前一节介绍说,

这里主要介绍 tf.keras 中的 Sequential 模型。
Sequential 是 Keras 中的一种神经网络框架,可以被认为是一个容器,其中封装了神经网络的结构。Sequential 模型只有一组输入和一组输出。各层之间按照先后顺序进行堆叠。前面一层的输出就是后面一次的输入。通过不同层的堆叠,构建出神经网络。
model = tf.keras.Sequential()
这条语句表示建立了一个 Sequential 模型,并给它取了一个名字 model ,输出这个 model ,

可以看出它是 keras 中的 Sequential 类的对象 。
这个 model 是一个空的容器,现在就需要向其中添加层,构成神经网络。这也是 Sequential 模型的核心操作。
model.add(tf.keras.layers...)
keras 中内置了很多神经网络 中常见的层,例如:全连接层、卷积层、池化层等。

它们都是 layers 类中的函数,可以直接作为 add 的参数,例如

Dense 表示全连接层,
参数 inputs 表示指定该网络层中的神经元个数,
参数 activation 表示激活函数,以字符串的形式给出,包括relu、softmax、Sigmoid、Tanh 等。

参数 input_shape 表示输入数据的形状。
全连接神经网络中的第一层接收来自输入层的数据,必须要指明形状,后面的层接收前面一层的输出,不用再指明输入数据的形状。
在定义神经网络之后,可以使用它的 summary() 函数来查看网络的结构和参数信息。
例如,为了实现某个多分类任务,需要构建一个三层神经网络。
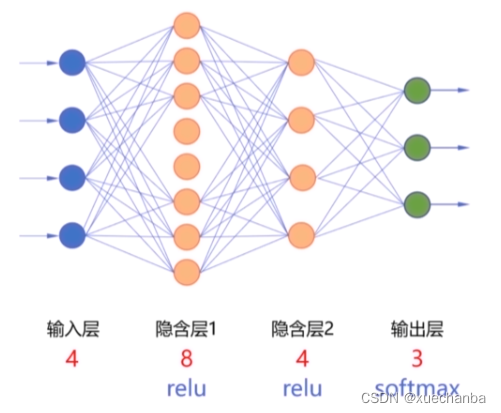
其中,
输入层中有4个结点,
隐含层1中有8个神经元
隐含层2中有4个神经元
输出层中有3个神经元
隐含层1 和 隐含层2 中的激活函数为 relu 函数,输出层的激活函数为 softmax 函数。
现在,我们就用 Sequential 模型来构建这个网络,
import tensorflow as tf
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(8, activation="relu", input_shape=(4, ))) # 添加第一个隐含层, 需要指定输入层的形状
model.add(tf.keras.layers.Dense(4, activation="relu")) # 添加第二个隐含层, 不需要指定输入层的形状
model.add(tf.keras.layers.Dense(3, activation="softmax")) # 添加输出层, 不需要指定输入层的形状
下面,再使用 model 的 summary() 函数来查看网络的结构和参数信息。
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 8) 40
_________________________________________________________________
dense_1 (Dense) (None, 4) 36
_________________________________________________________________
dense_2 (Dense) (None, 3) 15
=================================================================
Total params: 91
Trainable params: 91
Non-trainable params: 0
_________________________________________________________________
None
"""
其中,Dense 表示全连接。

每一层输出的形状,如下图所示。

也就是各层中神经元的个数。
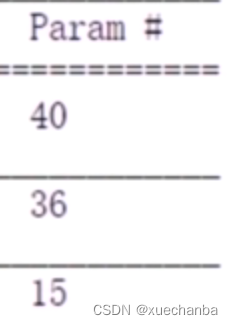
每层中的参数个数。
在输入层和隐含层1之间有 32 个权值(w),8个阈值(b),一共 40 个参数。
在隐含层1和隐含层2之间有32个权值,4个阈值,一共是 36 个参数。
在隐含层2和输出层之间有12个权值,3个阈值,一共15个参数。
在整个神经网络中,一共有91个模型参数,它们都是可训练参数。

