开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
RESTFUL特点包括:
1、每一个URI代表1种资源;
2、客户端使用GET、POST、PUT、DELETE4个表示操作方式的动词对服务端资源进行操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源;
3、通过操作资源的表现形式来操作资源;
4、资源的表现形式是XML或者HTML;
5、客户端与服务端之间的交互在请求之间是无状态的,从客户端到服务端的每个请求都必须包含理解请求所必需的信息。
官方网站:
https://www.elastic.co
中文社区:
https://elasticsearch.cn
官方参考文档:
https://www.elastic.co/guide/en/elasticsearch/reference/6.6/setup-configuration-memory.html
下载地址:
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/6.x/yum/6.6.0/
elasticsearch-6.6.0.rpm 存储nosql非关系型数据库
filebeat-6.6.0-x86_64.rpm 从nginx服务日志中读取数据并发送给redis
kibana-6.6.0-x86_64.rpm 以图形化方式展示
logstash-6.6.0.rpm 负责将redis缓存中的数据收集并提交给elasticsearch
redis负责缓存数据库
拓扑图如下:

前提环境:jdk-1.8.0

硬件要求:
主机 | IP | 内存 | 网络 |
node-1 | 192.168.8.1 | 4G | NAT |
node-2 | 192.168.8.2 | 2/4G | NAT |
node-3 | 192.168.8.3 | 2/4G | NAT |
安装elasticsearch:
[root@node-1 ~]# rpm -ivh /media/elk-6.6/elasticsearch-6.6.0.rpm elasticsearch目录和文件
/etc/elasticsearch/elasticsearch.yml #配置文件
/etc/elasticsearch/jvm.options #java虚拟机
/etc/init.d/elasticsearch #服务启动脚本
/etc/sysconfig/elasticsearch #elasticsearch服务变量
/usr/lib/sysctl.d/elasticsearch.conf #设置elasticsearch用户使用的内存大小
/usr/lib/systemd/system/elasticsearch.service #添加系统服务文件
/var/log/elasticsearch/elasticsearch.log #日志文件路径
修改配置文件:
[root@node-1 ~]# vim /etc/elasticsearch/elasticsearch.yml
node.name: node-1 #群集中本机节点名
path.data: /data/elasticsearch #数据目录
path.logs: /var/log/elasticsearch #日志目录
bootstrap.memory_lock: true #锁定内存,需要和/etc/elasticsearch/jvm.options关联
network.host: 192.168.8.1,127.0.0.1 #监听的ip地址
http.port: 9200 #端口号创建数据目录,并修改权限
[root@node-1 ~]# mkdir -p /data/elasticsearch
[root@node-1 ~]# chown -R elasticsearch.elasticsearch /data/elasticsearch/分配锁定内存:
实验环境一般默认就是1g,所以就不需要更改。
[root@node-1 ~]# vim /etc/elasticsearch/jvm.options
-Xms1g #分配最小内存
-Xmx1g #分配最大内存,官方推荐为物理内存的一半,但最大为32G修改锁定内存后,无法重启,解决方法如下
[root@node-1 ~]# systemctl edit elasticsearch
[Service]
LimitMEMLOCK=infinity
按键F2保存退出
[root@node-1 ~]# systemctl daemon-reload
[root@node-1 ~]# systemctl restart elasticsearch
启动后稍等一会,需要启动时间,查看端口打开就完成了。
[root@node-1 ~]# netstat -anpt | grep 9200
tcp6 0 0 192.168.8.1:9200 :::* LISTEN 105678/java
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 105678/java 查看主机
查看单主机

查看群集健康状态
http://192.168.8.1:9200/_cluster/health?pretty

查看整个群集状态信息
http://192.168.8.1:9200/_cluster/state?pretty

下载es-head插件
插件下载地址
https://github.com/mobz/elasticsearch-head
下载后,解压,复制crx目录下es-head.crx到桌面改名es-head.crx为es-head.crx.zip。
解压es-head.crx.zip到es-head.crx目录,把目录es-head.crx,上传到谷歌浏览器更多工具→扩展程序。

