在vue中使用v-for时需要,都会提示或要求使用 :key,有的的开发者会直接使用数组的 index 作为 key 的值,但不建议直接使用 index作为 key 的值,有时我们面试时也会遇到面试官问:为什么不推荐使用 index 作为 key ?接下来和小颖一起来瞅瞅吧
当 Vue 正在更新使用 v-for 渲染的元素列表时,它默认使用“就地更新”的策略。如果数据项的顺序被改变,Vue 将不会移动 DOM 元素来匹配数据项的顺序,而是就地更新每个元素,并且确保它们在每个索引位置正确渲染。这个类似 Vue 1.x 的 track-by="$index"。
这个默认的模式是高效的,但是只适用于不依赖子组件状态或临时 DOM 状态 (例如:表单输入值) 的列表渲染输出。
为了给 Vue 一个提示,以便它能跟踪每个节点的身份,从而重用和重新排序现有元素,你需要为每项提供一个唯一 key attribute:
官网解释:key
预期:number | string | boolean (2.4.2 新增) | symbol (2.5.12 新增)key 的特殊 attribute 主要用在 Vue 的虚拟 DOM 算法,在新旧 nodes 对比时辨识 VNodes。如果不使用 key,Vue 会使用一种最大限度减少动态元素并且尽可能的尝试就地修改/复用相同类型元素的算法。而使用 key 时,它会基于 key 的变化重新排列元素顺序,并且会移除 key 不存在的元素。
有相同父元素的子元素必须有独特的 key。重复的 key 会造成渲染错误。
通俗解释:
key 在 diff 算法的作用,就是用来判断是否是同一个节点。
Vue 中使用虚拟 dom 且根据 diff 算法进行新旧 DOM 对比,从而更新真实 dom ,key 是虚拟 DOM 对象的唯一标识, 在 diff 算法中 key 起着极其重要的作用,key可以管理可复用的元素,减少不必要的元素的重新渲染,也要让必要的元素能够重新渲染。
使用 index 做 key,破坏顺序操作的时候, 因为每一个节点都找不到对应的 key,导致部分节点不能复用,所有的新 vnode 都需要重新创建。
示例:
<template>
<div class="hello">
<ul>
<li v-for="(item,index) in studentList" :key="index">{{ item.name }}</li>
</ul>
<br>
<button @click="addStudent">添加一条数据</button>
</div>
</template>
<script>
export default {
name: 'ceshi',
data() {
return {
studentList: [
{id: 1, name: '张三', age: 18},
{id: 2, name: '李四', age: 19},
{id: 3, name: '王麻子', age: 20},
],
};
},
methods: {
addStudent() {
const studentObj = {id: 4, name: '王五', age: 20};
this.studentList = [studentObj, ...this.studentList]
}
}
}
</script>打开浏览器的开发工具,修改数据的文本,后面加上 “-我没变”,点击添加一条数据 按钮,则发现dom整体都变了

当给key绑定唯一不重复的值时:
<li v-for="item in studentList" :key="item.id">{{ item.name }}</li>打开浏览器的开发工具,修改数据的文本,后面加上 “-我没变”,点击添加一条数据 按钮,则发现只是顶部多了一条,其他dom没有重新渲染。
当用index做key时,当我们在前面加了一条数据时 index 顺序就会被打断,导致新节点 key 全部都改变了,所以导致我们页面上的数据都被重新渲染了。而用了不会重复的唯一标识id时,diff算法比较后发现只有头部有变化,其他没有变,则只给头部新增了一个元素。从上面比较可以看出,用唯一值作为 key 可以节约开销这样大家应该就明白了吧·················
示例:
<template>
<div class="hello">
<ul>
<li v-for="item in studentList" :key="item.id">{{ item.name }}<input /></li>
</ul>
<br>
<button @click="addStudent">添加一条数据</button>
</div>
</template>
<script>
export default {
name: 'ceshi',
data() {
return {
studentList: [
{id: 1, name: '张三', age: 18},
{id: 2, name: '李四', age: 19}
],
};
},
methods: {
addStudent() {
const studentObj = {id: 4, name: '王五', age: 20};
this.studentList = [studentObj, ...this.studentList]
}
}
}
</script>我们往 input 里面输入一些值,添加一位同学看下效果:
这时候我们就会发现,在添加之前输入的数据错位了。添加之后王五的输入框残留着张三的信息,这很显然不是我们想要的结果。
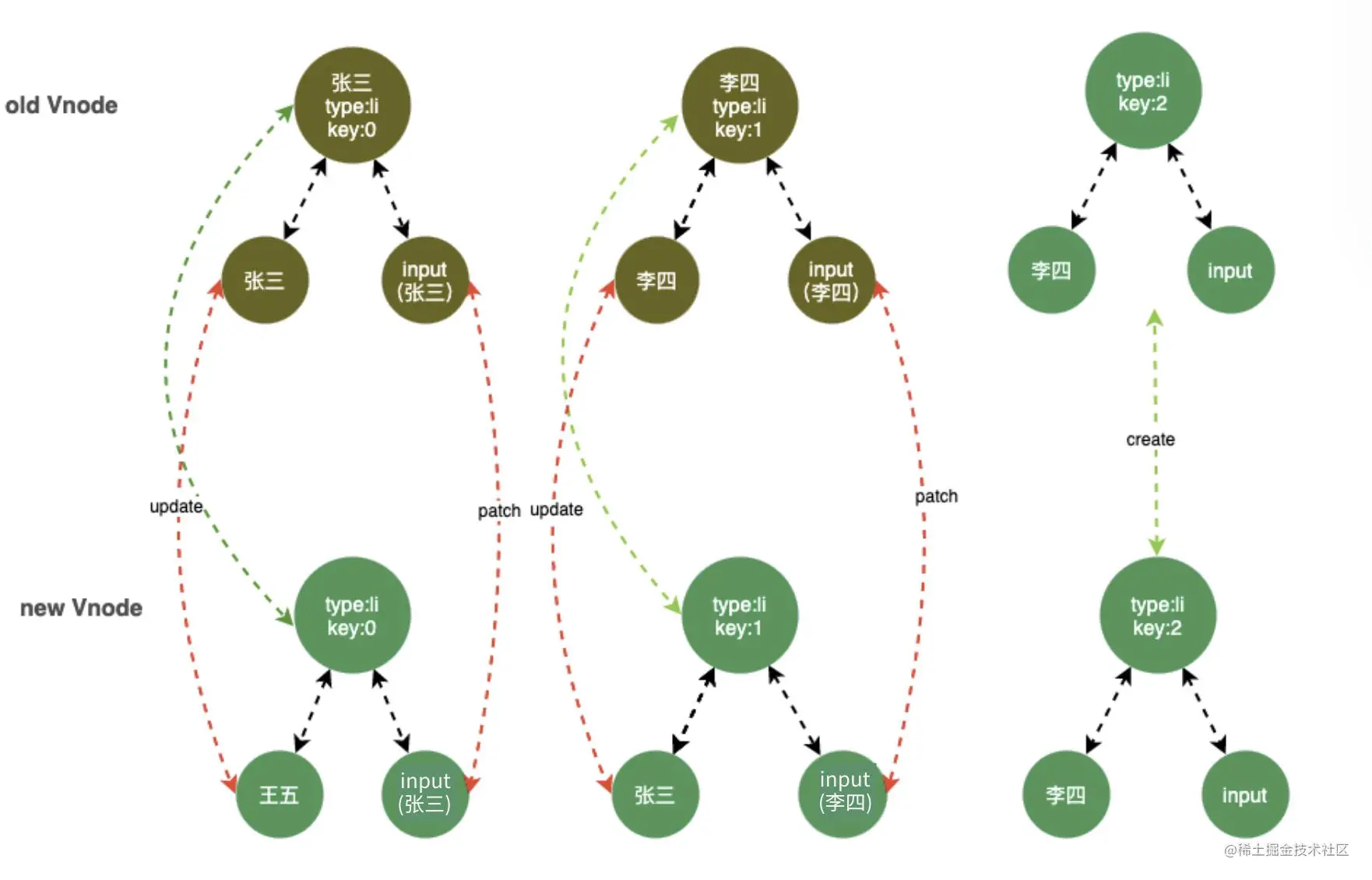
从上面比对可以看出来这时因为采用 index 作为 key 时,当在比较时,发现虽然文本值变了,但是当继续向下比较时发现 DOM 节点还是和原来一摸一样,就复用了,但是没想到 input 输入框残留输入的值,这时候就会出现输入的值出现错位的情况
当我们将key绑定为唯一标识id时,如图所示。key 相同的节点都做到了复用。起到了diff 算法的真正作用。

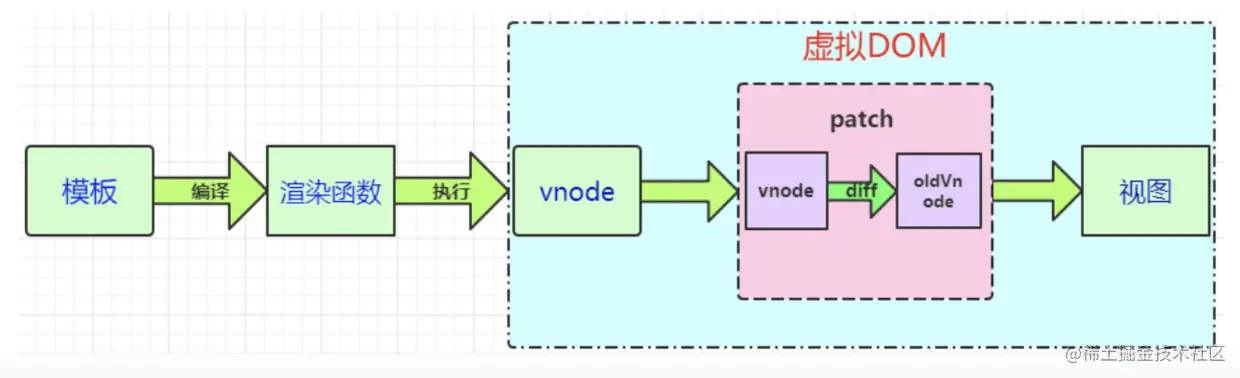
Vue.js通过编译将模版转换成渲染函数(render),执行渲染函数就可以得到一个以vnode节点(JavaScript对象)作为基础的树形结构,vnode节点里面包含标签名(tag)、属性(attrs)和子元素对象(children)等等属性,这个树形结构就是Virtual DOM,简单来说,可以把Virtual DOM理解为一个树形结构的JS对象。
参考: 浅谈Vue中的虚拟DOM
简而言之 虚拟DON就是javascript对象,通过对虚拟 DOM进行diff,算出最小差异,然后更新真实的DOM。
如果大家不太明白的话,我们来看个示例
<template>
<div class="hello">
<ul>
<li v-for="(item,index) in studentList" :key="item.id" @click="changeName(index)">{{ item.name }}</li>
</ul>
</div>
</template>
<script>
export default {
name: 'ceshi',
data() {
return {
studentList: [
{id: 1, name: '张三', age: 18},
{id: 2, name: '李四', age: 19},
{id: 3, name: '王麻子', age: 20},
],
};
},
methods: {
changeName(index) {
this.studentList[index].name = '我变啦'
}
}
}
</script>上面的修改数组值得方式 仅在 2.2.0+ 版本中支持 Array + index 用法。
如果使用之前的则使用 Vue.set( target, propertyName/index, value )
运行后,我们打开开发者工具,然后手动修改页面的文本,给每个后面加 “-我没变”
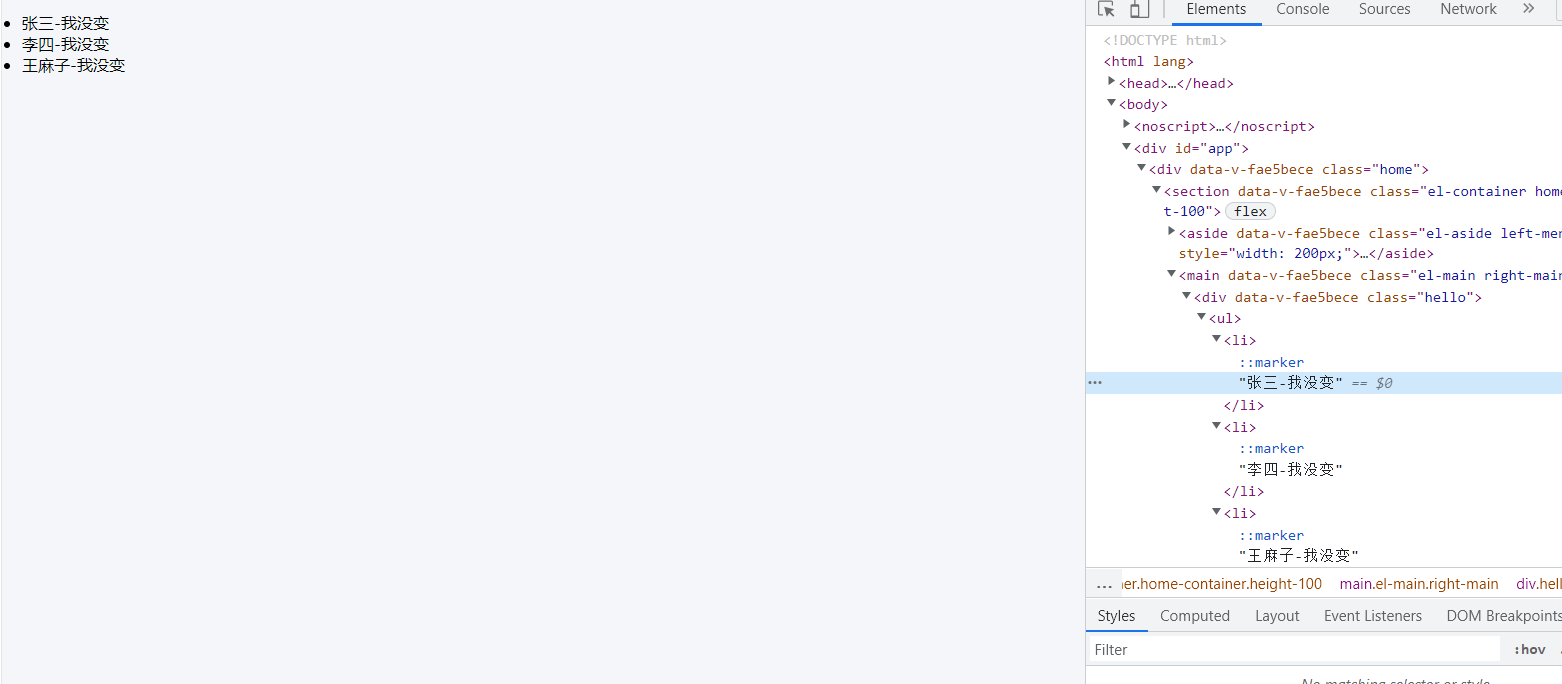
然后随便点击其中一个,我们会发现只有点击那个文本变了,并且只是它的文本内容变了,dom并没有整体变。

参考: 浅谈Vue中的虚拟DOM
简单来说就是:通过编译将模版转换成渲染函数(render),执行渲染函数就可以得到一个以vnode节点(JavaScript对象)作为基础的树形结构(虚拟dom),当数据发生变化虚拟dm通过diff算法找出新树和旧树的不同,记录两棵树差异根据差异应用到所构建的真正的DOM树上,视图就更新。
虚拟DOM中,在DOM的状态发生变化时,虚拟DOM会进行Diff运算,来更新只需要被替换的DOM,而不是全部重绘。 在Diff算法中,只平层的比较前后两棵DOM树的节点,没有进行深度的遍历。
同层比较,如上面div的Old Vnode,跟其Vnode比较,div只会跟同层div比较,不会跟p进行比较,下面是示例图:

当数据发生改变时,set方法会让调用Dep.notify通知所有订阅者Watcher,订阅者就会调用patch给真实的DOM打补丁,更新相应的视图。
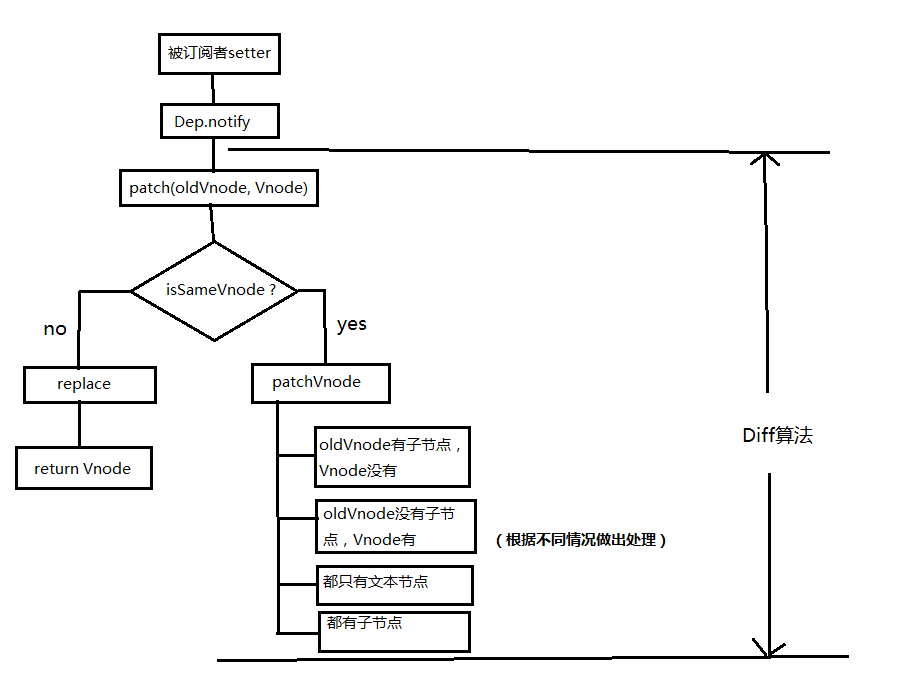
来看看patch是怎么打补丁的(代码只保留核心部分)
function patch (oldVnode, vnode) {
// some code
if (sameVnode(oldVnode, vnode)) {
patchVnode(oldVnode, vnode)
} else {
const oEl = oldVnode.el // 当前oldVnode对应的真实元素节点
let parentEle = api.parentNode(oEl) // 父元素
createEle(vnode) // 根据Vnode生成新元素
if (parentEle !== null) {
api.insertBefore(parentEle, vnode.el, api.nextSibling(oEl)) // 将新元素添加进父元素
api.removeChild(parentEle, oldVnode.el) // 移除以前的旧元素节点
oldVnode = null
}
}
// some code
return vnode
}patch函数接收两个参数oldVnode和Vnode分别代表新的节点和之前的旧节点
patchVnode
function sameVnode (a, b) {
return (
a.key === b.key && // key值
a.tag === b.tag && // 标签名
a.isComment === b.isComment && // 是否为注释节点
// 是否都定义了data,data包含一些具体信息,例如onclick , style
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b) // 当标签是<input>的时候,type必须相同
)
}Vnode替换oldVnode如果两个节点都是一样的,那么就深入检查他们的子节点。如果两个节点不一样那就说明Vnode完全被改变了,就可以直接替换oldVnode。
虽然这两个节点不一样但是他们的子节点一样怎么办?别忘了,diff可是逐层比较的,如果第一层不一样那么就不会继续深入比较第二层了。(我在想这算是一个缺点吗?相同子节点不能重复利用了...)
当我们确定两个节点值得比较之后我们会对两个节点指定patchVnode方法。那么这个方法做了什么呢?
patchVnode (oldVnode, vnode) {
const el = vnode.el = oldVnode.el
let i, oldCh = oldVnode.children, ch = vnode.children
if (oldVnode === vnode) return
if (oldVnode.text !== null && vnode.text !== null && oldVnode.text !== vnode.text) {
api.setTextContent(el, vnode.text)
}else {
updateEle(el, vnode, oldVnode)
if (oldCh && ch && oldCh !== ch) {
updateChildren(el, oldCh, ch)
}else if (ch){
createEle(vnode) //create el's children dom
}else if (oldCh){
api.removeChildren(el)
}
}
}这个函数做了以下事情:
elVnode和oldVnode是否指向同一个对象,如果是,那么直接returnel的文本节点设置为Vnode的文本节点。oldVnode有子节点而Vnode没有,则删除el的子节点oldVnode没有子节点而Vnode有,则将Vnode的子节点真实化之后添加到elupdateChildren函数比较子节点,这一步很重要参考:详解vue的diff算法
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or