文章目录
Redis持久化提供:RDB、AOF两种方式
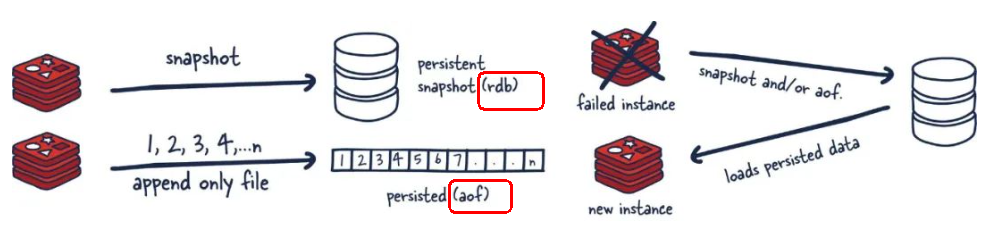
RDB 持久性以指定的时间间隔执行数据集的时间点快照
实现类似照片记录效果的方式,就是把某一时刻的数据和状态以文件的形式写到磁盘上,也就是快照。这样一来即使故障宕机,快照文件也不会丢失,数据的可靠性也就得到了保证。
这个快照文件就称为RDB文件(dump.rdb),其中,RDB就是Redis DataBase的缩写。
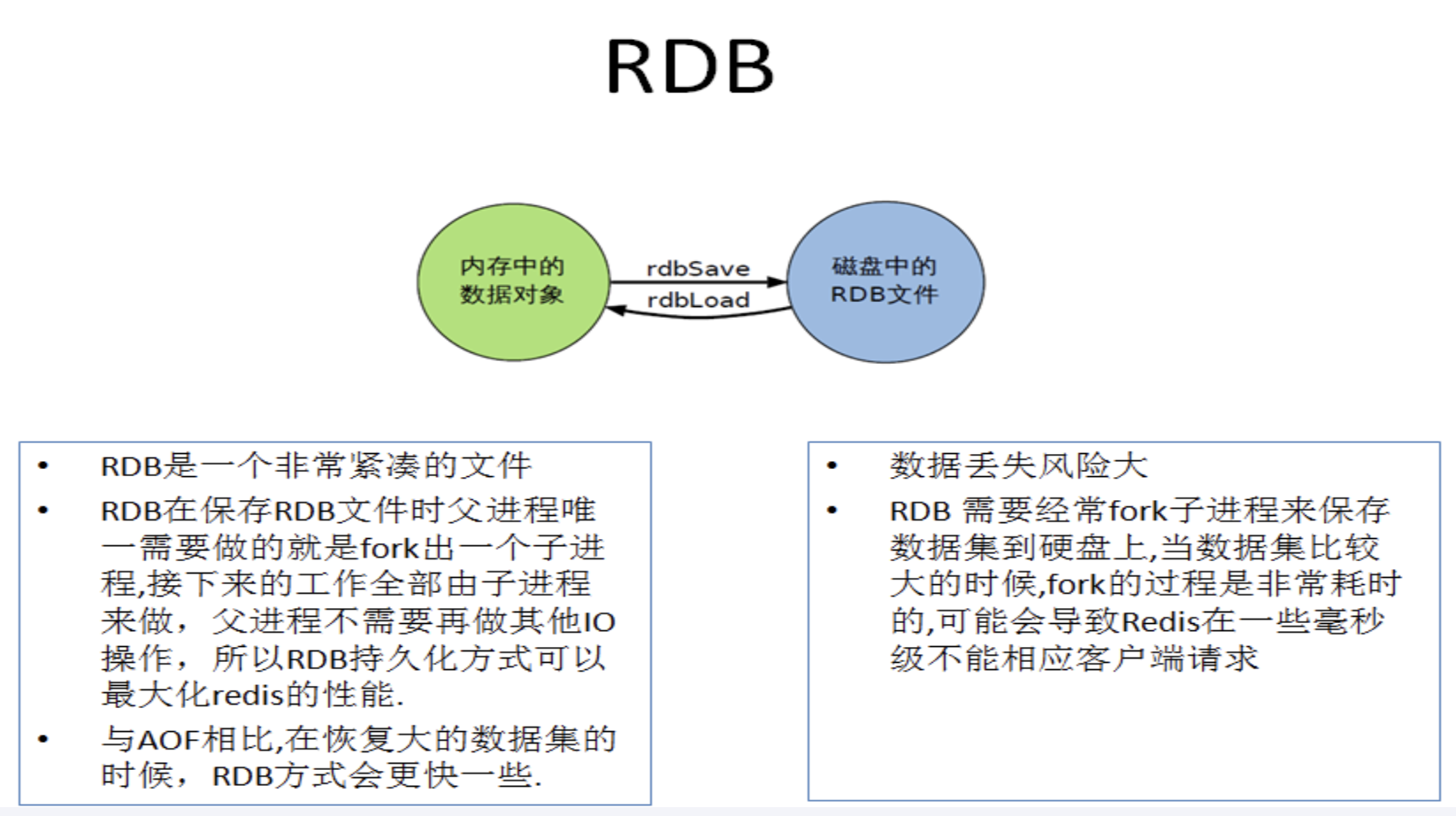
在指定的时间间隔内将内存中的数据集快照写入磁盘也就是行话讲的Snapshot内存快照,它恢复时再将硬盘快照文件直接读回到内存里
Redis的数据都在内存中,保存备份时它执行的是全量快照也就是说,把内存中的所有数据都记录到磁盘中,一锅端
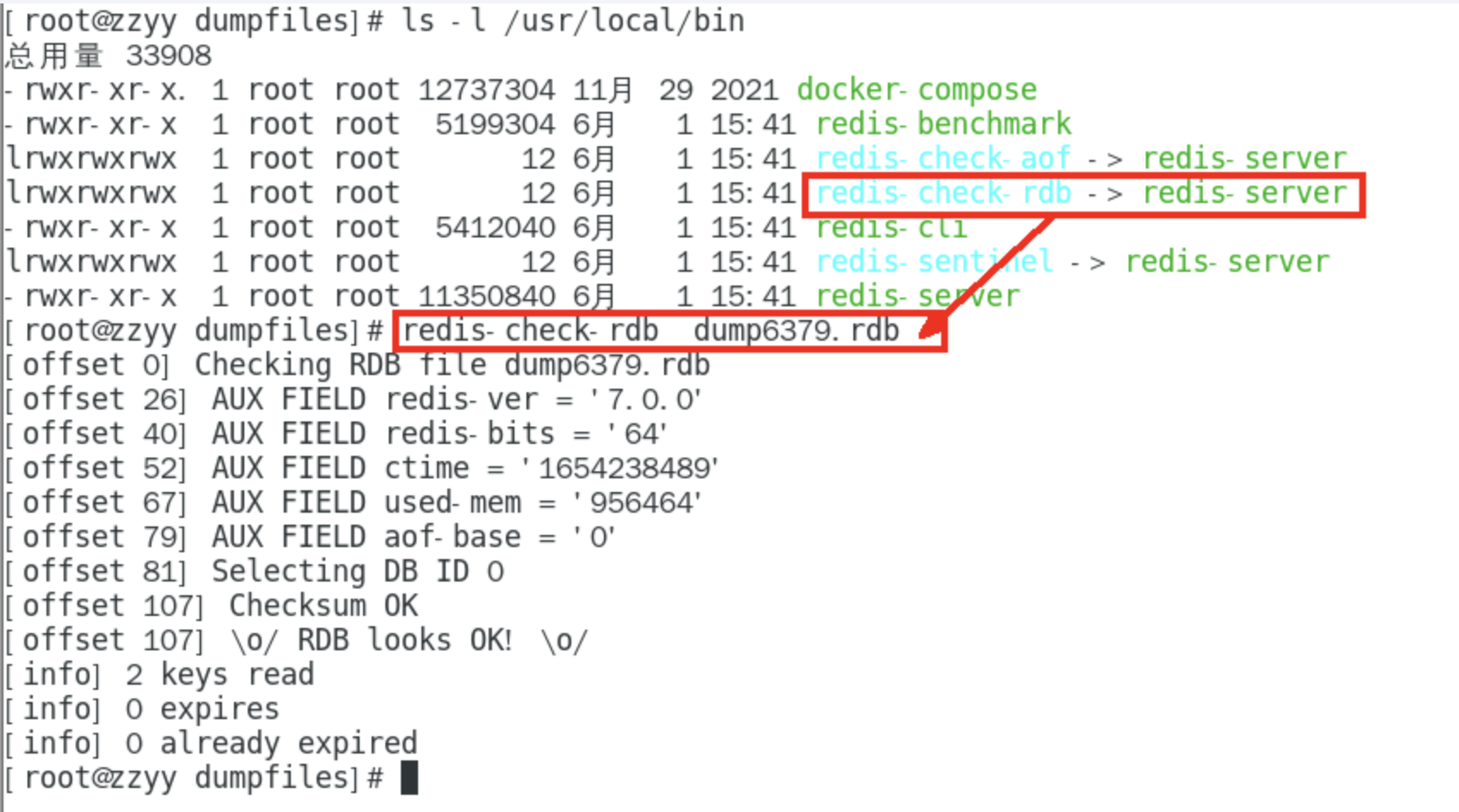
Rdb保存的是dump.rdb文件
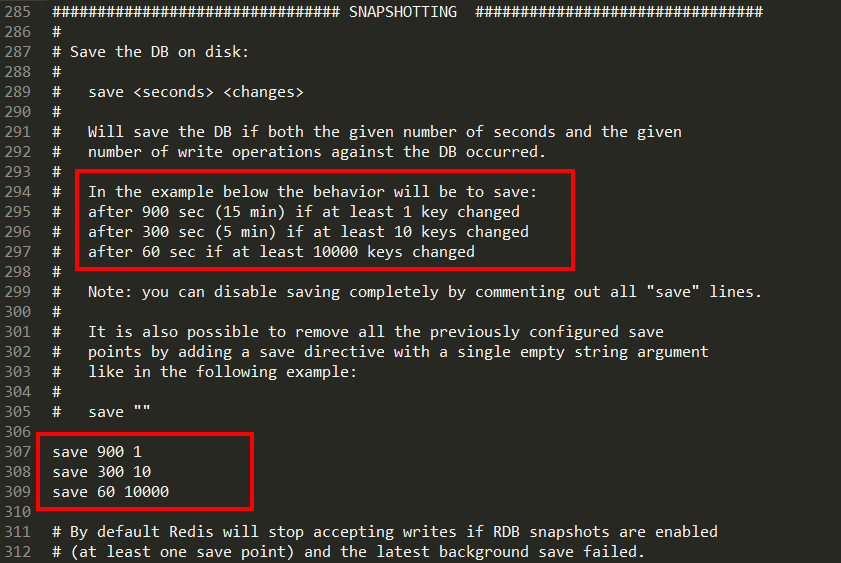
Redis6.0.16及以下

