跨域问题是前后端分离项目中非常常见的一个问题,举例来说,编程猫(codingmore)学习网站的前端服务跑在 8080 端口下,后端服务跑在 9002 端口下,那么前端在请求后端接口的时候就会出现跨域问题。
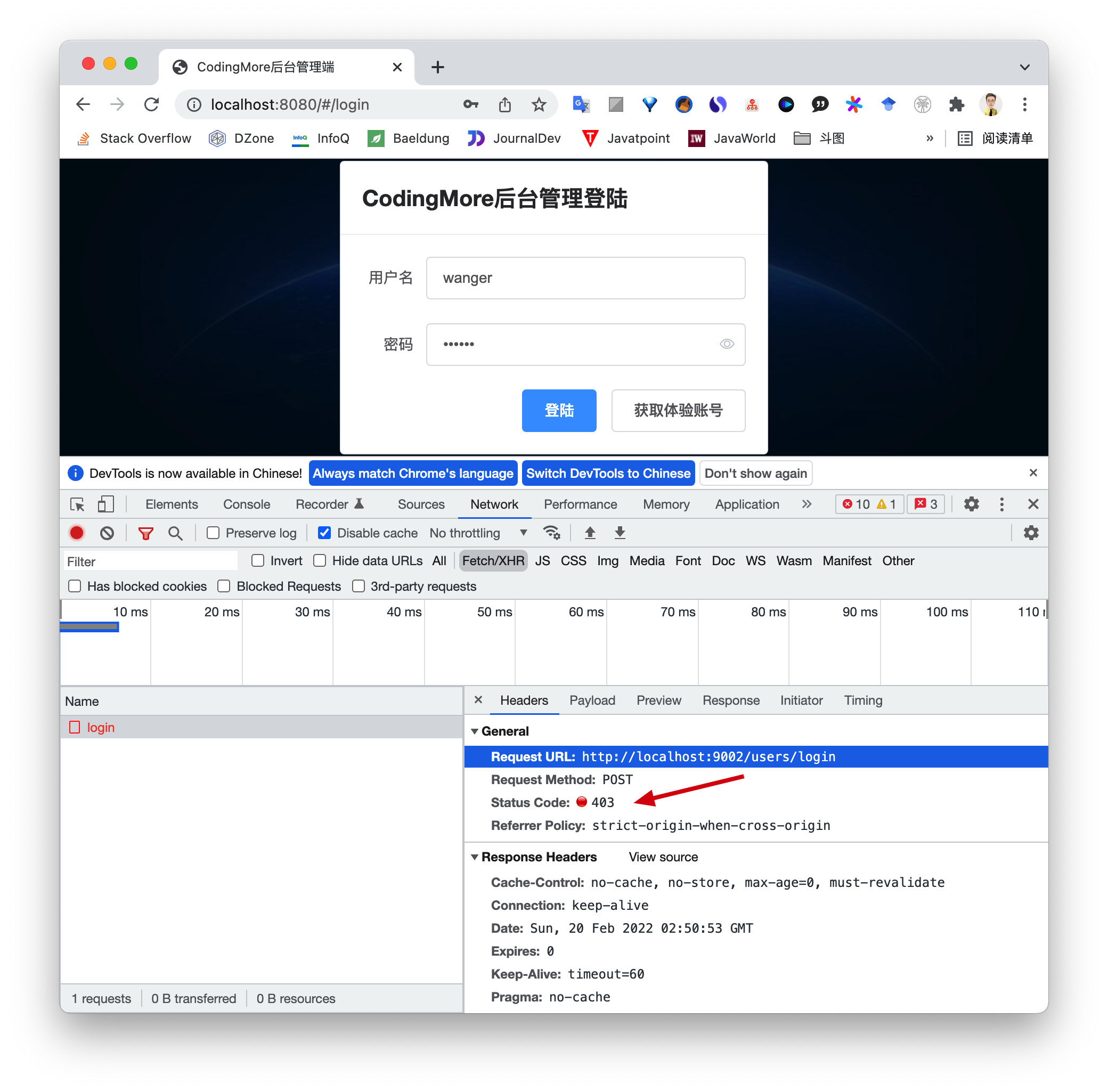
403 Forbidden 是HTTP协议中的一个状态码(Status Code),意味着后端服务虽然成功解析了请求,但前端却没有访问该资源的权限。
那怎么解决这个问题呢?通常有两个思路:
跨域对于前后端开发者来说,就像一块狗皮膏药,无论是面试还是开发中,都会经常遇到。
之所以出现跨域问题,是因为浏览器的同源策略,为了隔离潜在的恶意文件,为了防御来自歪门邪道的攻击,浏览器限制了从同一个源加载的文档或脚本与来自另一个源的资源进行交互。
前面我们提到了,前端跑在 8080 端口下,后端跑在 9002 端口下,这种情况就属于不同的源(域名不同,协议不同,端口不同),所以 8080 端口下的前端请求直接访问 9002 端口下的后端接口时就访问失败了。
那正确的打开方式是什么呢?我们前面也提到了,前端使用 Nodejs 代理或者后端开启跨域资源共享,我们一一来实践下。

