😽PREFACE
🎁欢迎各位→点赞👍 + 收藏⭐ + 评论📝
📢系列专栏:数据结构
🔊本专栏主要更新的是数据结构部分知识点
💪种一棵树最好是十年前其次是现在
目录
文章链接:【数据结构】堆的实现
在上篇博客里面,我们详细给出了堆的由来及其实现,其实由于堆这个结构的性质,也是可以直接对一个乱序数组实现排序的。不妨假设排升序并且有一个小根堆,实现过程如下:
- 首先,把数组里面的每个数都插入(HeapPush)到堆里。(注意HeapPush里面包含向上调整,所以每次插入之后都会保持堆这个结构)
- 其次,小根堆的堆顶是最小的,我们只需每次取出堆顶(HeapTop)元素到数组里面,从堆中取完之后,记得删除该元素(HeapPop)。由于HeapPop里面就有向下调整,每次删完之后都会保持堆的结构,也就是说堆顶元素永远都是最小的。接着一直重复上述操作,直至堆为空(HeapEmpty).
void HeapSort(int* a, int size)
{
HP hp;
HeapInit(&hp);
//把数组元素插入到堆里
for (int i = 0; i < size; i++)
{
HeapPush(&hp, a[i]);
}
int j = 0;
//依次遍历,取堆顶元素到数组,++下标,pop堆顶,依次循环
while (!HeapEmpty(&hp))
{
a[j] = HeapTop(&hp);
j++;
HeapPop(&hp);
}
HeapDestroy(&hp);//记得销毁
}
int main()
{
int a[] = { 3,4,1,9,6,7,5,8 };
HeapSort(a, sizeof(a) / sizeof(int));
for (int i = 0; i < sizeof(a) / sizeof(int); i++)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}很显然,每次要进行上述方法排序时都要手搓堆的实现代码,很繁琐!!!
堆排序就是利用堆的思想来排序,总共分为两步:
1.建堆