在构建网络模型时,也可以采用下面这种形式,直接将每一层作为参数传进去。
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(8, activation="relu", input_shape=(4, )),
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(3, activation="softmax")
])
model.compile(loss, optimizer, metrics)
其中,参数 loss 是损失函数,optimizer 是优化器,metrics 是模型训练时,我们希望输出的评测指标。
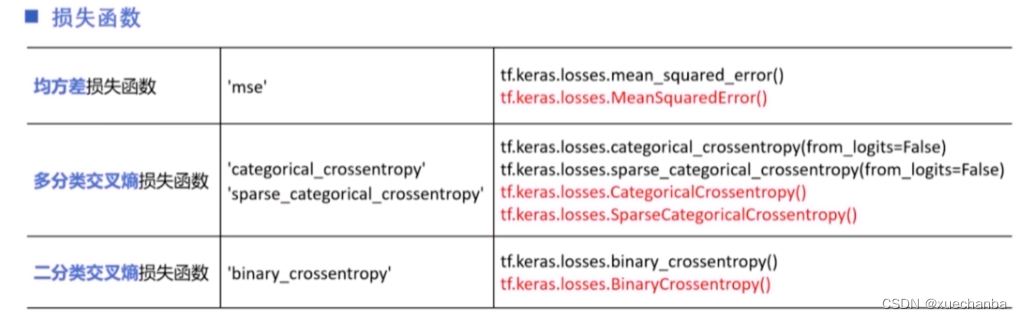
下图为 tf.keras 中常用的损失函数。
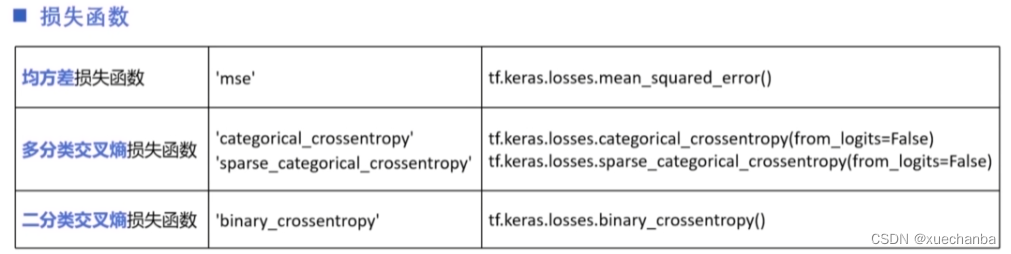
可以以字符串的形式给出(左边列),也可以以函数形式给出(右边列)。
对于多分类交叉熵损失函数来说,当标签值采用独热编码表示时,使用第一个,当标签值采用自然顺序码表示时,使用第二个。多分类交叉熵损失函数中有一个参数 from_logits,表示神经网络在输出前是否已经使用 softmax 函数将预测结果变换为概率分布(所有的输出之和概率为1),(当该参数为false时,表示已经将预测结果变换为概率分布,而该参数为true时,则表示不用将预测结果变换为概率分布,即原始输出。)我们前面介绍的多分类网络都是这样处理的。
在逻辑回归进行二分类时,通常就使用二分类交叉熵损失损失函数,与激活函数 Sigmoid 搭配使用。
这些损失函数都是 tf.keras 中 losses 类中的子类,因此也可以采用下表中所列出的形式进行操作。
在前面的课程中,我们介绍了训练神经网络的各种优化算法。
在 keras 中,提供了一系列的优化器来实现这些优化算法,

它们都是 optimizer 的子类,在使用它们时,可以以字符串的形式给出优化器的名称(左边列),也可以以函数形式给出(右边列)。使用函数,可以设定学习率,权重等超参数。
SGD Optimizer 是小批量随机梯度下降算法。
Adam Optimizer 是对SGD的扩展,可以代替经典的随机随机梯度下降法来更有效地更新网络权重。
要注意的是,在 tf.train 中也提供了一系列的优化器,在 TensorFlow 1.x 版本中被广泛使用。但是在 TensorFlow 2.0 + 版本中,建议使用 tf.keras 中的优化器,否则可能会因为参数命名冲突等问题在学习率衰减时无法正确的执行。
参数 metrics 用来指定训练模型时所使用的评价指标,这里可以使用

