(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
随着人工智能的飞速发展,市场上推出了各式各样的智能设备,AI 语音的发展更是使得语音助手成为各大智能终端设备必不可少的软件。语音是人类与设备最直接的交互方式,不需要和实物接触,可远程操控,对于人们来说是最方便自然的交流方式。
自动语音识别(Automatic Speech Recognition, ASR)是一种将语音转化为文字的技术,是人与机器、人与人自然交流的关键技术之一。ASR 是人与智能设备交互的入口,它的功能就是让设备”听懂“人类的语言,从而能够根据识别到的内容去完成人类想要让它做的事情。
语音唤醒(Keyword Spotting, KWS)是语音识别的入口,如何高效、准确地对用户指令给出反应成为这一技术的最重要的目标。
下图是 IPhone 中 Siri 语音助手的交互示意图,总体上可分为以下三个步骤:
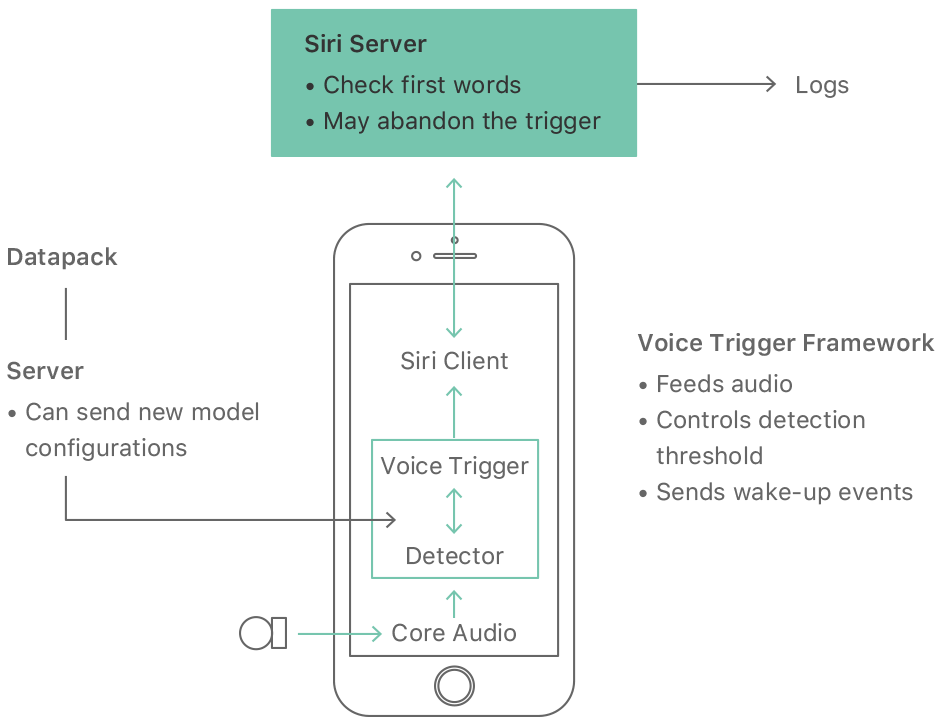

Apple 广告中 Siri 语音助手的交互演示视频。
点击播放
KWS、ASR 和声音检测的关系:
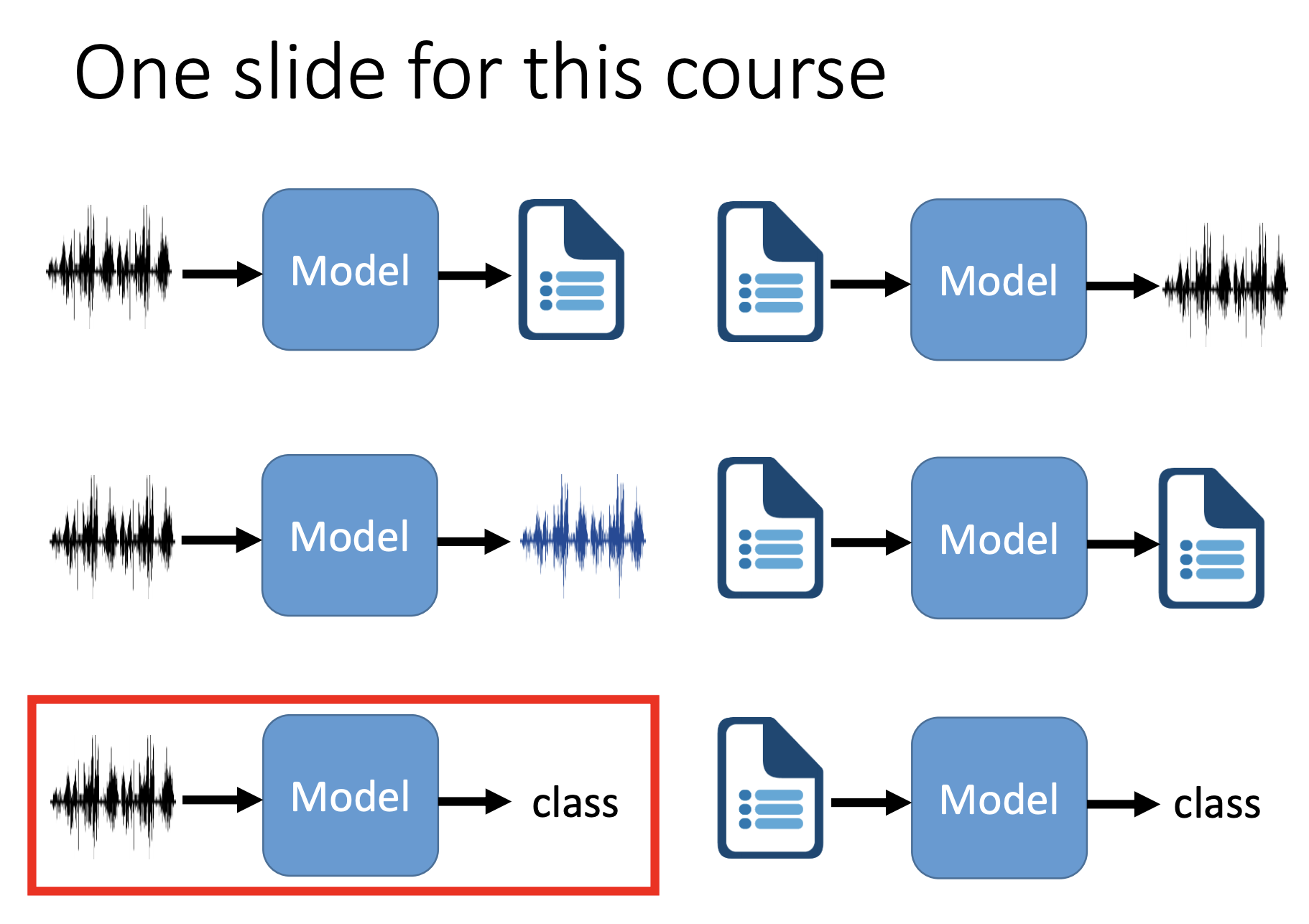
与语音识别 ASR 类似,KWS 可以用传统的 HMM 模型完成建模和识别,模型结构上是也是声学模型加解码器。
基于 HMM 的 KWS 模型和传统 ASR 模型的区别:

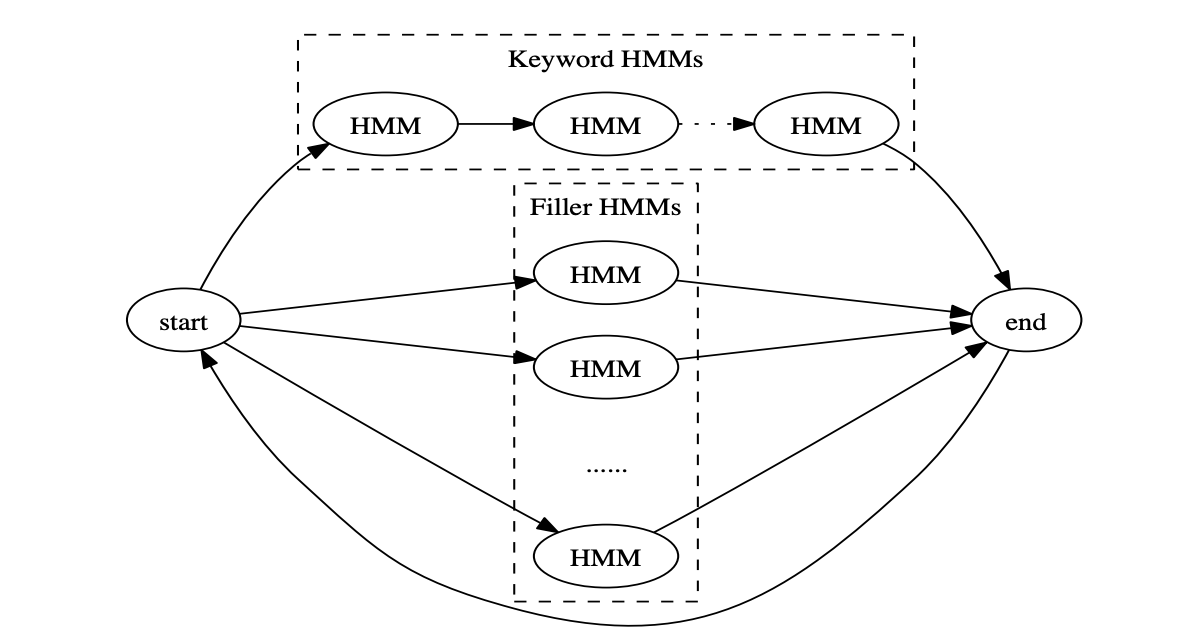