在 Nodejs 出现之前,JavaScript 编写的程序通常需要在用户的浏览器上执行,Node.js 出现后,JavaScript 也能用于服务端编程了。Nodejs 一系列的内置模块使得程序可以脱离 IIS、Apache 这种 Web 服务作为独立的服务器执行。
我们使用 Nodejs 来解决跨域问题的思路就是,在本地创建一个虚拟服务器,对 8080 端口下的前端请求进行代理,同时接收 9002 端口下的服务器端响应,这样服务端和服务端进行数据的交互就不会出现跨域问题了。
第一步,配置 Nodejs 代理服务
module.exports = {
dev: {
// Paths
assetsSubDirectory: 'static',
assetsPublicPath: '/',
proxyTable: {
'/api': {
target: 'http://localhost:9002', // 你请求的第三方接口
changeOrigin: false, // 在本地会创建一个虚拟服务端,然后发送请求的数据,并同时接收请求的数据,这样服务端和服务端进行数据的交互就不会有跨域问题
pathRewrite: { // 路径重写,
'^/api': '' // 替换target中的请求地址,也就是说以后你在请求http://api.codingmore.top/v2/XXXXX这个地址的时候直接写成/api即可。
}
},
},
}
第二步,配置前端访问请求路径
module.exports = merge(prodEnv, {
NODE_ENV: '"development"',
VUE_APP_BASE_API: '"/api"'
// VUE_APP_BASE_API: '"http://localhost:9002"'
})
第三步,重启前端服务
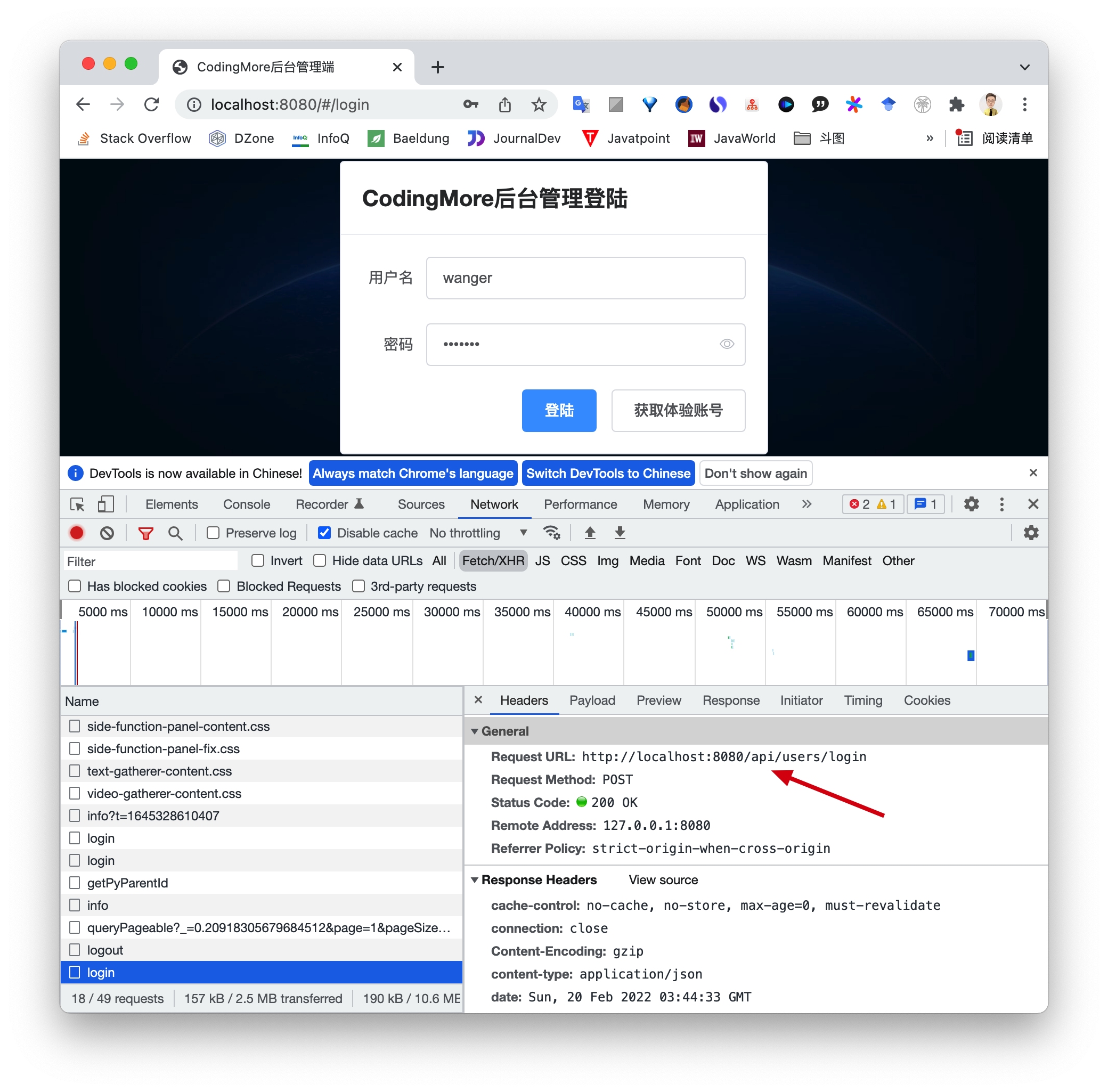
再次点击「登录」按钮,可以看到请求的 URL 发生了改变,原来是 http://localhost:9002/users/login,现在是 http://localhost:8080/api/users/login。与此同时,可以看到多了一个 Remote Address,端口也是 8080,也就是说经过 Nodejs 的代理,前后端的交互在同一个源下面了,这样就不会发生跨域问题了。
同时,可以看得到,服务器端返回的状态码变成了 200,表示请求成功。
跨域资源共享,也就是 Cross-Origin Resource Sharing,简拼为 CORS,是一种基于 HTTP 头信息的机制,通过允许服务器标识除了它自己以外的资源,从而实现跨域访问。
第一步,开启 CORS 支持
在 Spring Boot 应用中,加入 CORS 的支持简单到不忍直视,添加一个配置类就可以了。
@Configuration
public class GlobalCorsConfig {
@Bean
public CorsFilter corsFilter() {
CorsConfiguration config = new CorsConfiguration();
// 设置你要允许的网站域名
config.addAllowedOrigin("http://localhost:8080");
//允许跨域发送cookie
config.setAllowCredentials(true);
//放行全部原始头信息
config.addAllowedHeader("*");
//允许所有请求方法跨域调用
config.addAllowedMethod("*");
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**", config);
return new CorsFilter(source);
}
}
第二步,重启后端服务,再次点击登录按钮,发现请求已经可以正常访问了。

