黑马点评
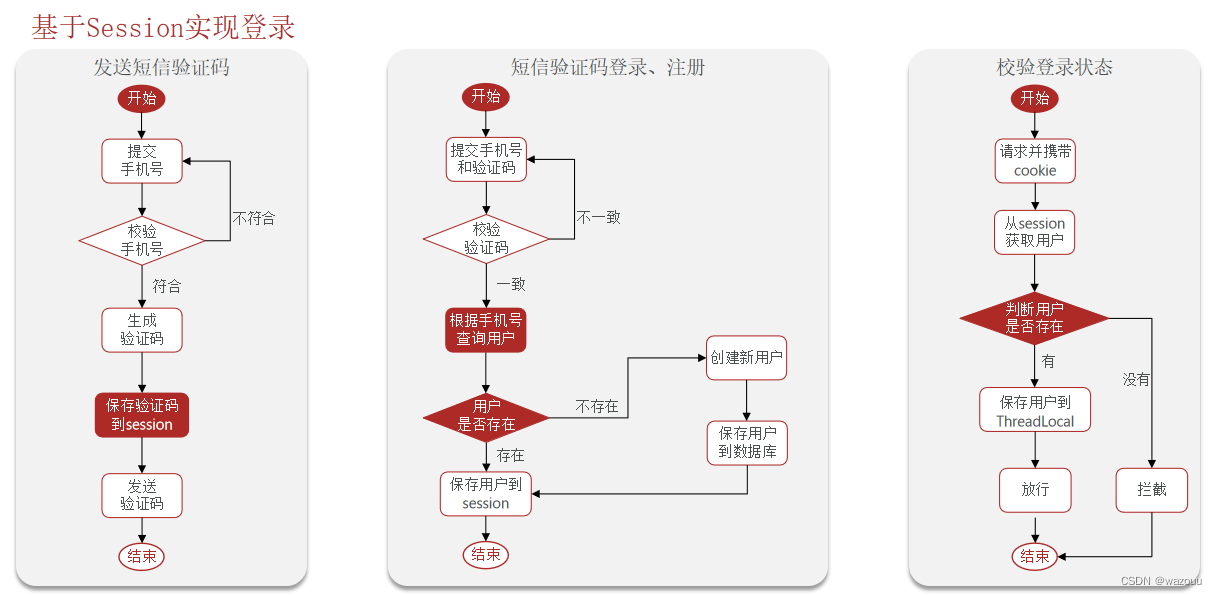
单体应用时用户的会话信息保存在session中,session存在于服务器端的内存中,由于前前后后用户只针对一个web服务器,所以没啥问题。但是一到了web服务器集群的环境下(我们一般都是用Nginx做负载均衡,若是使用了轮询等这种请求分配策略),就会导致用户小a在A服务器登录了,session存在于A服务器中,但是第二次请求被分配到了B服务器,由于B服务器中没有用户小a的session会话,导致用户小a还要再登陆一次,以此类推。这样用户体验很不好。当然解决办法也有很多种,比如同一个用户分配到同一个服务处理、使用cookie保持用户会话信息等。
因此,要解决这样的问题必须满足以下条件:
发送验证码:
/**
* 发送手机验证码
*/
@PostMapping("code")
public Result sendCode(@RequestParam("phone") String phone, HttpSession session) {
return userService.sendCode(phone,session);
}
@Override
public Result sendCode(String phone, HttpSession session) {
//1.校验手机号
if (RegexUtils.isPhoneInvalid(phone)) {
//2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
//3.符合则生成验证码
final String code = RandomUtil.randomNumbers(6);
//4.保存验证码到redis
stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY+phone,code,LOGIN_CODE_TTL, TimeUnit.MINUTES);
//5.发送验证码
log.debug("发送短信验证码成功,验证码:{}",code);
//6.返回null
return Result.ok();
}
验证登陆功能:
login方法会把生成的token返回给前端,浏览器会将其保存到session中。
/**
* 登录功能
* @param loginForm 登录参数,包含手机号、验证码;或者手机号、密码
*/
@PostMapping("/login")
public Result login(@RequestBody LoginFormDTO loginForm, HttpSession session){
return userService.login(loginForm,session);
}
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
//1.校验手机号
final String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)) {
//2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
//2.校验验证码,从redis中获取
final String cacheCode = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY+phone);
final String code = loginForm.getCode();
if(cacheCode==null||!cacheCode.equals(code)){
//3.不一直,报错
return Result.fail("验证码错误");
}
//4.一致,根据手机号查询用户
User user = query().eq("phone", phone).one();
//5.判断用户是否存在
if (user == null) {
//6.不存在,创建新用户并保存
user = createUserWithPhone(phone);
}
//7.保存用户信息到redis中
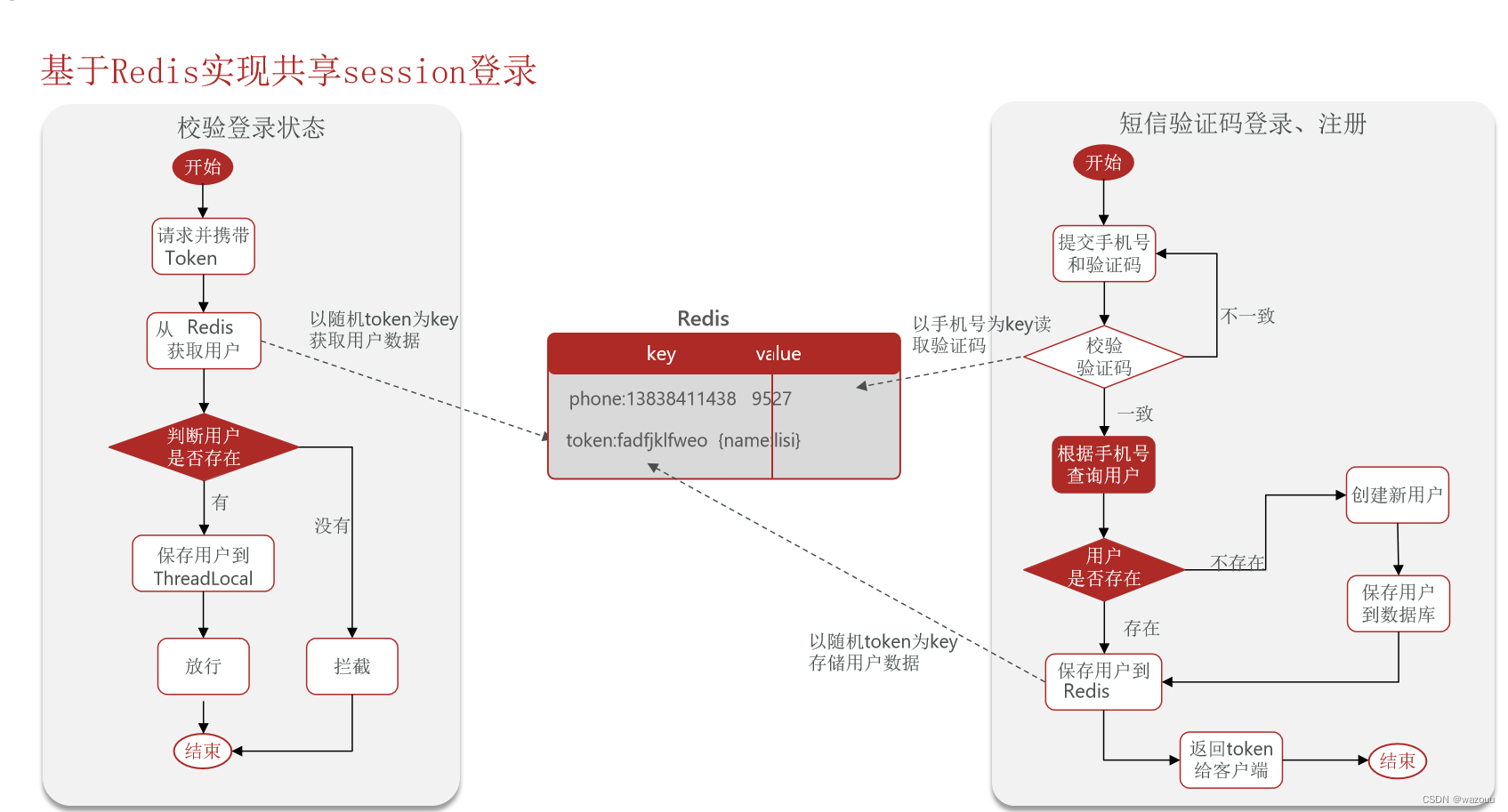
//7.1随机生成token,作为登陆令牌
String token = UUID.randomUUID().toString(true);
//7.2将User对象转为HashMap存储
UserDTO userDTO = BeanUtil.copyProperties(user,UserDTO.class);
final Map<String, Object> map = BeanUtil.beanToMap(userDTO, new HashMap<>(),
CopyOptions.create().setIgnoreNullValue(true).setFieldValueEditor((fieldName,fieldValue)->{
return fieldValue.toString();
})
);
//7.3存储