在 2014 年的文章 Small-footprint keyword spotting using deep neural networks 中,作者提出了一种基于神经网络加后验概率平滑的 KWS 方法,该方法利用词粒度来建模声学模型,可分为以下四个执行步骤:



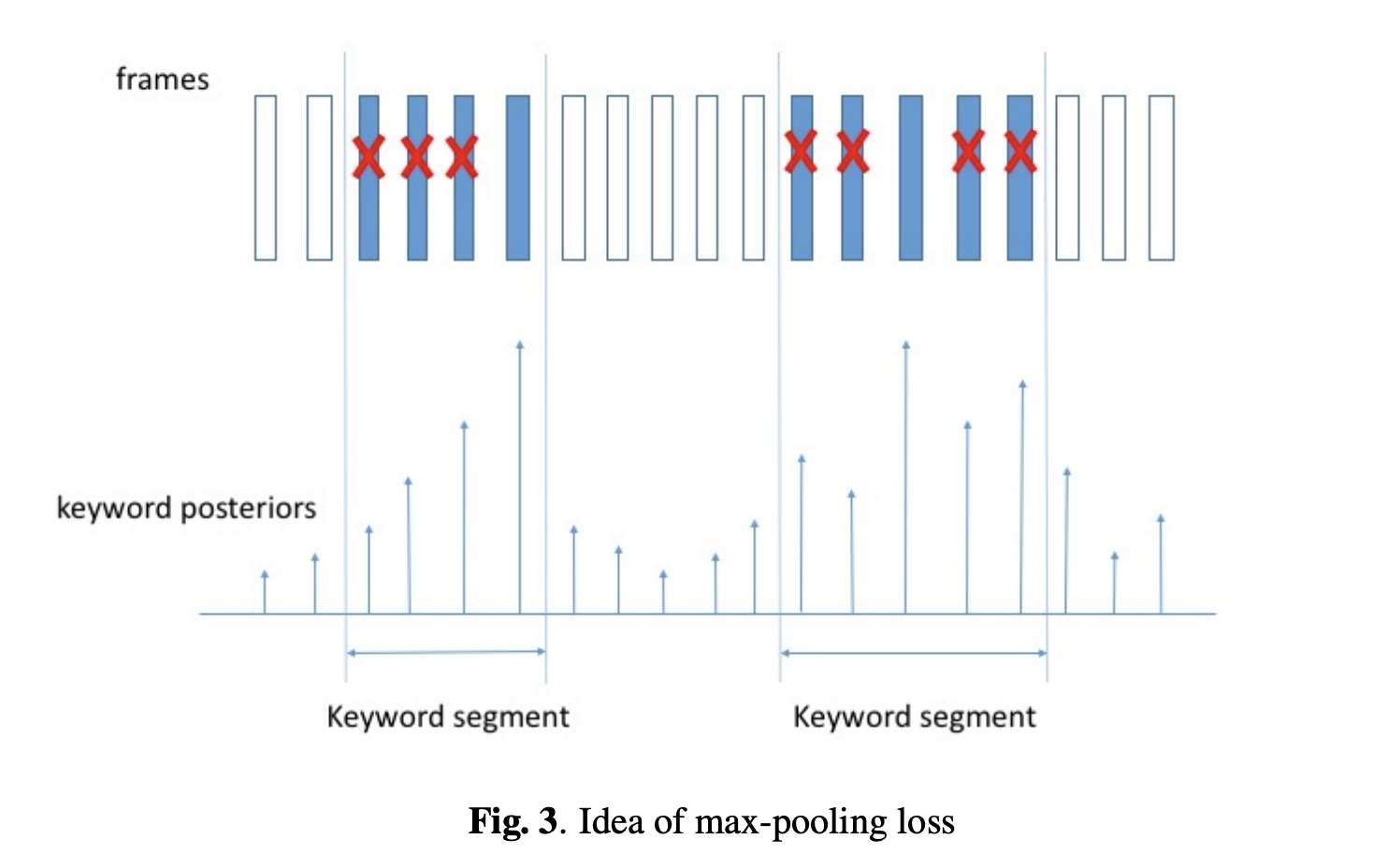
在 2017 年的文章 Max-Pooling Loss Training of Long Short-Term Memory Networks for Small-Footprint Keyword Spotting 中,作者提出了一种基于 Max-Pooling Loss 的 KWS 模型训练方法。
这种方法可以看作是从帧级别的训练方式转向段级别的训练方式,如下图所示,蓝色填充的帧是唤醒词,在训练阶段,模型对于唤醒词片段的得分取决于某一帧中的最高的得分;而非唤醒词片段,为了保证所有帧的得分都足够低,则需要关注所有的帧。这种得分可以看作是基于声学得分的 Max-Pooling。
有了这个训练方式,我们直接地对唤醒词进行端到端的建模,具体模型可以采取 RNN-based、CNN-based 和 Attention-based 可对音频特征序列建模的模型。PaddleSpeech 中的 examples/hey_snips 采用了
Multi-scale Dilated Temporal Convolutional 模型,通过 Max-Pooling Loss 的训练方法实现了在 Snips 数据集上的训练和评估。