也可以使用

在

类中,预定义了很多常用的评价函数,例如,下图均是准确率评价函数。
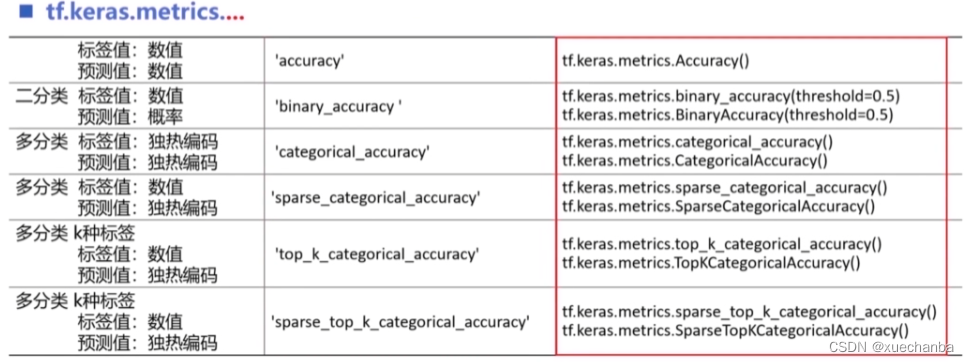
同样既可以以字符串的形式给出,也可以以函数的形式给出。
当数据集的标签值和神经网络输出的预测值均为数值(也就是以标量的形式给出)时,使用 accuracy 字符串或函数。
在二分类问题中,标签值为数值,预测值为概率,这时使用 binary_accuracy 。参数 threadhold 用来指定阈值,默认为 0.5。例如,下图分别为四个样本的标签值和相应的模型预测出来的概率,

阈值为0.5,表示当预测值大于 0.5 时被归类为 1 ,当小于 0.5 时被归类为 0。显然,前面三个样本预测正确,该模型的分类准确率为 75%
对于多分类问题中的标签值和预测值均采用独热编码形式给出时,使用 categorical_accuracy 这个字符串或相应函数,它比较两个向量中最大元素的下标值是否一致,例如在鸢尾花分类中,把标签值表示为独热编码的形式,

其中的元素分别表示样本属于各个类别的概率,标签值和预测值中最大元素的下标一致,则预测正确。
对于多分类问题中的标签值是数值类型,而预测值以独热编码形式给出时,使用 sparse_categorical_accuracy 这个字符串或相应函数,例如在鸢尾花分类中,我们可以直接采用自然顺序码(0,1,2)来表示鸢尾花的类别,

输入神经网络,网络输出的预测值是向量形式,其中的元素分别表示样本属于各个类别的概率。
上表中相应的两行,

不再只是比较最大概率的下标,而是可以接受预测概率中的前 K 种标签,例如,当 K = 3 时,只要预测值概率排名前三列的类别中有一个和标签值一致,就算预测正确。显然,这个评价标准更加宽松。
下图为 tf.keras 中其他的评价函数,有求和、求平均值、交叉熵损失等。