2.利用堆删除思想来进行排序
关于建堆,有两种方法:
1.使用向上建堆,插入数据的思想建堆
2.使用向下调整建堆
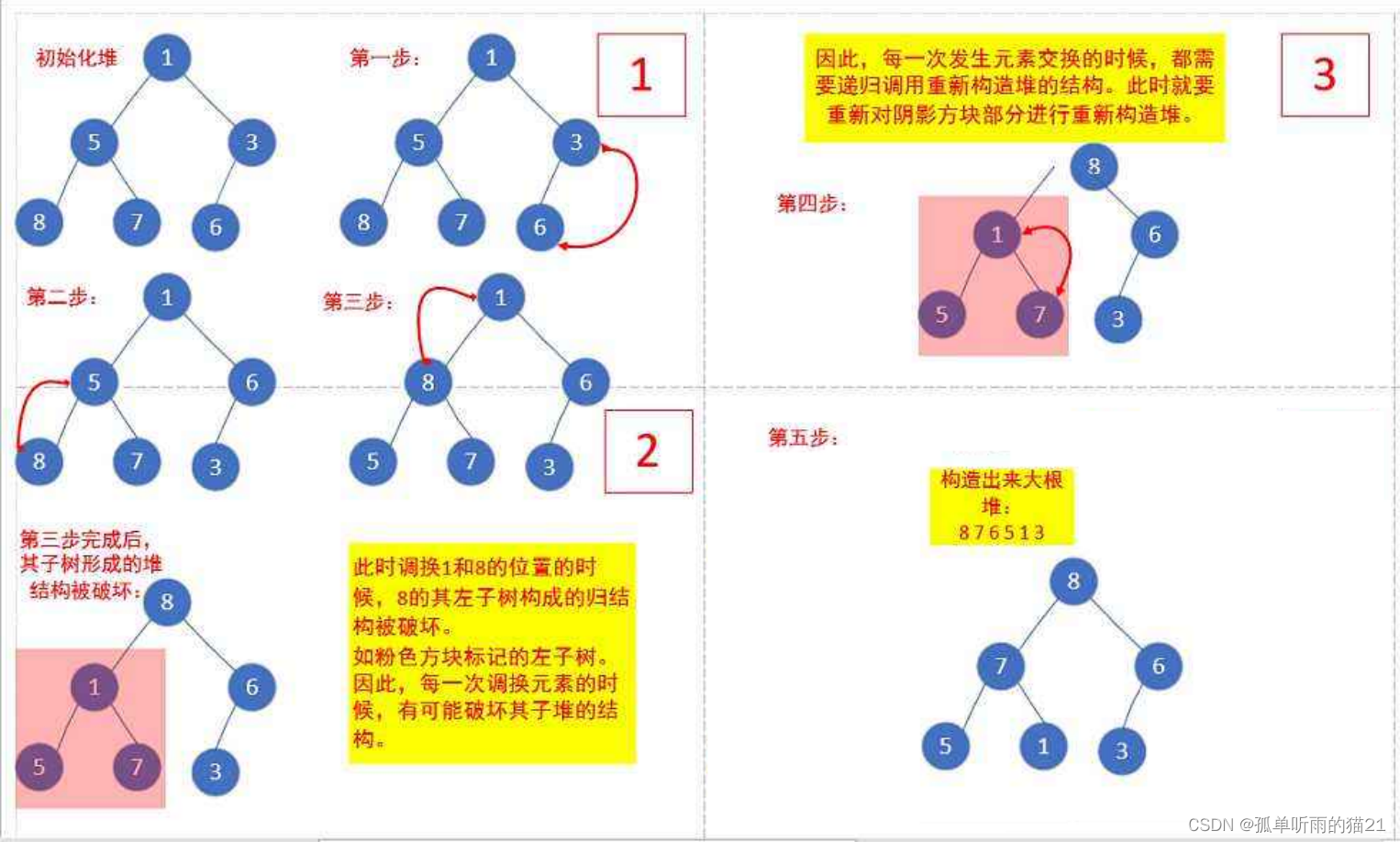
图解过程:

代码如下:
#include <stdio.h>
#include <assert.h>
void AdjustUp(int* a, int child)
{
assert(a);
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])//小堆
{
int tmp = a[child];
a[child] = a[parent];
a[parent] = tmp;
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//升序
void HeapSort(int* a, int n)
{
//建堆
for (int i = 1; i < n; i++)//i从1开始遍历,因为第一个数据在堆里不需要调整,后续再插入时调整
{
AdjustUp(a, i);
}
}
int main()
{
int a[] = { 3,4,1,9,6,7,5,8 };
HeapSort(a, sizeof(a) / sizeof(int));
for (int i = 0; i < sizeof(a) / sizeof(int); i++)
{
printf("%d ", a[i]);
}
return 0;
}运行结果:

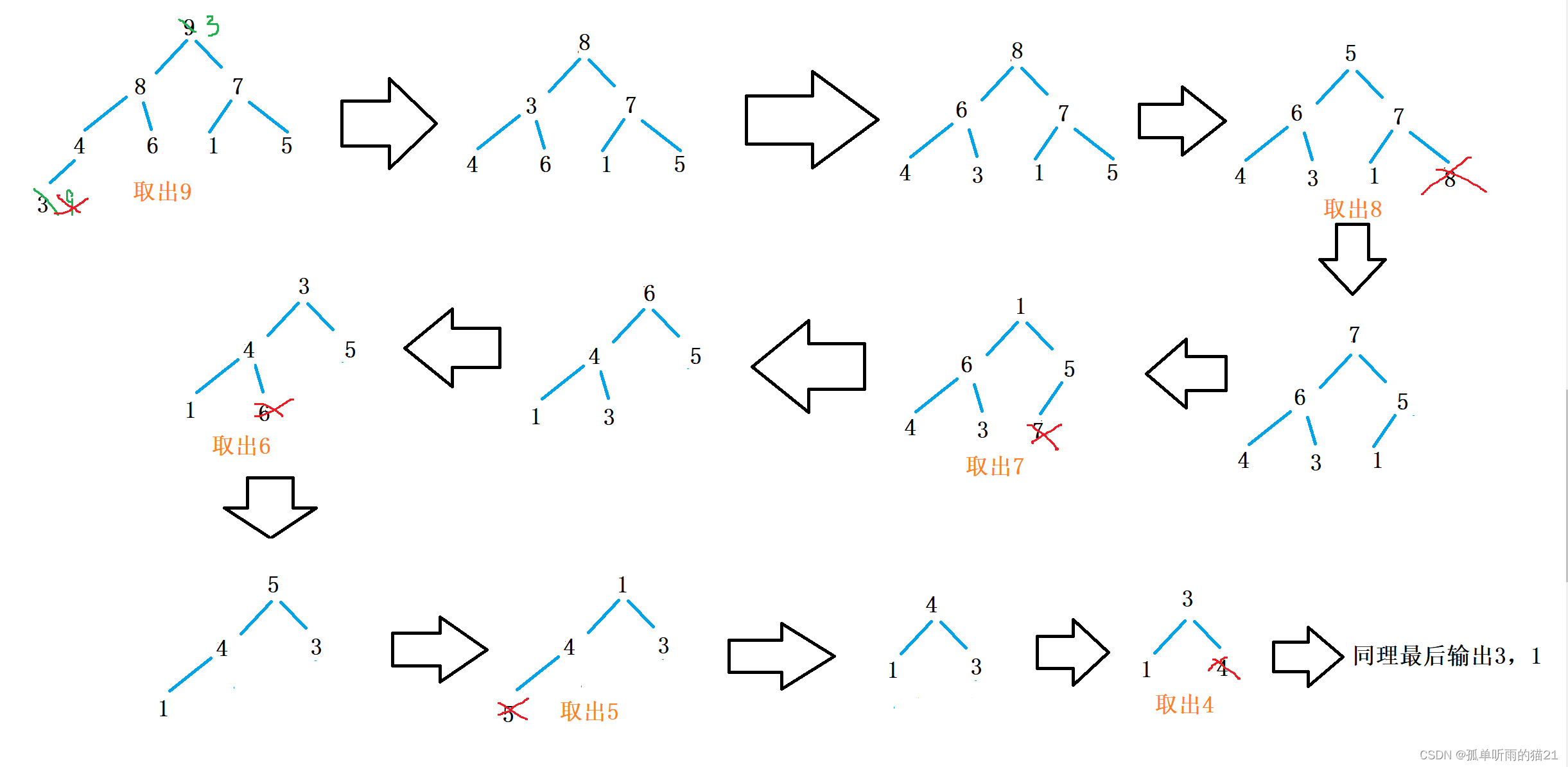
首先不能直接进行向下调整,因为向下调整的前提是 必须保证根结点的左右子树均为小堆,但是这里的数组是乱序的,因此不能直接使用。但是我们可以 从倒数第一个非叶结点开始向下调整,从下往上调。这又出现了一个问题,那就是倒数第一个非叶结点在哪呢,通过画逻辑图不难看出,其实 最后一个结点的父亲就是倒数第一个非叶结点。当我们找到这个非叶结点时,把它和它的孩子看作一个整体,进行向下调整。调整之后,再将次父结点向前挪动,再次进行向下调整,依次循环下去。
图解过程:

#include <stdio.h>
#include <assert.h>
void Swap(int* pa, int* pb)
{
int tmp = *pa;
*pa = *pb;
*pb = tmp;
}
void AdjustUp(int* a, int child)
{
assert(a);
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])//小堆
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void AdjustDown(int* a, int n, int parent)
{
int child = 2 * parent + 1;
while (child < n)
{
if (child + 1 < n && a[child + 1] < a[child])
{
++child;
}
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
//升序
void HeapSort(int* a, int n)
{
建堆
//for (int i = 1; i < n; i++)//i从1开始遍历,因为第一个数据在堆里不需要调整,后续再插入时调整
//{
// AdjustUp(a, i);
//}
//建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
}
int main()
{
int a[] = { 3,4,1,9,6,7,5,8 };
HeapSort(a, sizeof(a) / sizeof(int));
for (int i = 0; i < sizeof(a) / sizeof(int); i++)
{
printf("%d ", a[i]);
}
return 0;
}运行结果:
满足小堆性质。
1.1中的向上建堆和向下建堆哪个时间复杂度更小呢?
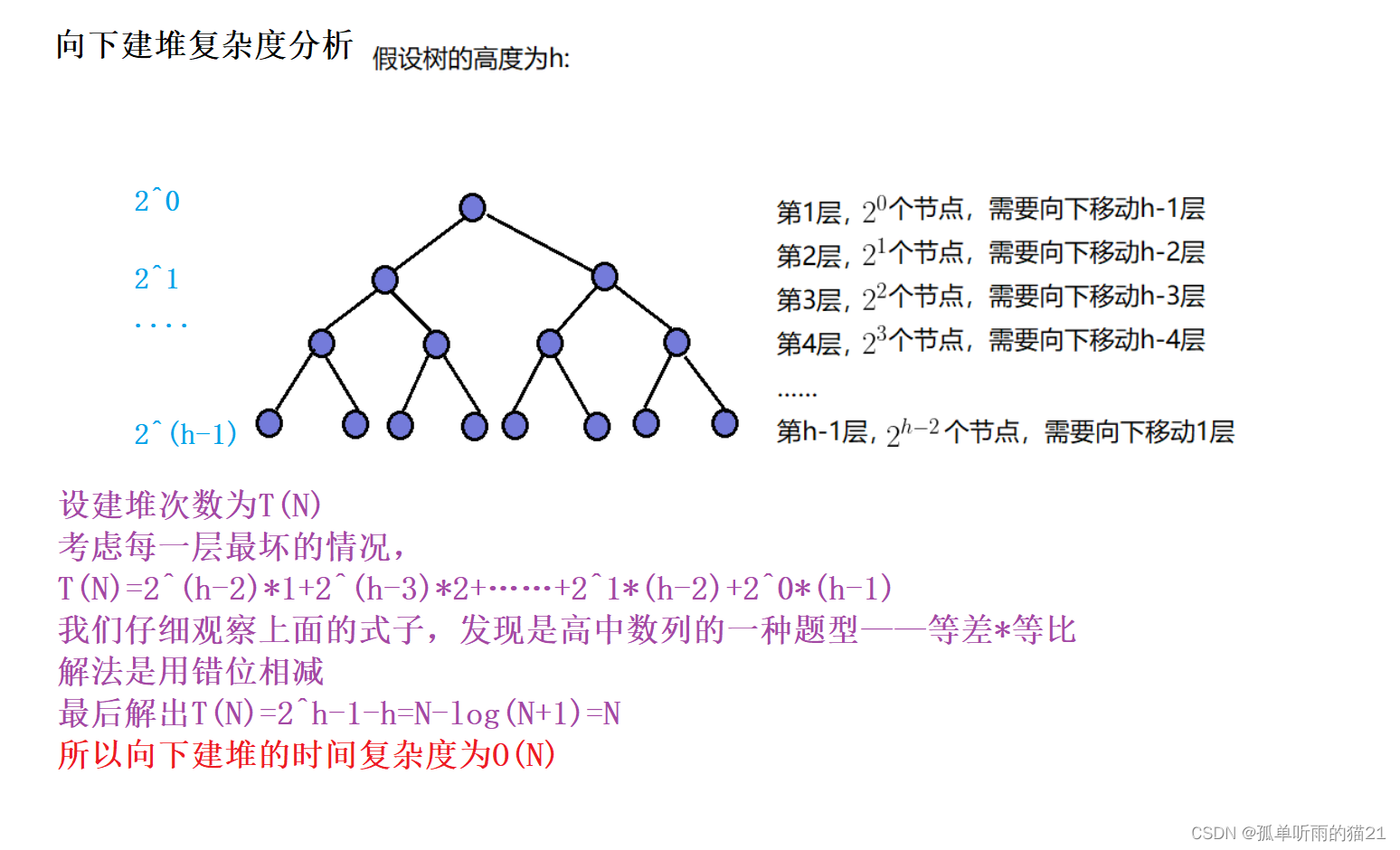
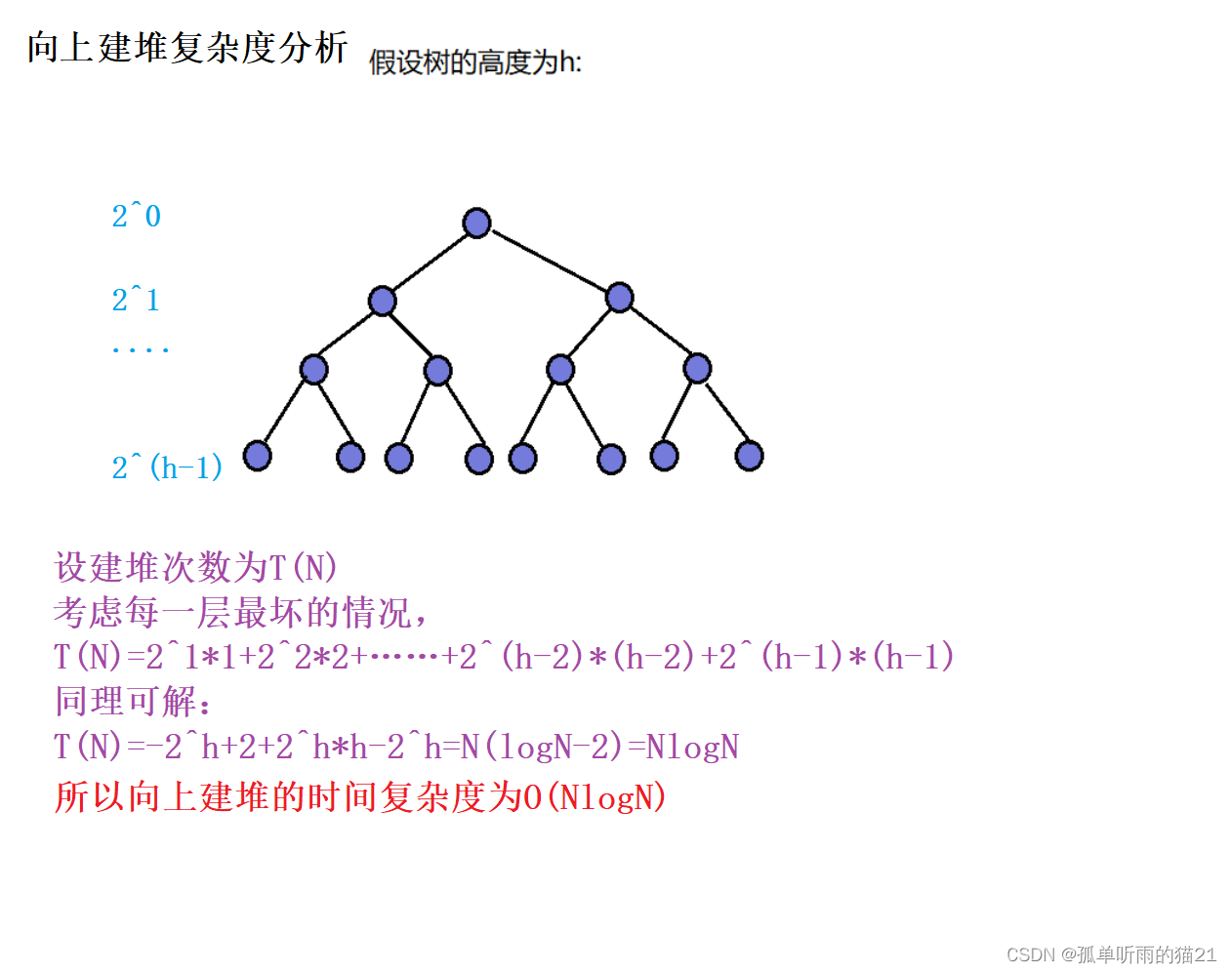
综上所得,向下建堆时间复杂度更低。即使我们不用公式去推,我们也可以直观感受到二叉树越往下的结点就越多,下面结点越多向下建堆的次数就越少,而向上建堆相反,下面越多反而向上建堆的次数就越多。相比之下,向上建堆的复杂度明显高于向下建堆。
在进行堆排序之前要思考一个问题——升序降序分别应该建什么堆?