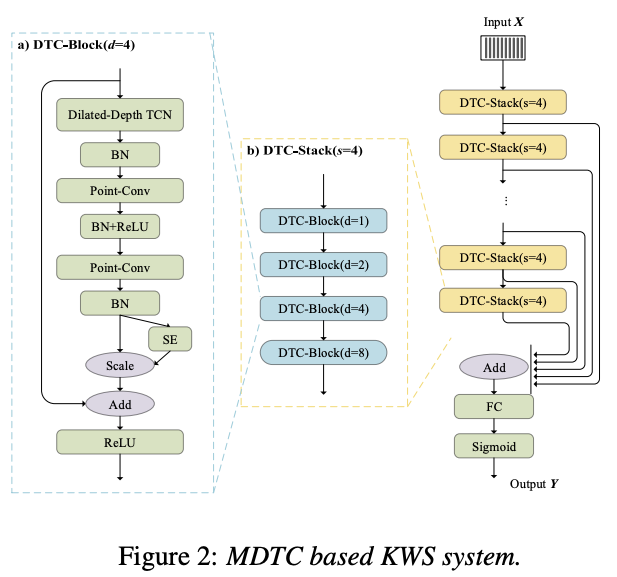
PaddleSpeech 提供了 MDTC 模型在 Snips 数据集上的从训练到评估的全流程脚本,在此章节中将对一些重要步骤做讲解,如需完整执行训练和评估,可以根据 example 中的文档提示运行脚本,详情请参考:examples/hey_snips/kws0
下载 PaddleSpeech 代码并安装所需依赖:
本教程要求paddlepaddle >= 2.2.2的环境,并需要 Clone PaddleSpeech Repo的代码(因网络访问问题可能需要等待较长时间,此处直接提供 PaddleSpeech r1.0 分支的代码压缩包):
!unzip work/PaddleSpeech-r1.0.zip
额外依赖:
!pip install scipy resampy soundfile tqdm colorlog pathos dtaidistance sklearn yacs loguru matplotlib
进入 example 目录:
%cd PaddleSpeech-r1.0/examples/hey_snips/kws0/
Snips 数据集需要用户自行申请下载:keyword-spotting-research-datasets
该数据集包含不同英语口音的约 11,000 “Hey Sinips” 的关键词的音频和 86,500(约96小时) 的其他发音的负样本。正负样本的音频均在相同的说话人、录音设备和环境噪音等条件下录制的,防止模型在训练的过程中关注非关键词相关的特征。数据集的切分和具体数量由下表所示:
