☕目录☕
🍔前言
🍤🍤2.1 新增元素
🧀🧀3.1 全列查询
🍜后续
咳咳~~
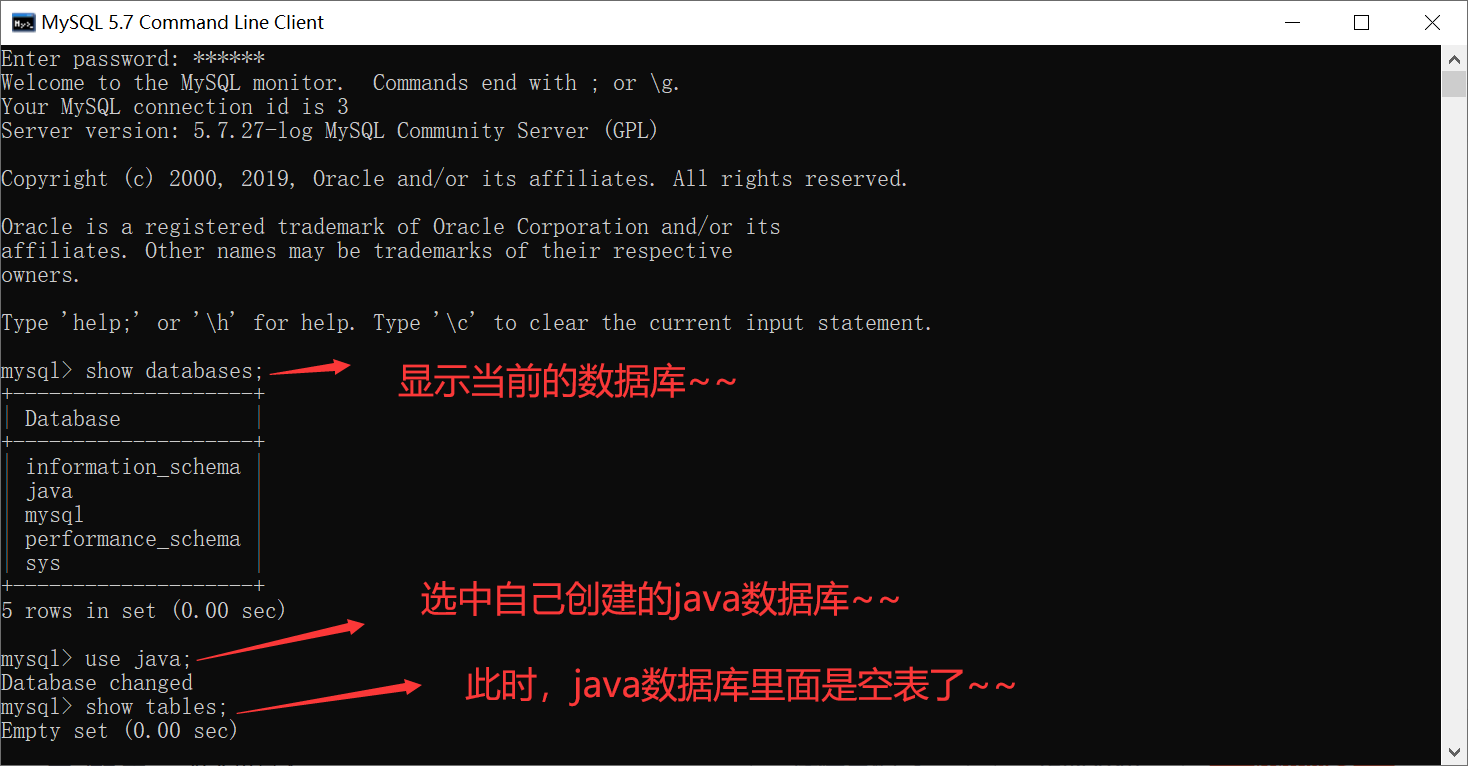
为了本篇博客的学习,先把MySQL数据库里面自己创建的表都删掉~~
并且留下自己创建的java数据库~~

CRUD 即 增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写~~
MySQL表的增删改查,是整个MySQL数据库中的最重要的内容~~
MySQL的工作就是 组织管理数据,即 需要先保存,保存好了 后续好进行增删改查~~
增删改查的前提,是把数据库已经创建好了,并且选中了,而且表也已经创建就绪了~~

新增元素 主要的命令行就是:
insert into 表名 values (值1,值2,值3,......);注意:
- insert 和 values 都是关键字~~
- into是可以省略的(个人习惯写上了)~~
- 插入的值可以有若干个,值的个数 要和 表的列数 相匹配;值的类型 需要和 列的类型 相匹配~~
首先,我们新建一张 student表:
接着,我们来查看一下表结构:
最后,我们可以往这张 student表 里面插入数据了:
此时,插入数据成功~~
需要注意的是,在SQL中表示字符串,可以用单引号,也可以用双引号,它们是等价的关系;SQL里没有 字符类型~~
插入数据失败的情况:

注意:
如果有刚刚使用 MySQL数据库 的小伙伴,啥都没有设置~~
会发现,如果插入的数据是中文的话,那么都会插入数据错误~~
我的这个中文数据插入成功,是因为在之前已经配置好了~~
如果想知道是怎么设置的,可以移步至这个传送门:
🚪传送门:【MySQL系列】“一劳永逸”解决MySQL中“插入中文数据”出错的问题
insert 插入的时候 可以指定列插入~~
即 不一定非得把这一行的所有列插入,可以想插入几列就插入几列~~
insert into 表名(列名1,列名2,列名3,......) values (值1,值2,值3,......);
--注意:
--列名 和 值 的各种关系要一一对应~~ 
指定了 name 这一列进行插入~~
其他未被指定的列(id),填入的值就是这一列的默认值,默认的默认值就是啥也不填,也就是NULL~~
insert 语句还可以一次插入多条记录~~
说白了,就是 在values后面,带有多组(),每个()之间采用,来进行分割~~
insert into 表名 values (值1,值2,...),(值3,值4,...),(值5,值6);
--注意:
--列名 和 值 的各种关系要一一对应~~ 
当然,也可以把 上面的插入方式组合在一起~~
insert into 表名(列名1,列名2,列名3,...) values (值1,值2,...),(值3,值4,...),...;
--注意:
--列名 和 值 的各种关系要一一对应~~ 
注意:
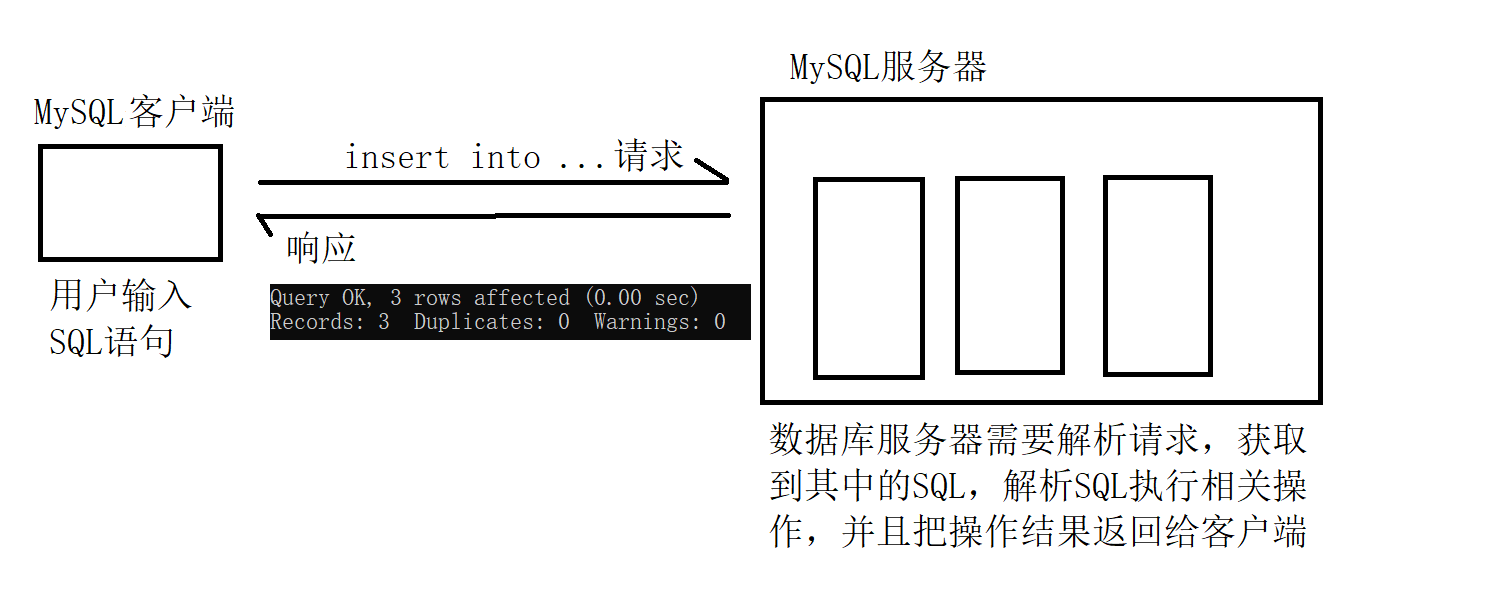
在MySQL里面,"一次插入一条记录,分多次插入" 相比于 "一次插入多条记录" 来说,要慢上很多~~
一方面,
如果要是"一次插入一条,分多次来插入",就会有多个 请求/响应;
如果要是"一次插入多条记录",就一个 请求/响应 就够了~~
另外一方面,MySQL服务器方面,是通过一系列的复杂的数据结构来组织数据的,
每一次的插入操作其实都是比较耗时的(在数据结构中进行一定的便利操作 找到合适的位置)~~
如果是"一次插入一条,分多次来插入",服务器这边的准备工作就要准备多次;
如果要是"一次插入多条记录",服务器准备工作就只需要做一次就可以了~~
类似于,室友B叫室友A去带东西的场景~~
"一次插入一条,分多次来插入"的场景就是这样子的:室友B叫室友A去食堂带一份午饭,室友A答应了;之后,在快回到宿舍的时候,室友B又叫室友A去带一份奶茶,室友A于是就重新返回到食堂旁边的奶茶店去买奶茶了......
