使用 Hadoop 实现WordCount 应用。
WordCount 是一个最简单的分布式应用实例,主要功能是统计输入目录中所有单词出现的总次数,如文本文件中有如下内容:
Hello world
则统计结果应为:
Hello 1
world 1
WordCount 可以使用多种方式实现,本次实验内容选择使用 Hadoop 实现 WordCount 程序,并完成对应实验报告。
路径:C:\Program Files\Java\jdk1.8.0_192
环境变量:HAVA_HOME,值:C:\Program Files\Java\jdk1.8.0_192
原版的Hadoop不支持Windows系统,我们需要修改一些配置方便在Windows上运行,需要从网上搜索下载hadoop对应版本的windows运行包hadooponwindows-master.zip()。解压后,复制解压开的bin文件和etc文件到hadoop-2.7.3文件中,并替换原有的bin和etc文件。
配置Java环境变量:
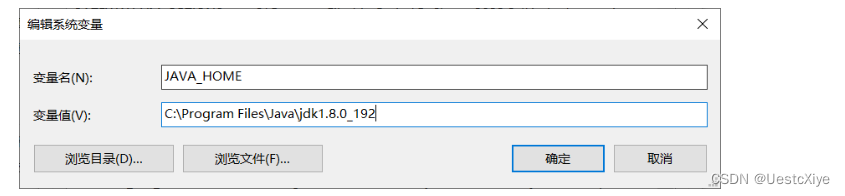
并在Path系统变量中加上:%JAVA_HOME%\bin;
配置Hadoop环境变量:
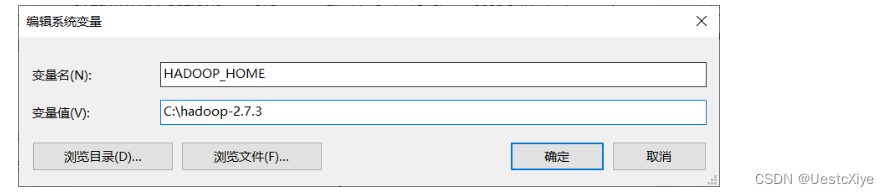
并在Path系统变量中加上:%HADOOP_HOME%\bin;
使用编辑器打开C:\hadoop-2.7.3\etc\hadoop\hadoop-env.cmd,找到set JAVA_HOME,将等号右边的值改成自己Java jdk的路径(如果路径中有Program Files,则将Program Files改为 PROGRA~1)。

配置好上面所有操作后,win+R 输入cmd 打开命令提示符,然后输入hadoop version,按回车,如果出现如图所示结果,则说明安装成功:

在hadoop-2.7.3根目录下新建data文件夹和tmp文件夹,再在data文件夹里面新建datanote和namenote文件夹:

在hadoop-2.7.3\etc\hadoop中找到以下几个文件用文本编辑器打开。
打开 hadoop-2.7.3/etc/hadoop/core-site.xml, 复制下面内容粘贴到最后并保存:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
打开hadoop-2.7.3/etc/hadoop/mapred-site.xml, 复制下面内容粘贴到最后并保存:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
打开hadoop-2.7.3/etc/hadoop/hdfs-site.xml, 复制下面内容粘贴到最后并保存:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/C:/hadoop-2.7.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/C:/hadoop-2.7.3/data/datanode</value>
</property>
</configuration>
打开hadoop-2.7.3/etc/hadoop/yarn-site.xml,复制下面内容粘贴到最后并保存:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
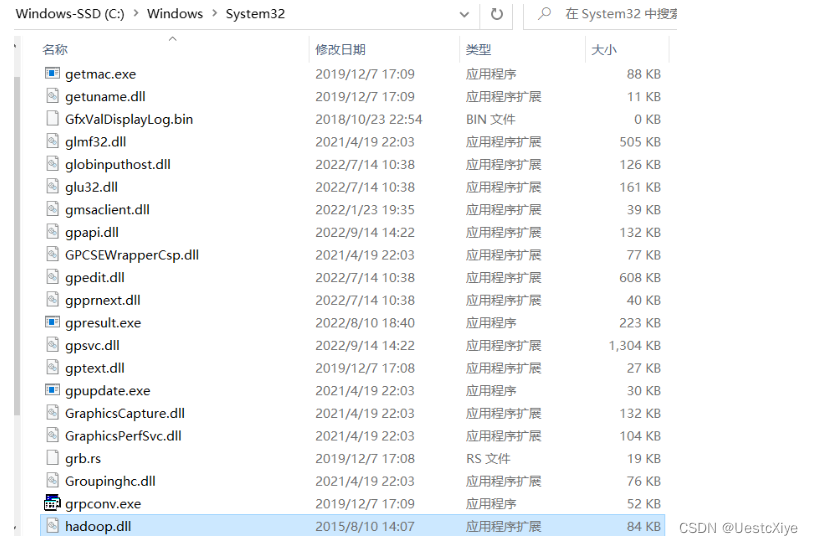
从C:\hadoop-2.7.3\bin下拷贝hadoop.dll到 C:\Windows\System32 ,不然在window平台使用MapReduce测试时报错:
到C:\hadoop-2.7.3\bin下,按下Win+R进入命令行窗口,输入hdfs namenode -format,执行结果如下图所示:
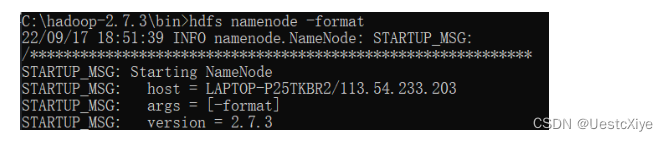
格式化之后,namenode文件夹里会自动生成一个current文件,说明格式化成功:

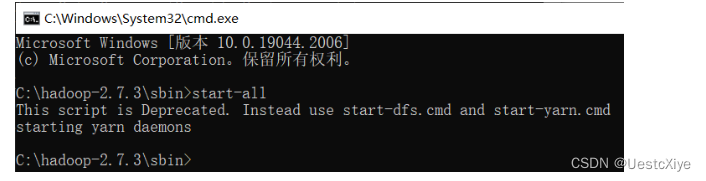
到C:\hadoop-2.7.3\sbin下,按下Win+R进入命令行窗口,输入start-all,启动Hadoop集群:
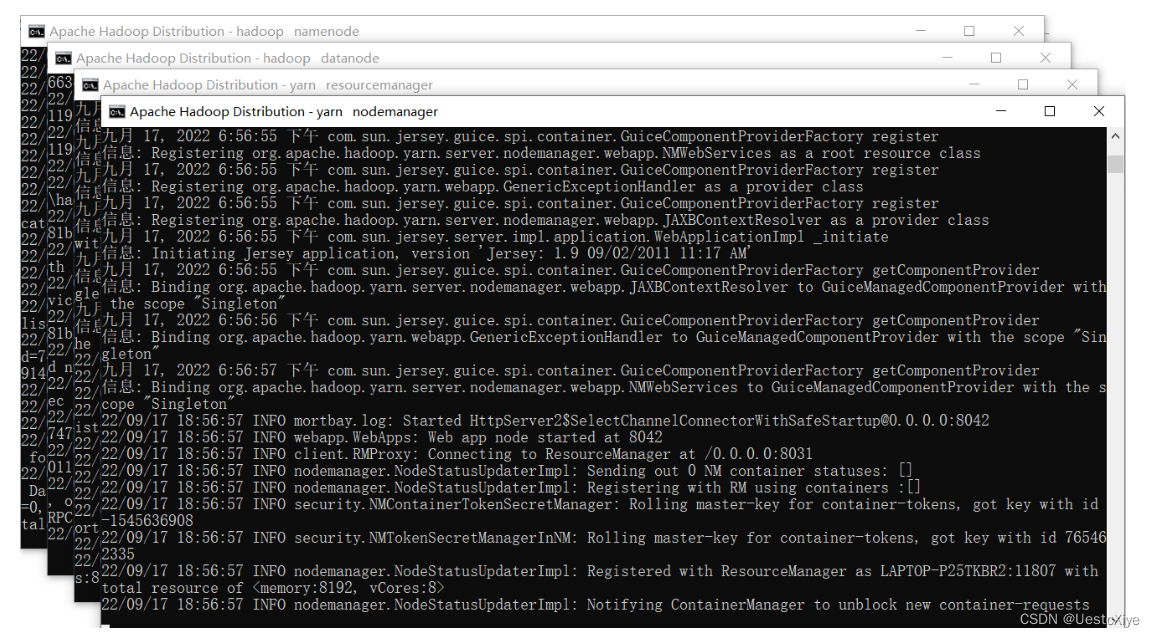
出现下面四个窗口表示启动Hadoop集群成功:
在同命令行窗口下输入start-all(或运行start-all.cmd),启动Hadoop服务,等待他启动完成。
完成之后,输入jps,可以查看运行的所有服务:

