今天在训练模型的时候突然报了显存不够的问题,然后分析了一下,找到了解决的办法,这里记录一下,方便以后查阅。
注:以下的解决方案是在模型测试而不是模型训练时出现这个报错的!
RuntimeError: CUDA out of memory
完整的报错信息:
Traceback (most recent call last):
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/main.py", line 420, in <module>
main()
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/main.py", line 414, in main
train_with_cross_validate(training_epochs, kfolds, train_indices, eval_indices, X_train, Y_train, model, losser, optimizer)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/main.py", line 77, in train_with_cross_validate
val_probs = model(inputs)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 235, in forward
x = self.camlp_mixer(x) # (batch_size, F, C, L)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/container.py", line 139, in forward
input = module(input)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 202, in forward
x = self.time_mixing_unit(x)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 186, in forward
x = self.mixing_unit(x)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 147, in forward
x = self.activate(x)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/activation.py", line 772, in forward
return F.leaky_relu(input, self.negative_slope, self.inplace)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/functional.py", line 1633, in leaky_relu
result = torch._C._nn.leaky_relu(input, negative_slope)
RuntimeError: CUDA out of memory. Tried to allocate 2.49 GiB (GPU 0; 23.70 GiB total capacity; 21.49 GiB already allocated; 550.81 MiB free; 21.53 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
因为自己写的程序训练完成一轮会有输出,所以这些信息是在模型预测过程中发生的。
关键的报错信息:
RuntimeError: CUDA out of memory. Tried to allocate 2.49 GiB (GPU 0; 23.70 GiB total capacity; 21.49 GiB already allocated; 550.81 MiB free; 21.53 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
大体意思就是显存不够了。
通过下面的代码查看程序运行过程中显卡的状态:
nvidia-smi -l 1
模型加载完成后,此时的显卡状态:

模型训练过程中显卡的状态:

模型训练完成,开始模型预测阶段,并且是数据输入模型之后,紧接着出现如下的显卡状态,并且这个状态持续时间很短,在显示过程中,只有一次输出结果是这样的:

紧接着程序报错,显卡内存被释放,显卡的任务栏中,运行的程序也没有了:

然后,就感觉很奇怪,觉得是梯度的问题,因为在训练的时候很正常,然后模型预测就出现问题了,然后模型训练需要梯度信息,模型预测不需要梯度信息,就尝试着解决梯度的问题:
就是在模型训练代码的前面加入下面这句话:
with torch.no_grad():
更改后的代码如下所示:
with torch.no_grad():
# validation
model.eval()
inputs = x_eval.to(device)
val_probs = model(inputs)
val_acc = (val_probs.argmax(dim=1) == y_eval.to(device)).float().mean()
# print(f"Eval : Epoch : {iter} - kfold : {kfold+1} - acc: {val_acc:.4f}\n")
epoch_val_acc += val_acc
更改之后模型预测阶段显卡的状态如下所示:
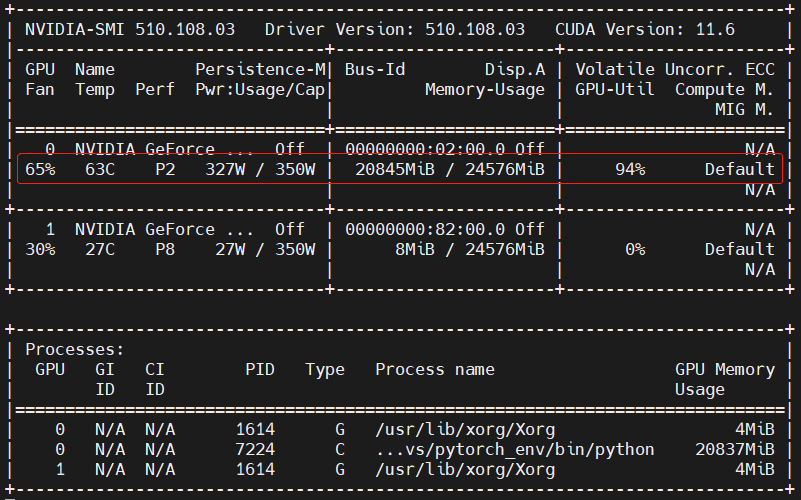
然后开始新一轮的训练过程,显卡的显存占用情况也没有再发生变化。
这样就不再报错了!!!
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
RuntimeError:CUDAerror:device-sideasserttriggered问题描述解决思路发现问题:总结问题描述当我在调试模型的时候,出现了如下的问题/opt/conda/conda-bld/pytorch_1656352465323/work/aten/src/ATen/native/cuda/IndexKernel.cu:91:operator():block:[5,0,0],thread:[63,0,0]Assertion`index>=-sizes[i]&&index通过提示信息可以知道是个数组越界的问题。但是如图一中第二行话所说这个问题可能并不出在提示的代码段
我尝试通过以下命令在我的计算机上安装gem(Mechanize):>>geminstallmechanize--platform=ruby>>geminstallmechanize错误ERROR:Errorinstallingmechanize:ERROR:Failedtobuildgemnativeextension."C:/ProgramFiles/Ruby200-x64/bin/ruby.exe"extconf.rbC:/ProgramFiles/Ruby200-x64/bin/ruby.exe:invalidswitchinRUBYOPT:-F(RuntimeError)在我尝
在我们的rails3.1.4应用程序中,rspec用于测试应用程序Controller中的公共(public)方法require_signin。这是require_signin方法:defrequire_signinif!signed_in?flash.now.alert="Loginfirst!"redirect_tosignin_pathendend这是rspec代码:it"shouldinvokerequire_signinforthosewithoutlogin"docontroller.send(:require_signin)controller{shouldredirec
我正在使用Ubuntu11.04在RubyonRails中开发一个应用程序。在应用程序中,我需要生成pdf文档。所以我正在使用wicked_pdf和wkhtmltopdf二进制gem。在我系统的开发环境中,一切正常。但是一旦我使用Phusion在CentOS5.6上部署应用程序乘客,当我尝试动态生成pdf时,出现以下错误:RuntimeError(wkhtmltopdf位置未知)我正在使用Ruby1.9.2.p136rails3.1.1任何帮助将不胜感激......谢谢。 最佳答案 另一种方法是通过Gemfile安装二进制文件。只需
我正在将开发中的应用程序从Rails4.2升级到Rails5beta1.1。应用程序在升级前运行良好。我已经完成了基本的升级步骤(更新Ruby、更新Rails和相关步骤:http://edgeguides.rubyonrails.org/upgrading_ruby_on_rails.html)。Gemfile也已更新为最新的Gems。当我运行$railsmiddleware或$railsconsole或$railsserver时,出现以下错误:Nosuchmiddlewaretoinsertafter:ActionDispatch::ParamsParser.../.rvm/gems
当我在Windows764位系统上运行bundleexecrspecspec/时,我收到以下错误:invalidswitchinRUBYOPT:-F(RuntimeError)我正在运行ruby1.9.2p136(2010-12-25)[i386-mingw32](安装在c:\ProgramFiles(x86)\Ruby192)和bundler1.0.15(作为rubygem安装).关于如何解决这个问题的任何线索?谢谢,本 最佳答案 Bundler不喜欢Ruby的路径包含空格这一事实。为了解决这个问题,我编辑了runtime
今天升级到Ruby-1.9.3-p392后,REXML在尝试检索超过一定大小的XML响应时抛出运行时错误-一切正常,当接收到25条以下的XML记录时不会抛出错误,但是一旦达到特定的XML响应长度阈值,我收到此错误:Erroroccurredwhileparsingrequestparameters.Contents:RuntimeError(entityexpansionhasgrowntoolarge):/.rvm/rubies/ruby-1.9.3-p392/lib/ruby/1.9.1/rexml/text.rb:387:in`blockinunnormalize'我意识到这在最
我是ruby的新手,我正在尝试执行规范,但收到此错误:RuntimeError: :jsonisnotregisteredonFaraday::Request我正在尝试使用这个gem:https://github.com/Chicago/windyMacOSX10.7.4Ruby1.9.3,使用RVM 最佳答案 我刚刚在升级Faraday时遇到了这个问题。json请求中间件在0.8中从Faraday中移除。它现在位于faraday_middlewaregem中。您应该geminstallfaraday_middl
我最近从v4.3升级到Rails5.1,现在在运行测试时遇到这个错误:Anerroroccurredwhileloading./spec/controllers/admin/capacity_charges_controller_spec.rb.Failure/Error:requireFile.expand_path('../../config/environment',__FILE__)RuntimeError:can'tmodifyfrozenArray我为每个测试文件都得到了它。触发错误的行来自rails_helper。我已经检查了Rails5.1示例repo协议(protoc