这就很难受,需要在路中间来回折腾,浪费好长时间~~
"一次插入一条,分多次来插入"的场景就是这个样子的:室友B叫室友A带一份午饭和一杯奶茶(把所有要交代的东西都交代了),室友A同意了,于是,在买好午饭过后,又去了旁边的奶茶店带了一杯奶茶;
这样的话,所花费的时间就少多了,效率就得到了很大的提高~~

查询操作 是SQL最最重要,也是最最复杂的操作~~
此处先介绍一些 简单的查询~~
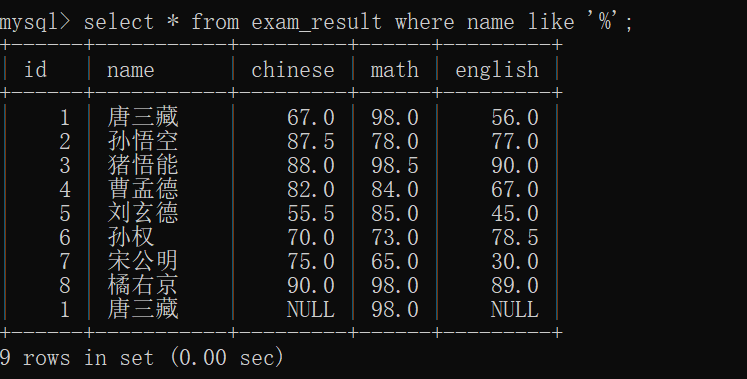
全列查询,即 把整个表里面的数据都查询出来~~
select * from 表名;
--*是通配符,表示匹配任意的列(所有的列)~~
此操作就把student表全都构建出来了~~
但是实际上这是一个"临时表",这个表格并不是 服务器上数据的本体~~
这里就会出现一个关键性的问题:
如果当前数据库里面的数据特别多,那么 执行上述 select * 会发生什么情况呢?
服务器需要先读取磁盘,把这些数据都查询出来,再通过网卡把数据传输给客户端~~
由于数据量非常大,极有可能把磁盘IO吃满,或者把网络带宽吃满~~
直观感受:卡(会卡多久不知道......)~~
如果当前操作的数据库是生产环境的服务器,因为 select * 就可能导致生产环境服务器卡顿,从而影响外面用户的使用体验~~
万一真的执行了这个操作的话,赶紧按住 ctrl+c 取消操作!!!
执行一些SQL的时候如果执行的时间比较长,随时可以按 ctrl+c 来中断~~
在控制台执行,ctrl+c 一般都是有效的;在图形化界面上,ctrl+c 是否还是有效,那就不清楚了~~
当然,除了select * 之外,只要返回的记录足够多,哪怕是进行的是其他的查询,也是有同样风险的~~
比如,即使加上了后面所要介绍的where条件查询,万一筛选之后的结果还是很多,仍然可能把服务器弄坏了~~
更稳妥的办法,就是加上limit(后面也会介绍)~~
一张表里面可能会有许多列~~
但是如果我们只需要观察 其中的某些列,那么就可以使用 指定列查询:
select 列名1,列名2,列名3,... from 表名;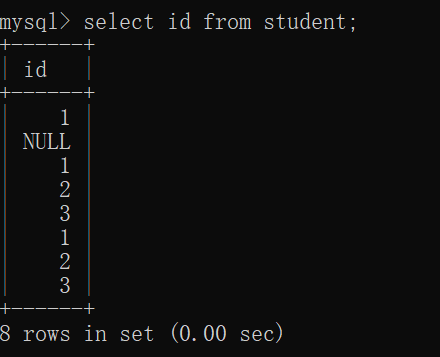
当我们省略掉一些不必要的列的时候,就可以节省大量的磁盘IO和网络带宽了~~
MySQL是客户端/服务器结构的程序,在此处看到的结果这张表,同样也是"临时表",只是在客户端这里显示成了这个样子,而不是说服务器上 就真的有一个这样的 里面只存了id 的这张表~~
select所有的操作的结果都是"临时表",可能会把显示在客户端上的结果进行了加工,但是不会影响到数据库服务器原有的数据~~
在查询的时候带有表达式,让查询的结果进行一些计算~~