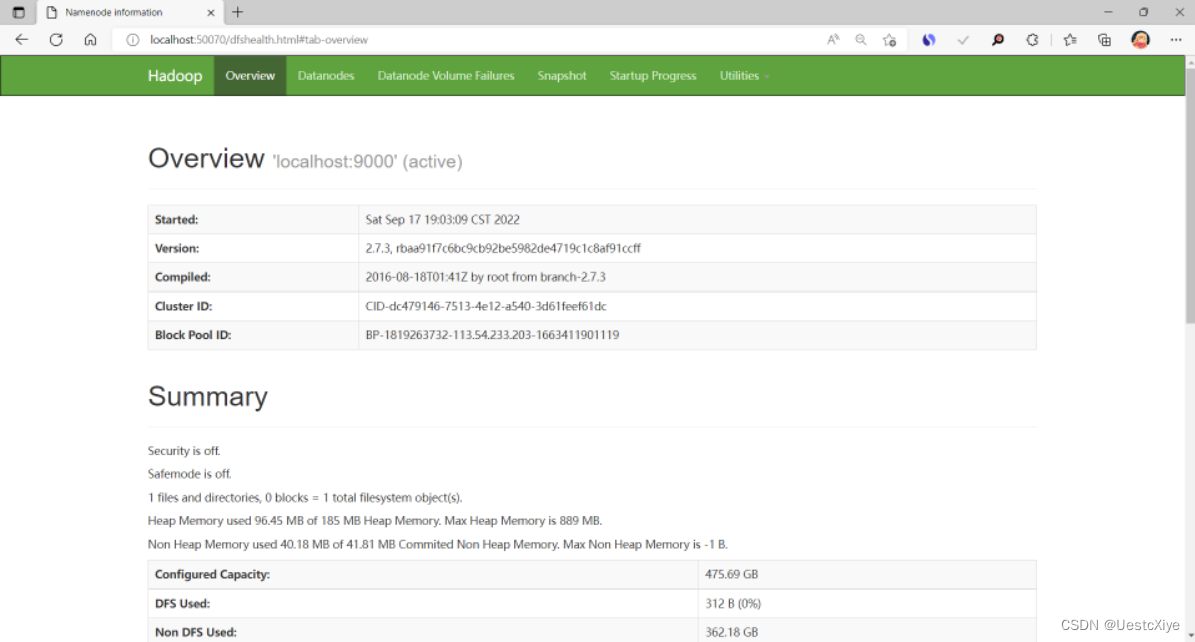
访问http://localhost:50070,这是Hadoop的管理页面:
访问http://localhost:8088,这是yarn的Web界面:
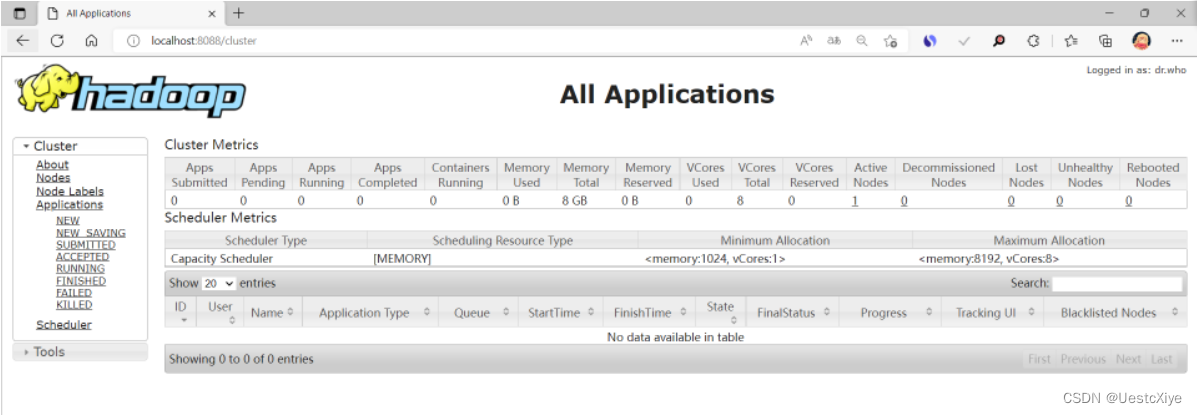
在同命令行窗口下输入stop-all(或运行stop-all.cmd),关闭Hadoop服务。
到C:\hadoop-2.7.3\sbin下,按下Win+R进入命令行窗口,输入start-all(或运行start-all.cmd),启动Hadoop服务。
按Win+R输入cmd打开命令行窗口,键入hadoop fs -mkdir /wordcount命令,在hdfs中创建一个wordcount文件夹。
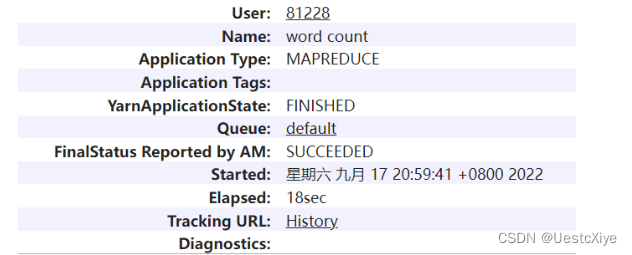
可以在http://localhost:8088/中查看。
键入hadoop fs -mkdir /wordcount/input命令,在wordcount文件夹下创建input文件夹。
再次键入hdfs dfs -ls /wordcount命令,显示wordcount文件夹里的内容:

键入hadoop fs -put C:/Users/81228/Desktop/input.txt /wordcount/input命令,将桌面的input.txt放入hdfs中的input内。
键入hdfs dfs -ls /wordcount/input命令,显示wordcount/input文件夹里的内容,可以看到input.txt已经在input中:

键入hadoop dfs -cat /wordcount/input/input.txt命令,查看上传文件中的内容:

这是taylor swift的歌——《Love Story》的歌词 😃
键入hadoop jar C:/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /wordcount/input/input.txt /wordcount/output命令,运行C:/hadoop-2.7.3/share/hadoop/mapreduce文件夹中hadoop-mapreduce-examples-2.7.3.jar这个Java程序,调用wordcount方法,输入为/wordcount/input/input.txt,输出结果存储在/wordcount/output里。以下是运行细节:

报错信息:Diagnostics: Failed to setup local dir /tmp/hadoop-81228/nm-local-dir, which was marked as good.
解决方法:使用管理员身份命令行启动Hadoop集群,然后使用普通用户身份命令行提交作业。
以管理员身份打开命令行窗口,cd定位到C:\hadoop-2.7.3\sbin下,再次启动Hadoop集群:
再次运行7中的命令,可以看到,成功运行:

键入hdfs dfs -ls /wordcount命令,显示wordcount文件夹里的内容,可以看到output文件夹:

键入hadoop dfs -cat /wordcount/output命令,output文件夹下有两个文件:

在工作的顺利完成,MapReduce的运行时创建的输出目录中的文件_SUCCESS。
键入hadoop dfs -cat /wordcount/output/part-r-00000命令,查看part-r-00000文件,里面就是我们要的结果:
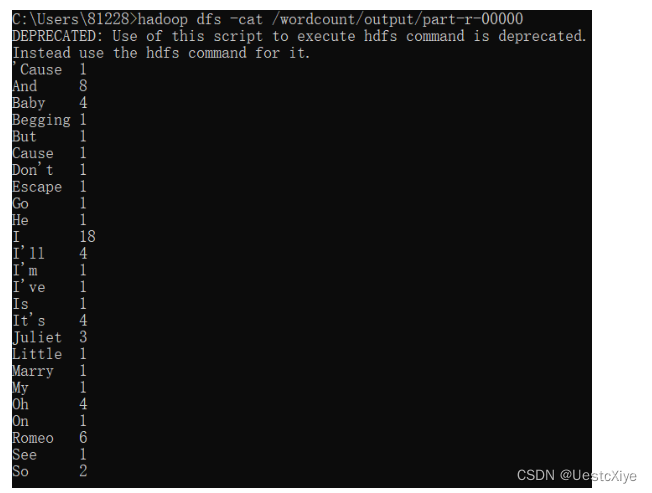
完整的MapReduce结果如下所示:
'Cause 1
And 8
Baby 4
Begging 1
But 1
Cause 1
Don't 1
Escape 1
Go 1
He 1
I 18
I'll 4
I'm 1
I've 1
Is 1
It's 4
Juliet 3
Little 1
Marry 1
My 1
Oh 4
On 1
Romeo 6
See 1
So 2
That 1
They're 1
This 1
We 2
When 1
Wondering 1
You'll 2
a 9
afraid 1
air 1
all 3
alone 4
and 5
around 1
away 2
balcony 1
ball 1
be 10
been 1
begging 1
both 2
but 2
can 2
cause 1
close 2
come 1
coming 1
crowd 1
crying 1
dad 1
daddy 2
dead 1
did 1
difficult 1
do 2
don't 3
dress 1
ever 1
everything 1
eyes 2
fading 1
faith 1
feel 1
feeling 1
first 2
flashback 1
for 2
from 2
garden 1
go 2
got 1
gowns 1
ground 1
have 1
head 1
hello 1
how 1
if 2
in 3
is 3
it 1
it's 1
just 4
keep 2
knelt 1
knew 1
know 3
left 2
letter 1
lights 1
little 1
love 6
make 2
me 7
mess 1
met 1
my 4
never 2
of 3
oh 7
on 2
out 4
outskirts 1
party 1
pebbles 1
pick 1
please 2
prince 2
princess 2
pulled 1
quiet 1
real 1
really 1
ring 1
run 2
said 6
save 2
saw 2
say 5
scarlet 1
see 3
sneak 1
so 1
somewhere 2
staircase 1
standing 1
starts 1
stay 2
story 4
summer 1
take 2
talked 1
tell 1
that's 1
the 13
there 1
there's 2
they 1
think 1
this 3
through 1
throwing 1
tired 1
to 11
town 2
trying 1
waiting 4
was 4
way 1
we 3
we'll 1
we're 1
were 7
what 1
when 2
while 1
white 1
yes 4
you 16
you'll 1
young 2
your 3
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h