stringRedisTemplate.opsForHash().putAll(LOGIN_USER_KEY+token,map);
//7.4设置token有效期
stringRedisTemplate.expire(LOGIN_USER_KEY+token,3000,TimeUnit.MINUTES);
//8.返回token
return Result.ok(token);
}
private User createUserWithPhone(String phone) {
User user = new User();
user.setPhone(phone);
user.setNickName(USER_NICK_NAME_PREFIX+RandomUtil.randomString(5));
save(user);
return user;
}
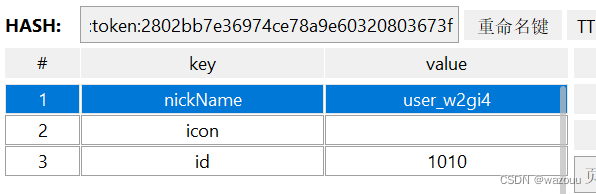
这里使用redis的hash结构存储user信息,原因是:
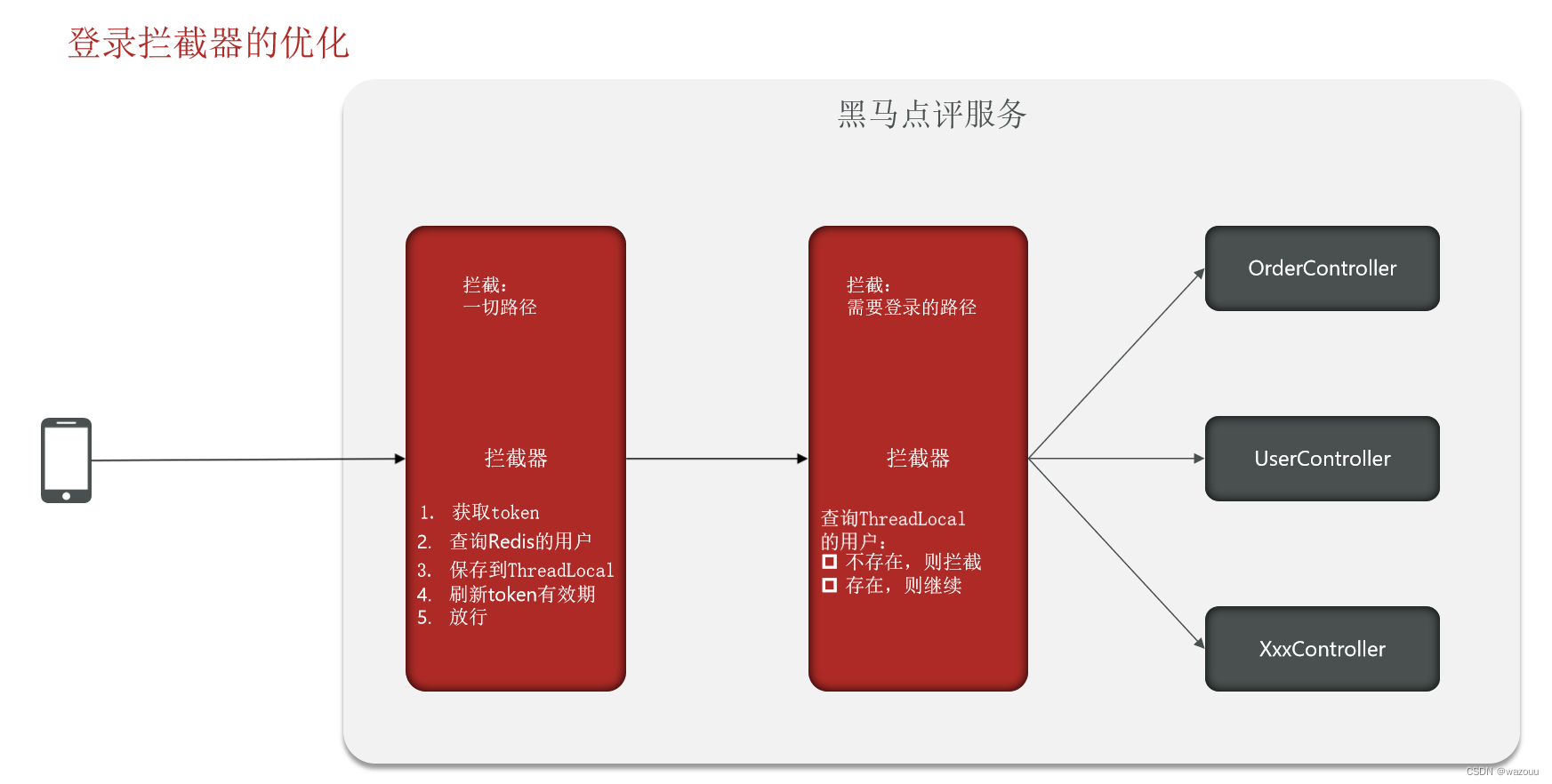
拦截器:
定义UserHolder工具类:
public class UserHolder {
private static final ThreadLocal<UserDTO> tl = new ThreadLocal<>();
public static void saveUser(UserDTO user){
tl.set(user);
}
public static UserDTO getUser(){
return tl.get();
}
public static void removeUser(){
tl.remove();
}
}
刷新token拦截器:
@Slf4j
public class RefreshTokenInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate){
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//1.获取请求头中的token
final String token = request.getHeader("authorization");
if (token == null) {
return true;
}
//2.获取redis中的用户
final Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(LOGIN_USER_KEY + token);
//3.判断用户是否存在
if (userMap.isEmpty()) {
return true;
}
//5.将查询到的Hash数据转换为UserDto对象
final UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
//6.存在,保存用户信息到ThreadLocal
UserHolder.saveUser(userDTO);
//7.刷新token有效期
stringRedisTemplate.expire(LOGIN_USER_KEY+token,3000, TimeUnit.MINUTES);
//8.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
UserHolder.removeUser();
}
}
登陆拦截器:
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//1.判断是否需要拦截(ThreadLocal中是否有用户)
if(UserHolder.getUser()==null){
response.setStatus(401);
return false;
}
//8.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
UserHolder.removeUser();
}
}
在配置类中配置拦截器:
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public void addInterceptors(InterceptorRegistry registry) {
//登陆拦截器
registry.addInterceptor(new LoginInterceptor()).excludePathPatterns(
"/user/code","/user/login","/blog/hot","/shop/**","/shop-type/**","/upload/**"
,"/voucher/**"
).order(1);
//token属性的拦截器
registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate)).addPathPatterns("/**").order(0);
}
}
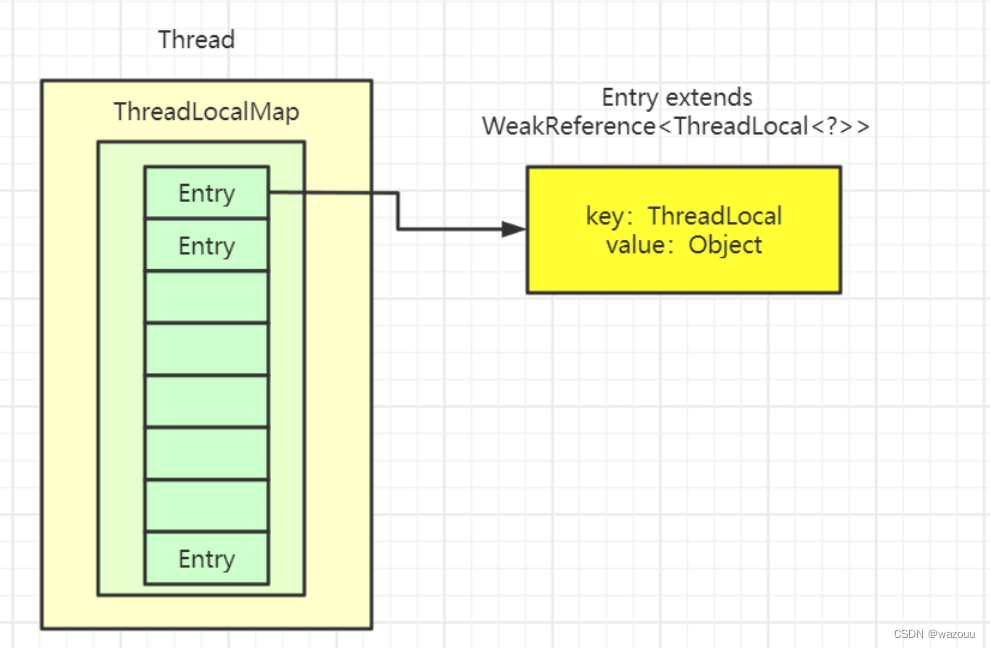
Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,也就是说每个线程有一个自己的ThreadLocalMap。
ThreadLocalMap有自己的独立实现,可以简单地将它的key视作ThreadLocal,value为代码中放入的值(实际上key并不是ThreadLocal本身,而是它的一个弱引用)。
每个线程在往ThreadLocal里放值的时候,都会往自己的ThreadLocalMap里存,读也是以ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
ThreadLocalMap有点类似HashMap的结构,只是HashMap是由数组+链表实现的,而ThreadLocalMap中并没有链表结构。
我们还要注意Entry, 它的key是ThreadLocal<?> k ,继承自WeakReference, 也就是我们常说的弱引用类型。
由于ThreadLocal的key是弱引用,故在gc时,key会被回收掉,但是value是强引用没有被回收,所以在我们拦截器的方法里必须手动remove()。

项目选择了主动更新策略,相对较好,主动更新又有以下三种方式:

选择在更新数据库的同时更新缓存。
操作缓存和数据库时有三个问题需要考虑:
若先删除缓存,再操作数据库:
请求1先把缓存中的A数据删除,请求2从db中读数据,请求1再把db中的A更新
若先操作数据库,再删除缓存:
请求1从db中读取数据A,请求2随后更新db中的数据(缓存中由于没有数据,所以不需要删除),最后请求1更新缓存。
可以看出两种方法都有各自的问题,但是由于写的时间要远大于读的时间,所以先操作db再删除cache的出现问题的几率非常小。
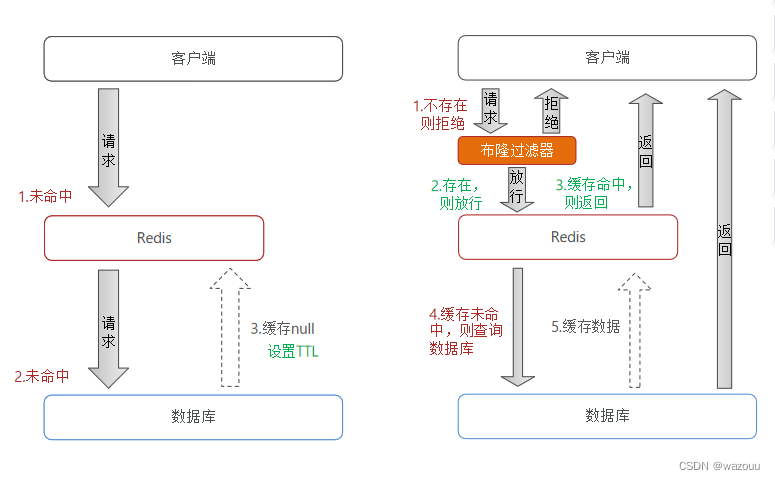
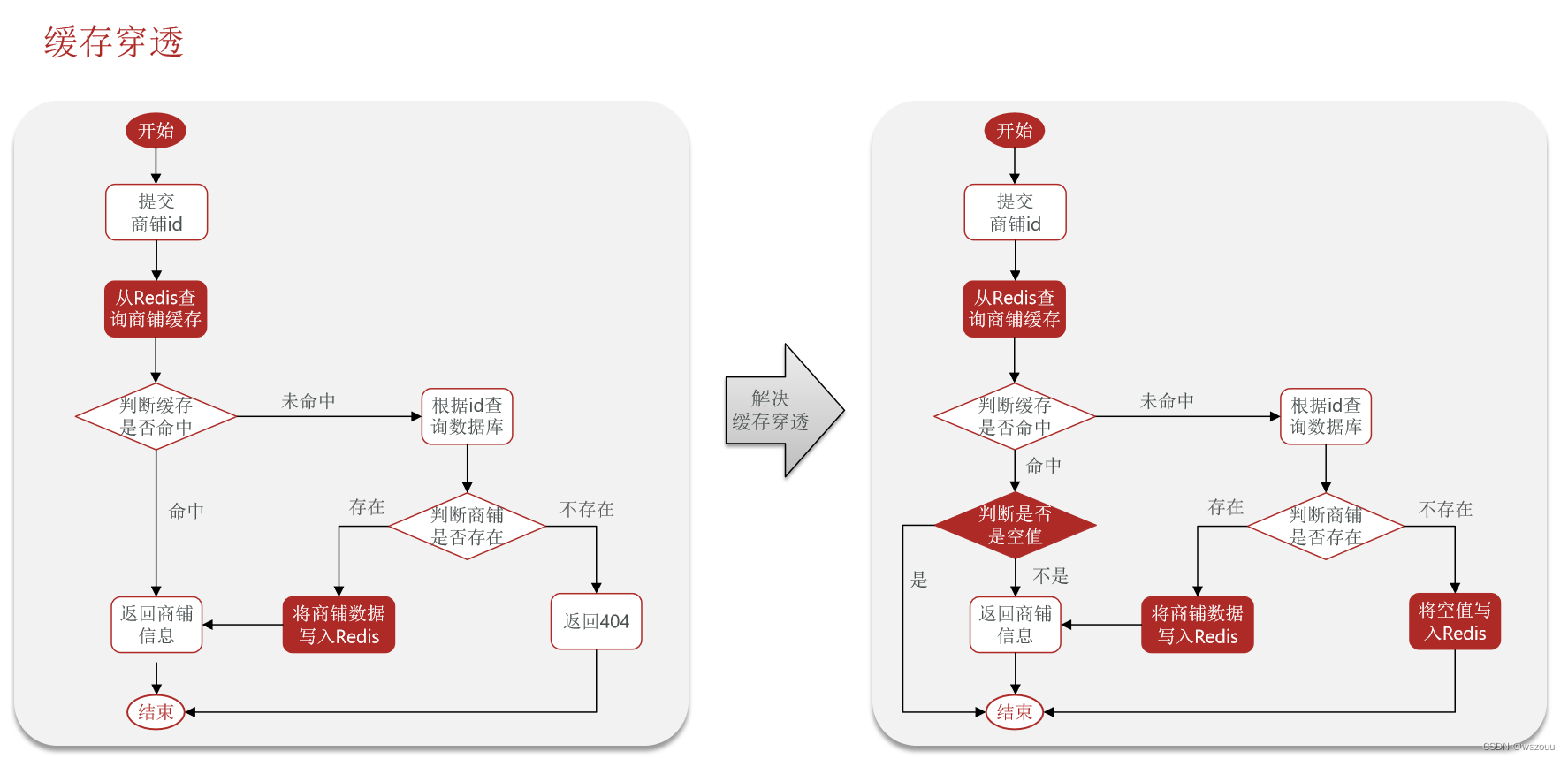
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
/**
* 缓存穿透方法
* @param id
* @return
*/
public <R,ID> R queryWithPassThrough(String keyPrefix, ID id, Class<R> type, Long time, TimeUnit unit,Function<ID,R> dbFallback){
String key = keyPrefix+id;
//1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
//2.判断是否存在
if (StrUtil.isNotBlank(json)) {
//3.存在,直接返回
return JSONUtil.toBean(json, type);
}
//命中的是否是空值
if (json != null) {
return null;
}
//4.不存在,根据id查询数据库
R r = dbFallback.apply(id);
//5.不存在,返回错误
if(r==null){
//将空值写入reddis
stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
//6.存在,写入redis
this.set(key,r,time,unit);
//7.返回
return r;
}
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
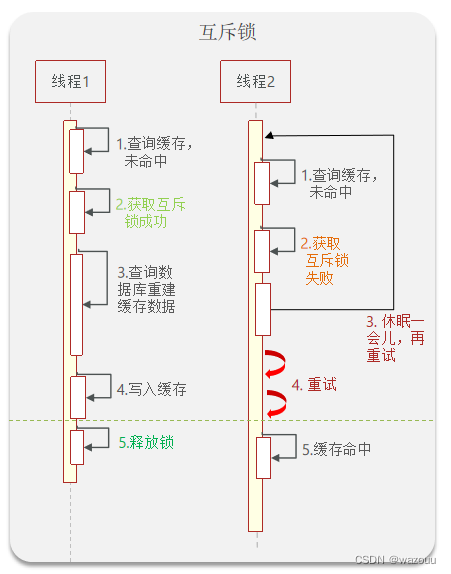
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
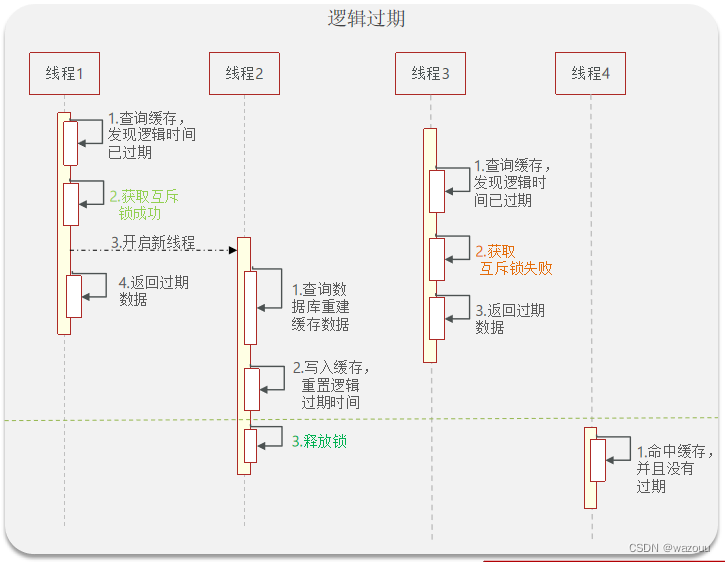

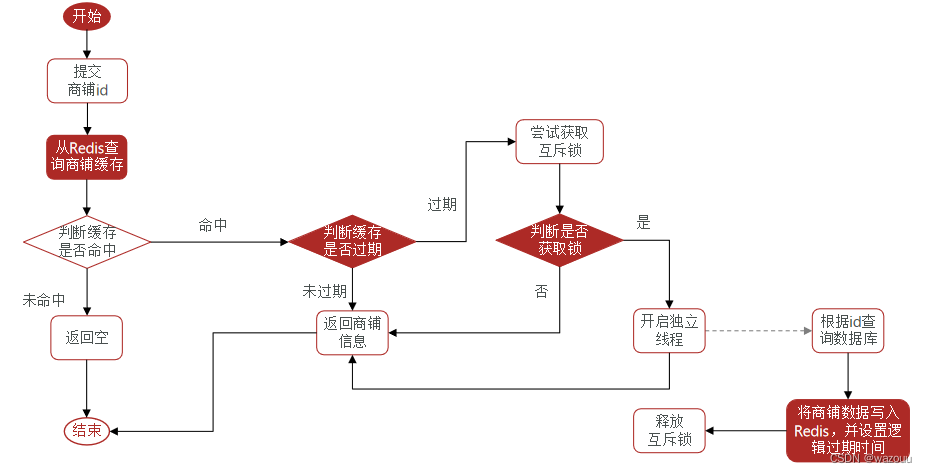
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
/**
* 逻辑过期解决缓存击穿
* @param id
* @return
*/
public <R,ID> R queryWithLogicalExpire(String keyPrefix,ID id,Class<R> type, Long time, TimeUnit unit,Function<ID,R> dbFallback){
String key = keyPrefix+id;
//1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
//2.判断是否存在
if (StrUtil.isBlank(json)) {
//3.不存在,直接返回
return null;
}
//4.命中,先把json反序列化
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
JSONObject data = (JSONObject) redisData.getData();
R r = JSONUtil.toBean(data, type);
LocalDateTime expireTime = redisData.getExpireTime();
//5.判断是否过期
if(expireTime.isAfter(LocalDateTime.now())){
//5.1未过期,直接返回
return r;
}
//5.2已过期,需要缓存重建
//6.缓存重建
//6.1获取互斥锁
String lockkey = LOCK_SHOP_KEY + id;
boolean lock = tryLock(lockkey);
//6.2判断是否获取锁成功
if(lock){
//6.3成功,开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(()->{
try {
//查询数据库
R r1 = dbFallback.apply(id);
//写入redis
this.setWithLogicalExpire(key,r1,time,unit);
} catch (Exception e) {
e.printStackTrace();
} finally {
//释放锁
unlock(lockkey);
}
});
}
//6.4返回商铺信息
return r;
}
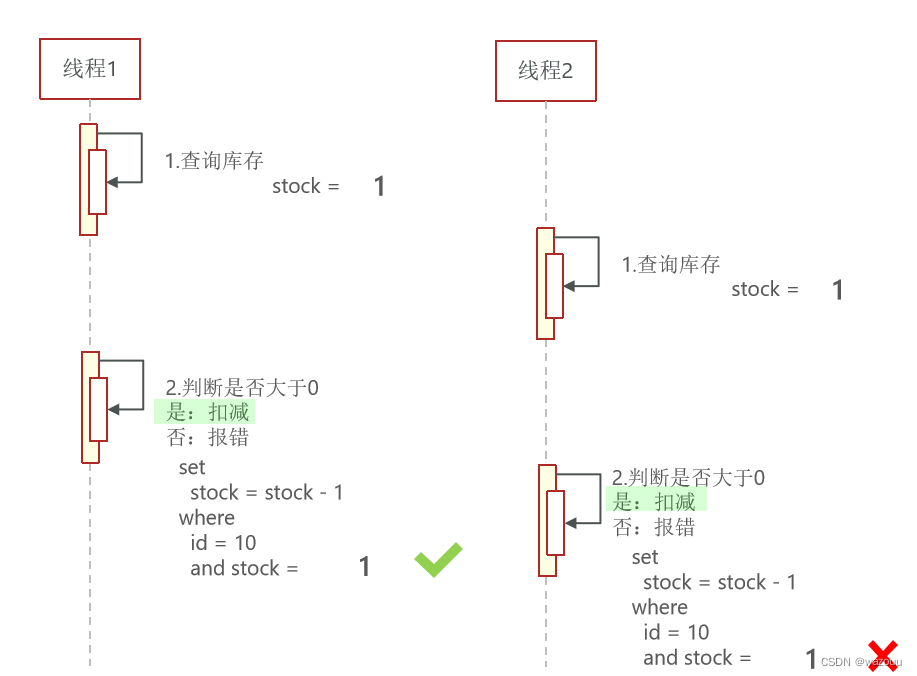
一般流程:
请求a查询库存,发现库存为1,请求b这时也来查询库存,库存也为1,然后请求a让数据库减1,这时候b查询到的仍然是1,也继续让库存减1,就会导致超卖。
超卖问题有以下几个解决方案:
乐观锁:认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其它线程对数据做了修改。如果没有修改则认为是安全的,自己才更新数据。如果已经被其它线程修改说明发生了安全问题,此时可以重试或异常。悲观锁:认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。例如Synchronized、Lock都属于悲观锁实现乐观锁主要有以下两种方法:
每次更新数据库的时候按照版本查询,并且要更新版本。
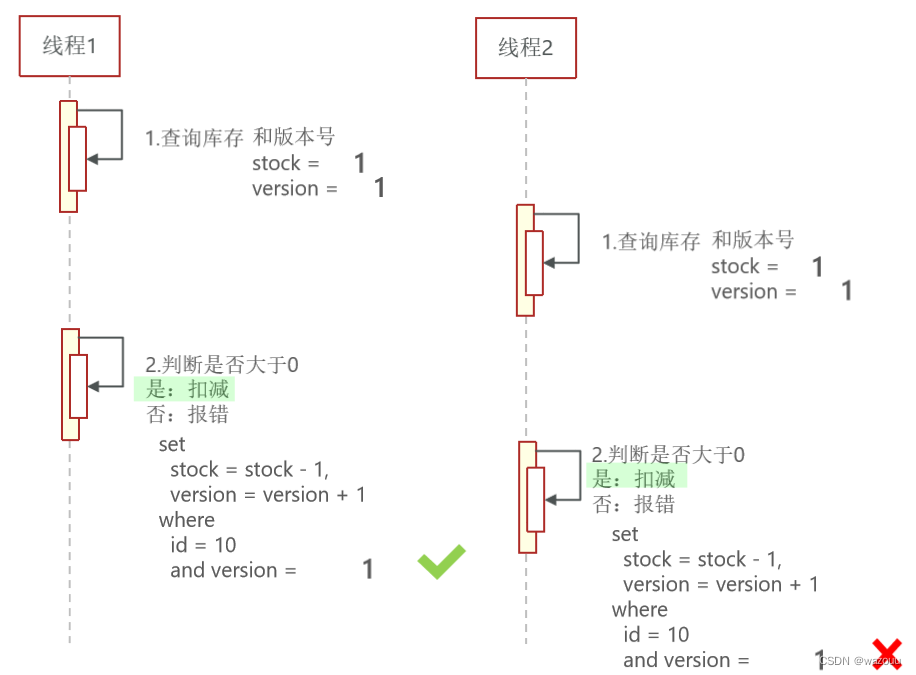
CAS是英文单词Compare And Swap的缩写,翻译过来就是比较并替换。
CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。
更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。
CAS的缺点:
1.CPU开销较大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很大的压力。
2.不能保证代码块的原子性
CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用Synchronized了。
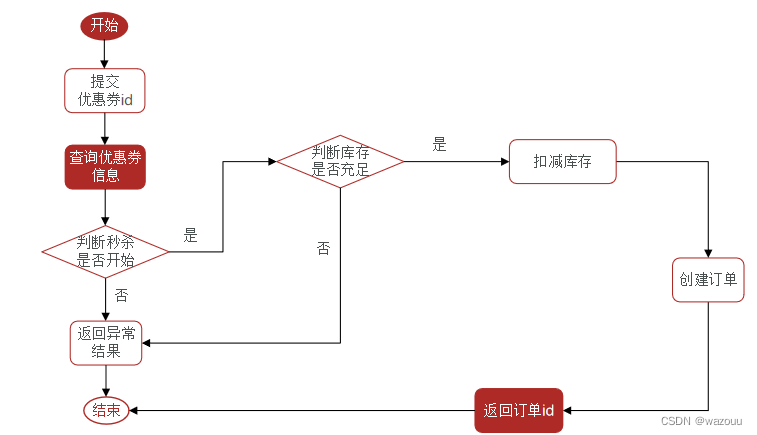
要求同一个优惠券,一个用户只能下一单
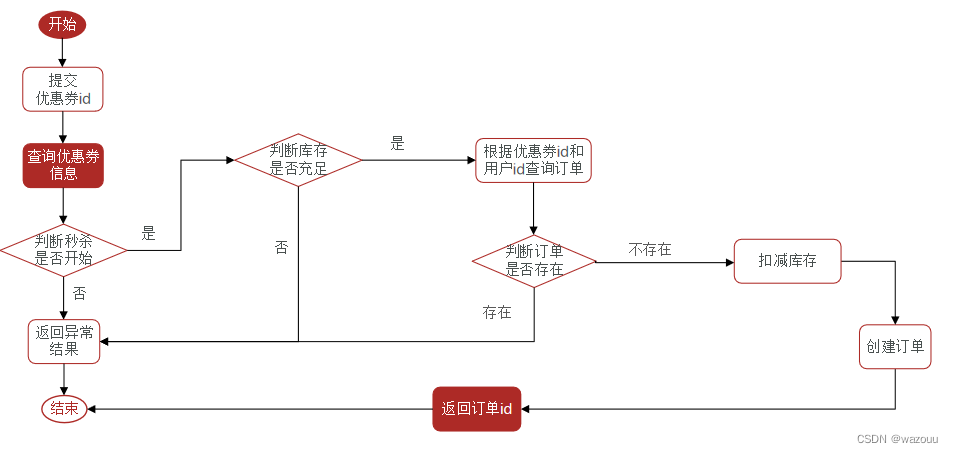
这样的方式会产生并发安全问题:
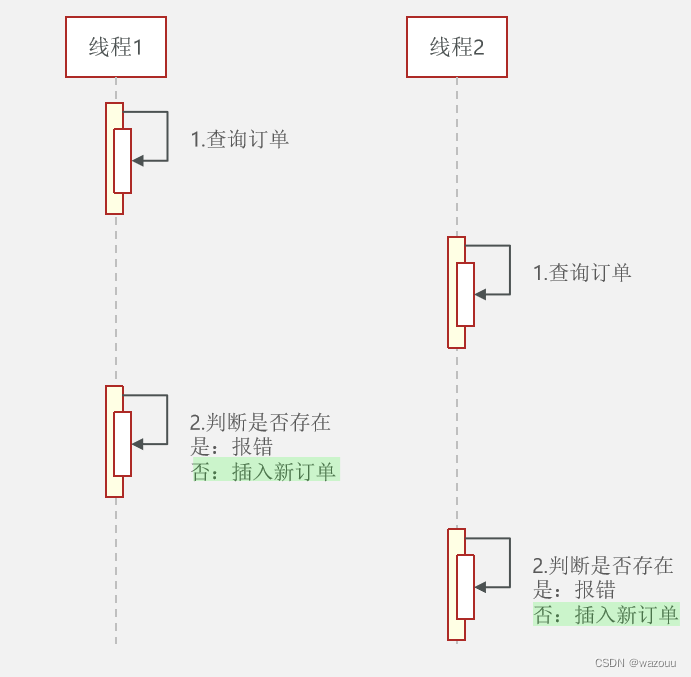
通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了(每个jvm都有自己的锁监视器,集群模式下各个服务器的锁不共享)。
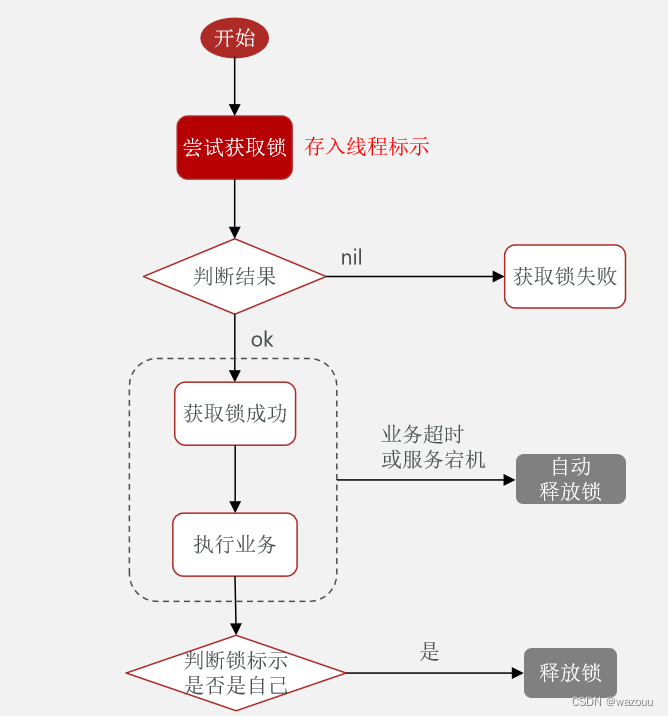
因此,我们的解决方案就是实现一个共享的锁监视器,即:
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
setnx = SET if Not eXists
将 key 的值设为 value ,当且仅当 key 不存在。
若给定的 key 已经存在,则 SETNX 不做任何动作

在某个线程获取锁执行业务时若发生阻塞,且阻塞过程中锁超时,此时另一个线程同样来请求锁,发现可以获取锁,但实际上前一个线程还没执行完。
解决方案:
(三四章先占坑)
简单的crud
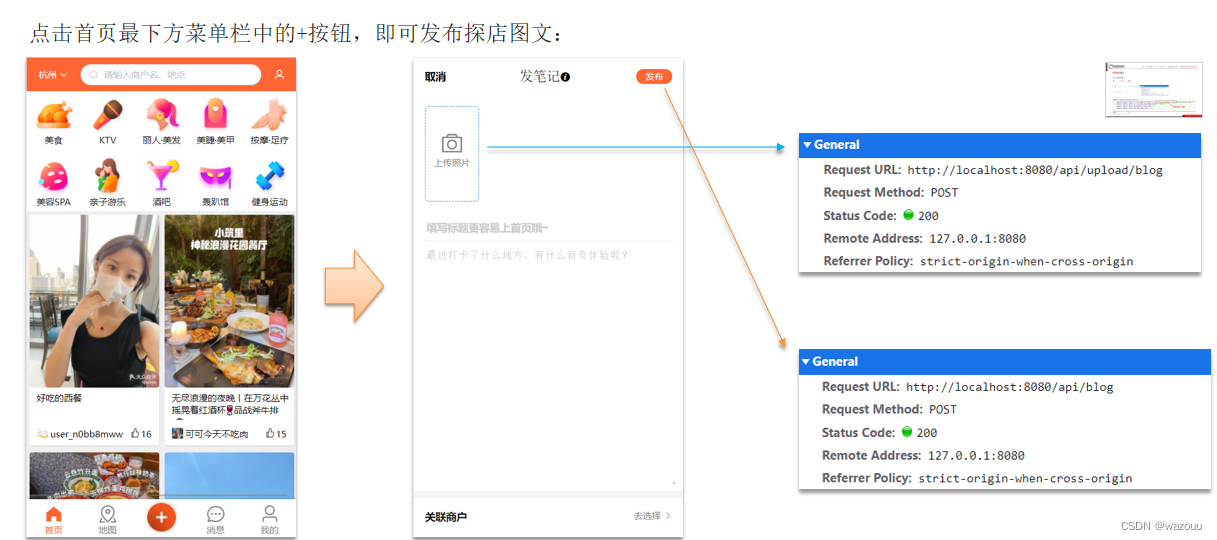
需求:
实现步骤:
需求:按照点赞时间先后排序,返回Top5的用户
使用SortedSet:
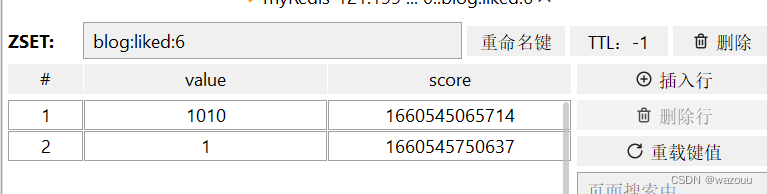
完整代码:
BlogController
@RestController
@RequestMapping("/blog")
public class BlogController {
@Resource
private IBlogService blogService;
@PutMapping("/like/{id}")
public Result likeBlog(@PathVariable("id") Long id) {
return blogService.likeBlog(id);
}
@GetMapping("/hot")
public Result queryHotBlog(@RequestParam(value = "current", defaultValue = "1") Integer current) {
return blogService.queryHotBlog(current);
}
@GetMapping("/{id}")
public Result queryBlogById(@PathVariable("id") String id){
return blogService.queryBlogById(id);
}
@GetMapping("/likes/{id}")
public Result queryBlogLikes(@PathVariable("id") String id) {
return blogService.queryBlogLikes(id);
}
}
IBlogService
public interface IBlogService extends IService<Blog> {
Result queryBlogById(String id);
Result queryHotBlog(Integer current);
Result likeBlog(Long id);
Result queryBlogLikes(String id);
}
BlogServiceImpl
Service
public class BlogServiceImpl extends ServiceImpl<BlogMapper, Blog> implements IBlogService {
@Autowired
private IUserService userService;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryHotBlog(Integer current) {
// 根据用户查询
Page<Blog> page = query()
.orderByDesc("liked")
.page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
// 查询用户
records.forEach(blog -> {
this.queryBlogUser(blog);
this.isBlogLiked(blog);
});
return Result.ok(records);
}
@Override
public Result likeBlog(Long id) {
// 1、获取登录用户
UserDTO user = UserHolder.getUser();
// 2、判断当前登录用户是否已经点赞
Double score = stringRedisTemplate.opsForZSet().score(RedisConstants.BLOG_LIKED_KEY + id, user.getId().toString());
if(score == null) {
// 3、如果未点赞,可以点赞
// 3.1、数据库点赞数 +1
boolean isSuccess = update().setSql("liked = liked+1").eq("id", id).update();
// 3.2、保存用户到 Redis 的 set 集合
if(isSuccess){
// 时间作为 key 的 score
stringRedisTemplate.opsForZSet().add(RedisConstants.BLOG_LIKED_KEY + id, user.getId().toString(), System.currentTimeMillis());
}
} else {
// 4、如果已点赞,取消点赞
// 4.1、数据库点赞数 -1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
// 4.2、把用户从 Redis 的 set 集合移除
if(isSuccess){
stringRedisTemplate.opsForZSet().remove(RedisConstants.BLOG_LIKED_KEY + id, user.getId().toString());
}
}
return Result.ok();
}
@Override
public Result queryBlogLikes(String id) {
String key = RedisConstants.BLOG_LIKED_KEY + id;
// 查询 top5 的点赞用户
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);
if(top5 == null){
return Result.ok(Collections.emptyList());
}
// 解析出其中的用户id
List<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());
String join = StrUtil.join(",", ids);
// 根据用户id查询用户
List<UserDTO> userDTOS = userService.query().in("id", ids).last("order by filed(id, "+join+")").list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(userDTOS);
}
private void queryBlogUser(Blog blog) {
Long userId = blog.getUserId();
User user = userService.getById(userId);
blog.setName(user.getNickName());
blog.setIcon(user.getIcon());
}
@Override
public Result queryBlogById(String id) {
Blog blog = getById(id);
if(blog == null){
return Result.fail("笔记不存在!");
}
queryBlogUser(blog);
// 查询 Blog 是否被点赞
isBlogLiked(blog);
return Result.ok(blog);
}
private void isBlogLiked(Blog blog) {
UserDTO user = UserHolder.getUser();
if(user == null){
return;
}
Long userId = user.getId();
String key = RedisConstants.BLOG_LIKED_KEY + blog.getId();
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
blog.setIsLike(score != null);
}
}
基于mysql实现:
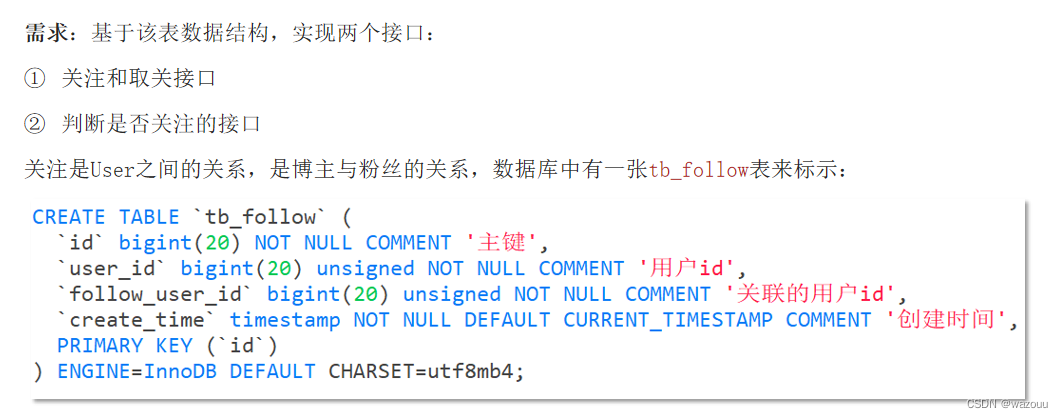
基于redis实现:
设置一个给每个用户设置一个key,利用set结构存储关注该用户的人。
代码:
@PutMapping("/{id}/{isFollow}")
public Result follow(@PathVariable("id") Long followUserId,@PathVariable("isFollow") Boolean isFollow){
return followService.follow(followUserId,isFollow);
}
@Override
public Result follow(Long followUserId, Boolean isFollow) {
Long userId = UserHolder.getUser().getId();
String key = "follows:" + userId;
//1.判断关注还是取关
if(isFollow){
//2.关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean success = save(follow);
if(success){
//把关注用户的id,放入redis的set集合
stringRedisTemplate.opsForSet().add(key,followUserId.toString());
}
}else{
//3.取关,删除数据
boolean success = remove(new QueryWrapper<Follow>().eq("user_id", userId).eq("follow_user_id", followUserId));
//把关注的用户id从redis集合中移除
if(success) stringRedisTemplate.opsForSet().remove(key,followUserId.toString());
}
return Result.ok();
}
@GetMapping("/or/not/{id}")
public Result isFollow(@PathVariable("id") Long followUserId){
return followService.isFollow(followUserId);
}
@Override
public Result isFollow(Long followUserId) {
Long userId = UserHolder.getUser().getId();
//1.查询是否关注
Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count();
return Result.ok(count>0);
}
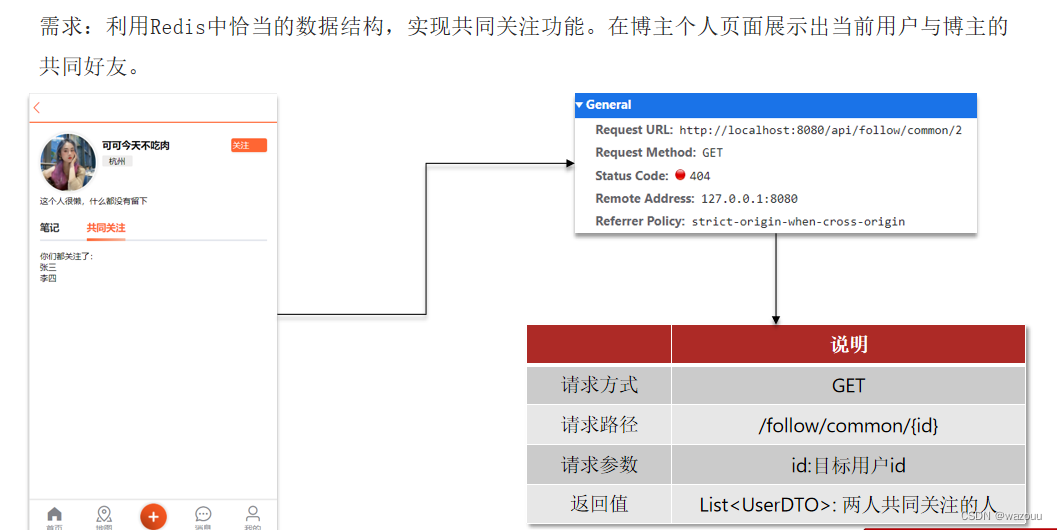
在关注点击关注用户时,用redis的set结构存储自己关注了哪些用户,然后利用集合的交集就能轻松求出共同关注的用户了。
@GetMapping("/common/{id}")
public Result followCommons(@PathVariable("id") Long id){
return followService.followCommons(id);
}
@Override
public Result followCommons(Long id) {
//1.获取当前用户
Long userId = UserHolder.getUser().getId();
String key = "follows:" + userId;
//2.求交集
String key2 = "follows:" + id;
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
if(intersect==null||intersect.isEmpty()){
//无交集
return Result.ok(Collections.emptyList());
}
//3.解析id集合
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
//4.查询用户
List<UserDTO> users = userService.listByIds(ids)
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(users);
}
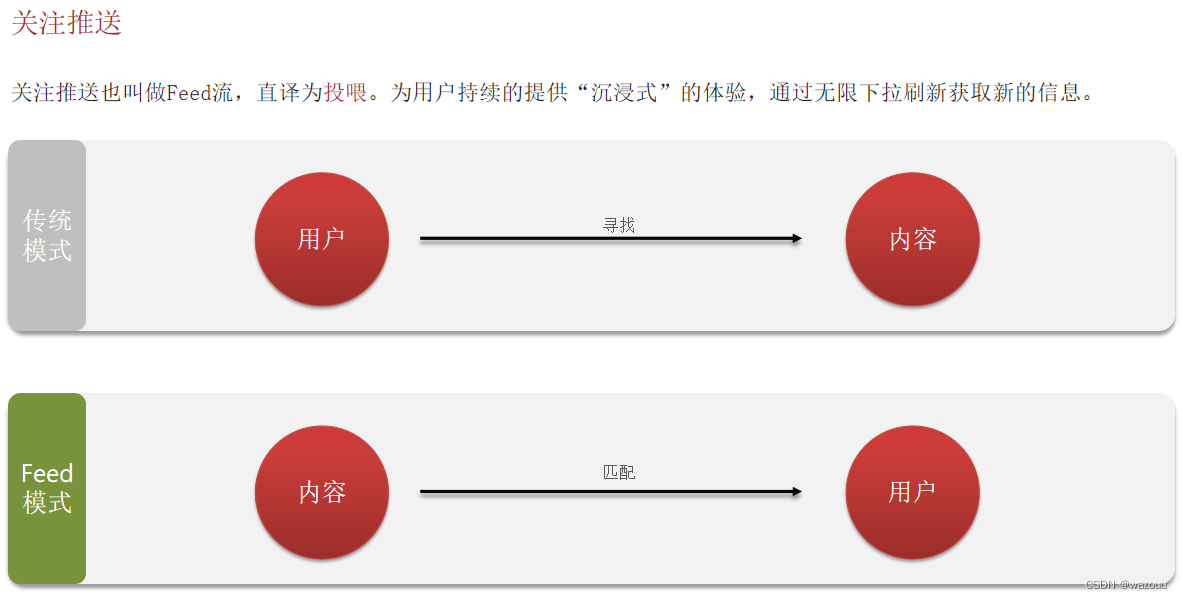
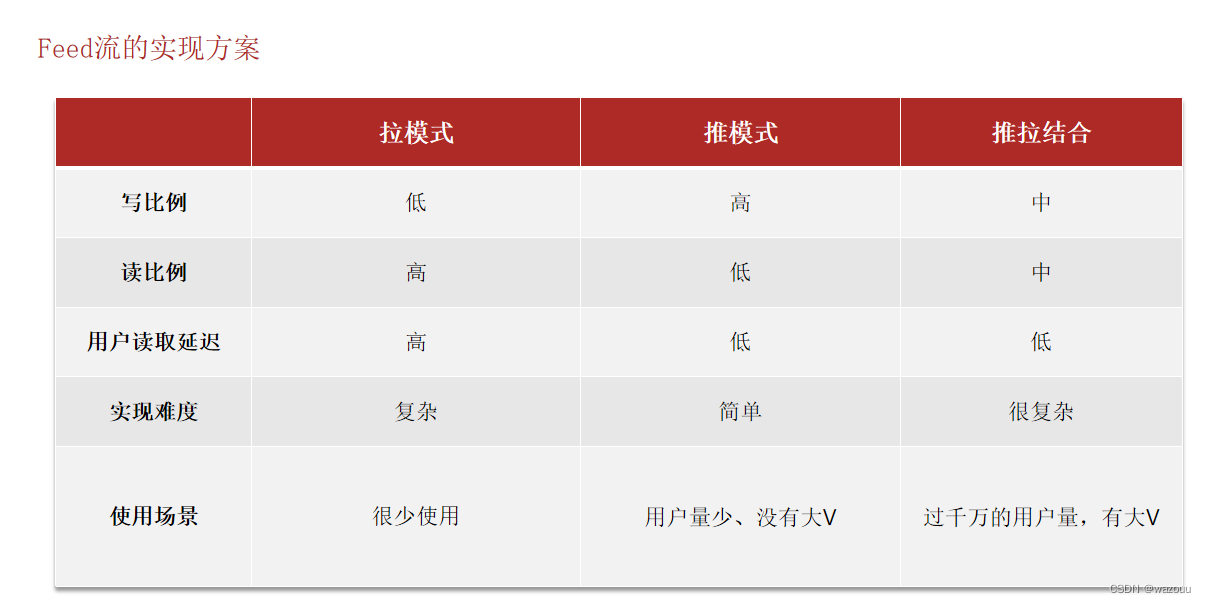
Feed流产品有两种常见模式:
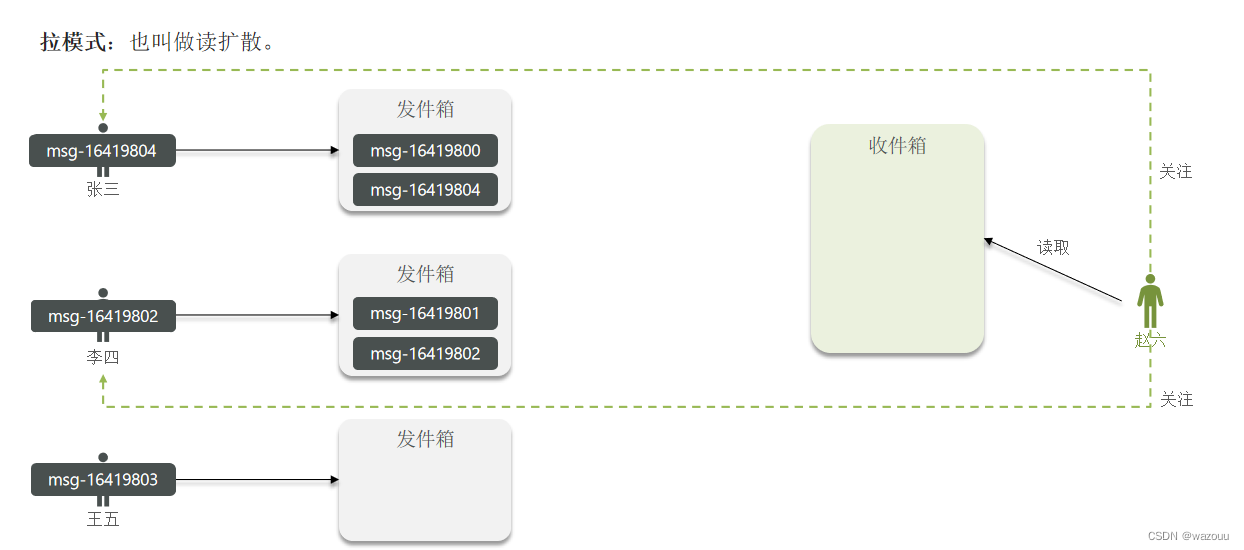
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:
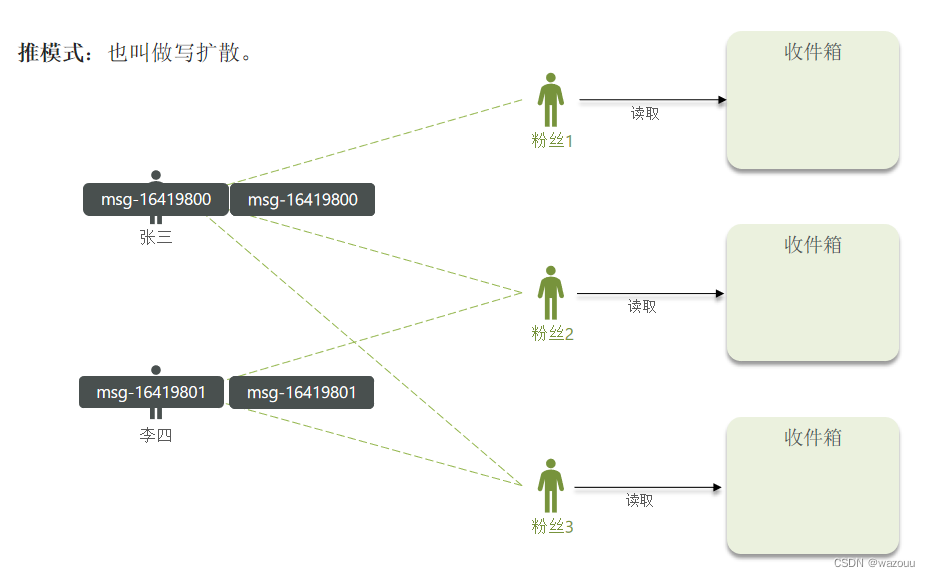
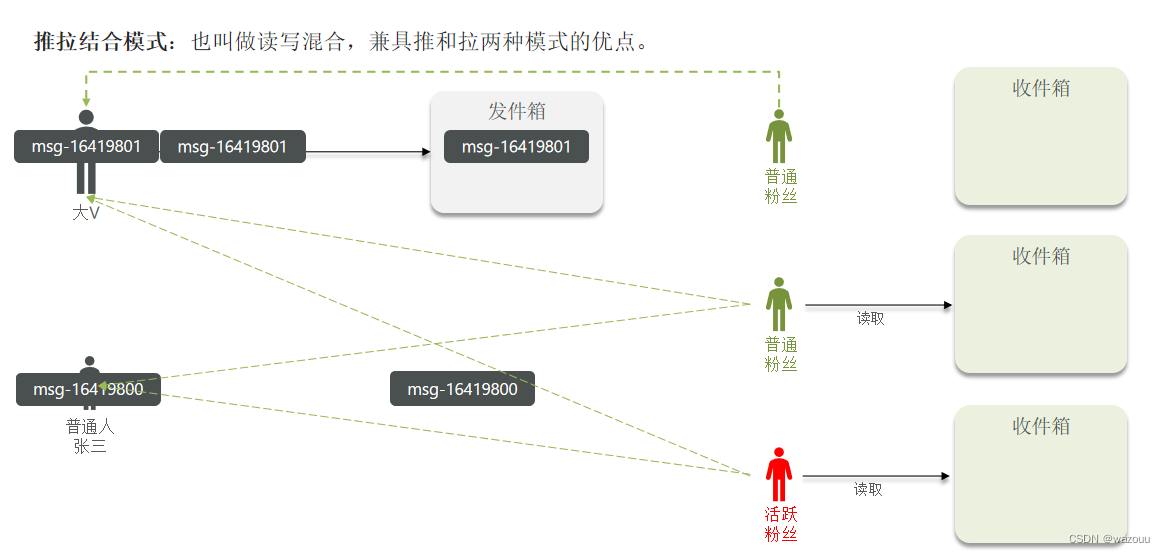
这里基于推模式模式实现关注推送,需求:
推送:
@PostMapping
public Result saveBlog(@RequestBody Blog blog) {
return blogService.saveBlog(blog);
}
@Override
public Result saveBlog(Blog blog) {
// 1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2.保存探店博文
boolean success = this.save(blog);
if(!success) return Result.fail("新增笔记失败!");
//3.查询笔记作者的所有粉丝
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
//4.推送笔记id给有所粉丝
for (Follow follow : follows) {
//4.1获取粉丝id
Long followId = follow.getUserId();
//4.2推送
String key = FEED_KEY+followId;
stringRedisTemplate.opsForZSet().add(key,blog.getId().toString(),System.currentTimeMillis());
}
// 返回id
return Result.ok(blog.getId());
}
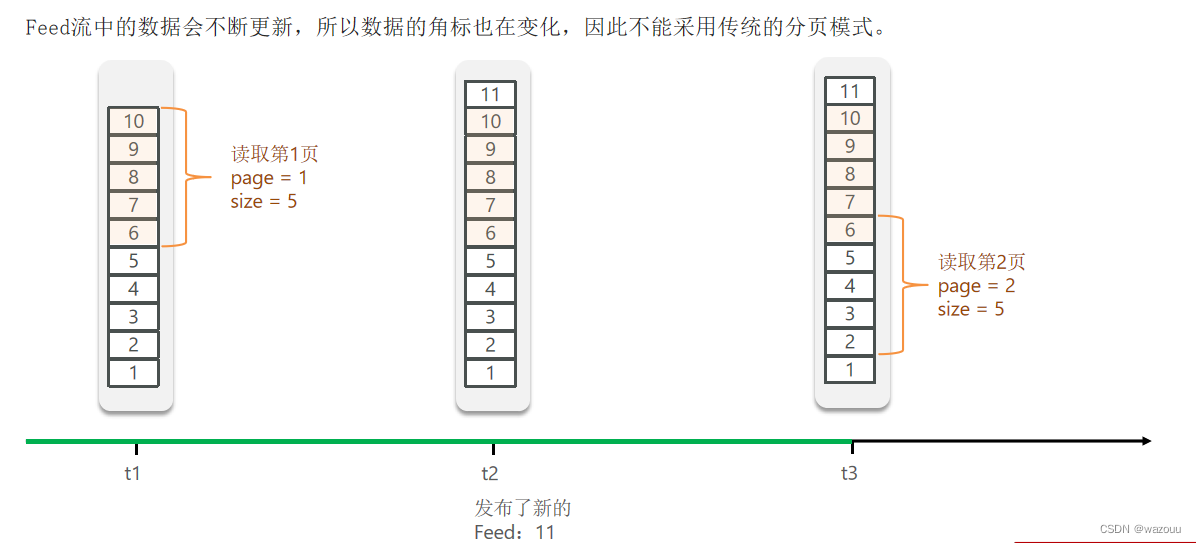
读取:
@GetMapping("/of/follow")
public Result queryBlogOfFollow(
@RequestParam("lastId") Long max,@RequestParam(value = "offset",defaultValue = "0") Integer offset){
return blogService.queryBlogOfFollow(max,offset);
}
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
//1.获取当前用户
Long userId = UserHolder.getUser().getId();
//2.查询收件箱
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
if(typedTuples==null||typedTuples.isEmpty()) return Result.ok();
//3.解析数据:blogId,minTime(时间戳),offset
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0;
int os = 1;
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {
//3.1查询id
String idStr = tuple.getValue();
ids.add(Long.valueOf(idStr));
//4.2获取分数(时间戳)
if(tuple.getScore().longValue()==minTime){
os++;
}else os = 1;
minTime = tuple.getScore().longValue();
}
//4.根据id查询blog
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query()
.in("id",ids).last("ORDER BY FIELD(ID,"+idStr+")").list();
for (Blog blog : blogs) {
queryBlogUser(blog);
isBlogLiked(blog);
}
//5.封装并返回
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}
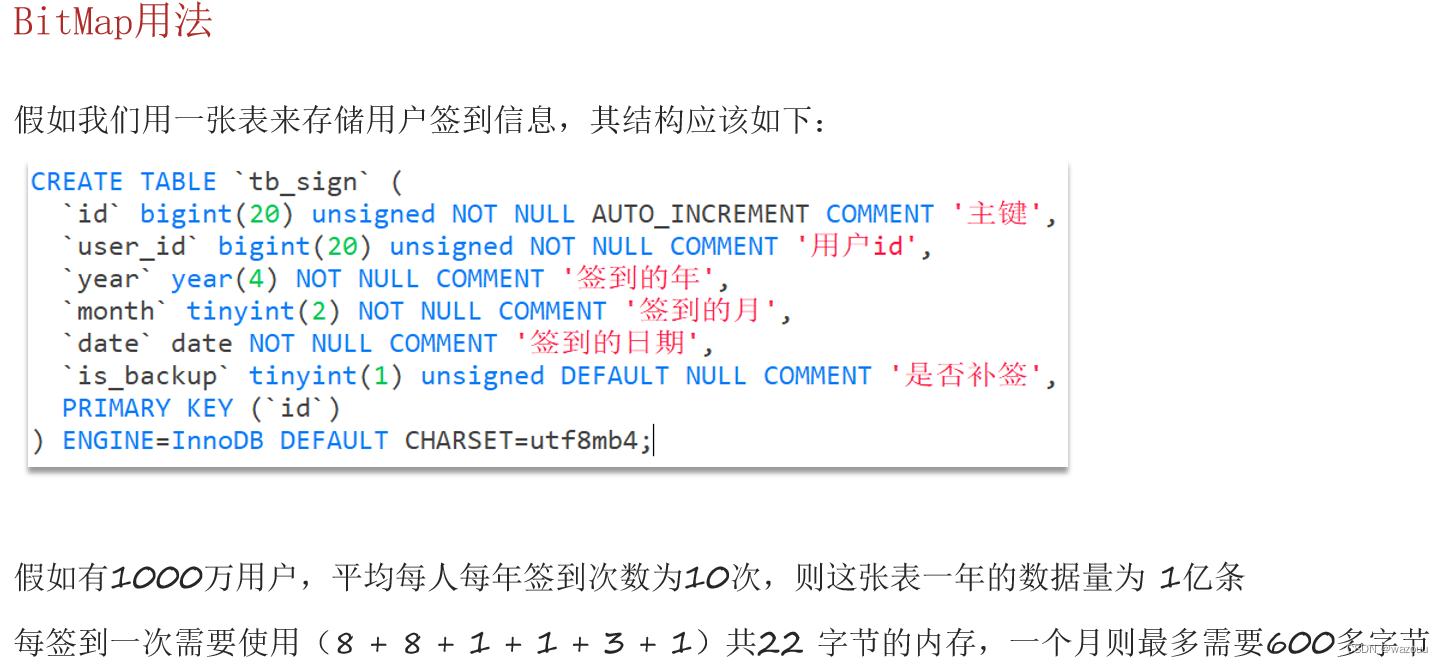

@PostMapping("/sign")
public Result sign(){
return userService.sign();
}
@Override
public Result sign() {
//1.获取当前用户
Long userId = UserHolder.getUser().getId();
//2.获取日期
LocalDateTime now = LocalDateTime.now();
//3.拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;
//4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth() - 1;
//5.写入redis
stringRedisTemplate.opsForValue().setBit(key,dayOfMonth,true);
return Result.ok();
}
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
我正在尝试创建一个带有项目符号字符的Ruby1.9.3字符串。str="•"+"helloworld"但是,当我输入它时,我收到有关非ASCII字符的语法错误。我该怎么做? 最佳答案 你可以把Unicode字符放在那里。str="\u2022"+"helloworld" 关于ruby-如何在Ruby字符串中插入项目符号字符?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1195
我的Rails站点使用了一个确实不是很好的gem。每次我需要做一些新的事情时,我最终不得不花费与向实际Rails项目添加代码一样多的时间来为gem添加功能。但我不介意,我将我的Gemfile设置为指向我的gem的GitHub分支(我尝试提交PR,但维护者似乎已经下台)。问题是我真的没有找到一种合理的方法来测试我添加到gem的新东西。在railsc中测试它会特别好,但我能想到的唯一方法是a)更改~/.rvm/gems/.../foo。rb,这看起来不对或者b)升级版本,推送到Github,然后运行bundleup,这除了耗时之外显然是一场灾难,因为我不确定我所做的promise是否正
我一直在尝试使用nanoc用于生成静态网站。我需要组织一个复杂的排列页面,我想让我的内容保持干燥。包含或合并的概念在nanoc系统中如何运作?我已阅读文档,但似乎找不到我想要的内容。例如:我如何获取两个部分内容项并将它们合并到一个新的内容项中。在staticmatic您可以在您的页面中执行以下操作。=partial('partials/shared/navigation')类似的约定在nanoc中如何运作? 最佳答案 这里是nanoc的作者。在nanoc中,部分是布局。因此,您可以拥有layouts/partials/shared/
我安装了ruby、yeoman,当我运行我的项目时,出现了这个错误:Warning:Running"compass:dist"(compass)taskWarning:YouneedtohaveRubyandCompassinstalledthistasktowork.Moreinfo:https://github.com/gruUse--forcetocontinue.Use--forcetocontinue.我有进入可变session目标的路径,但它不起作用。谁能帮帮我? 最佳答案 我必须运行这个:geminstallcom
我有一个包含多个组件的存储库,其中大部分是用JavaScript(Node.js)编写的,一个是用Ruby(RubyonRails)编写的。我想要一个.travis.yml文件来触发一个运行每个组件的所有测试的构建。根据thisTravisCIGoogleGroupthread,目前还没有官方支持。我的目录结构是这样的:.├──构建服务器├──核心├──扩展├──网络应用├──流浪文件├──package.json├──.travis.yml└──生成文件我希望能够运行特定版本的Ruby(2.2.2)和Node.js(0.12.2)。我已经有了一个make目标,所以maketest在每