表达式查询,这里进行的计算,都是列和列之间的计算,而不是行和行之间的计算(行和行之间的计算,有另外的办法)~~
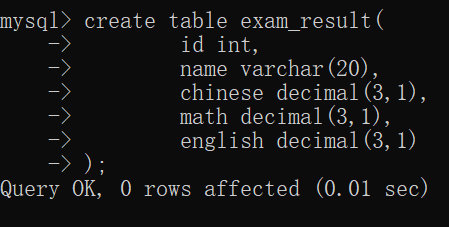
现在创建一个新的表,以方便计算~~
decimal(3,1):
成绩得要是 90.5或88.8这样的形式,形如100、5.23这样的形式其实就是非法字符~~
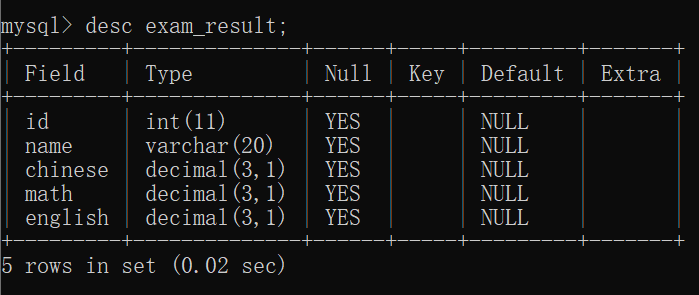
此时我们就可以查看表的结构:
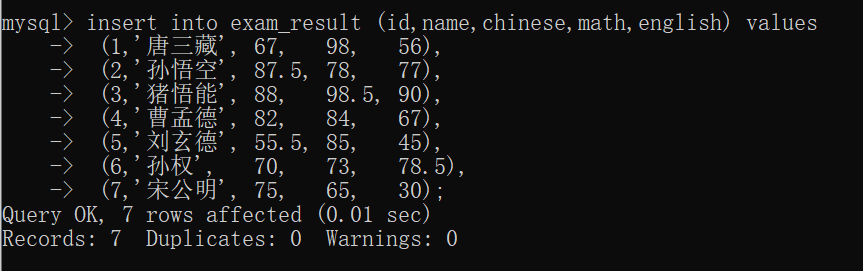
接下来我们就可以来插入数据:
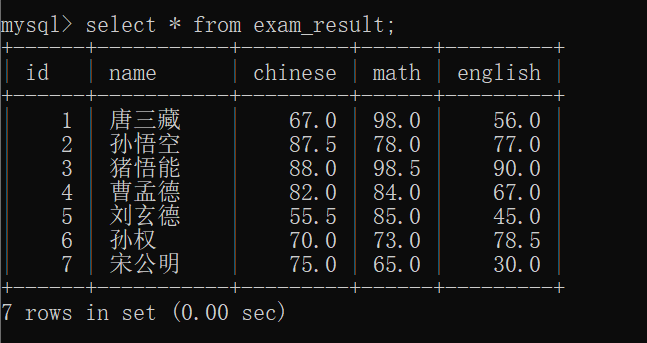
此时,我们可以来看一下 exam_result表 的数据:
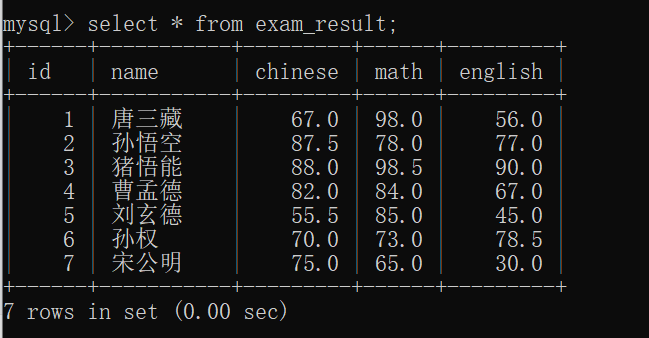
那么,现在就可以来 做一些查询字段带有表达式 的查询了~~
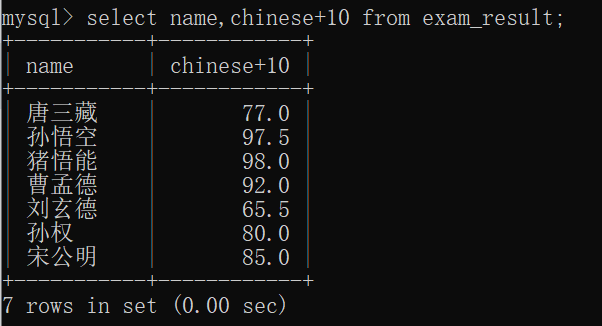
如:查询结果中,每个同学的语文成绩都多10分:
对比 exam_result表 的数据,可以发现,每个人的语文成绩都多10分~~
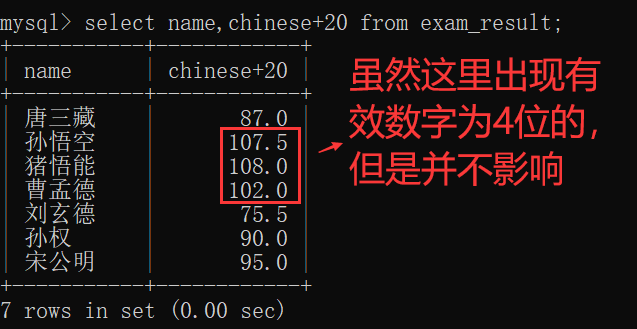
如果说,加的数字超过了decimal(3,1)的限制会怎么样呢?
答案是,不会怎么样~~
得到的结果是"临时表","临时表"的列的类型并不是严格和原有表的类型一致~~
"临时表"会尽可能的保证显示结果是正确的~~
但是,尝试往原始的表中插入一个超出范围的数据,那是不可以的:
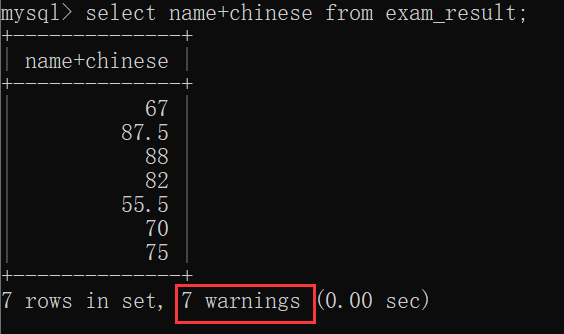
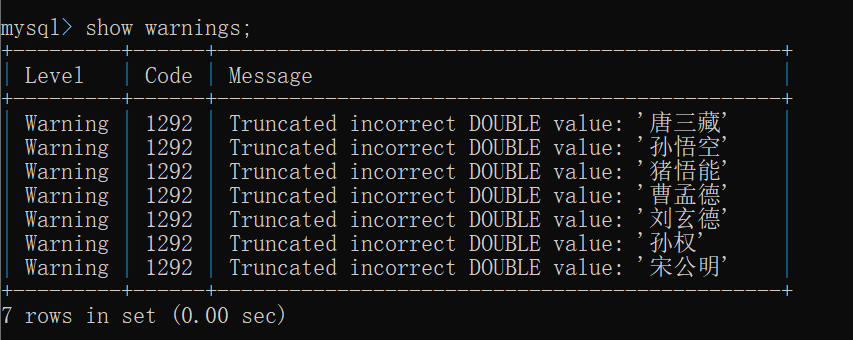
如果尝试把 字符串 和 数字 进行算术运算,就可能会报错,也可能会出现警告:
可以使用 show warnings 查看警告的详细情况:
临时表中显示的列完全取决于select指定的列名:
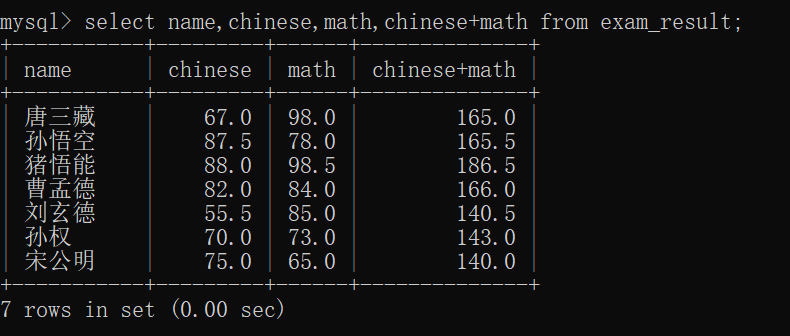
正因为这里支持表达式查询,也容易带来一些小的困惑,
如:
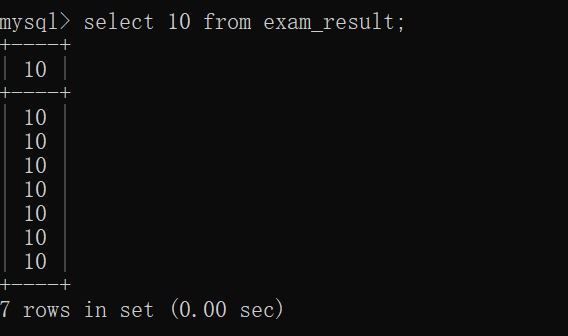
当前表里,没有名字为10的这一列~~
但是这样的SQL也可以执行~~
也是因为10也是一个表达式(语法上没错,但是实际上没有什么意义)~~
有的时候,在MySQL客户端中,会发现"临时表"中 显示的列名 会非常特别的长,很不好看,也并不直观~~
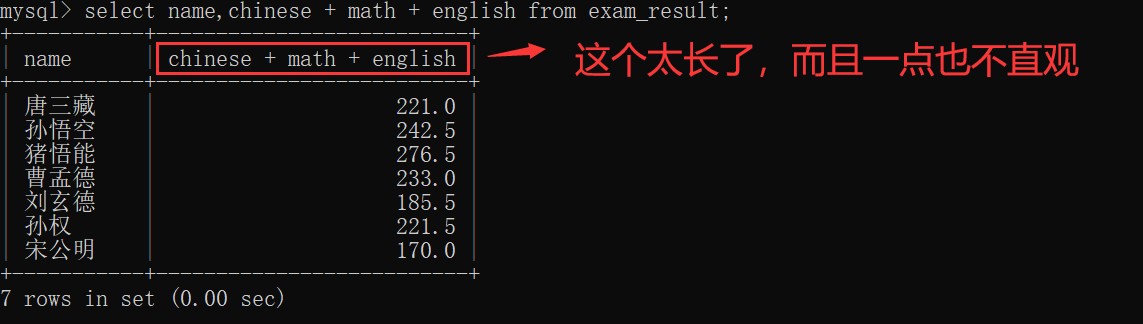
