这是一篇关于遗传算法的总结博客,包括算法思想,算法步骤,python实现的两个简单例子,算法进阶(持续更新ing)。
遗传算法的应用很多,诸如寻路问题,8数码问题,囚犯困境,动作控制,找圆心问题(在一个不规则的多边形中,寻找一个包含在该多边形内的最大圆圈的圆心),TSP问题,生产调度问题,人工生命模拟等。
遗传算法起源于对生物系统所进行的计算机模拟研究,是一种随机全局搜索优化方法,它模拟了自然选择和遗传中发生的复制、交叉(crossover)和变异(mutation)等现象,从任一初始种群(Population)出发,通过随机选择、交叉和变异操作,产生一群更适合环境的个体,使群体进化到搜索空间中越来越好的区域,这样一代一代不断繁衍进化,最后收敛到一群最适应环境的个体(Individual),从而求得问题的优质解。
举个已经举烂的例子:
我们把要求的函数曲线想象成一个一个山峰和山谷组成的山脉。那么我们可以设想每一个可能解都是一只袋鼠,我们希望它们不断的向更高处跳去,直到跳到最高的山峰(尽管袋鼠本身不见得愿意那么做)。
遗传算法是这样做的:有一大群袋鼠,有的跳跃能力强,喜欢往高处,有的跳跃能力弱,喜欢在低处。有一天它们被莫名其妙的零散地扔到喜马拉雅山脉,在那里艰苦的生活繁衍下去。海拔低的地方弥漫着一种无色无味的毒气,海拔越高毒气越稀薄。可怜的袋鼠们并不知道毒气的存在,还是活蹦乱跳。于是,不断有不善跳跃的袋鼠死于海拔较低的地方,而在海拔越高的善于跳跃的袋鼠活得越久,也越有机会生儿育女,把善于跳跃的基因传给后代。就这样经过许多年繁衍生息,这些袋鼠们渐渐聚拢到了一个个的山峰上。最终,只有最高的珠穆朗玛峰上的袋鼠被带回了美丽的澳洲。
术语介绍:
跟着B站一位博主的学习视频敲下了我的第一个遗传算法
视频链接
题目:在一个长度为n的数组nums中选择10个元素,使得10个元素的和与原数组的所有元素之和的1/10无限接近。
比如n=50,sum(nums)=1000,选择的元素列表answer要满足sum(answer)-100的绝对值小于e,e要尽可能的小。
思路:
import random
#1.创建初始解集
def create_answer(numbers_set,n):
result=[]#存放解集的列表
for i in range(n):#循环n次,每次创建一个解集(包含10个元素)
result.append(random.sample(numbers_set,10))#从初始数组中随机抽取10个元素
return result
#2.选择两个解
#计算误差
def error_level(new_answer,numbers_set):
error = []#存放适应度的列表
right_answer = sum(numbers_set)/10#正确答案,也就是原数组所有元素之和的1/10
for item in new_answer:
value = abs(right_answer-sum(item))#误差等于每个解与正确答案之差的绝对值
if value==0:#误差最小是0.1
error.append(10)#????
else:
error.append(1/value)#用反比例函数计算适应度
return error
#选择两个解
def choice_selected(old_answer,numbers_set):
result=[]
error = error_level(old_answer,numbers_set)#调用计算误差函数
error_one = [item/sum(error) for item in error]#归一化,列表每个元素除以列表总体元素之和,选择概率error_one
for i in range(1,len(error_one)):#叠加化
error_one[i] += error_one[i-1]
for i in range(len(old_answer)//2):#整体选两波
temp = []#存放父体母体的列表
for j in range(2):#一波选两个
rand = random.uniform(0,1)#从0-1中随机选择一个浮点数
for k in range(len(error_one)):#遍历寻找最接近的答案
if k==0:
if rand<error_one[k]:#如果该浮点数小于第一个数,选择出来放到temp中
temp.append(old_answer[k])
else:
if rand>=error_one[k-1] and rand<error_one[k]:#如果该浮点数处在两个数中间,将更大的选择出来放到temp中
temp.append(old_answer[k])
#3.交叉(交换信息)?????
rand = random.randint(0,6)
temp_1 = temp[0][:rand]+temp[1][rand:rand+3]+temp[0][rand+3:]#新子体temp1
temp_2 = temp[1][:rand]+temp[0][rand:rand+3]+temp[1][rand+3:]#新子体temp2
result.append(temp_1)
result.append(temp_2)
return result
#4.随机变异
def variation(old_answer,numbers_set,pro):
for i in range(len(old_answer)):
rand = random.uniform(0,1)
if rand<pro:#如果该随机浮点数小于0.1,就发生变异
rand_num = random.randint(0,9)#从该解中随便挑出一个元素,发生变异
old_answer[i] = old_answer[i][:rand_num]+random.sample(numbers_set,1)+old_answer[i][rand_num+1:]
return old_answer
numbers_set = random.sample(range(0,1000),50)#从0-1000随机抽取50个元素,创建初始nums数组
middle_answer = create_answer(numbers_set,100)#创建包含100个解的随机初始解集,每个解都是随机的10个元素
first_answer = middle_answer[0]#随便找个原始解
great_answer = []#最优解集
for i in range(1000):#训练1000次
middle_answer = choice_selected(middle_answer,numbers_set)#选择交叉完的middle
middle_answer = variation(middle_answer,numbers_set,0.1)#变异完的middle
error = error_level(middle_answer,numbers_set)#生成适应度列表
index = error.index(max(error))#挑出该群体中适应度最大的下标
great_answer.append([middle_answer[index],error[index]])
great_answer.sort(key=lambda x:x[1],reverse=True)#从大到小排序
print('正确答案为',sum(numbers_set)/10)
print('原始解为',sum(first_answer))
print('最优解为',great_answer[0][0])
print('最优解的和为',sum(great_answer[0][0]))
print('选择系数为',great_answer[0][1])
这里迭代了1000次,可以看到随机初始化得到的原始解与正确答案相差4869-2554.9,经过1000次迭代后,得到的最优解2555与正确答案只相差0.1。
正确答案为 2554.9
原始解为 4869
最优解为 [87, 451, 249, 249, 205, 258, 285, 0, 133, 638]
最优解的和为 2555
选择系数为 10.000000000009095
吾等菜鸡,皆需代码之实践
问题:求下列函数的最大值和最小值,定义域为
x
∈
[
−
3
,
3
]
,
y
∈
[
−
3
,
3
]
x∈[−3,3],y∈[−3,3]
x∈[−3,3],y∈[−3,3]
F
(
x
,
y
)
=
3
(
1
−
x
)
2
∗
e
(
−
(
x
2
)
−
(
y
+
1
)
2
)
−
10
(
x
5
−
x
3
−
y
5
)
e
(
−
x
2
−
y
2
)
−
1
3
e
(
−
(
x
+
1
)
2
−
y
2
)
F(x,y)=3(1-x)^2*e^{(-(x^2)-(y+1)^2)}- 10(\frac{x}{5} - x^3 - y^5)e^{(-x^2-y^2)}- \frac{1}{3^{e^{(-(x+1)^2 - y^2)}}}
F(x,y)=3(1−x)2∗e(−(x2)−(y+1)2)−10(5x−x3−y5)e(−x2−y2)−3e(−(x+1)2−y2)1
这么复杂的函数…拿GA解最适合不过了,开干!
该函数图像如下:
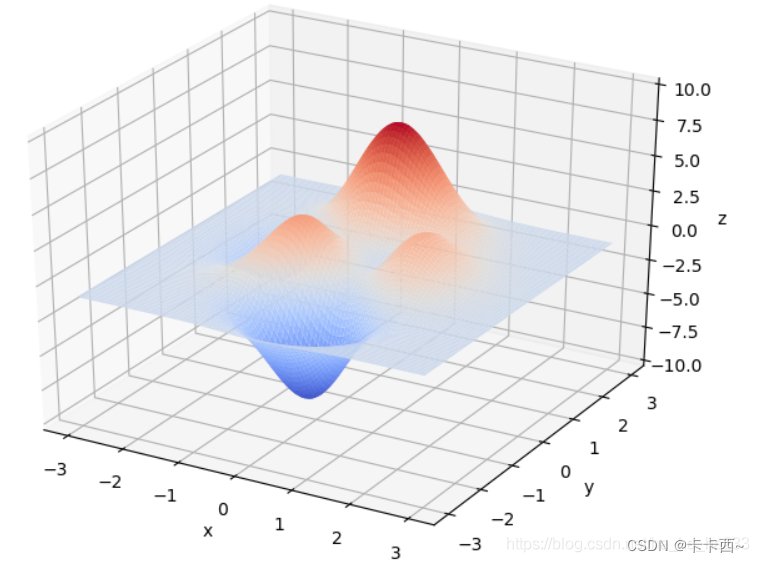
很直观的可以看到,最大值是当x ≈ 0 , y ≈ 1.5 时,那个深红色的尖尖,最小值是当x ≈ 0.2 , y ≈ -1.7 时,蓝色的尖尖,这两个就是全局最优解。另外两个小山包是极大值,是局部最优解,我们的目的就是求得那两个全局最优解,避免陷在局部最优解里。
先计算最大值。首先生成200个随机的(x,y)对,将(x, y)坐标对带入要求解的函数F(x,y)中,根据适者生存,我们定义使得函数值F(x,y)越大的(x,y)对越适合环境,从而这些适应环境的(x,y)对被保留下来的概率越大,而那些不适应该环境的(x,y)则有很大概率被淘汰,保留下来的点经过繁殖产生新的点,如此进化下去最后留下的大部分点都是适应环境的点,即在最高点附近。
最小值的计算过程同上,区别在于函数值F(x,y)越小的(x,y)对越适合环境。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
DNA_SIZE = 24
POP_SIZE = 200
CROSSOVER_RATE = 0.8
MUTATION_RATE = 0.005
N_GENERATIONS = 50
X_BOUND = [-3, 3]
Y_BOUND = [-3, 3]
def F(x, y):
return 3*(1-x)**2*np.exp(-(x**2)-(y+1)**2)- 10*(x/5 - x**3 - y**5)*np.exp(-x**2-y**2)- 1/3**np.exp(-(x+1)**2 - y**2)
def plot_3d(ax):
X = np.linspace(*X_BOUND, 100)
Y = np.linspace(*Y_BOUND, 100)
X,Y = np.meshgrid(X, Y)
Z = F(X, Y)
ax.plot_surface(X,Y,Z,rstride=1,cstride=1,cmap=cm.coolwarm)
ax.set_zlim(-10,10)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
plt.pause(3)
plt.show()
def get_fitness(pop):
x,y = translateDNA(pop)
pred = F(x, y)
return (pred - np.min(pred)) + 1e-3 #减去最小的适应度是为了防止适应度出现负数,通过这一步fitness的范围为[0, np.max(pred)-np.min(pred)],最后在加上一个很小的数防止出现为0的适应度
def translateDNA(pop): #pop表示种群矩阵,一行表示一个二进制编码表示的DNA,矩阵的行数为种群数目
x_pop = pop[:,1::2]#奇数列表示X
y_pop = pop[:,::2] #偶数列表示y
#pop:(POP_SIZE,DNA_SIZE)*(DNA_SIZE,1) --> (POP_SIZE,1)
x = x_pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*(X_BOUND[1]-X_BOUND[0])+X_BOUND[0]
y = y_pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*(Y_BOUND[1]-Y_BOUND[0])+Y_BOUND[0]
return x,y
def crossover_and_mutation(pop, CROSSOVER_RATE = 0.8):
new_pop = []
for father in pop: #遍历种群中的每一个个体,将该个体作为父亲
child = father #孩子先得到父亲的全部基因(这里我把一串二进制串的那些0,1称为基因)
if np.random.rand() < CROSSOVER_RATE: #产生子代时不是必然发生交叉,而是以一定的概率发生交叉
mother = pop[np.random.randint(POP_SIZE)] #再种群中选择另一个个体,并将该个体作为母亲
cross_points = np.random.randint(low=0, high=DNA_SIZE*2) #随机产生交叉的点
child[cross_points:] = mother[cross_points:] #孩子得到位于交叉点后的母亲的基因
mutation(child) #每个后代有一定的机率发生变异
new_pop.append(child)
return new_pop
def mutation(child, MUTATION_RATE=0.003):
if np.random.rand() < MUTATION_RATE: #以MUTATION_RATE的概率进行变异
mutate_point = np.random.randint(0, DNA_SIZE*2) #随机产生一个实数,代表要变异基因的位置
child[mutate_point] = child[mutate_point]^1 #将变异点的二进制为反转
def select(pop, fitness): # nature selection wrt pop's fitness
idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True,
p=(fitness)/(fitness.sum()) )
return pop[idx]
def print_info(pop):
fitness = get_fitness(pop)
max_fitness_index = np.argmax(fitness)
print("max_fitness:", fitness[max_fitness_index])
x,y = translateDNA(pop)
print("最优的基因型:", pop[max_fitness_index])
print("(x, y):", (x[max_fitness_index], y[max_fitness_index]))
if __name__ == "__main__":
fig = plt.figure()
ax = Axes3D(fig)
plt.ion()#将画图模式改为交互模式,程序遇到plt.show不会暂停,而是继续执行
plot_3d(ax)
pop = np.random.randint(2, size=(POP_SIZE, DNA_SIZE*2)) #matrix (POP_SIZE, DNA_SIZE)
for _ in range(N_GENERATIONS):#迭代N代
x,y = translateDNA(pop)
if 'sca' in locals():
sca.remove()
sca = ax.scatter(x, y, F(x,y), c='black', marker='o');plt.show();plt.pause(0.1)
pop = np.array(crossover_and_mutation(pop, CROSSOVER_RATE))
#F_values = F(translateDNA(pop)[0], translateDNA(pop)[1])#x, y --> Z matrix
fitness = get_fitness(pop)
pop = select(pop, fitness) #选择生成新的种群
print_info(pop)
plt.ioff()
plot_3d(ax)
算法的运行过程如下,可以看到随着迭代的进行,散落在各地的解渐渐向最高处聚集:

运行结果:
max_fitness: 0.10333042920383484
最优的基因型: [1 1 1 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 1 1 0 1 1 1 0 0 1 0 1 1 0
1 1 1 0 1 1 0 1 0 0 1]
(x, y): (0.04820019294024647, 1.571304832178642)
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
我收到错误:unsupportedcipheralgorithm(AES-256-GCM)(RuntimeError)但我似乎具备所有要求:ruby版本:$ruby--versionruby2.1.2p95OpenSSL会列出gcm:$opensslenc-help2>&1|grepgcm-aes-128-ecb-aes-128-gcm-aes-128-ofb-aes-192-ecb-aes-192-gcm-aes-192-ofb-aes-256-ecb-aes-256-gcm-aes-256-ofbRuby解释器:$irb2.1.2:001>require'openssl';puts
文章目录一.Dijkstra算法想解决的问题二.Dijkstra算法理论三.java代码实现一.Dijkstra算法想解决的问题解决的问题:求解单源最短路径,即各个节点到达源点的最短路径或权值考察其他所有节点到源点的最短路径和长度局限性:无法解决权值为负数的情况二.Dijkstra算法理论参数:S记录当前已经处理过的源点到最短节点U记录还未处理的节点dist[]记录各个节点到起始节点的最短权值path[]记录各个节点的上一级节点(用来联系该节点到起始节点的路径)Dijkstra算法步骤:(1)初始化:顶点集S:节点A到自已的最短路径长度为0。只包含源点,即S={A}顶点集U:包含除A外的其他顶
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
我正在尝试计算由二进制形式的1和0的P数表示的数字的数量。如果P=2,则表示的数字为0011、1100、0110、0101、1001、1010,所以计数为6。我试过:[0,0,1,1].permutation.to_a.uniq但这不是大数的最佳解决方案(P可以什么可能是最好的排列技术,或者我们是否有任何直接的数学来做到这一点? 最佳答案 Numberofpermutationcanbecalculatedusingfactorial.a=[0,0,1,1](1..a.size).inject(:*)#=>4!=>24要计算重复项,