勾选开发者模式→加载已解压的扩展程序→选择刚解压的文件即可。

打开后修改左上角的IP为本机IP,连接成功即可图形化的显示集群状态,后面配置好集群后就可以查看整个集群的图形化状态。

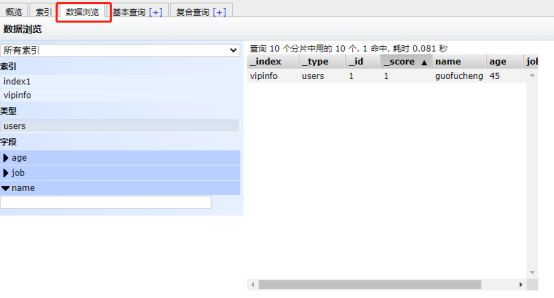
创建索引:vipinfo,类型:users,序号:1,数据部分:...
[root@node-1 ~]# curl -XPUT '192.168.8.1:9200/vipinfo/users/1?pretty&pretty' -H 'Content-Type: application/json' -d '{"name": "guofucheng","age": "45","job": "mingxing"}'选项说明:
XPUT 创建
XDELETE 删除
curl命令是个功能强大的网络工具,可用来模拟客户端请求,抓取网页、网络监控等。
curl常见用法
get请求:curl url
post请求:curl -d ‘xxx’ -X POST $url
proxy使用:curl -x ‘ http://127.0.0.1:8080’ $url :指定 HTTP 请求通过 http://127.0.0.1:8080
具体参数
-H: “Content-type: application/json” 添加 HTTP 请求头 curl -H 'Content-type: application/json' $url
-G: 把data数据当成get请求的参数发送,用来构造 URL 的查询字符串,与–data-urlencode结合使用
-X:指定 HTTP 请求的方法 curl -X POST $url
-d: 发送post请求数据,@file表示来自于文件
--data-urlencode:发送post请求数据,会对内容进行url编码
-u: username:password用户认证
-o: 写文件,将服务器的响应保存成文件
-v: verbose,打印更详细日志
-s, --silent: 关闭一些提示输出,不输出错误和进度信息。
-S:只输出错误信息
-k:使用SSL时允许不安全的服务器连接
-L:跟随跳转链接
YAML 是一种较为人性化的数据序列化语言,可以配合目前大多数编程语言使用。
YAML的语法比较简洁直观,特点是使用空格来表达层次结构,其最大优势在于数据结构方面的表达,所以 YAML 更多应用于编写配置文件,其文件一般以 .yml 为后缀。
一、 json与xml的相同点
1. json与xml是一种远程数据传输交换格式。
2. json是轻量级的,xml标记电子文件具有结构性的语言。
二、json与xml的不同点
1.xml缺点:xml是远程数据传输,交换格式数据庞大,比较占宽带,解析异常复杂,不易于维护,同时在不同服务器中的解析格式不同,造成大量数据重复。
2. json优点:因为文件格式压缩,格式简单,占宽带小,易于维护
XML和JSON都使用结构化方法来标记数据,下面来做一个简单的比较。
XML
用XML表示中国部分省市数据如下:
<?xml version="1.0" encoding="utf-8"?>
<country>
<name>中国</name>
<province>
<name>黑龙江</name>
<cities>
<city>哈尔滨</city>
<city>大庆</city>
</cities>
</province>
<province>
<name>广东</name>
<cities>
<city>广州</city>
<city>深圳</city>
<city>珠海</city>
</cities>
</province>
<province>
<name>台湾</name>
<cities>
<city>台北</city>
<city>高雄</city>
</cities>
</province>
<province>
<name>新疆</name>
<cities>
<city>乌鲁木齐</city>
</cities>
</province>
</country>JSON
{
"name": "中国",
"province": [{
"name": "黑龙江",
"cities": {
"city": ["哈尔滨", "大庆"]
}
}, {
"name": "广东",
"cities": {
"city": ["广州", "深圳", "珠海"]
}
}, {
"name": "台湾",
"cities": {
"city": ["台北", "高雄"]
}
}, {
"name": "新疆",
"cities": {
"city": ["乌鲁木齐"]
}
}]
}如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
我正在使用此代码在我的Sinatra应用程序中启用日志记录:log_file=File.new('my_log_file.log',"a")$stdout.reopen(log_file)$stderr.reopen(log_file)$stdout.sync=true$stderr.sync=true实际的日志记录是使用:logger.debug("Startingcall.Params=#{params.inspect}")事实证明,只有INFO或更高级别的日志消息被记录,而DEBUG消息没有被记录。我正在寻找一种将日志级别设置为DEBUG的方法。 最佳
我有这段代码来跟踪远程日志文件:defdo_tail(session,file)session.open_channeldo|channel|channel.on_datado|ch,data|puts"[#{file}]->#{data}"endchannel.exec"tail-f#{file}"endNet::SSH.start("host","user",:password=>"passwd")do|session|do_tailsession,"/path_to_log/file.log"session.loop我只想在file.log中检索带有ERROR字符串的行,我正在尝
当我为Daemons(1.1.0)gem设置日志记录参数时,我将如何实现与此行类似的行为?logger=Logger.new('foo.log',10,1024000)守护进程选项:options={:ARGV=>['start'],:dir_mode=>:normal,:dir=>log_dir,:multiple=>false,:ontop=>false:mode=>:exec,:backtrace=>true,:log_output=>true} 最佳答案 不幸的是,Daemonsgem不使用Logger。它将STDOUT和S
在Rails3.x应用程序中,我正在使用net::ssh并向远程pc运行一些命令。我想向用户的浏览器显示实时日志。比如,如果两个命令在net中运行::ssh执行即echo"Hello",echo"Bye"被传递然后"Hello"应该在执行后立即显示在浏览器中。这是代码我在rubyonrails应用程序中使用ssh连接和运行命令Net::SSH.start(@servers['local'],@machine_name,:password=>@machine_pwd,:timeout=>30)do|ssh|ssh.open_channeldo|channel|channel.requ
我正在构建一个应该输出日志文件的rubygem。将日志文件存储在哪里是一个好习惯?我正在从我正在构建的Rails网站中提取此功能,我可以在那里简单地登录到log/目录。 最佳答案 理想情况下,使路径可配置(.rc文件、交换机、rails/rack配置等)。如果它是一个Rack中间件,添加在构造函数的参数中指定它的可能性。如果没有提供日志路径,回退到检测日志目录。(我依稀记得它是Rails中的config.paths['log'],但如果可以的话,请确保config在你的gem中使用之前确实指向某些东西在Rails之外使用。)如果