此时,为了解决这个问题,就可以起一个别名~~
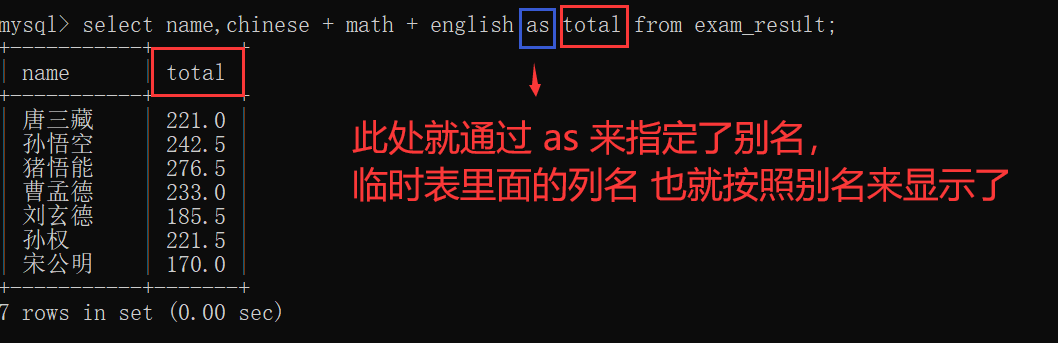
当然,as也可以省略,不过个人建议还是写上最好~~
不写as的时候,不一定能看清楚~~
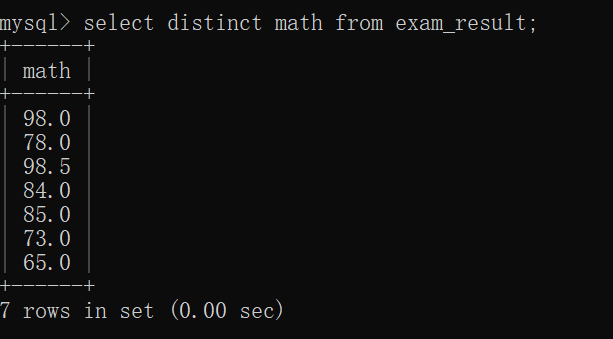
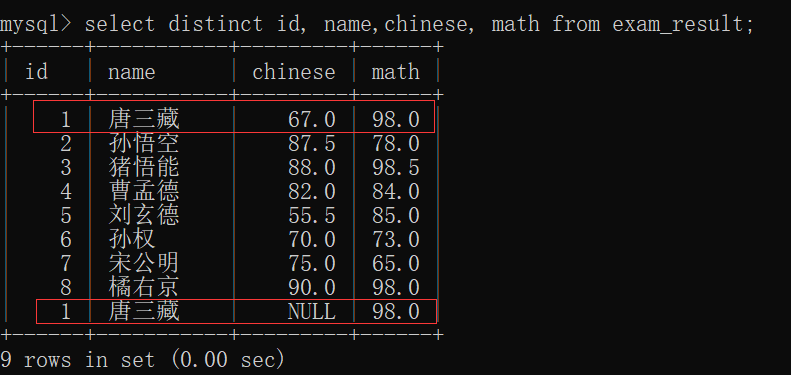
去重查询 需要用到一个关键字:distinct ~~
去重查询 会把查询结果相同的行,合并成一个~~
即 把查询结果相同的行给去掉~~
去重查询的命令行是这样的:
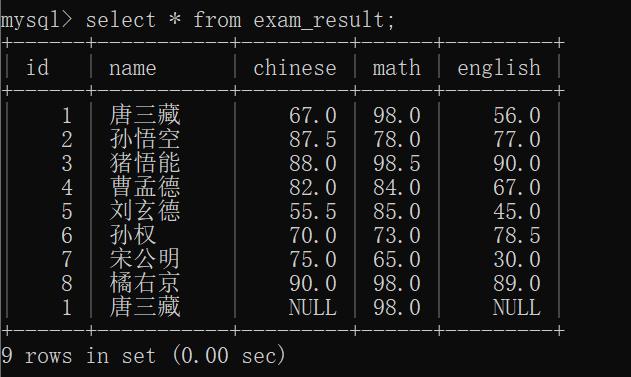
select distinct 列名 from 表名;先观察exam_result表:
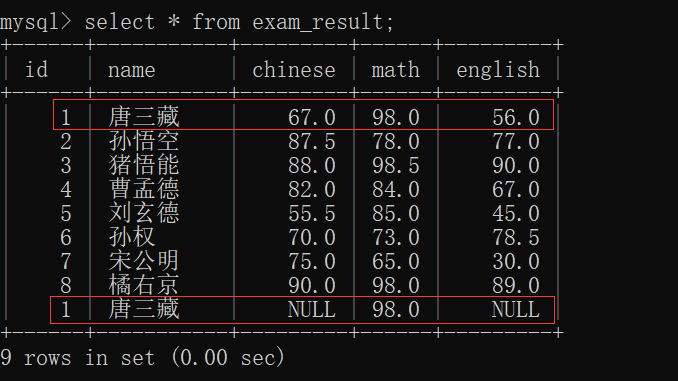
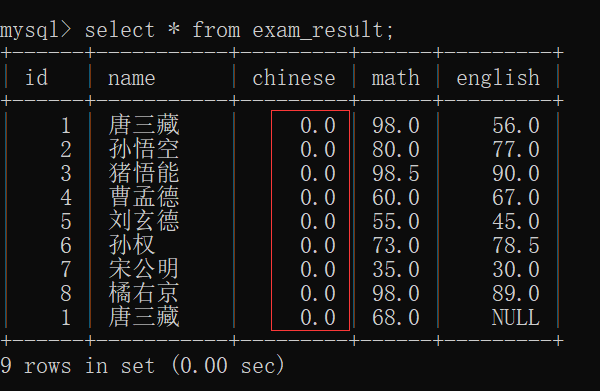
那我们就来插入一个数据,使得其有重复的(数学成绩 与 '唐三藏' 重复):
此时再来查看 exam_result表:
此时,我们用去重查询:
去重查询成功~~
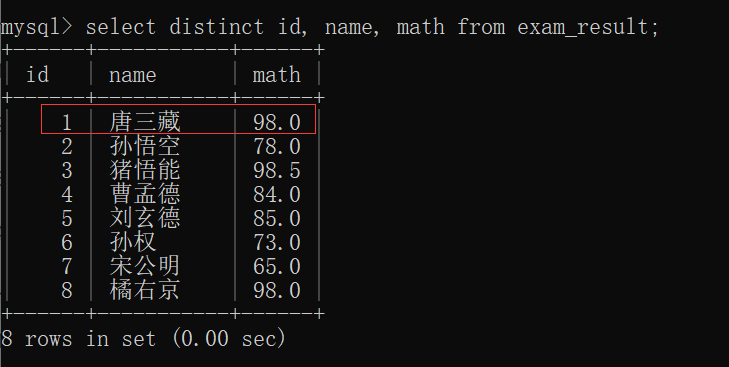
当然,distinct 后面也可以指定多个列~~
不过,必须是多个列的值 完全相同 的时候才视为相同(才会去重)~~
此时,再插入一条数据:
观察此时的 exam_result表:
观察完全相同时的操作:
观察不完全相同时的去重操作:
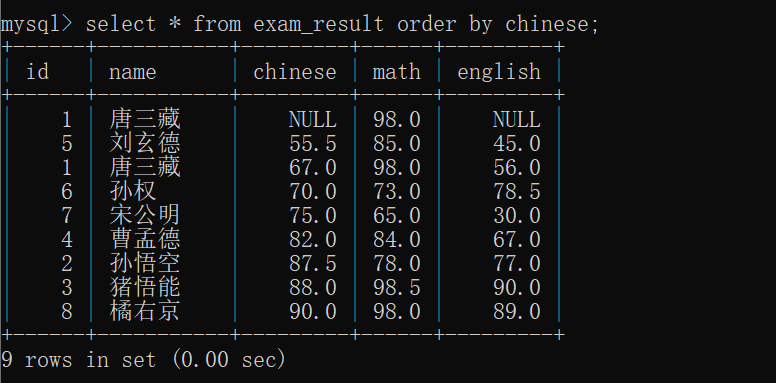
排序查询,在查询过程中,对于查询到的结果,进行排序~~
这里的"排序",针对的只是"临时表",对于数据库上原来存储的数据没有影响~~
这里的排序查询的语法是:
select 列名 from 表名 order by 列名 asc/desc;
--asc 升序,默认值是 升序,可以省略~~
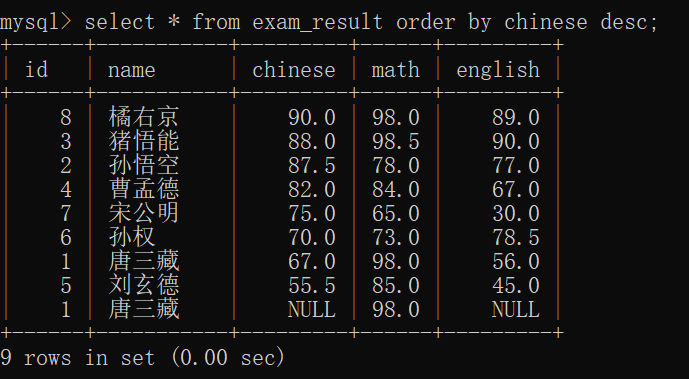
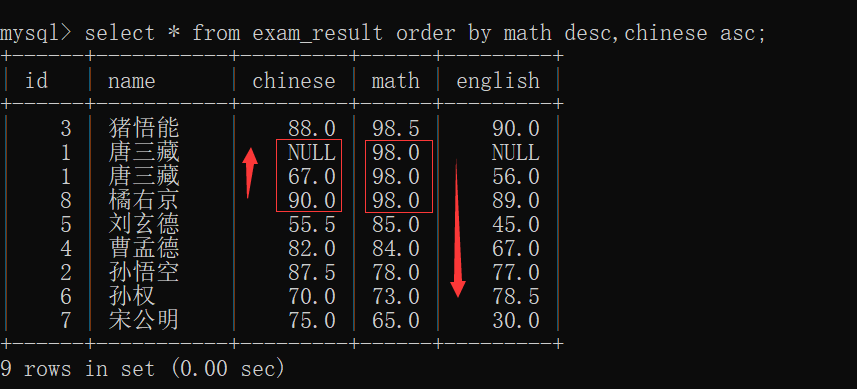
--desc 降序(descending order的缩写)~~于是,我们可以把 exam_result表 按照 chinese的顺序 升序或者降序排序:
其中,NULL是最小值的意思~~
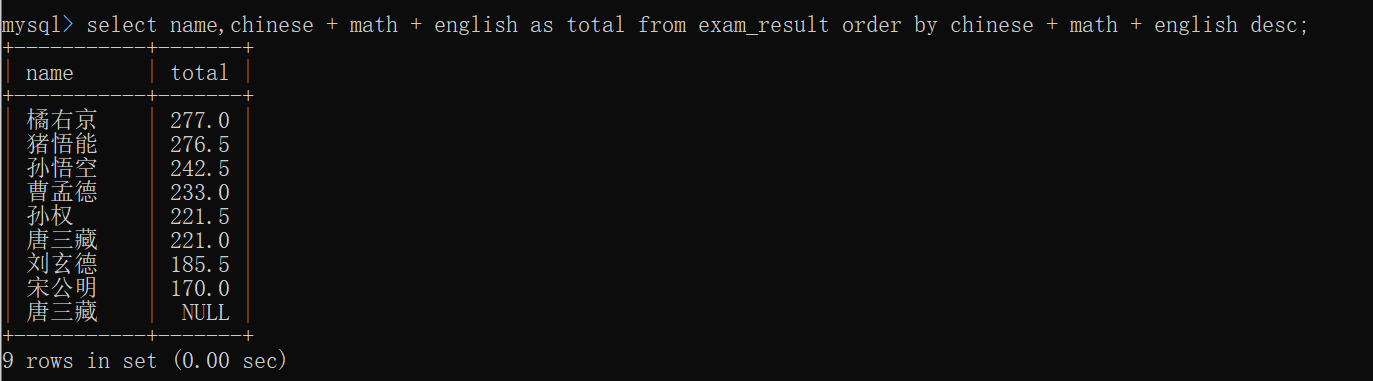
order by 也可以针对带有别名的表达式进行排序:
这里有一个小细节~~
SQL中,如果拿NULL和其它类型进行混合运算,结果仍然是 NULL~~
order by 进行排序的时候,还可以指定多个列来进行排序!!!