| Train | Dev | Test | ||
|---|---|---|---|---|
| Positive | Utterances | 5,876 | 2,504 | 25,88 |
| Speakers | 1,179 | 516 | 520 | |
| max / speaker | 10 | 10 | 10 | |
| Negative | Utterances | 45,344 | 20,321 | 20,821 |
| Speakers | 3,330 | 1,474 | 1,469 | |
| max / speaker | 30 | 30 | 30 |
数据集下载完成后,解压至/PATH/TO/DATA/hey_snips_research_6k_en_train_eval_clean_ter目录。
修改conf/mdtc.yaml中的data_dir为'/PATH/TO/DATA/hey_snips_research_6k_en_train_eval_clean_ter' ,只想数据集目录,配置CUDA_VISIBLE_DEVICES启动 CPU/单卡/多卡训练。
CUDA_VISIBLE_DEVICES=0,1 ./run.sh conf/mdtc.yaml
针对使用场景和训练样本不均衡问题,通常对 KWS 模型通常关注 False Reject 和 False Alarm 指标。在测试集中,通过对不同的唤醒得分阈值下,对模型的指标进行考察。得到每个阈值的样本判别结果后,可以绘制 DET(Detection Error Tradeoff) 曲线:
在此 example 中,我们考察模型在 False Reject 为每小时1次的前提下,False Alarm 的情况,该数值越小则表示模型越好。在下图的结果中,可以确定唤醒阈值为 0.83,此时的 False Alarm Rate为 0.003559(数据由 example 中训练后的模型得到,重新跑后可能会有细微不同):
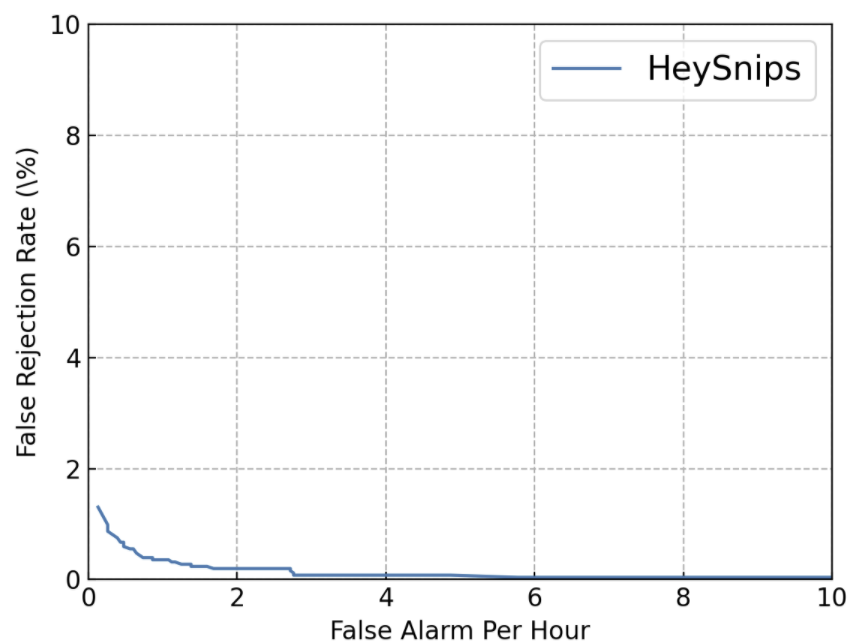
通过上述的训练后得到模型的 checkpoint,并确定了唤醒阈值为 0.83,在此通过正负样本两段音频的输入进行预测,感兴趣的朋友也可以尝试自己提供录音音频进行预测(采样率为 16000 的单通道 wave 文件)。
keyword.wav: 正样本,包含唤醒词 Hey Snips 的发音。non-keyword.wav: 负样本。import IPython
IPython.display.Audio('/home/aistudio/work/keyword.wav')
IPython.display.Audio('/home/aistudio/work/non-keyword.wav')
加载从上述训练过程中得到的模型参数文件,完成预测模型的加载。
加入 Python Package 的搜索路径。
import os
import sys
sys.path.insert(0, os.path.abspath('../../..'))
sys.path.insert(0, os.path.abspath('../../../audio'))
加载 MDTC 模型,模型结构的参数与 /examples/hey_snips/kws0/conf/mdtc.yaml 保持一致。
import paddle
from paddlespeech.kws.models import MDTC
from paddlespeech.kws.models.mdtc import KWSModel
# Model
backbone = MDTC(
stack_num=3,
stack_size=4,
in_channels=80,
res_channels=32,
kernel_size=5,
)
model = KWSModel(backbone=backbone, num_keywords=1)
kws_checkpoint = '/home/aistudio/work/kws.pdparams'
model.set_state_dict(paddle.load(kws_checkpoint))
model.eval()
通过对测试音频进行特征提取和模型前向计算,获取唤醒得分,并通过对比唤醒阈值得到判别结果。
特征提取的参数与 /examples/hey_snips/kws0/conf/mdtc.yaml 保持一致。
音频加载和特征计算:
import paddleaudio
from paddleaudio.compliance.kaldi import fbank
feat_func = lambda waveform, sr: fbank(
waveform=paddle.to_tensor(waveform).unsqueeze(0),
sr=sr,
frame_shift=10,
frame_length=25,
n_mels=80)
keyword_feat = feat_func(
*paddleaudio.load('/home/aistudio/work/keyword.wav'))
non_keyword_feat = feat_func(
*paddleaudio.load('/home/aistudio/work/non-keyword.wav'))
print(keyword_feat.shape, non_keyword_feat.shape)
获取音频的预测得分:
keyword_logits = model(keyword_feat.unsqueeze(0))
keyword_score = paddle.max(keyword_logits).numpy().item()
print(keyword_score)
non_keyword_logits = model(non_keyword_feat.unsqueeze(0))
non_keyword_score = paddle.max(non_keyword_logits).numpy().item()
print(non_keyword_score)
从阈值( 0.83)和音频的预测得分的比较重容易看出,keyword.wav 判别为唤醒,而 non-keyword.wav 为非唤醒。
[1] https://machinelearning.apple.com/research/hey-siri
[2] Chen, Guoguo et al. “Small-footprint keyword spotting using deep neural networks.” 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2014): 4087-4091.
[3] Wang, Zhiming et al. “Small-footprint Keyword Spotting Using Deep Neural Network and Connectionist Temporal Classifier.” ArXiv abs/1709.03665 (2017): n. pag.
[4] Coucke, Alice et al. “Efficient Keyword Spotting Using Dilated Convolutions and Gating.” ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2019): 6351-6355.
[5] Hou, Jingyong et al. “The NPU System for the 2020 Personalized Voice Trigger Challenge.” ArXiv abs/2102.13552 (2021): n. pag.
[6] Sun, Ming et al. “Max-pooling loss training of long short-term memory networks for small-footprint keyword spotting.” 2016 IEEE Spoken Language Technology Workshop (SLT) (2016): 474-480.
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
请关注我们的 Github Repo,非常欢迎加入以下微信群参与讨论:

P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
我刚刚看到whitehouse.gov正在使用drupal作为CMS和门户技术。drupal的优点之一似乎是很容易添加插件,而且编程最少,即重新发明轮子最少。这实际上正是Ruby-on-Rails的DRY理念。所以:drupal的缺点是什么?Rails或其他基于Ruby的技术有哪些不符合whitehouse.org(或其他CMS门户)门户技术的资格? 最佳答案 Whatarethedrawbacksofdrupal?对于Ruby和Rails,这确实是一个相当主观的问题。Drupal是一个可靠的内容管理选项,非常适合面向社区的站点。它
当音乐碰上区块链技术,会擦出怎样的火花?或许周杰伦已经给了我们答案。8月29日下午,B站独家首发周杰伦限定珍藏Demo独家访谈VCR,周杰伦在VCR里分享了《晴天》《青花瓷》《搁浅》《爱在西元前》四首经典歌曲Demo背后的创作故事,并首次公布18年前未发布的神秘作品《纽约地铁》的Demo。在VCR中,方文山和杰威尔音乐提及到“多亏了区块链技术,现在我们可以将这些Demos,变成独一无二具有收藏价值的艺术品,这些Demos可以在薄盒(国内数藏平台)上听到。”如何将音乐与区块链技术相结合,薄盒方面称:“薄盒作为区块链技术服务方,打破传统对于区块链技术只能作为数字收藏的理解。聚焦于区块链技术赋能,在
我感到有点困惑——大约24小时以来,我一直在考虑在我的项目中使用哪种组播技术。基本上,我需要的是:创建组(通过一些后端进程)任意客户端广播消息(1:N,N:N)(可能)直接消息(1:1)(重要)使用我自己的后端(例如,通过某种HTTPAPI)对客户端进行身份验证/授权能够通过后端进程(或服务器插件)踢出特定的客户端这是我要的:Ruby或Haxe中的后端相关流程JS+Haxe(Flash9)中的前端—在浏览器中,因此理想情况下通过80/443进行通信,但不一定。因此,这项技术必须能够在HaxeforFlash中轻松访问,最好是Ruby。我一直在考虑:RabbitMQ(或OpenAMQ)、
文章目录概述背景为何要存算分离优势**应用场景**存算分离产品技术流派华为JuiceFSHashDataXSKY概述背景Hadoop一出生就是奔存算一体设计,当时设计思想就是存储不动而计算(code也即是代码程序)动,负责调度Yarn会把计算任务尽量发到要处理数据所在的实例上,这也是与传统集中式存储最大的不同。为何当时Hadoop设计存算一体的耦合?要知道2006年服务器带宽只有100Mb/s~1Gb/s,但是HDD也即是磁盘吞吐量有50MB/s,这样带宽远远不够传输数据,网络瓶颈尤为明显,无奈之举只好把计算任务发到数据所在的位置。众观历史常言道天下分久必合合久必分,随着云计算技术的发展,数据
文章目录华为OD面试流程1.mysql数据库建了两个字段,且设置了联合索引,如果其中有一个字段为空会出现什么问题?2.谈谈springIOC的理解,有什么好处,解决了什么问题3.谈谈springAOP的理解,切面编程有没有实际应用,有哪些注解,作用是什么,有那些应用场景?4.Erika和zookeeper有了解过吗,作用是什么,主要解决了什么问题5.谈谈JDK、JRE、JVM的理解,区别是什么6.谈谈对泛型的理解7.JVM的组成华为OD面试流程机试:三道算法题,关于机试,橡皮擦已经准备好了各语言专栏,可以直接订阅。性格测试:机试技术一面(本专栏核心)技术二面(本专栏核心)主管面试定级定薪发of
解开谜团:深入探索ChatGPT的技术奇迹。ChatGpt无处不在,无论是在播客、博客、YouTube还是社交媒体上。当我注意到这项新技术如此受欢迎时,我决定试一试,我被震惊了!有很多关于ChatGpt及其魔力的博客,但在这篇博客中,我将深入探讨其内部技术及其工作原理!ChatGpt简介根据OpenAI,ChatGpt被描述为:“我们训练了一个名为ChatGpt的模型,它以对话方式进行交互。对话格式使ChatGpt可以回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求。ChatGPT是InstructGPT的兄弟模型,它经过训练可以按照提示中的说明进行操作并提供详细的响应。”OpenA
作为一个相当新的Rails开发人员,上周我第一次尝到了重构的滋味,我不得不重命名Controller和模型以更好地反射(reflect)我们正在使用的领域。我使用.NET多年,并认为Resharper之类的工具很容易重命名类。我想知道Rails界的人们如何缓解重构问题?我最感兴趣的是那些主要使用vim(或IDE以外的任何东西)的人。我最感兴趣的是:特定于rails的有效vim插件可能有助于流程内置的vim工具也可能有助于该过程我花了将近两个小时进行重构并希望提高效率,因此Rails专家的任何建议都会很棒。干杯。注意,我意识到这个问题类似于Whattoolsareavailablefor
BigData/CloudComputing:基于阿里云技术产品的人工智能与大数据/云计算/分布式引擎的综合应用案例目录来理解技术交互流程目录一、云计算网站建设:部署与发布网站建设:简单动态网站搭建云服务器管理维护云数据库管理与数据迁移云存储:对象存储管理与安全超大流量网站的负载均衡二、大数据MOOC网站日志分析搭建企业级数据分析平台基于LBS的热点店铺搜索基于机器学习PAI实现精细化营销基于机器学习的客户流失预警分析使用DataV制作实时销售数据可视化大屏使用MaxCompute进行数据质量核查使用Quick BI制作图形化报表使用时间序列分解模型预测商品销量三、云安全云平台使用安全云上服务