AVFrame结构体一般用于存储原始数据(即非压缩数据,例如对视频来说是YUV,RGB,对音频来说是PCM),此外还包含了一些相关的信息。
比如说,解码的时候存储了宏块类型表,QP表,运动矢量表等数据。编码的时候也存储了相关的数据。因此在使用FFMPEG进行码流分析的时候,AVFrame是一个很重要的结构体。
AVFramet通常在解码时包含较多的码流参数,编码时主要用于承载图像数据或者音频采样数据。结构体的定义位于libavutil/frame.h,这里介绍解码情况下的主要变量

①uint8_t *data[AV_NUM_DATA_POINTERS];
(1)图像数据:
对于packed格式的数据(例如RGB24),会存到data[0]里面。
对于planar格式的数据(例如YUV420P),则会分开成data[0],data[1],data[2]…(YUV420P中data[0]存Y,data[1]存U,data[2]存V)
(2)音频数据:
采样数据PCM, 保存方式同图像数据。 对于对于planar格式的音频数据通道数超过8时,其余通道数据存放于extended_data中。
②int linesize[AV_NUM_DATA_POINTERS];
行字节的跨度,相当于stride。对于data[i]区域中的一行像素占用的字节数,对于RGB24理论是{wh3, 0, …}; 对于yuv420p,理论是{w, w/2, w/2, 0, …}。但ffmpeg内存会填充对齐,实际行字节数会大于等于理论值。
③enum AVPictureType pict_type;
帧数据类型,部分摘取如下

1、av_frame_alloc()
申请AVFrame结构体空间,同时会对申请的结构体初始化。注意哦,这个函数只是创建AVFrame结构的空间,AVFrame中的uint8_t *data[AV_NUM_DATA_POINTERS]空间此时NULL,不会创建的。
2、av_frame_free()
释放AVFrame的结构体空间。这个函数就有点意思了。因为他不仅仅释放结构体空间,还涉及到AVFrame中的uint8_t *data[AV_NUM_DATA_POINTERS];字段的释放问题。,如果AVFrame中的uint8_t *data[AV_NUM_DATA_POINTERS]中的引用==1,则释放data的空间。
3、int av_frame_ref(AVFrame *dst, const AVFrame *src)
对已有AVFrame的引用,这个引用做了两个动作:1、将src属性内容复制到dst,2、对AVFrame中的uint8_t *data[AV_NUM_DATA_POINTERS]字段引用计数+1。
4、void av_frame_unref(AVFrame *frame)
对frame释放引用,做了两个动作:1、将frame的各个属性初始化,2、如果AVFrame中的uint8_t *data[AV_NUM_DATA_POINTERS]中的引用==1,则释放data的空间。当然,如果data的引用计数>1则由别的frame去检测释放。
5、av_frame_get_buffer()
这个函数是建立AVFrame中的uint8_t *data[AV_NUM_DATA_POINTERS]内存空间,使用这个函数之前frame结构中的format、width、height:必须赋值,要不然函数怎么知道创建多少字节的空间呢!
3个步骤:
①AVFrame *pFrame = av_frame_alloc()分配一个AVFrame对象,缓冲区data[]未分配。
②使用调用av_receive_frame解码,会对pFrame分配data[]缓冲区并保存解码数据;每一次使用后,必须需要使用av_frame_unref释放缓冲区,否则重复解码会造成内存泄露。
③需要使用av_frame_free 释放整个对象。
AVFrame *pFrame = av_frame_alloc(); // [1]
while(){
…
av_receive_frame(ctx, pFrame);
… // process
av_frame_unref(pFrame); // [2]
}
av_frame_free(pFrame); // [3]
前面提到,ffmpeg内部编码器对于图像处理部分为了方便优化处理,通常创建的缓冲区比原始图像大,实际有效数据部分只是缓冲区的一部分。这一种优化方案直接反应在linesize上,使用8或16或32字节对齐,取决于平台。
对于分辨率为638*272的视频解码后yuv420p的缓冲区 linsesize为{640,320,320,…},内存布局结构如下图
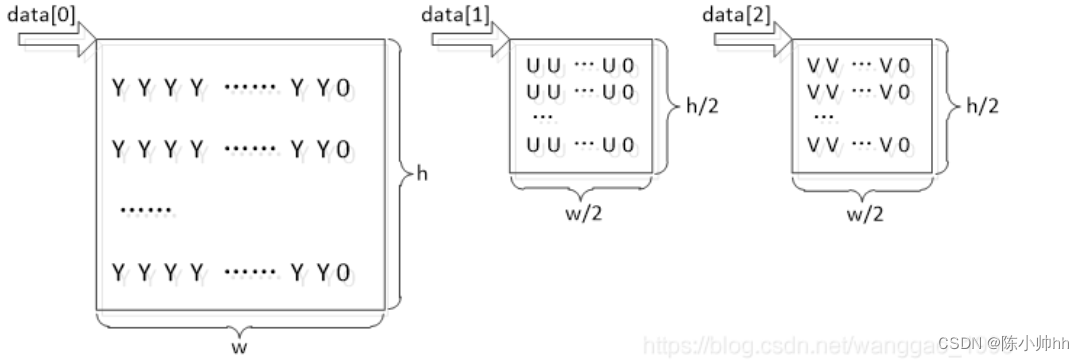
图中,其中w = 640 , h = 320。可以看到,在三个通道中每一行数据间进行了数据填充,Y区域的行字节数不等于638,U/V区域的行字节数也不等于319。注意观察data[2],data[1],data[0]之间的差值。
如果我们需要yuv三个分量无填充的 yuv420p数据,可以手动分配大小为wh3/2的内存,再从解码后AVFrame的data[]中拷贝出来。
①方法一:使用malloc原生的内存管理方式,
uint8_t yuv_buf = malloc(w*h*3/2);
②方法二:fmpeg内存分配函数
// yuv420p对齐处理 变量
AVFrame *frame_yuv = av_frame_alloc();
// 分配缓冲区,接收转换后yuv420p的1字节对齐数据,分辨率不改变
av_image_alloc(frame_yuv->data, frame_yuv->linesize,
video_decoder_ctx->width, video_decoder_ctx->height, AV_PIX_FMT_YUV420P, 1);
// 对于编码,需要AVFrame有对应的参数
frame_yuv->width = video_decoder_ctx->width;
frame_yuv->height = video_decoder_ctx->height;
frame_yuv->format = AV_PIX_FMT_YUV420P;
③方法三:原生指针加ffmpeg内存分配函数
uint8_t *yuvbuf;
int linesize[4];
av_image_alloc(&yuvbuf, linesize, video_decoder_ctx->width, video_decoder_ctx->height,
AV_PIX_FMT_YUV420P, 1);
④方法四:使用av_frame_get_buffer函数(注意检查内存是否连续)
AVFrame *frame_yuv = av_frame_alloc();
frame_yuv->width = video_decoder_ctx->width;
frame_yuv->height = video_decoder_ctx->height;
frame_yuv->format = AV_PIX_FMT_YUV420P;
// 使用一下函数必须先指定frame的 音频/视频 参数
av_frame_get_buffer(frame_yuv, 1); // align = 0, 由系统选择最优对齐方式
注意,av_frame_get_buffer(frame_yuv, 1); 保证y,u,v分量数据区域是1字节对齐的、连续的,但是y,u,v三个数据区不是1字节对齐、也不是连续的。例如,手动分配100*100尺寸的yuv420的数据分量部分
AVFrame *frame_yuv = av_frame_alloc();
frame_yuv->width = 100;
frame_yuv->height = 100;
frame_yuv->format = AV_PIX_FMT_YUV420P;
av_frame_get_buffer(frame_yuv, 1);
结果如下图,三个分量数据区指针从小到大为 u < y < v,指针之间的间隔不等于wh,也不等于wh/2。
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
我正在尝试学习Ruby词法分析器和解析器(whitequarkparser)以了解更多有关从Ruby脚本进一步生成机器代码的过程。在解析以下Ruby代码字符串时。defadd(a,b)returna+bendputsadd1,2它导致以下S表达式符号。s(:begin,s(:def,:add,s(:args,s(:arg,:a),s(:arg,:b)),s(:return,s(:send,s(:lvar,:a),:+,s(:lvar,:b)))),s(:send,nil,:puts,s(:send,nil,:add,s(:int,1),s(:int,3))))任何人都可以向我解释生成的
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
下面的代码工作正常:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson)do|key,oldv,newv|ifkey==:aoldvelsifkey==:bnewvelsekeyendendputskerson.inspect但是如果我在“ifblock”中添加return,我会得到一个错误:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化
我定义了一个方法:defmethod(one:1,two:2)[one,two]end当我这样调用它时:methodone:'one',three:'three'我得到:ArgumentError:unknownkeyword:three我不想从散列中一个一个地提取所需的键或排除额外的键。除了像这样定义方法之外,有没有办法规避这种行为:defmethod(one:1,two:2,**other)[one,two,other]end 最佳答案 如果不想写**other中的other,可以省略。defmethod(one:1,two:2