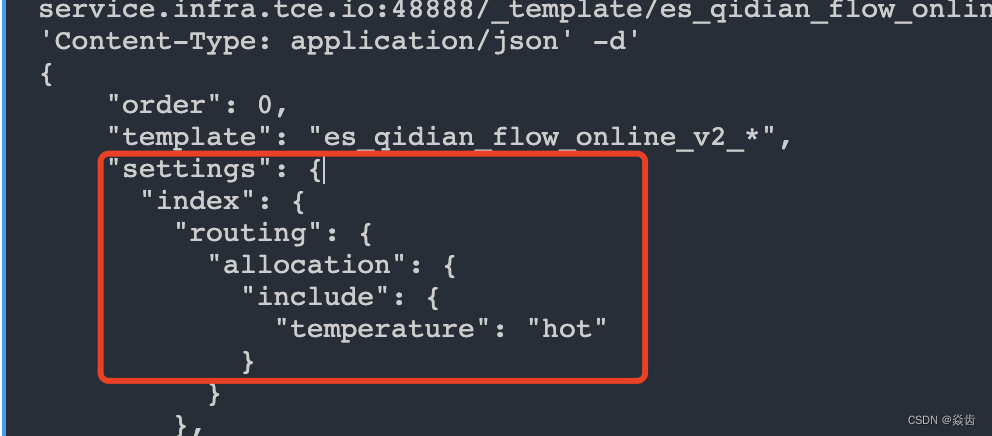
总的来讲就是调整索引(或者模板)的setting里面的temperature属性,实在不行不设就好了。
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
当我的预订模型通过rake任务在状态机上转换时,我试图找出如何跳过对ActiveRecord对象的特定实例的验证。我想在reservation.close时跳过所有验证!叫做。希望调用reservation.close!(:validate=>false)之类的东西。仅供引用,我们正在使用https://github.com/pluginaweek/state_machine用于状态机。这是我的预订模型的示例。classReservation["requested","negotiating","approved"])}state_machine:initial=>'requested
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
我想为我的Task模型创建一个status属性,该属性将按以下顺序指示它在三部分进度中的位置:打开=>进行中=>完成。它的工作方式类似于亚马逊包裹的交付方式:已订购=>已发货=>已交付。我想知道设置此属性的最佳方法是什么。我可能是错的,但创建三个独立的bool属性似乎有点多余。实现此目标的最佳方法是什么? 最佳答案 Rails4有一个内置的enummacro.它使用单个整数列并映射到键列表。classOrderenumstatus:[:ordered,:shipped,:delivered]end状态映射如下:{ordered:0,
s=Socket.new(Socket::AF_INET,Socket::SOCK_STREAM,0)s.connect(Socket.pack_sockaddr_in('port','hostname'))ssl=OpenSSL::SSL::SSLSocket.new(s,sslcert)ssl.connect从这里开始,如果ssl连接和底层套接字仍然是ESTABLISHED,或者它是否在默认值7200之后进入CLOSE_WAIT,我想检查一个线程几秒钟甚至更糟的是在实际上不需要.write()或.read()的情况下关闭。是用select()、IO.select()还是其他方法完成
我想从rubyrake脚本运行一个可执行文件,比如foo.exe我希望将foo.exe的STDOUT和STDERR输出直接写入我正在运行rake任务的控制台.当进程完成时,我想将退出代码捕获到一个变量中。我如何实现这一目标?我一直在玩backticks、process.spawn、system但我无法获得我想要的所有行为,只有部分更新:我在Windows上,在标准命令提示符下,而不是cygwin 最佳答案 system获取您想要的STDOUT行为。它还返回true作为零退出代码,这可能很有用。$?填充了有关最后一次system调
这是我当前的类定义和规范:classEvent:not_starteddoevent:game_starteddotransition:not_started=>:in_progressendevent:game_endeddotransition:in_progress=>:finalendevent:game_postponeddotransition[:not_started,:in_progress]=>:postponedendstate:not_started,:in_progress,:postponeddovalidate:end_time_before_finalen
我有一个功能“从外部网站导入文章”。在我的第一个场景中,我测试从外部网站导入链接列表。Feature:ImportingarticlesfromexternalwebsiteScenario:Searchingarticlesonexample.comandreturnthelinksGiventhereisanImporterAnditsURLis"http://example.com"Whenwesearchfor"demo"ThentheImportershouldreturn25linksAndoneofthelinksshouldbe"http://example.com/d
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a