当指定多个列排序的时候~~
就相当于:如果第一列不分胜负,再按照第二列进行比较......
如表所示,先按照 math 成绩降序排序,有 math 成绩一样的,按照 chinese 成绩升序排序~~
条件查询,我们在进行查询的时候,引入where子句,针对查询结果进行筛选~~
筛选可以简单理解成,对于查询结果进行依次遍历~~
把对应的查询结果带入到条件中~~
条件成立,则把这个纪录带入到最终查询结果里~~
条件不成立,则直接舍弃掉,不作为最终结果~~
此处的条件,和Java中的if语句里的条件是差不多的~~
条件查询的命令行是:
select 列名 from 表名 where 条件;
常见的条件如下所示:
条件运算符 运算符 说明 > , >= , < ,<= 大于 , 大于等于 , 小于 , 小于等于 = 等于, NULL 不安全,例如 NULL = NULL 的结果是 NULL <=> 等于, NULL 安全,例如 NULL <=> NULL 的结果是 true(1) != ,<> 不等于 between A and B 范围匹配,闭区间 [A,B] in (option, ...) 如果是 option 中的任意一个,返回 true(1) is null 是null is not null 不是null like 模糊匹配。 % 表示任意多个(包括 0 个)任意字符; _ 表示任意一个字符
逻辑运算符 运算符 说明 and(相当于 与) 多个条件必须都为 true(1),结果才是 true(1) or(相当于 或) 任意一个条件为 true(1), 结果为 true(1) not(相当于 非) 任意一个条件为 true(1), 结果为 true(1)
先看一看 exam_result表的内容:
下面我们可以来举一些条件查询的例子了:
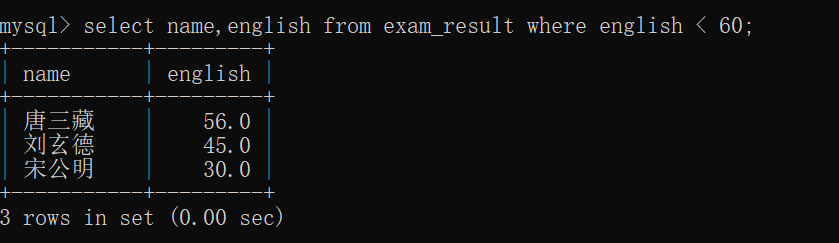
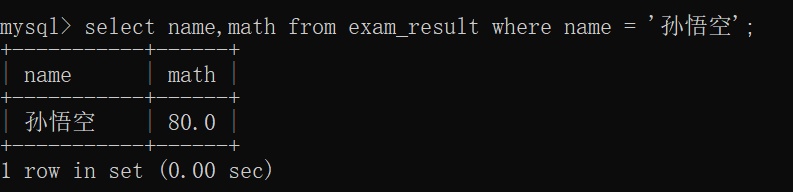
查询英语成绩不及格的同学姓名及其英语成绩~~
需要注意的是,此时这张表里面有 "英语成绩" 是 NULL 的 "唐三藏"同学(有两个 "唐三藏",此时查询到的只有一个);
NULL < 60 => NULL;
NULL就相当于 false,结果不成立 ,不成立就不会出现在表上~~
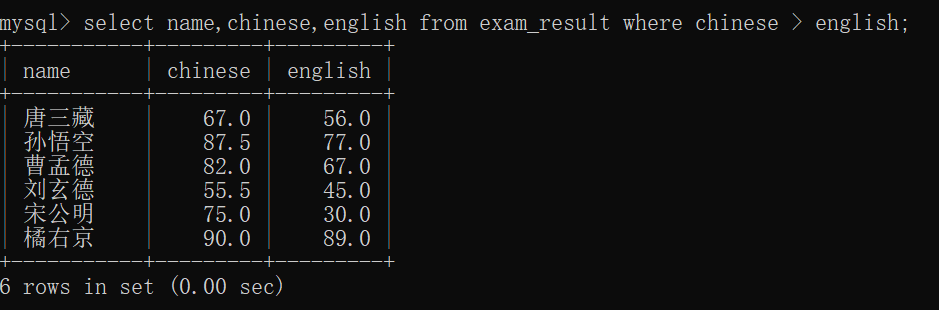
查询语文成绩比英语成绩好的同学~~
查询总分在200以下的同学~~
这句查询是没有问题的,可是 当我们在条件查询中 使用了别名时:
却发现是错误的~~
即 条件查询不允许使用别名~~
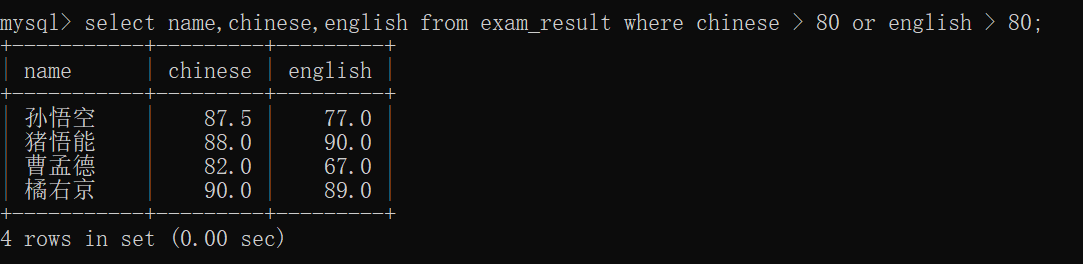
查询语文成绩大于80分,且英语成绩也大于80分的同学~~
查询语文成绩大于80分,或英语成绩大于80分的同学~~
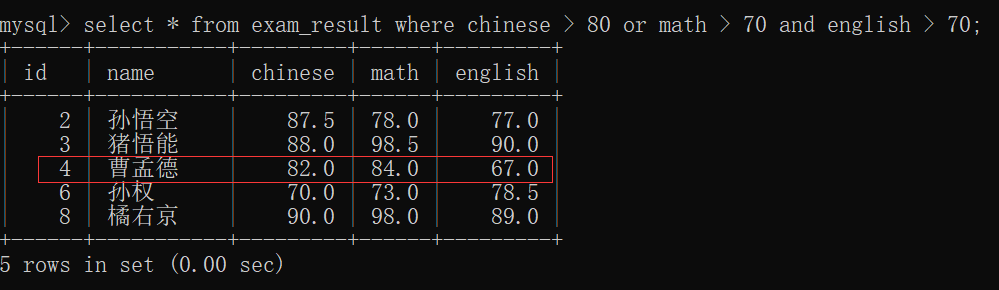
小细节:一个条件中 同时有 and 和 or ,那么 and 的优先级更高(先算 and 再算 or)~~
该查询我们就只看 "曹孟德" 的成绩,
如果说,or 的优先级更高(先算的 or 再算的 and ),
此时,就相当于:
select * from exam_result where (chinese > 80 or math > 70) and english > 70;
那么,语文和数学成绩满足的,但是英语成绩不满足条件,"曹孟德"不应该出现在这张表中;
所以说,and的优先级更高(先算的and再算的or),
此时,就相当于:
select * from exam_result where chinese > 80 or (math > 70 and english > 70);
英语成绩虽然不满足,但是数学成绩满足,再者说了语文成绩也满足了,所以 "曹孟德" 的名字出现在表上~~
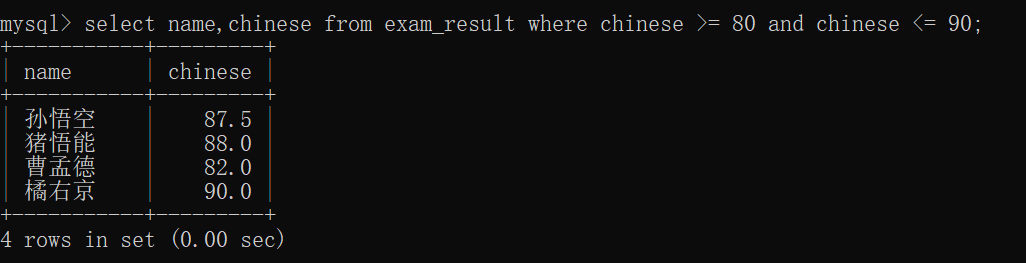
查询语文成绩在 [80,90] 之间的同学及语文成绩~~
这里我们可以使用and和><来解决;
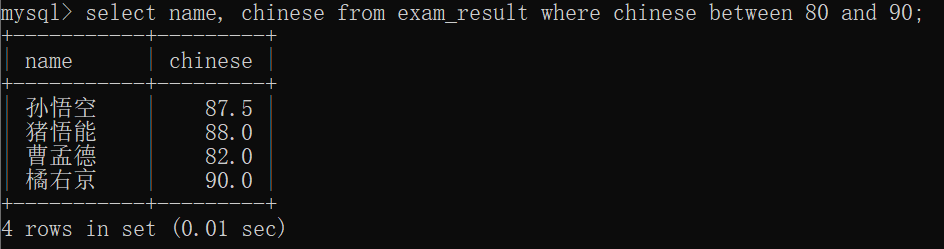
当然也可以使用 between...and...来解决:
between A and B~~
这里构造的闭区间[A,B]~~
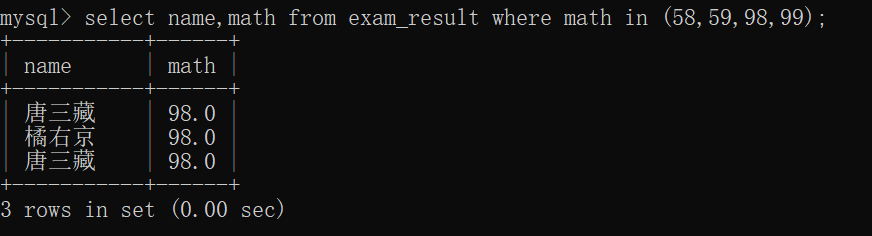
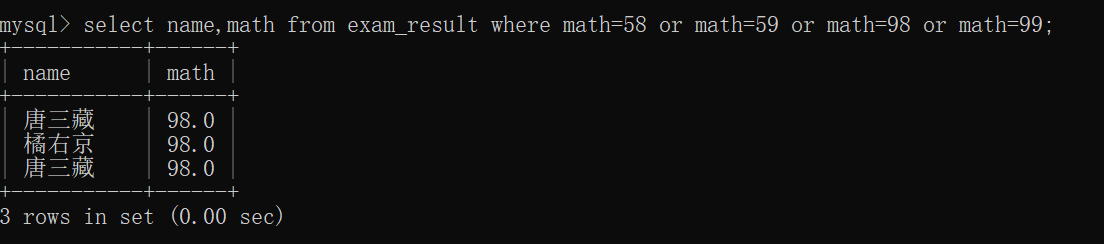
查询数学成绩是58或者59或者98或者99分的同学及数学成绩~~
当然,这样的代码也可以修改成:
模糊查询:like
通过like来完成模糊查询~~
不一定完全相等,只要有一部分匹配即可~~
模糊查询中需要用到 通配符:%和_
% 可以用来代替任意任意个字符(也包括了 0 个字符);
_ 可以用来代替一个任意字符~~
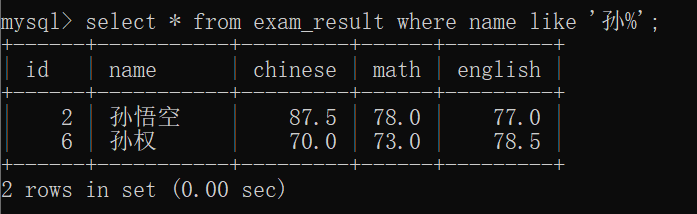
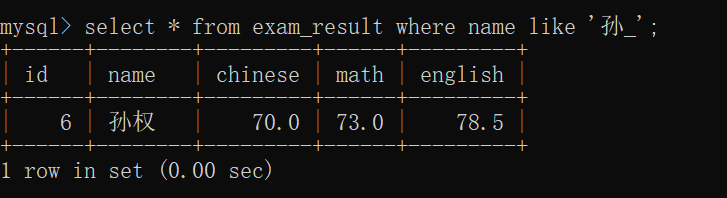
寻找到姓"孙"的同学的信息~~
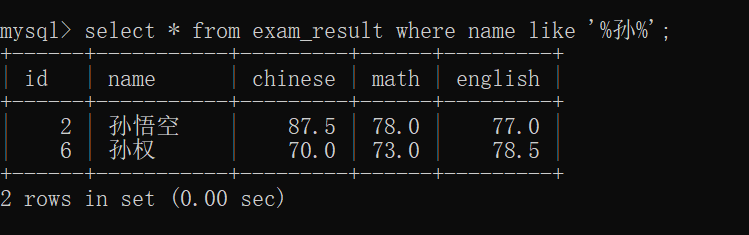
当然,类似的~~
%孙 匹配以孙结尾的数据~~
%孙% 匹配包含 孙 的数据~~
% 匹配任意数据~~
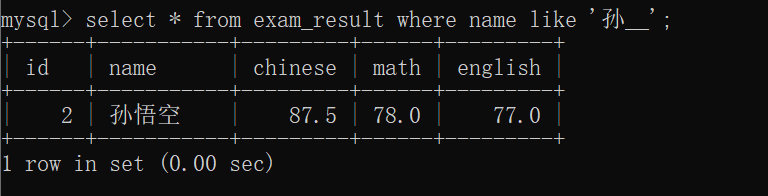
查询只有 两个字的 姓"孙"的同学的信息~~
查询只有 3个字的 姓"孙"的同学的信息~~
和NULL进行比较~~
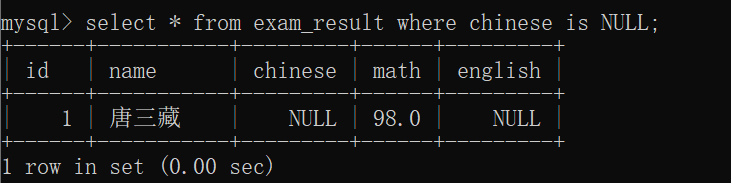
查询语文成绩为NULL的同学~~
需要使用 <=> 和空值进行正确匹配:
但是,如果用等号来进行匹配,那结果一定是出错的~~
上面说了~~
NULL = NULL => NULL
NULL相当于是false,条件不成立~~
当然,也可以使用 is NULL来进行匹配~~
需要注意的是,is [not] NULL 是专门用来和空值进行比较的~~
注意:
<=> 可以是用来比较多列,如果多列都是NULL的话,那是可以查找出来的(= 是查找不出来的)~~
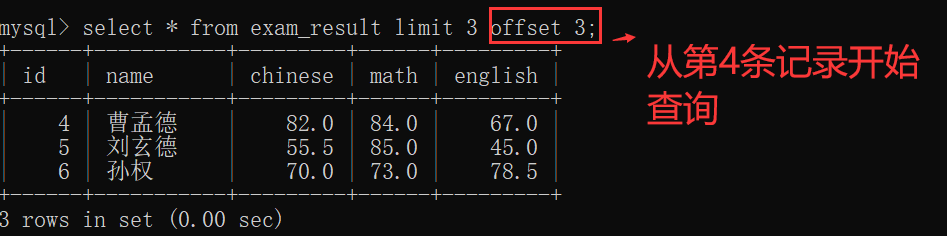
分页查询,让查询的结果,只取其中的一个部分~~
从而能够降低开销,加快查询速度~~
比如说,一个论坛,可能会有几千/上万的帖子,但是 打开页面的时候,其实只能先看到其中的一小部分(只显示前XXX条记录)~~
点击翻页,才会看到后面的帖子~~
分页查询的关键用法,
在于 使用 limit 关键字,来限制返回的结果条数(说白了 就是显示形成的"临时表"里面有多少条记录),
使用 offset 关键字,来确定从第几条开始进行返回~~
select 列名 from 表名 limit N offset M;
--limit 限制
--offset 开端、出发
当然,还有另外一种写法,和上述意思是一样的,不过更建议使用 上面的写法,更直观一点点:
select 列名 from 表名 limit M,N;
注意:
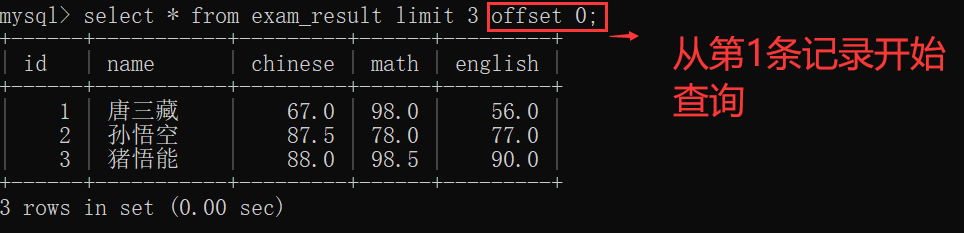
上面的 offset M 可以省略,如果省略的话,表示从一开始的记录开始返回~~
select 列名 from 表名 limit N;
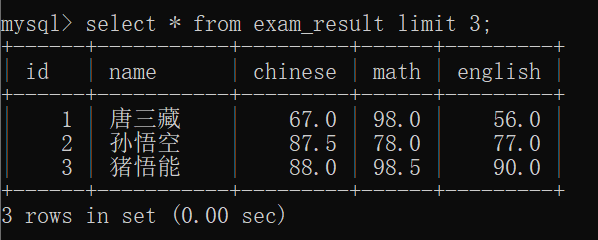
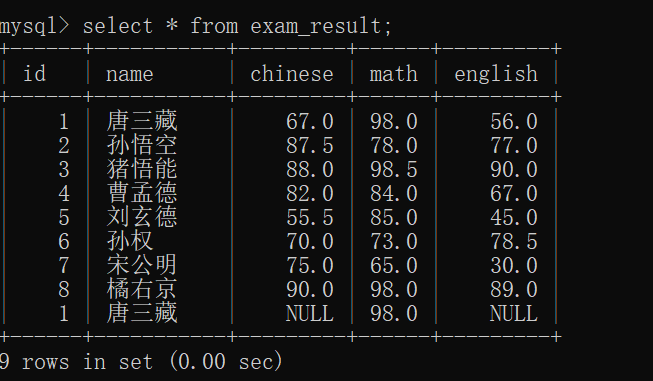
如果直接查询整个 exam_result表:
如果像下面的样子查询,就会得到前3条记录:
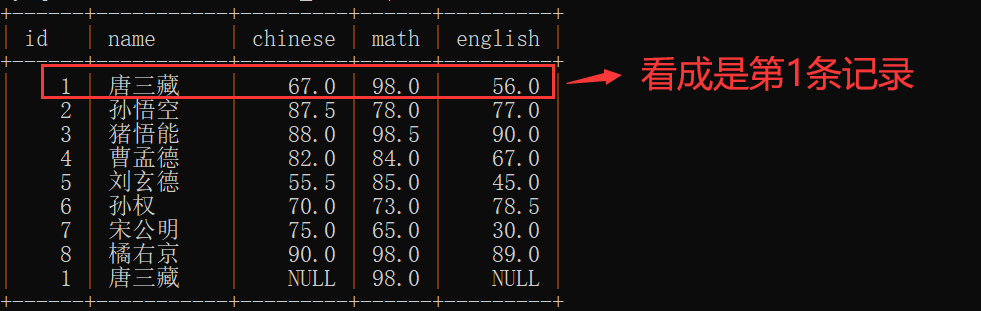
类似于数组,array[0] 用来表示 第1组 XXX,array[1] 用来表示 第2组 XXX......;
offset 后面接着的 数字M 可以看作 array[M],即 从第 M+1 条记录 开始查询:
此时,把第1行记录 看成是 第1条记录,如上表的:
所以说,
【说明】
这一块 是自己的巧记方法......
实际上可能不是这样解释的,关于偏移量啥啥的,
但是并不影响最终的结果,最终的结果是一样的~~
当然 如果不足的话,有几条记录 就返回(显示)几条记录:
一共有9条记录:
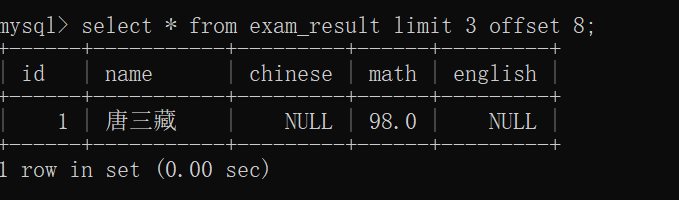
执行以下命令行:
从第9条记录开始,虽然说需要显示3条记录,但是不够了,所以只能显示1条记录
limit 是可以和order by,where等子句搭配使用的~~
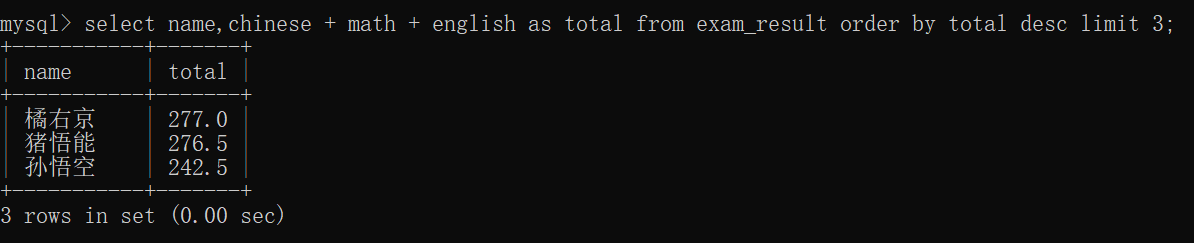
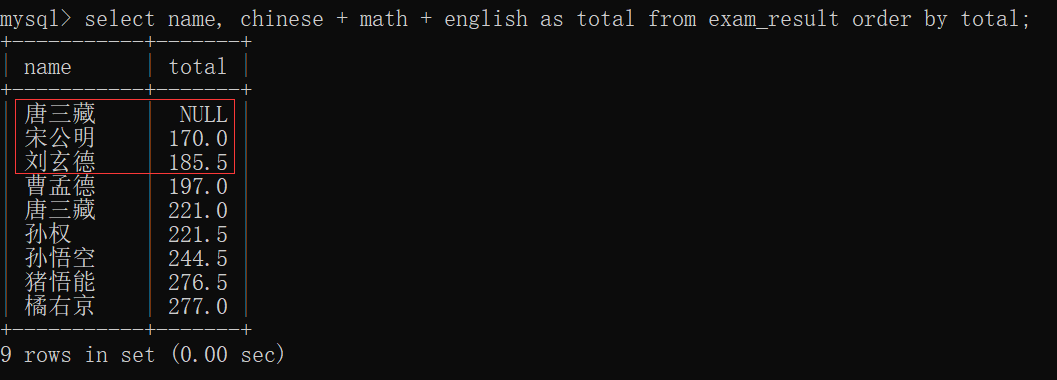
查询总成绩前三名的同学的信息~~

此处的修改,是针对数据库服务器进行的了~~
这里的修改是持续有效的~~
也就是说,这里的修改使磁盘上面保存的内容也变了,后面再怎么查询,也只是变化后的查询结果了~~
update 表名 set 列名 = 值1 (,列名 = 值2,...) where 子句;
--核心信息:针对哪个表的 哪些行 哪些列,改成啥样的值~~如:把 "孙悟空"同学 的数学成绩改为80分~~
此时,可以查看"孙悟空"同学的math成绩:
将"曹孟德"同学的数学成绩变更为60分,语文成绩变更为70分~~
将总成绩倒数前3的同学的数学成绩减去30分~~
总成绩最差先找出来:
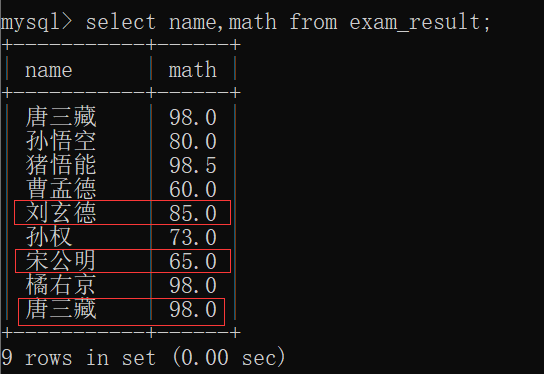
原先,他们三个人的math成绩:
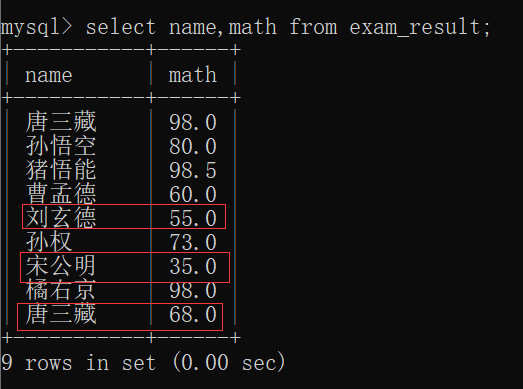
现在,把他们的成绩改一下:
update 后面的条件很关键~~
修改操作,是针对条件修改之后,剩下的数据进行修改~~
换句话说,如果没写条件,意位着就是针对所有行都进行修改~~

删除语句 是最最简单的~~
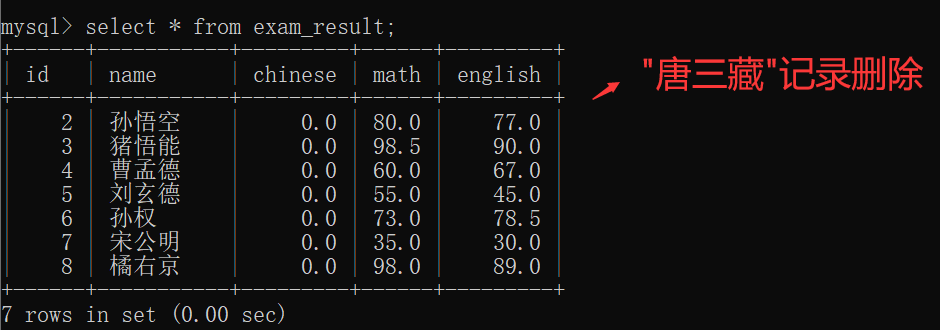
delete from 表名 where 条件; --删除符合条件的行~~例:删除姓名为"唐三藏"的同学的记录~~
如果没有条件的话,
即 delete from 表名;
意味着就把表里面的数据全部都删了,意味着只剩下一个空的表~~
例:
注意:
delete from 表名;
是把表的内容清空了,但是表的结构还在~~
drop table 表名;
是把整张表都给删除了~~

这就是MySQL数据库表的增删改查(基础)的全部内容啦~~
下一篇就是MySQL数据库表的增删改查(进阶)部分的内容了~~
如果这篇博客给你带来了收获~~
可以留下一颗小小的赞吗~~

关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi