在我们日常使用IDEA进行开发时,可能会遇到许多卡顿的瞬间,明明我们的机器配置也不低啊?为什么就会一直卡顿呢?
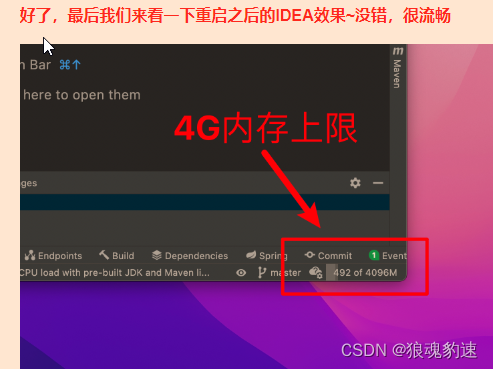
原来这是因为IDEA软件在我们安装的时候就设置了默认的内存使用上限(通常很小),这就是造成我们使用IDEA时卡顿的根本原因。比如我这台电脑,明明是16GB的运行内存,但是IDEA默认给我分配的使用上限是1GB,当我运行大量代码时自然而然的就会产生卡顿。我们可以通过显示内存使用情况来查看当前项目占用的内存大小。
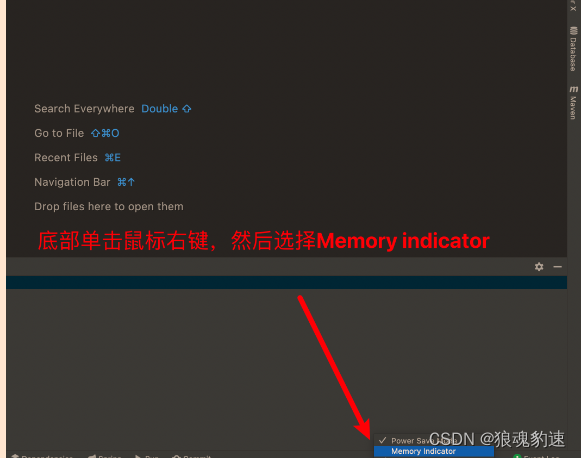
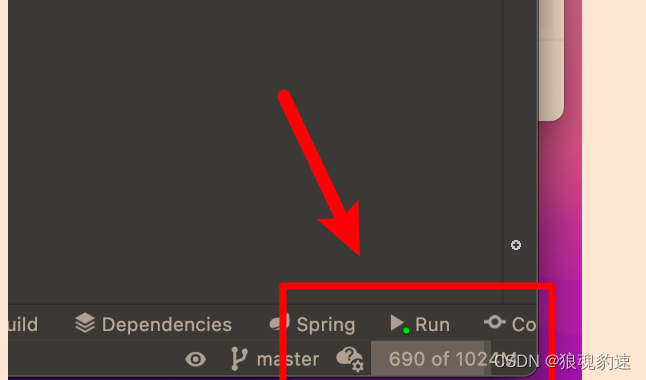
可以看到当前我的程序占用了690MB的内存,而上限是1024MB(在性能突发时完全承受不住)。我们可以通过进入IDEA的设置来更改这些配置。
具体步骤:(三步)
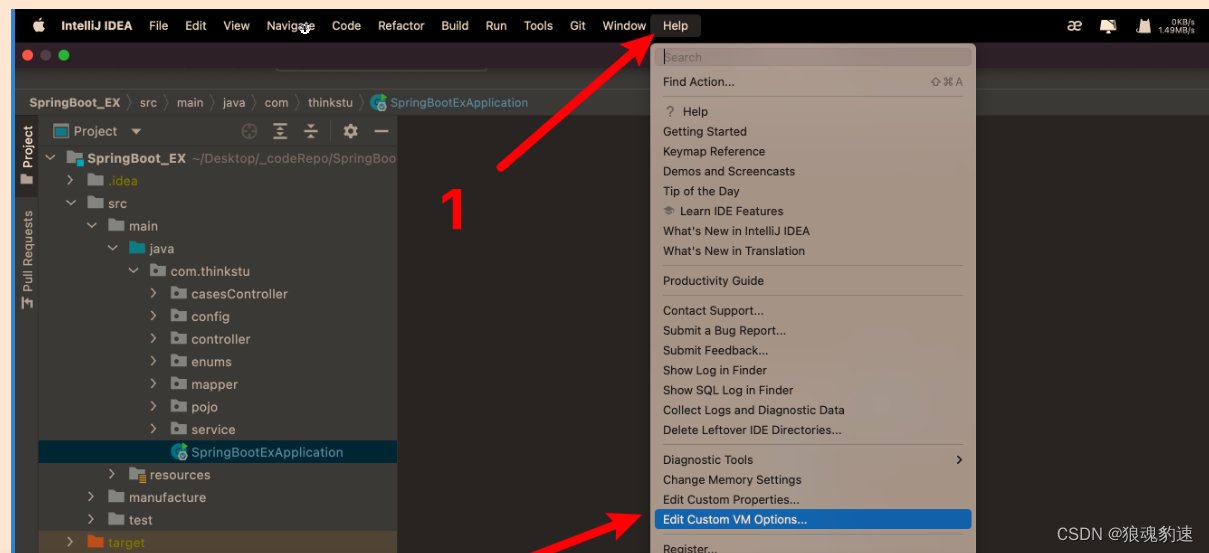
-Xmx1024m // 最大内存上限为:1024MB(1GB)
-Xms256m // 初始内存分配大小为:256MB
-XX:ReservedCodeCacheSize=128m //代码缓冲区大小:128MB
-XX:+UseG1GC
我们对其进行适当的修改(具体根据个人电脑配置),并保存文件:
我们对其进行适当的修改(具体根据个人电脑配置),并保存文件:
-Xmx4096m
-Xms4096m
-XX:ReservedCodeCacheSize=256m
-XX:+UseG1GC
3. 缓存清理(使新配置生效):
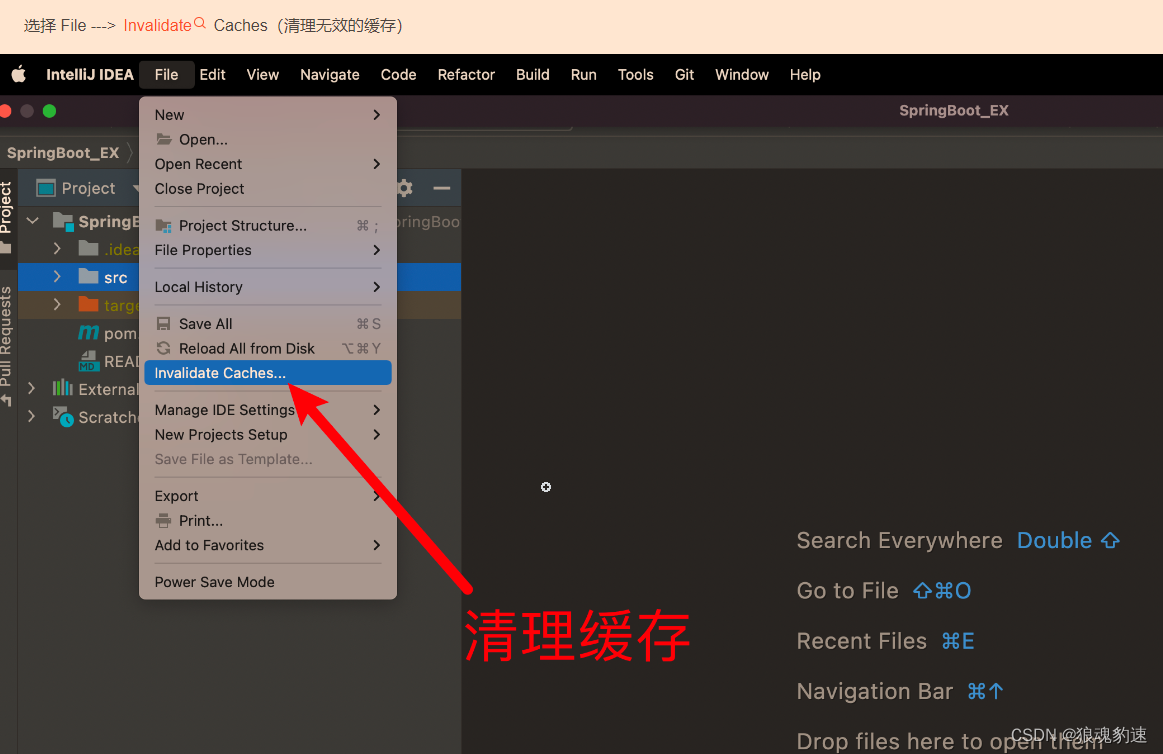
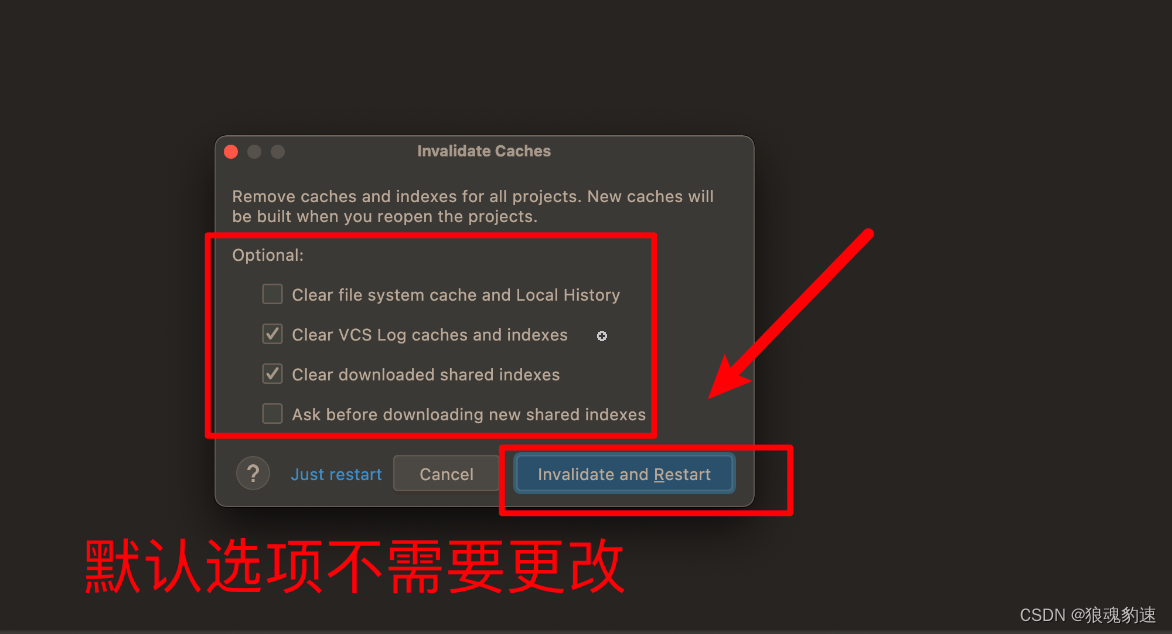
另外说一句,JetBrains系列的产品都可以通过这种设置来解决卡顿的问题。没错,包括PyCharm、Android Studio、WebStorm等,其余参数说明如下:
参数说明:
-server:一定要作为第一个参数,在多个CPU时性能佳
-Xms:初始Heap大小,使用的最小内存,cpu性能高时此值应设的大一些
-Xmx:java heap最大值,使用的最大内存
-XX:PermSize:设定内存的永久保存区域
-XX:MaxPermSize:设定最大内存的永久保存区域
-XX:MaxNewSize:
+XX:AggressiveHeap 使 Xms 失去意义。
-Xss:每个线程的Stack大小
-verbose:gc 现实垃圾收集信息
-Xloggc:gc.log 指定垃圾收集日志文件
-Xmn:young generation的heap大小,一般设置为Xmx的3、4分之一
-XX:+UseParNewGC :缩短minor收集的时间
-XX:+UseConcMarkSweepGC :缩短major收集的时间
提示:此选项在Heap Size 比较大而且Major收集时间较长的情况下使用更合适。
————————————————
参考 : https://blog.csdn.net/qq_35760825/article/details/123325533
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我想设置一个默认日期,例如实际日期,我该如何设置?还有如何在组合框中设置默认值顺便问一下,date_field_tag和date_field之间有什么区别? 最佳答案 试试这个:将默认日期作为第二个参数传递。youcorrectlysetthedefaultvalueofcomboboxasshowninyourquestion. 关于ruby-on-rails-date_field_tag,如何设置默认日期?[rails上的ruby],我们在StackOverflow上找到一个类似的问
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序