Redis6.0.16以上
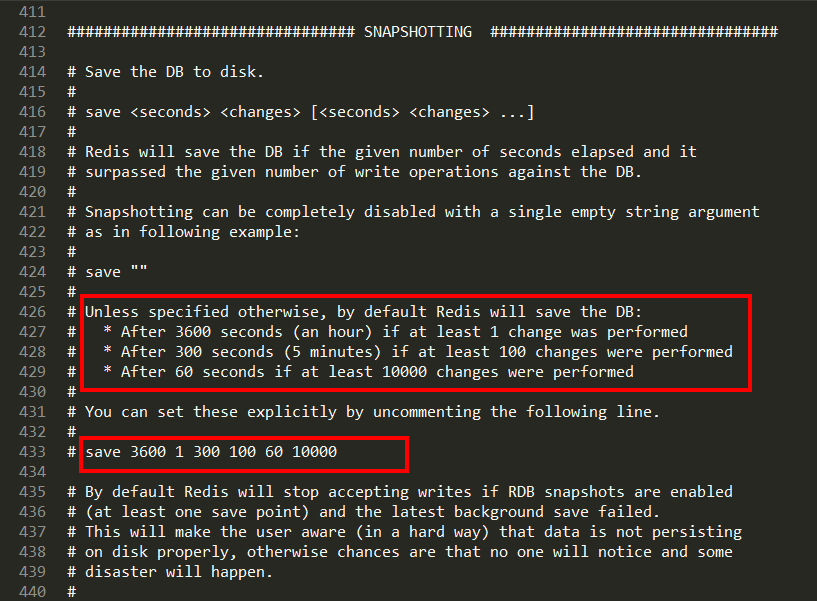
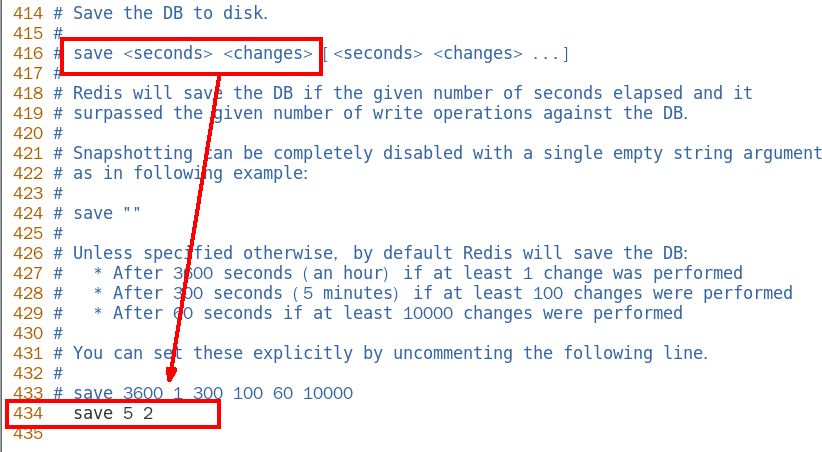
通过修改配置文件:5秒内修改两次即触发
修改保存路径
修改保存文件名称

测试:在redis里面命令
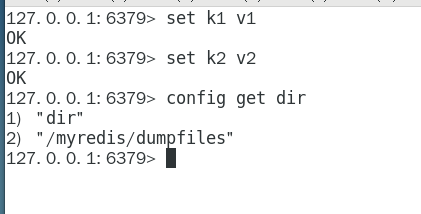
config get dir即可查看

如何通过dump.rdb文件恢复数据
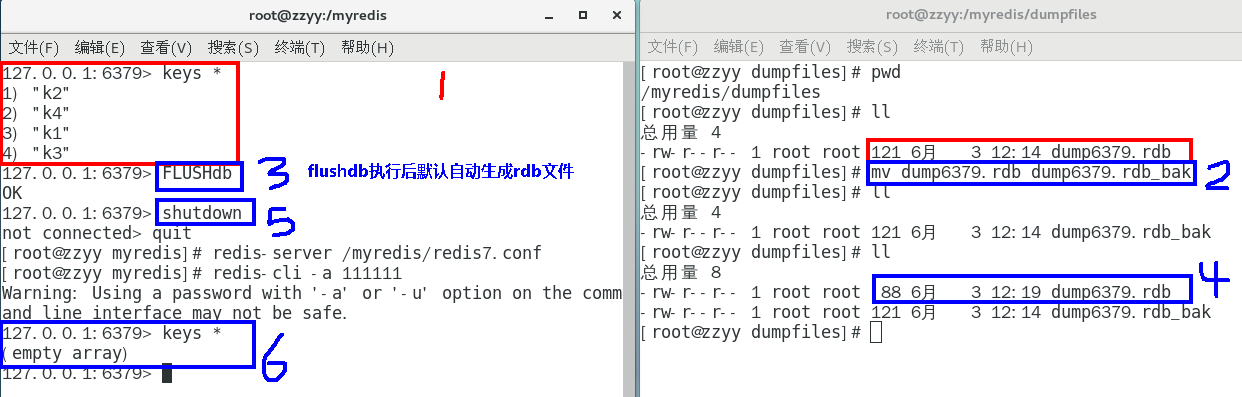
将备份文件 (dump.rdb)移动到 redis 安装目录并启动服务即可
注意
不可以把备份文件dump.rdb和生产redis服务器放在同一台机器,必须分开各自存储,以防生产机物理损坏后备份文件也挂了。
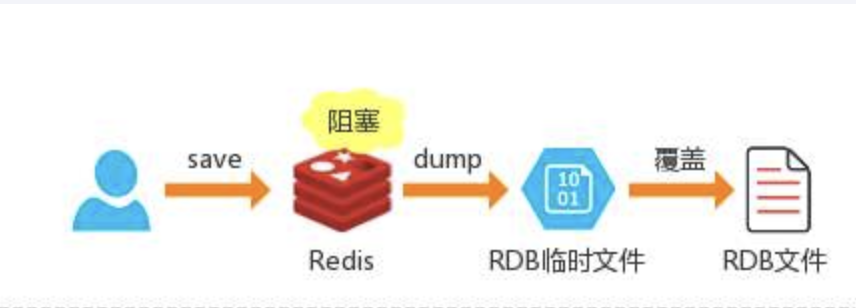
Redis提供了两个命令来生成RDB文件分别是save和bgsave(不阻塞,后端执行)
Save
在主程序中执行会阻塞当前redis服务器,直到持久化工作完成;线上禁止使用执行save命令期间,Redis不能处理其他命令
案例

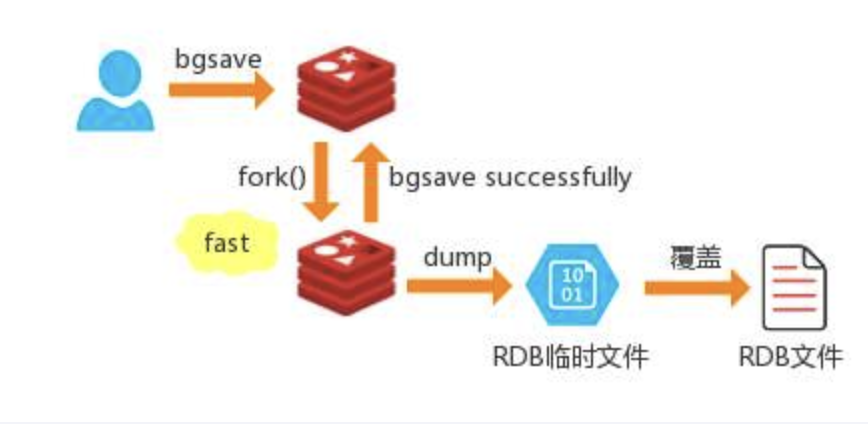
BGSAVE(默认)
Redis会在后台异步进行快照操作,不阻塞快照同时还可以响应客户端请求,该触发方式会fork一个子进程由子进程复制持久化过程。
Redis会使用bgsave对当前内存中的所有数据做快照这个操作是子进程在后台完成的,这就允许主进程同时可以修改数据
fork是什么?
案例
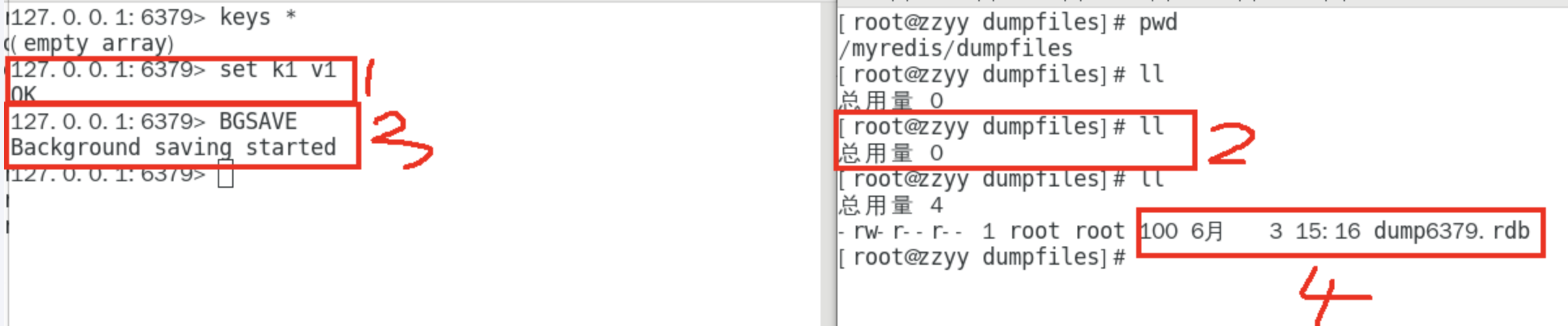
LASTSAVE
可以通过lastsave命令获取最后一次成功执行快照的时间
案例




数据丢失案例
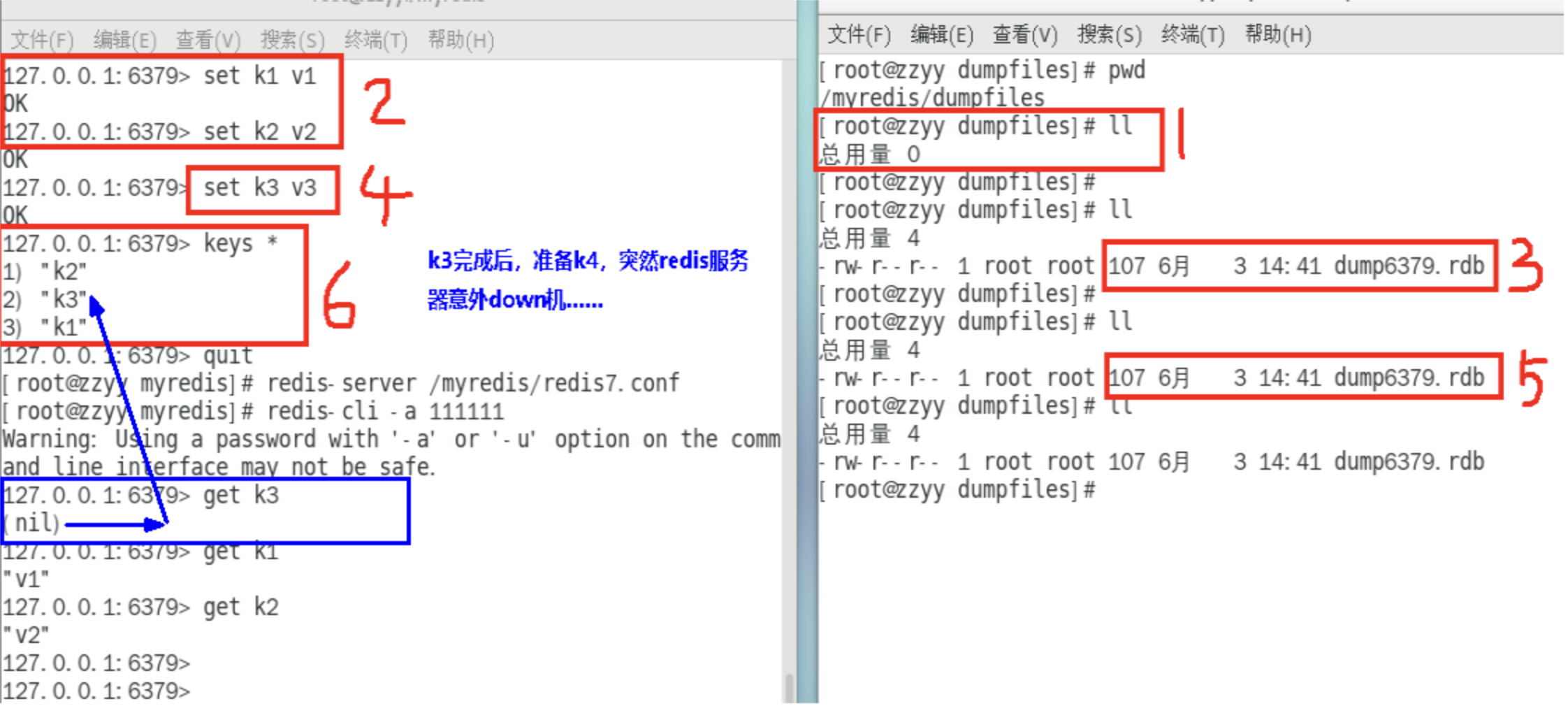
动态所有停止RDB保存规则的方法: redis-cli config set save
快照禁用
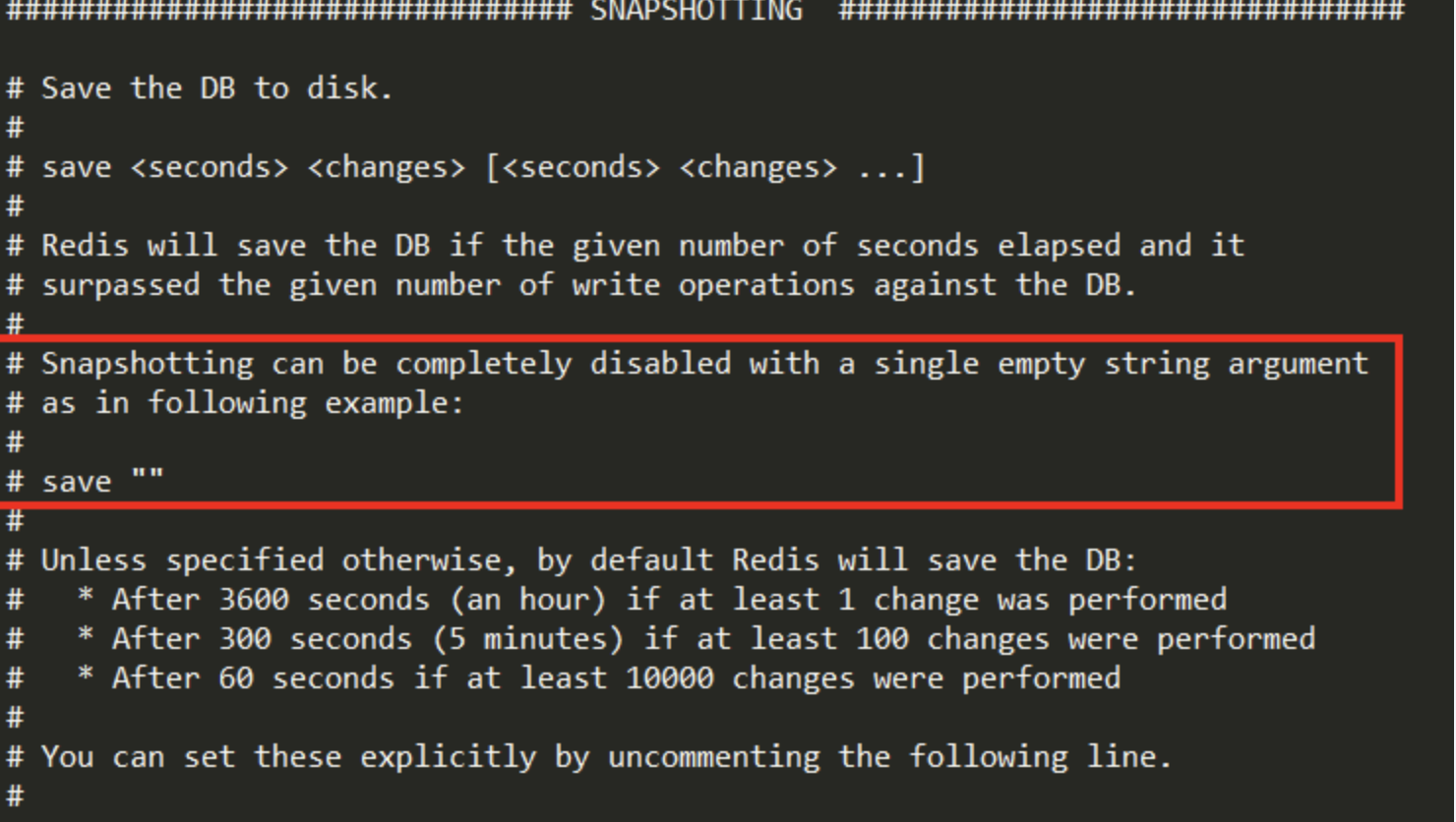
save <seconds> <changes>
dbfilename
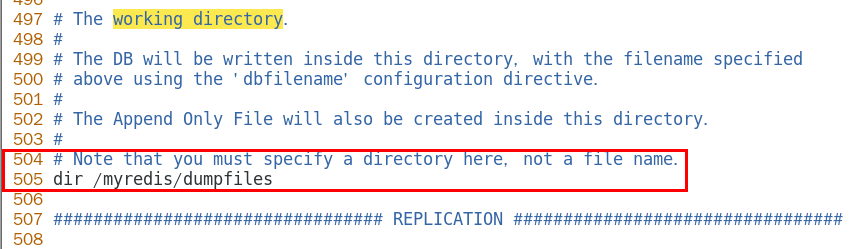
dir
stop-writes-on-bgsave-error
默认yes。如果配置成no,表示你不在乎数据不一致或者有其他的手段发现和控制这种不一致,那么在快照写入失败时,也能确保redis继续接受新的写请求
rdbcompression
默认yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。
如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能
rdbchecksum
默认yes。在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
rdb-del-sync-files
默认情况下no,此选项是禁用的。rdb-del-sync-files:在没有持久性的情况下删除复制中使用的RDB文件启用
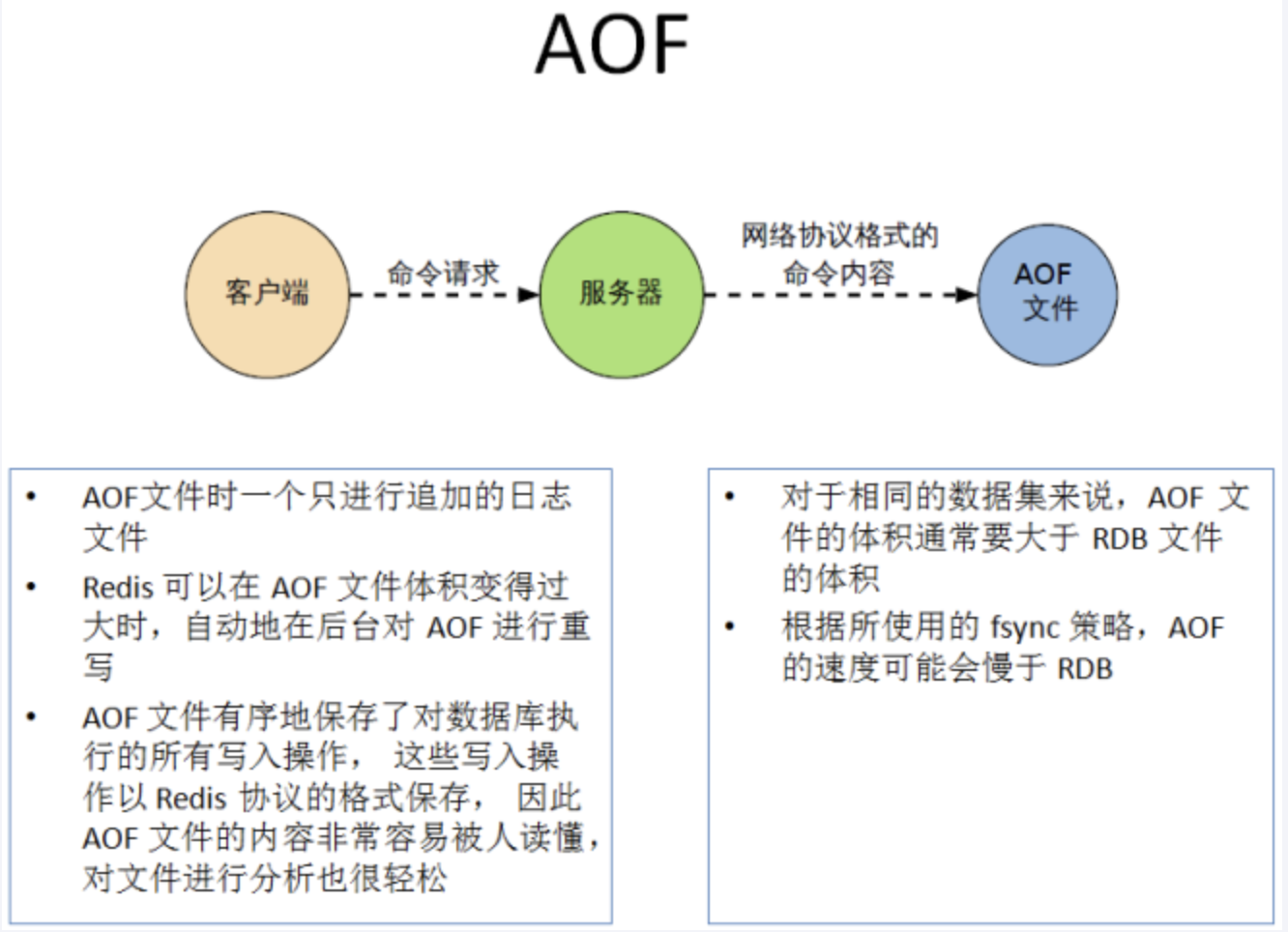
以日志的形式来记录每个写操作,将Redis执行过的所有**写指令记录下来(读操作不记录)**只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据。
换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
默认情况下,redis是没有开启AOF(append only file)的。开启AOF功能需要设置配置:
appendonly yes
Aof保存的是
appendonly.aof文件
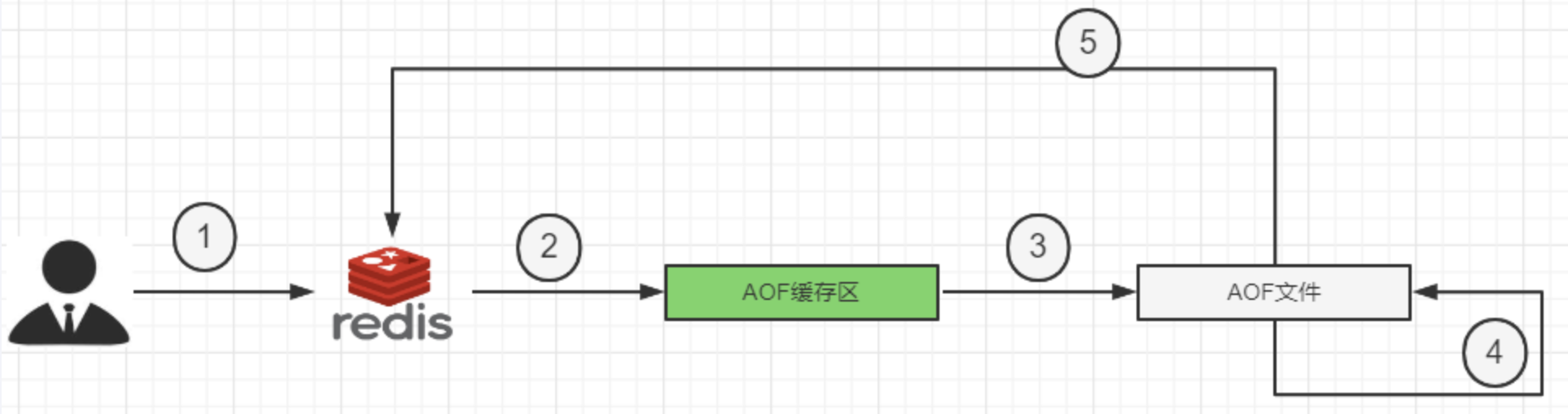
| 1 | Client作为命令的来源,会有多个源头以及源源不断的请求命令。 |
|---|---|
| 2 | 在这些命令到达Redis Server 以后并不是直接写入AOF文件,会将其这些命令先放入AOF缓存中进行保存。这里的AOF缓冲区实际上是内存中的一片区域,存在的目的是当这些命令达到一定量以后再写入磁盘,避免频繁的磁盘IO操作。 |
| 3 | AOF缓冲会根据AOF缓冲区同步文件的三种写回策略将命令写入磁盘上的AOF文件。 |
| 4 | 随着写入AOF内容的增加为避免文件膨胀,会根据规则进行命令的合并(又称AOF重写),从而起到AOF文件压缩的目的。 |
| 5 | 当Redis Server服务器重启的时候会从AOF文件载入数据。 |
Always
同步写回,每个写命令执行完立刻同步地将日志写回磁盘
everysec(默认的)
每秒写回,每个写命令执行完。只是先把日志写到AOF文件的内存缓冲区,每隔1秒把缓冲区中的内容写入磁盘
no
操作系统控制的写回,每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘

开启aof

使用默认写回策略

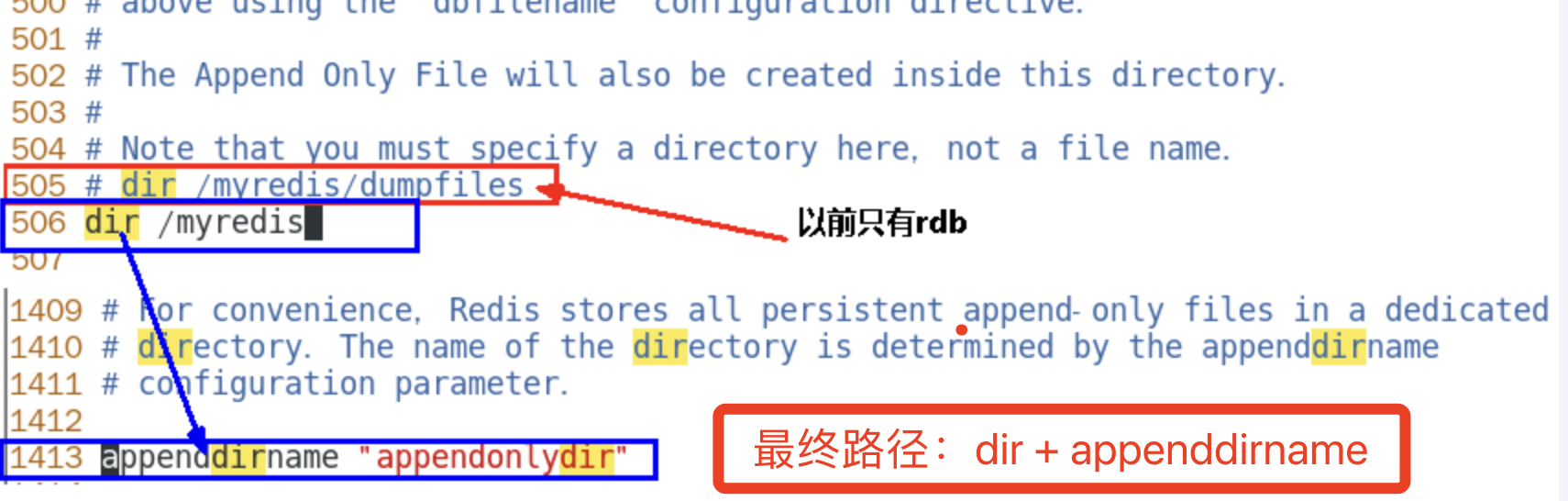
aof文件-保存路径
Redis6
AOF保存文件的位置和RDB保存文件的位置一样都是通过redis.conf配置文件的 dir配置

Redis7
新添了
appenddirname "appendonlydir"
aof文件-保存名称
Redis6
appendfilename 有且仅有一个

Redis7
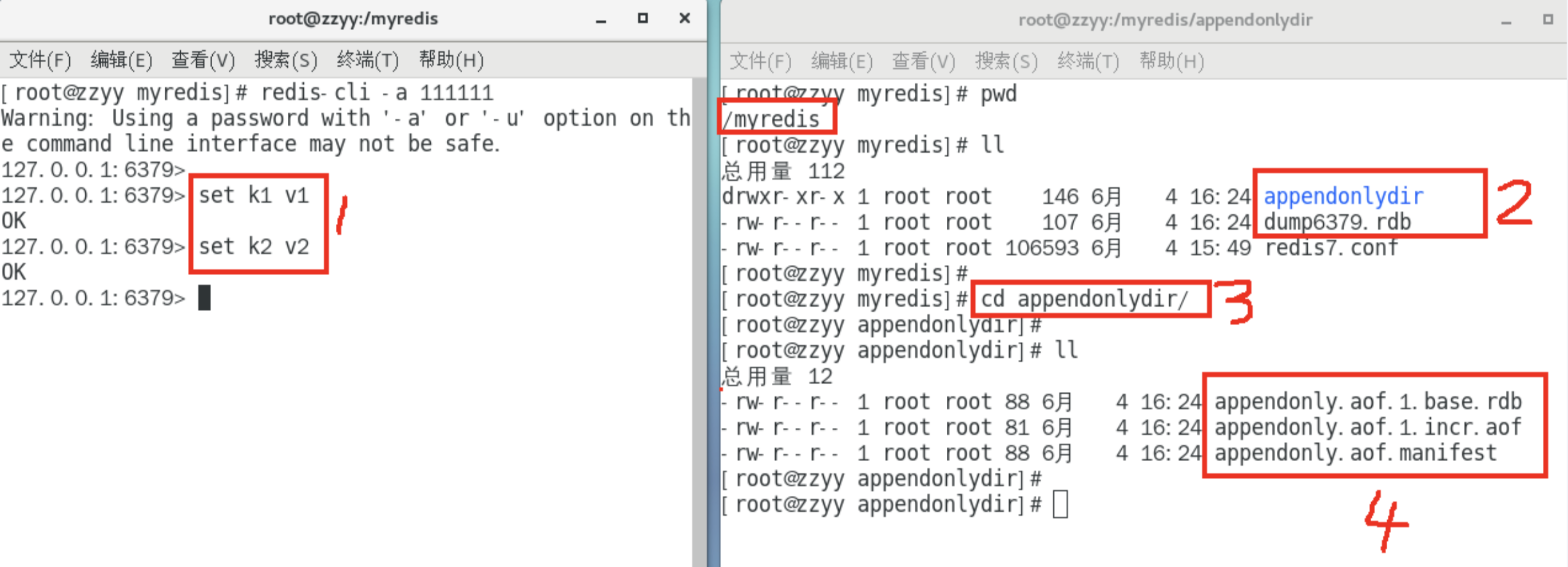
Redis7.0 Multi Part AOF的设计
- base基本文件
- incr增量文件
- manifest清单文件


配置文件表现上

写入aof文件
数据恢复

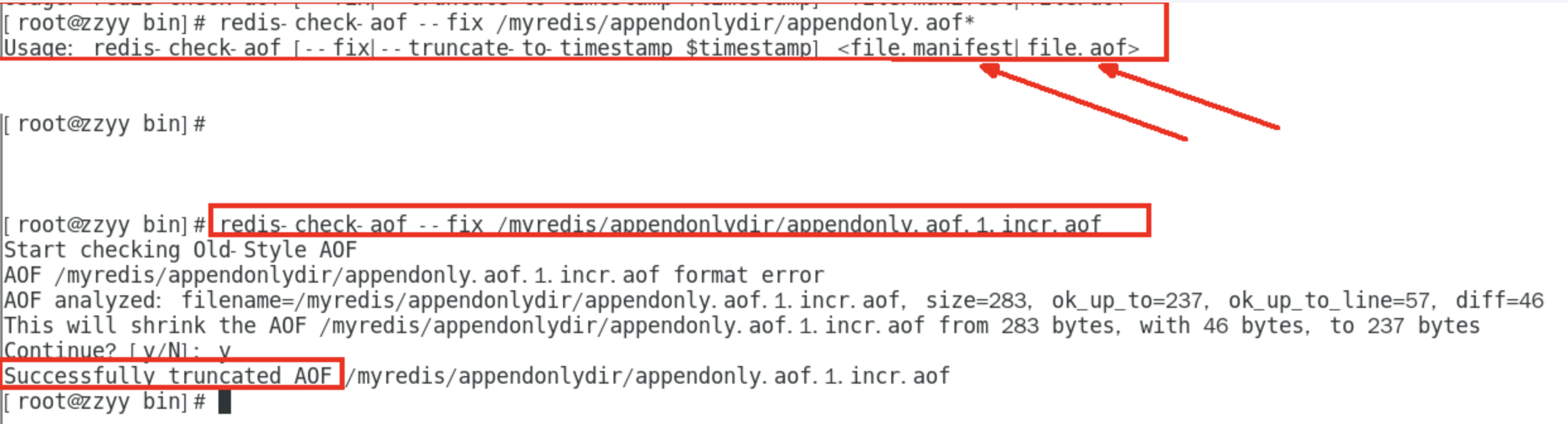
异常情况恢复
appendonly.aof.1.incr.aof文件内容异常redis-check-aof --fix进行修复

更好的保护数据不丢失 、性能高、可做紧急恢复

相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb
aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同

由于AOF持久化是Redis不断将写命令记录到 AOF 文件中,随着Redis不断的进行,AOF 的文件会越来越大,文件越大,占用服务器内存越大以及 AOF 恢复要求时间越长。
为了解决这个问题,Redis新增了重写机制,当AOF文件的大小超过所设定的峰值时,Redis就会自动启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集或者可以手动使用命令bgrewriteaof来重写。
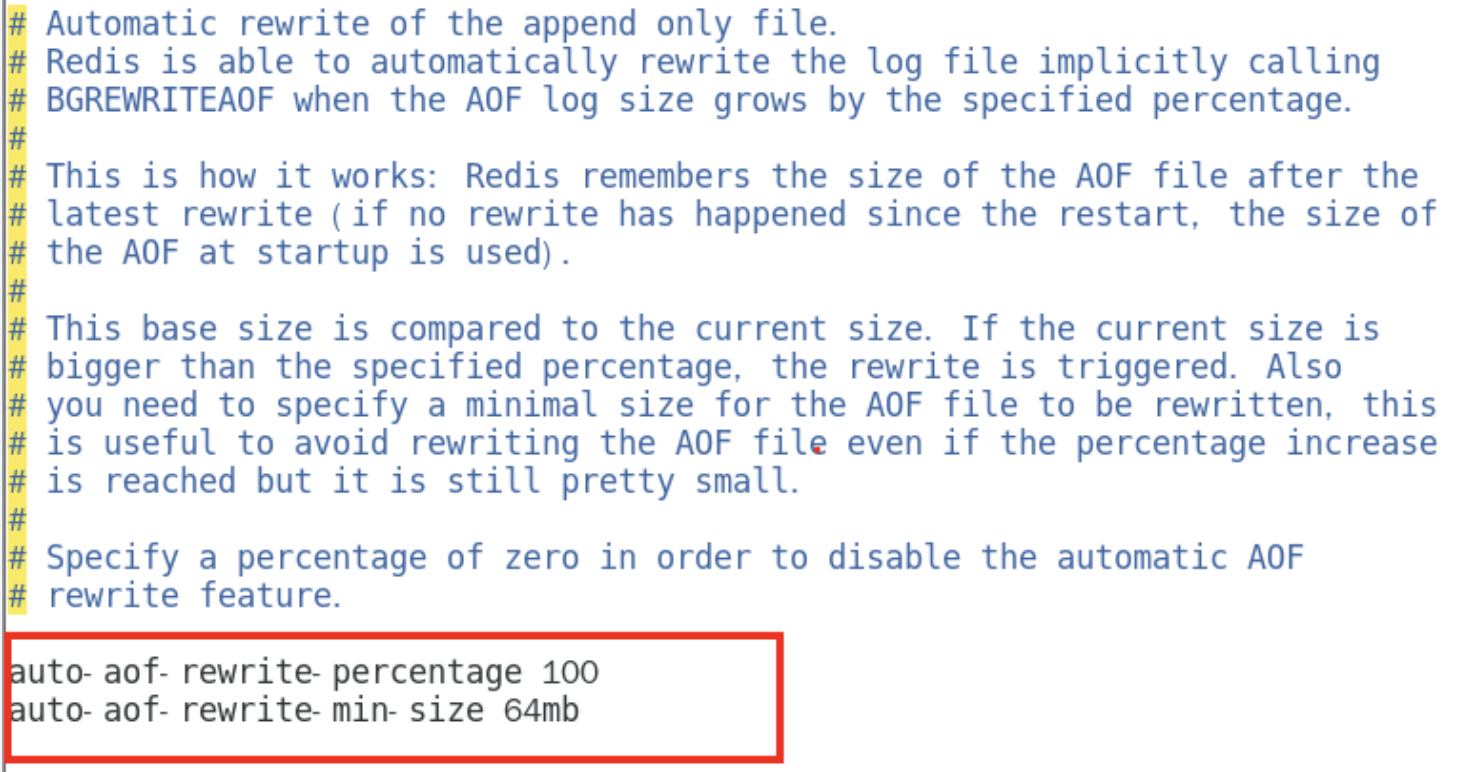
官网默认配置(自动执行)
注意 ,同时满足,且的关系才会触发
- 根据上次重写后的aof大小,判断当前aof大小是不是增长了1倍(100%)
- 重写时满足的文件大小
命令bgrewriteaof(手动)

重写原理
在重写开始前,redis会创建一个“重写子进程”,这个子进程会读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
与此同时,主进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中
当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中
重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似

官网建议使用RDB+AOF混合使用;共存的时候,AOF初始化被优先加载
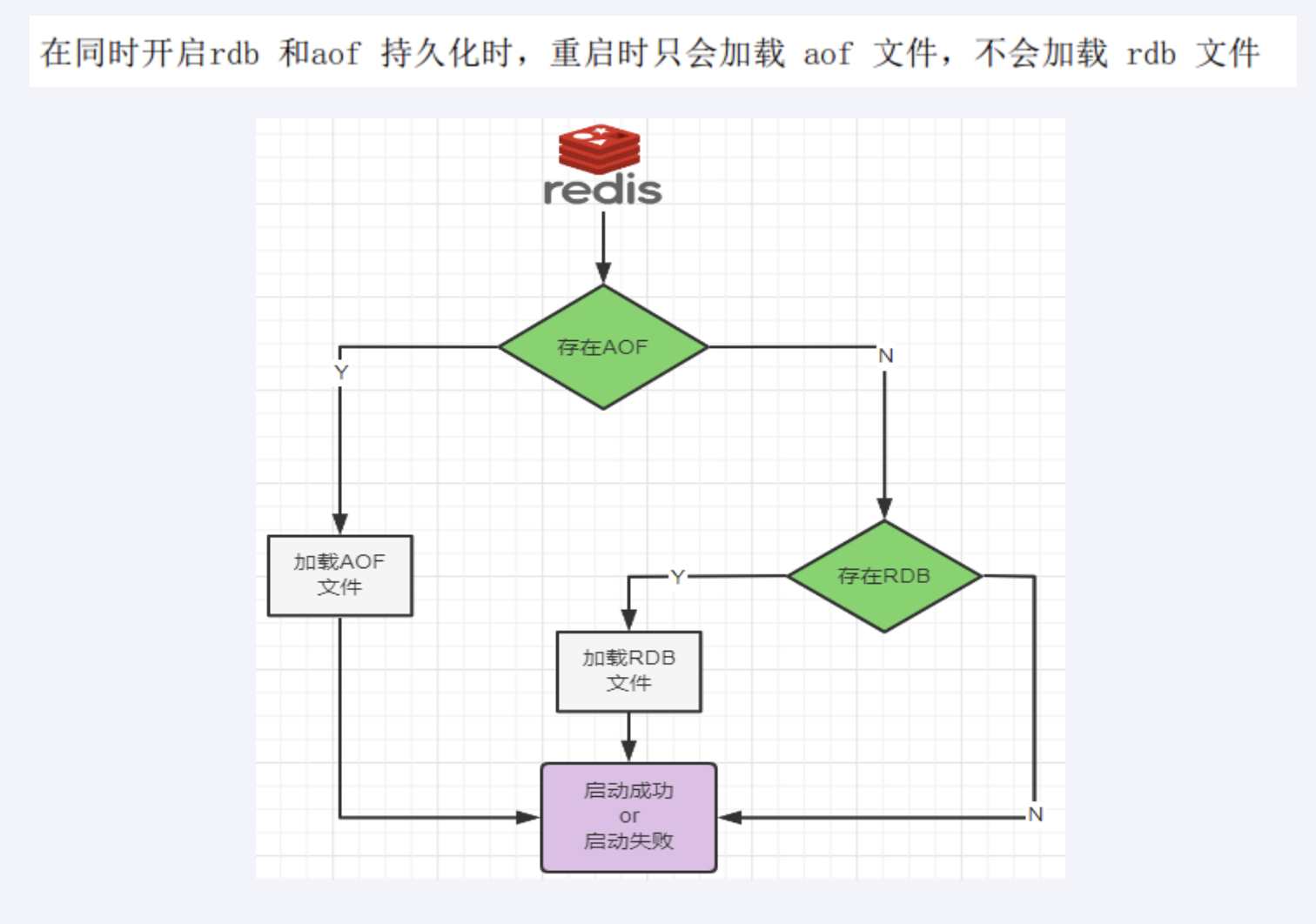
在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整
RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?
作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),留着rdb作为一个万一的手段.
设置
aof-use-rdb-preamble的值为yes yes表示开启,设置为no表示禁用
- RDB镜像做全量持久化,AOF做增量持久化
- 先使用RDB进行快照存储,然后使用AOF持久化记录所有的写操作,当重写策略满足或手动触发重写的时候,将最新的数据存储为新的RDB记录。这样的话,重启服务的时候会从RDB和AOF两部分恢复数据,既保证了数据完整性,又提高了恢复数据的性能。简单来说:混合持久化方式产生的文件一部分是RDB格式,一部分是AOF格式。----》AOF包括了RDB头部+AOF混写
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我的Ruby脚本需要一个小型非结构化数据库。不是Sqlite,更像是持久哈希表的东西可以完美地工作,只要它可以存储基本的Ruby结构(数组、字符串、哈希等-都是可序列化的)并且不会在Ruby脚本崩溃时被破坏。我知道有很多类似Perl和Tie::Hash的解决方案,所以可能有一些类似Ruby的gem。那会是什么gem?编辑:据我所知,PStore和yaml解决方案是基于每次更改时读取、解码、重新编码和写入整个数据库。这不仅需要所有这些都适合内存,而且是O(n^2)。所以它们似乎都不是特别好的解决方案。 最佳答案 有PStore在Rub
我正在尝试调试一些代码。一个奇怪的部分是before_save回调被调用了两次,尽管我只打算保存对象一次。为了追踪这是如何发生的,我在类中定义了这些方法:%w[savesave!].eachdo|method_name|define_method(method_name)do|*args|puts"whocalled'#{method_name}'?#{caller.first}"super(*args)endend从这个输出中,我只看到一个持久化调用。我相信save和save!是导致ActiveRecord持久化对象的唯一方法。据我所知,其他持久化方法依赖于这两者之一;例如,upda
我的sinatra应用程序必须解析一个~60MB的XML文件。这个文件几乎从不改变:在每晚的cron作业中,它被另一个覆盖。是否有技巧或方法可以将已解析的文件作为变量保存在内存中,以便我可以在传入请求时从中读取,而不必为每个传入请求一遍又一遍地解析它?一些伪代码来说明我的问题。get'/projects/:id'return@nokigiri_object.search("//projects/project[@id=#{params[:id]}]/name/text()")endpost'/projects/update'ifparams[:token]=="s3cr3t"@noko
在state_machine中的转换之前执行验证的正确语法是什么?gem?我试过以下,before_transition:apple=>:orangedovalidate:validate_coreenddefvalidate_coreifcore.things.blank?errors.add(:core,'musthaveonething')endend但是我得到以下错误,undefinedmethod`validate'for#我也试过把它写成,state:orangedovalidate:validate_coreend但这会导致记录保存后回滚,不太理想。我想首先阻止状态机转换
如果我通过Tempfile创建了一个临时文件,除了将它复制到另一个文件之外还有什么方法可以使它成为“永久”文件吗?我想避免在关联的Tempfile实例被垃圾回收或进程终止时删除它。与此相关,有没有一种方法可以利用Tempfile机制(或使用类似的机制)来获取"new"文件名,而无需以该名称创建文件? 最佳答案 不是真的。对于问题本身,请参见:ObjectSpace.undefine_finalizer(tmpfile)Tempfile库使用RubyObjectSpace终结器在垃圾回收时自动删除自身。通过使用上面的行,如果你不删除它
问题我正在尝试使用名为nedb的纯JS数据库在Electron渲染器进程中。它使用browserfield在itspackage.json交换基于浏览器的存储系统。这导致我的数据库实际上没有保存到文件中。背景我使用Next.js作为我的View框架,它的Webpack是为渲染线程配置的"target":"electron-renderer"。这显然会导致Webpack处理这些浏览器指令,即使渲染器进程应该可以访问浏览器和NodeAPI。这种行为并没有真正记录下来,所以我不知道如何覆盖它。我尝试过的我已经确认,如果我手动编辑node_modules/nedb/package.json本地
我正在开发一个Flask服务器,以便通过网络在某些后端Python功能和Javascript客户端之间进行通信。我正在尝试利用Flask的session变量在用户与应用程序交互的过程中存储用户特定的数据。我已经删除了下面大部分特定于应用程序的代码,但我遇到的核心问题仍然存在。这是我的(简化的)Flask应用程序的代码:importjsonimportosfromflaskimportFlask,jsonify,request,sessionapp=Flask(__name__)app.secret_key='my_secret_key'@app.route('/',methods=['
我是编程新手,作为帮助我更好地使用JavaScript的小型项目,我正在制作日落。背景开始是蓝色的,在某个时刻,背景必须变成黑色,大部分都是我做的,我只是不知道如何让它一直是黑色。noStroke();//OriginalypositionofthesunvarsunPosition=50;functiondraw(){//Drawskybackground("skyblue");//MovethesundownsunPosition=sunPosition+1;if(sunPosition===348){background("black");}//Drawsunfill("yell
我正在尝试使用在Backbone的模型中使用先前的api提到的示例。我已经粘贴了下面的例子varbill=newBackbone.Model({name:"BillSmith"});bill.bind("change:name",function(model,name){alert("Changednamefrom"+bill.previous("name")+"to"+name);});bill.set({name:"BillJones"});警报中的前一个值是BillSmith,这是正确的。但是如果我尝试通过调用在Firebug中访问它bill.previous("name");是