目录
前段时间 Zotero 更新后,将文献阅读器集成进去了,还挺好用,基本的功能都有,包括目录、缩略图、笔记等等,没有其他花里胡哨的功能,平常看文献这些也就够了,对于十分崇尚简洁界面的我来说,真的是眼睛一亮(见下图),于是就决定以后用 Zotero 自带的阅读器阅读了。但是美中不足的是缺少了翻译的功能,最近发现 Zotero 插件能完美解决这个问题,不禁感叹:开源的文件管理软件扩展性真的牛批!! 于是决定写一篇博客总结一下几个非常好用的插件,包含下载链接及配置方法噢 ~

打开软件,找到『工具选项卡』-『插件』,点击右上角的『齿轮』,选择 『Install Add-on from File』,然后选择.xpi文件安装即可(安装完需要重启 Zotero 插件方可生效)
注意:
- 后面介绍的时候会放
GitHub 链接,下载最新版本的插件,只需下载.xpi文件即可。- 如果发现最新的插件和本地的 Zotero 软件版本不兼容,则换低版本的插件就可以了。
- 考虑到很多小伙伴 Github 网站访问较慢的问题,文末会分享
CSDN链接和百度网盘链接~
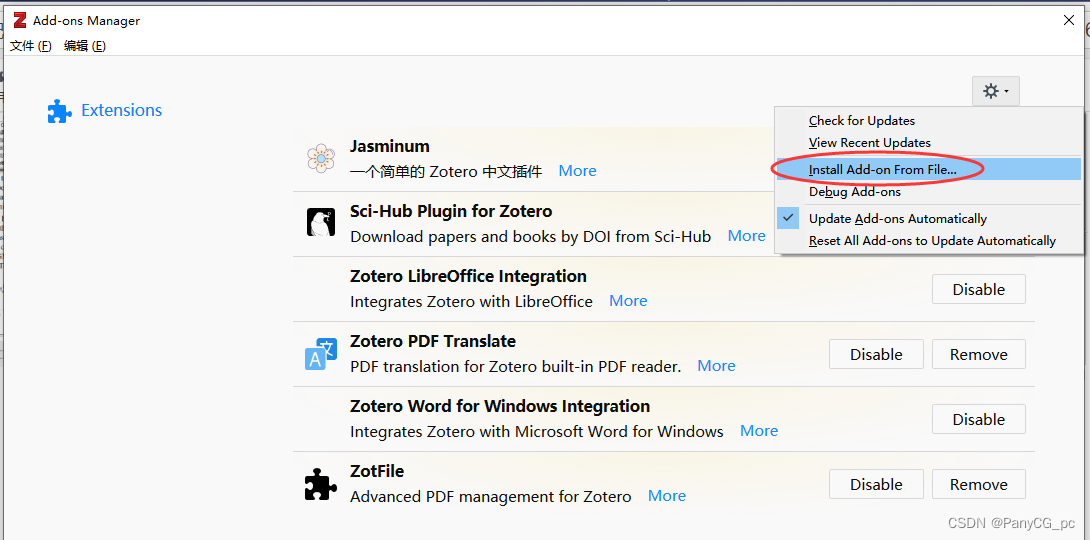

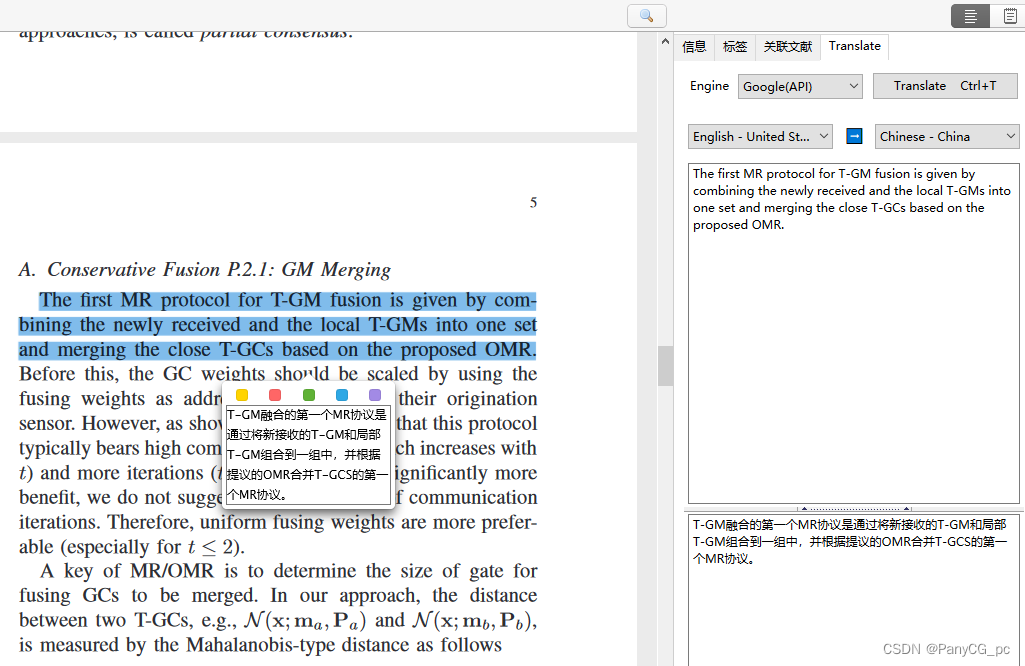
PDF Translate 是 Zotero 6 的附加组件之一,它为 Zotero 内置的 PDF 阅读器提供 PDF 翻译功能。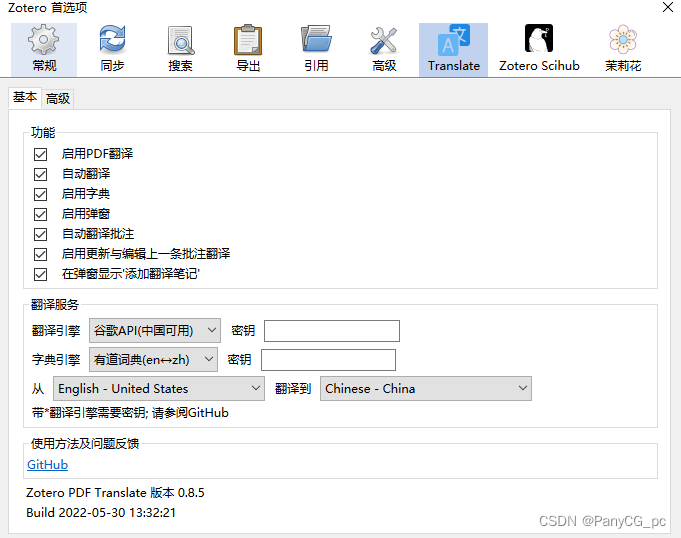

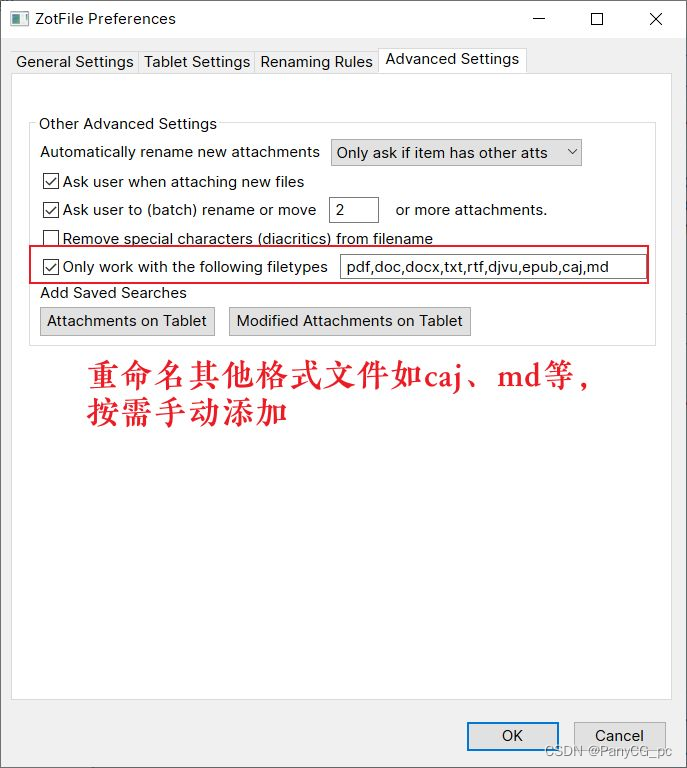
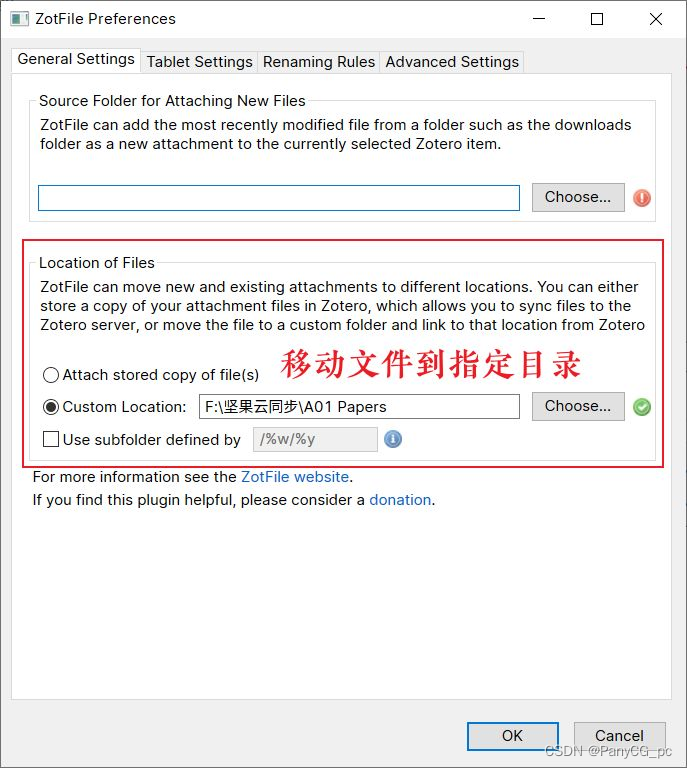
ZotFile 用于管理文献附件,例如移动、格式化重命名等。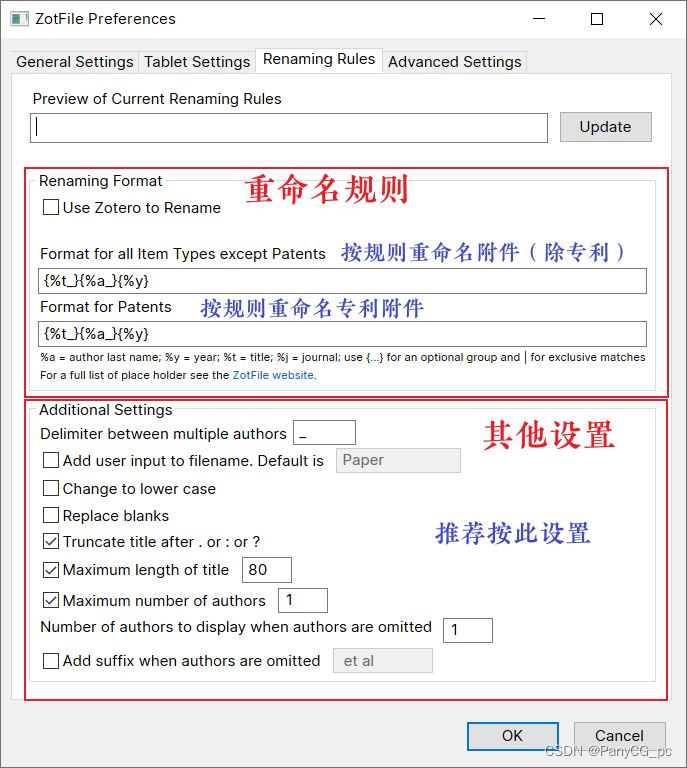

PDFtk server)
PDFtk server 下载链接:https://www.pdflabs.com/tools/pdftk-server/

我看到这个错误:translationmissing:da.datetime.distance_in_words.about_x_hours我的语言环境文件:http://pastie.org/2944890我的看法:我已将其添加到我的application.rb中:config.i18n.load_path+=Dir[Rails.root.join('my','locales','*.{rb,yml}').to_s]config.i18n.default_locale=:da如果我删除I18配置,帮助程序会处理英语。更新:我在config/enviorments/devolpment
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我需要一个表,其中行实际上是2行表,一个嵌套表是..我怎样才能在Prawn中做到这一点?也许我需要延期..但哪一个? 最佳答案 现在支持子表:Prawn::Document.generate("subtable.pdf")do|pdf|subtable=pdf.make_table([["sub"],["table"]])pdf.table([[subtable,"original"]])end 关于ruby-on-rails-PrawnPDF:Ineedtogeneratenested
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
我的Rails应用程序中安装了carrierwave。但是,当用户上传多页pdf时,我只希望应用程序获取文档中的第一页并将其转换为jpeg。这可能吗?用什么命令?这是我的uploader。#encoding:utf-8classImageUploader[200,300]##defscale(width,height)##dosomething#end#Createdifferentversionsofyouruploadedfiles:version:thumbdoprocess:resize_to_fill=>[150,210]process:convert=>:jpgdefful
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
我要下载http://foobar.com/song.mp3作为song.mp3,而不是让Chrome在其native中打开它浏览器中的播放器。我怎样才能做到这一点? 最佳答案 您只需要确保发送这些header:Content-Disposition:attachment;filename=song.mp3;Content-Type:application/octet-streamContent-Transfer-Encoding:binarysend_file方法为您完成:get'/:file'do|file|file=File.
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案