解:假设升序建小堆,有了上述时间复杂度的分析,我们采用复杂度较低的向下建堆,并且建好堆之后,堆顶元素必然是最小的一个。如果继续使用小堆的话,从第二个数开始往后当作堆,此时堆这个结构全乱了。反之,如果采用大堆的话,就会方便很多。因此升序要建大堆。
下面进入堆排序正文部分:
1.先建好大堆:
2.核心操作:我们把第一个数和最后一个数互换位置,并且最后一个数直接丢掉,即数组下标减减。此时左右子树仍是大堆,就可以再次进行向下调整。
图解过程(注:因为是最后一个元素不看做堆里的部分,因此是倒序确定)
代码如下:
#include <stdio.h> #include <assert.h> void Swap(int* pa, int* pb) { int tmp = *pa; *pa = *pb; *pb = tmp; } void AdjustDown(int* a, int n, int parent) { int child = 2 * parent + 1; while (child < n) { if (child + 1 < n && a[child + 1] > a[child]) { ++child; } if (a[child] > a[parent])//大堆 { Swap(&a[child], &a[parent]); parent = child; child = 2 * parent + 1; } else { break; } } } //升序 void HeapSort(int* a, int n) { //向下调整建堆 for (int i = (n - 1 - 1) / 2; i >= 0; i--) { AdjustDown(a, n, i); } //大堆升序 int end = n - 1; while (end > 0) { Swap(&a[0], &a[end]); AdjustDown(a, end, 0); end--; } } int main() { int a[] = { 3,4,1,9,6,7,5,8 }; HeapSort(a, sizeof(a) / sizeof(int)); for (int i = 0; i < sizeof(a) / sizeof(int); i++) { printf("%d ", a[i]); } return 0; }输出结果:
TopK问题,顾名思义就是N个数里面找出最大/最小的前k个。通常适用于数据比较大的情况。
这里我们不妨取在10000个数里面找出最大的前10个。
对于TopK问题,通常会有以下几种方法:
1.排序:先排降序(快排),前10个就是最大的。
2.将N个数依次插入大堆,再pop个k次,每次取出栈顶元素。
相较于法一,法二似乎更优,然而这也引发了一些问题:如果N非常大,以至于远远大于k。此时法一法二就不能在用了,因为此时会导致内存不足。因此就有了法三的由来:
3. 用前k个数建立一个k个数的小堆,然后让剩下的N-K个依次遍历,如果比堆顶的数据大,就替换它进堆(向下调整),最后堆里面剩下的就是最大的前k个。
test.c
// 向下调整
void AdjustDown(int* a, int n, int parent)
{
int child = 2 * parent + 1;
while (child < n)
{
//选出左右孩子中小的那个
if (a[child + 1] < a[child])
{
++child;
}
//如果小的孩子小于父亲,则交换,并继续向下调整
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
void PrintTopK(int* a, int n, int k)
{
// 1. 建堆--用a中前k个元素建堆
int* minHeap = (int*)malloc(sizeof(int) * k);
assert(minHeap);
for (int i = 0; i < k; i++)
{
minHeap[i] = a[i];
}
// 2. 建小堆
for (int j = (k - 1 - 1) / 2; j >= 0; j--)
{
//从倒数第一个非叶结点开始
AdjustDown(a, k, j);
}
// 3. 将剩余n-k个元素依次与堆顶元素交换,不满则则替换
for (int i = k; i < n; i++)
{
if (a[i] > minHeap[0])
{
minHeap[0] = a[i];//如果比堆顶大就替换他
AdjustDown(minHeap, k, 0);// 向下调整确保为堆
}
}
for (int j = 0; j < k; j++)
{
printf("%d ", minHeap[j]);//打印
}
printf("\n");
free(minHeap);//销毁
}
void TestTopk()
{
int n = 10000;
int* a = (int*)malloc(sizeof(int) * n);
srand(time(0));
for (int i = 0; i < n; ++i)
{
a[i] = rand() % 1000000;//生成一个随机数,使其数值都小于1000000
}
a[5] = 1000000 + 1;
a[1231] = 1000000 + 2;
a[531] = 1000000 + 3;
a[5121] = 1000000 + 4;
a[115] = 1000000 + 5;
a[2335] = 1000000 + 6;
a[9999] = 1000000 + 7;
a[76] = 1000000 + 8;
a[423] = 1000000 + 9;
a[3144] = 1000000 + 10;
PrintTopK(a, n, 10);
}
int main()
{
TestTopk();
return 0;
}
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。