在需要使用时,可以在

中找到说明文档。
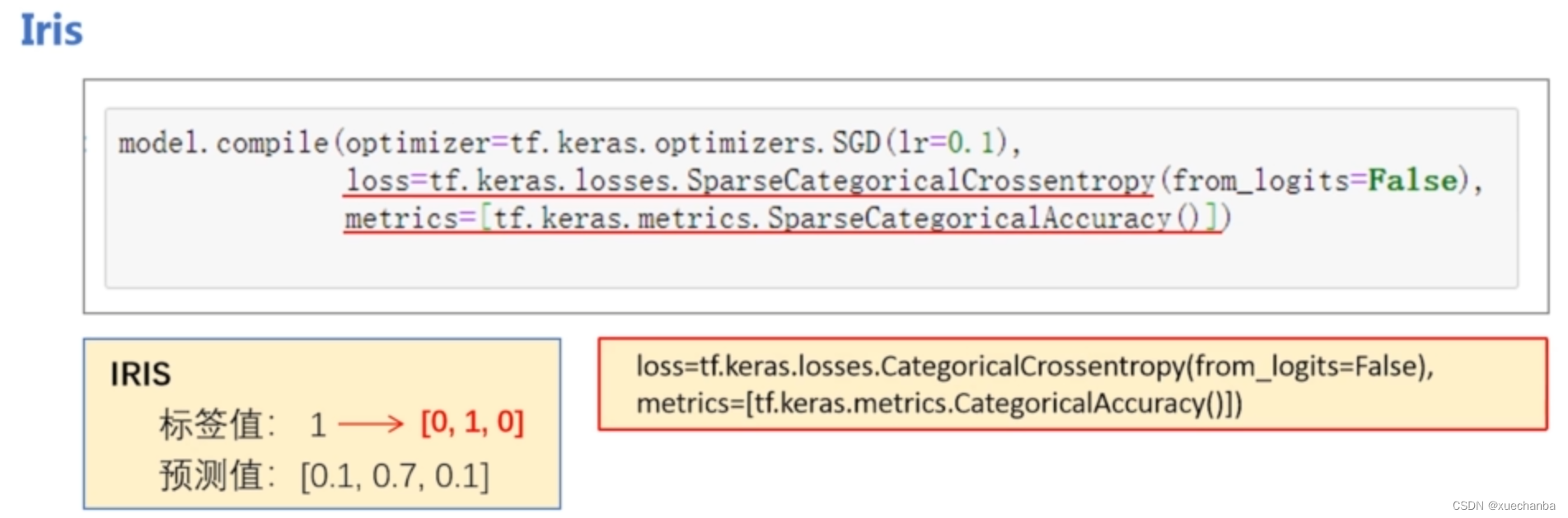
下图为针对鸢尾花数据集进行训练的 compile 语句
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
optimizer=tf.keras.optimizers.SGD(lr=0.1),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
鸢尾花数据集中,鸢尾花的类别采用自然顺序码表示,

因为神经网络的输出是经过 softmax 函数变换后得到的向量形式,因此,损失函数使用稀疏交叉熵损失函数。参数 from_logits 设置为 False,这里 False 是默认值,也可以不写。
这里的优化器采用小批量梯度下降算法,使用函数形式进行引用,并且设置学习率为 0.1 。
因为是多分类问题,且标签值为数值、预测值为独热编码的形式,所以准确率函数使用稀疏交叉熵准确率函数。此外,还要注意的是这里要使用中括号括起来。在这个中括号中,可以同时列出多个评价函数,用逗号隔开。
如果我们在数据预处理时,已经把鸢尾花数据的类别转换为独特编码的形式,那么相应的评价函数和损失函数也要进行修改。
下图为针对手写数字集 Mnist 进行训练的 compile 语句
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['sparse_categorical_accuracy'])
上述参数全部采用字符串形式进行表示。
配置好训练方法之后,就可以开始训练模型了。
模型的训练通过 fit 方法,

其中,需要说明的几点如下:
参数 shuffle 表示是否在每轮训练之前打乱数据,默认为 true 。
在训练过程中,可以同时使用测试集数据计算模型的评价指标,

上图中的这两个参数就是用来划分测试集数据的。这两个参数分别以不同的方式指定了测试集,是二选一的。如果同时给出,那么参数集数据就会覆盖参数设置集比例。
其中,validation_split 的取值为 0 — 1之间的小数。例如,0.2,就表示从训练家中抽取 20% 的数据作为测试集。测试集不参与训练,用来在训练的过程中,测试模型的误差、准确率等指标。
要注意的是,程序在执行 fit 方法时,是先执行 validation_split 参数来划分数据集,然后再执行 shuffle 参数来确定是否打乱数据。如果原始的数据集本身是有序的,那么在执行第一轮训练之前,应该首先打乱顺序。
参数 validation_freq 用来指定测试频率,也就是每隔多少轮训练并使用测试集计算和输出一次评测指标,默认为1。
参数 verbose 用来控制输出信息显示的方式,取值如下:

下图为 fit 方法中各个参数的默认值:

在手写数字识别程序中,训练模型的代码如下图所示:

其中,X_train 和 y_train 是训练集的属性和标签,批量大小为 32 ,一共训练 5 轮,测试数据的比例为数据集中数据的 20 %。
在手写数字集 Mnist 中,一共有 60000 条数据,现在 48000 条数据用来训练模型,划分出去12000条作为测试数据,

下图为运行的结果。
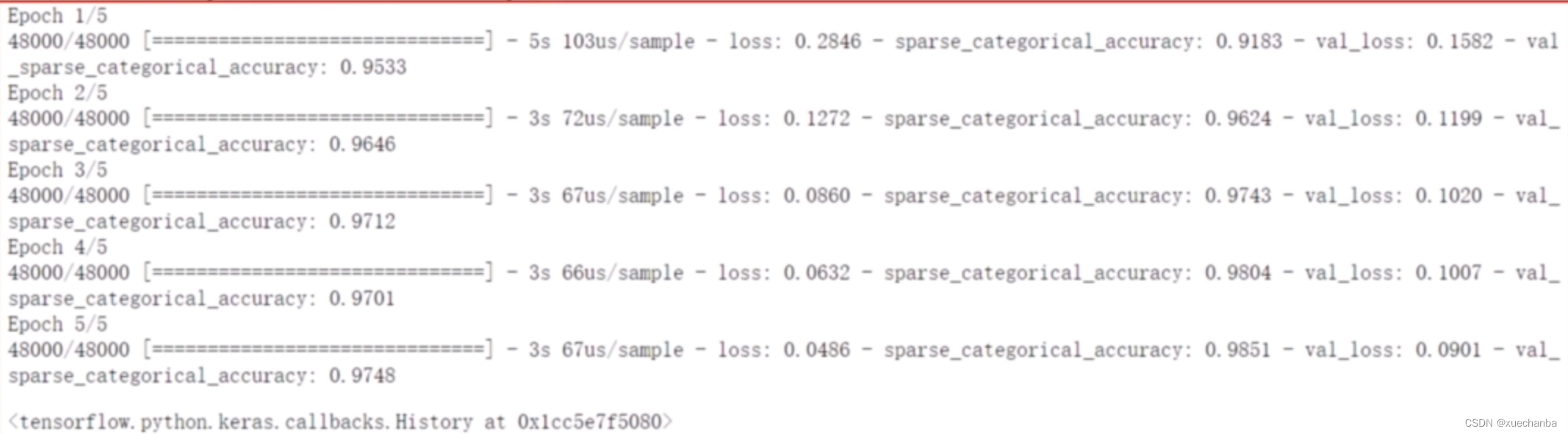
在这个例子中,我们没有设置测试频率,因此测试频率默认为1。也就是每训练完一轮就使用测试集计算和输出一次评测指标。
这里的评测指标就是上面在配置训练方法时使用 compile 指定的性能评价函数。
model.compile(loss, optimizer, metrics)
可以通过
model.metrics_names
来查看,可以看到第一项(损失函数项)输出的是 loss (没有具体的指明是哪种损失函数),第二项是准确率评价函数,是 sparse_categorical_accuracy。

fit 方法返回一个 History 对象,

在这个对象中,记录了在整个训练过程中性能指标的变换情况。例如,

然后,通过
type(history)
可以看到 history 的数据类型,

再来使用 History 对象的属性 history 来查看
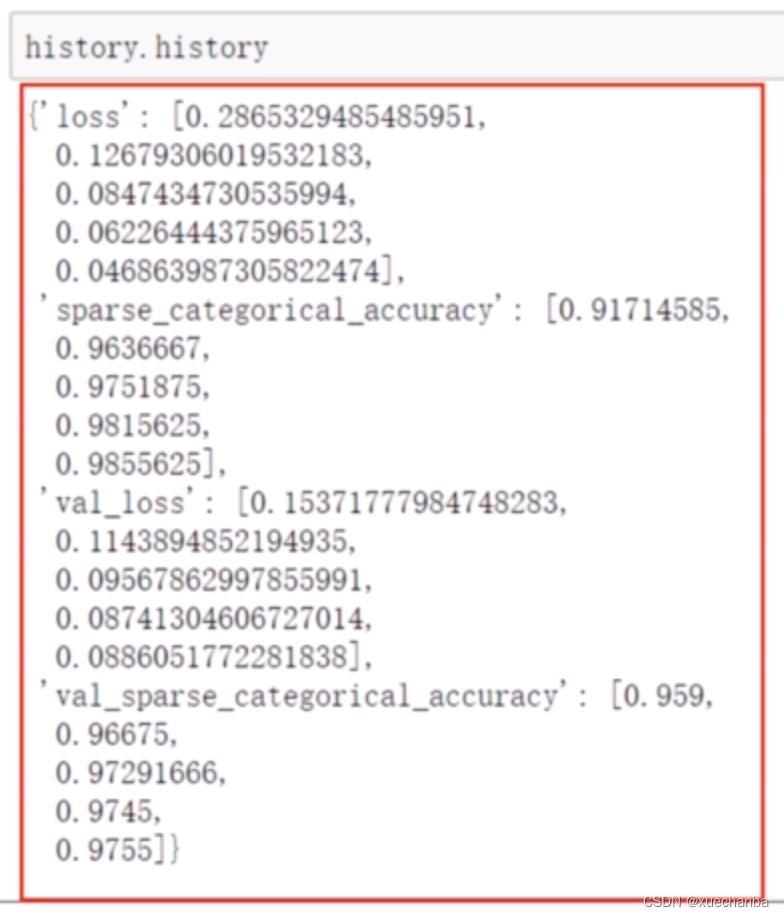
可以发现其返回值是一个字典,有四个字典元素,关键字分别是 ‘loss’、‘sparse_categorical_accuracy’、‘val_loss’ 以及 ‘val_sparse_categorical_accuracy’, 分别是训练集和测试集上的损失和准确率。每个关键字对应的值是一个列表,保存着各轮训练或测试的结果。
通过关键字还可以分别从字典中取出训练集和测试集的损失和准确率,

然后绘制折线图:

下图为绘制的结果:
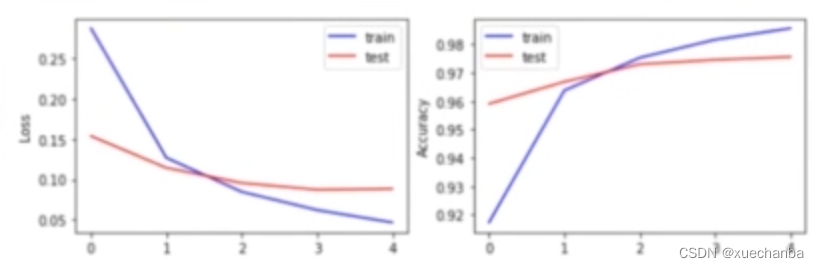
可以看出不管是训练集还是测试集,他们的损失都是逐步下降,准确率都是逐步上升。
如果,调整参数,将批量大小修改为 64 ,再将测试集比例删除(使用默认值 0.0)

这时,数据集中的全部 60000 条数据都被作为训练数据,显示结果如下:
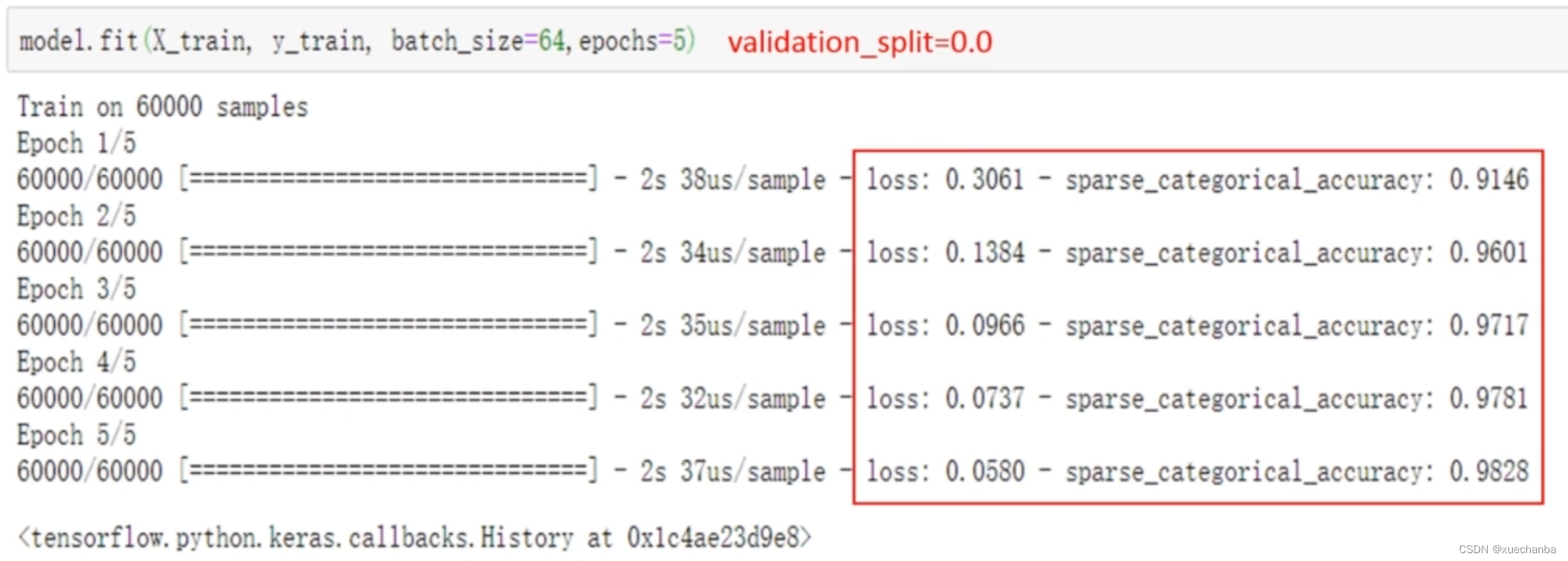
从图中,可以看出只有训练集的损失和准确率了。
可以发现,在改变了批量大小和测试集比例之后,模型的损失和准确率也相应发生了变化。
如果在训练模型时,没有划分测试数据,可以在模型训练结束之后,使用 evaluate 方法来评估模型的性能。

其中,test_set_x 和 test_set_y 用来提供测试数据的属性和标签值,而 batch_size 是批量的大小,默认值为32。verbose 是用来控制输出信息显示的方式,取值如下:
实际上,在我们下载的手写数字集 Mnist 中,本身就包含一个训练集和一个测试集。

现在可以使用下面语句来评估模型:
loss, acc = model.evaluate(X_test, y_test, verbose=2)
打印,输出结果:
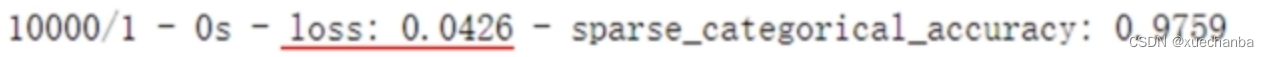
训练好模型之后,就可以使用模型来进行分类了。
通过 predict 方法可以使用模型进行分类
model.predict(x, batch_size, verbose)
这时只需要提供数据的属性值,就可以通过模型得到分类结果。当输入批量数据时,程序会根据 batch_size 的大小分批量的预测数据,这样比每次只预测一个样本更快。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b