本例中,后端返回 Access-Control-Allow-Origin: http://localhost:8080 就表示,跑在 9002 端口下的后端接口可以被 8080 端口的前端请求访问。
如果允许所有域名进行跨域调用的话,只需改变一行代码即可。
//允许所有域名进行跨域调用
config.addAllowedOriginPattern("*");
// 设置你要允许的网站域名
// config.addAllowedOrigin("http://localhost:8080");
对于 login 这种简单的请求来说,它们是不会触发 CORS 预检的,因此不需要在服务器端增加其他配置就可以了。那什么是简单请求呢?
1)请求方法是以下三种方法之一:
2)HTTP 的头信息不超出以下几种字段:
application/x-www-form-urlencoded、multipart/form-data、text/plain那对于会触发 CORS 预检的非简单请求(比如说请求方法是 PUT 或 DELETE,或者 Content-Type 字段的类型是 application/json,或者请求消息头包含了一些自定义的字段),该怎么办呢?
非简单请求在正式通信之前,会增加一次 HTTP 查询请求,称为“预检”请求。预检请求通过后,才会返回正常的响应内容。

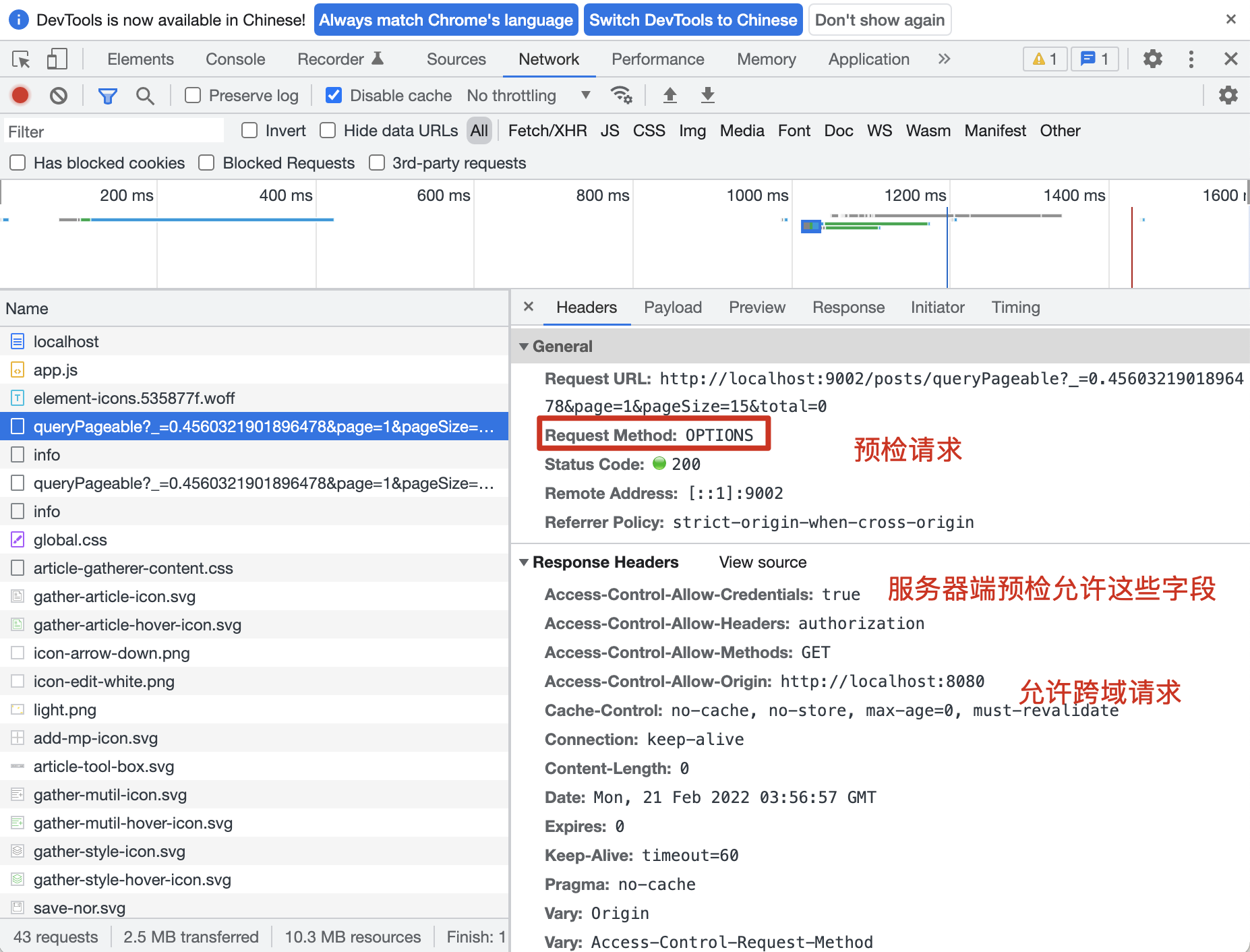
拿编程猫的文章管理页来举例,该页面会向后端发起一个 posts/queryPageable 的分页查询,该请求包含了一个自定义的消息头 Authorization,于是浏览器认为该请求是一个非简单请求,然后就会自动发起一次 OPTIONS 请求,但由于我们的 Spring Boot 项目整合了 SpringsScurity 安全管理框架,没有对OPTIONS请求放开登录认证,导致验证失败,文章分页请求的响应数据就没有返回回来。

第三步,通过以下代码给 OPTIONS 请求放行。
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity httpSecurity) throws Exception {
ExpressionUrlAuthorizationConfigurer<HttpSecurity>.ExpressionInterceptUrlRegistry registry = httpSecurity
.authorizeRequests();
//允许跨域请求的OPTIONS请求
registry.antMatchers(HttpMethod.OPTIONS)
.permitAll();
}
}
再次重启后端服务,重新访问文章列表接口,发现有响应数据了。

非简单请求必须首先使用 OPTIONS 请求方法发起一个预检请求到服务器端,以获知服务器是否允许该实际请求。"预检请求“的使用,避免了跨域请求对服务器的用户数据造成未预期的影响。
我们来通过两张图片简单总结一下预检请求的整个过程,第一张,发起 OPTIONS 预检请求:
第二章,发起正式请求:

编程猫后端源码:
编程猫后台管理的前端源码:
参考链接:
跨域:https://segmentfault.com/a/1190000015597029
CORS:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/CORS
阮一峰:https://www.ruanyifeng.com/blog/2016/04/cors.html
简单请求+预检请求:https://github.com/amandakelake/blog/issues/62
本篇已收录至 GitHub 上星标 1.6k+ star 的开源专栏《Java 程序员进阶之路》,据说每一个优秀的 Java 程序员都喜欢她,风趣幽默、通俗易懂。内容包括 Java 基础、Java 并发编程、Java 虚拟机、Java 企业级开发、Java 面试等核心知识点。学 Java,就认准 Java 程序员进阶之路😄。
https://github.com/itwanger/toBeBetterJavaer
star 了这个仓库就等于你拥有了成为了一名优秀 Java 工程师的潜力。也可以戳下面的链接跳转到《Java 程序员进阶之路》的官网网址,开始愉快的学习之旅吧。

没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack