注:本文仅供学习,未经同意请勿转载
说明:该博客来源于xiaobai_Ry:2020年3月笔记
对应的PDF下载链接在:待上传
目录
重点:平均精度(Average-Precision,AP)与 mean Average Precision(mAP)
ROC(Receiver Operating Characteristic)曲线与AUC(Area Under Curve)
准确率 (Accuracy),混淆矩阵 (Confusion Matrix),精确率(Precision),召回率(Recall),平均正确率(AP),mean Average Precision(mAP),交除并(IoU),ROC + AUC,非极大值抑制(NMS)。
(1)概念:分对的样本数除以所有的样本数 ,即:准确(分类)率 = 正确预测的正反例数 / 总数。
(2)作用:一般用来评估模型的全局准确程度,不能包含太多信息,无法全面评价一个模型性能。
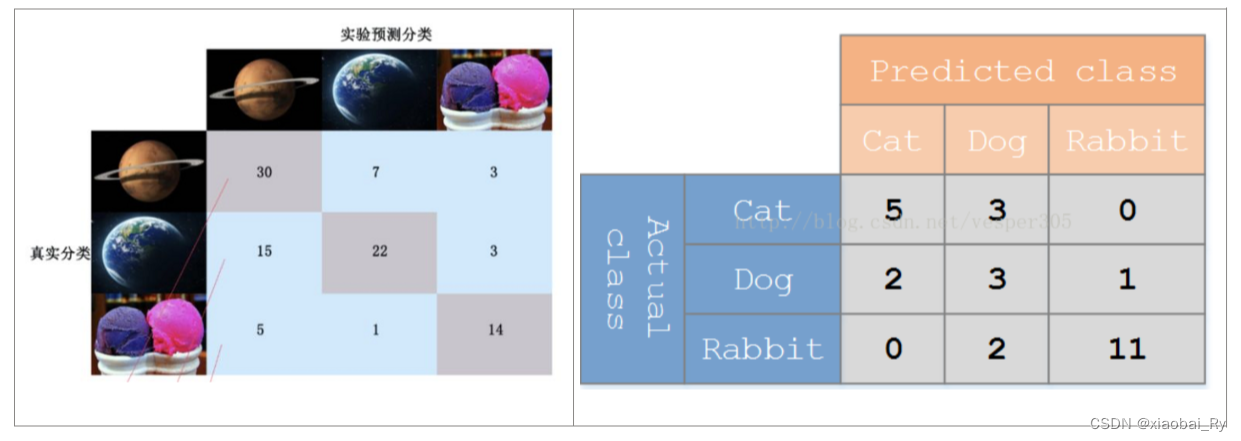
(1)概念:混淆矩阵又被称为错误矩阵, 在每个类别下,模型预测错误的结果数量,以及错误预测的类别和正确预测的数量都在一个矩阵下面显示出来,方便直观的评估模型分类的结果。其中,横轴是模型预测的类别数量统计,纵轴是数据真实标签的数量统计。
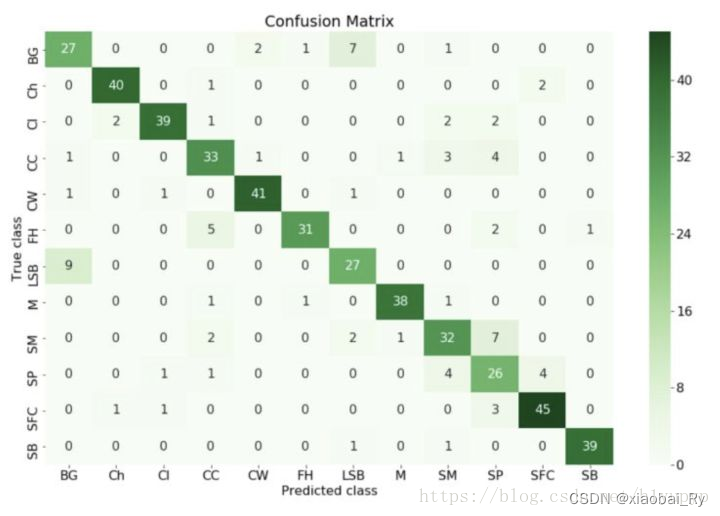
(2)对角线,表示模型预测和数据标签一致的数目,所以对角线之和除以测试集总数就是准确率。对角线上数字越大越好,在可视化结果中颜色越深,说明模型在该类的预测准确率越高。如果按行来看,每行不在对角线位置的就是错误预测的类别。总的来说,我们希望对角线越高越好,非对角线越低越好。
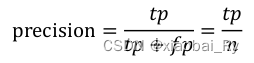
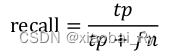
AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
在正样本非常少的情况下,PR表现的效果会更好。
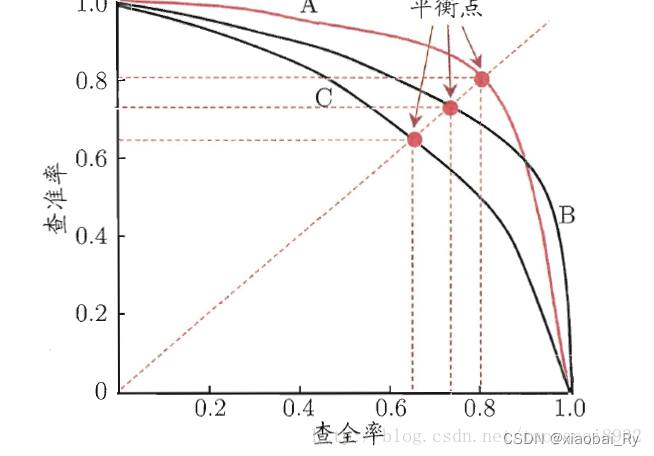
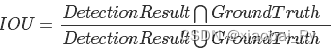
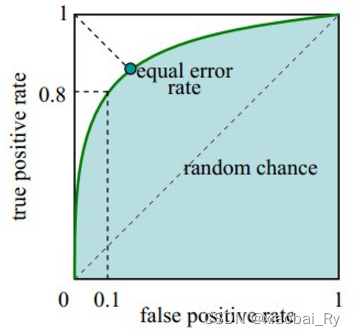
ROC曲线:
对角线对应于随机猜测模型,而(0,1)对应于所有整理排在所有反例之前的理想模型。曲线越接近左上角,分类器的性能越好。
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
ROC曲线绘制:
(1)根据每个测试样本属于正样本的概率值从大到小排序;
(2)从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本;
(3)每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。
当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
AUC(Area Under Curve)即为ROC曲线下的面积。AUC越接近于1,分类器性能越好。
物理意义:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
计算公式:就是求曲线下矩形面积。
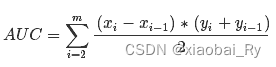
ROC曲线特点:
(1)优点:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。因为TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。
在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
(2)缺点:上文提到ROC曲线的优点是不会随着类别分布的改变而改变,但这在某种程度上也是其缺点。因为负例N增加了很多,而曲线却没变,这等于产生了大量FP。像信息检索中如果主要关心正例的预测准确性的话,这就不可接受了。在类别不平衡的背景下,负例的数目众多致使FPR的增长不明显,导致ROC曲线呈现一个过分乐观的效果估计。ROC曲线的横轴采用FPR,根据FPR ,当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的微小改变。结果是虽然大量负例被错判成正例,在ROC曲线上却无法直观地看出来。(当然也可以只分析ROC曲线左边一小段)
PR曲线:
(1)PR曲线使用了Precision,因此PR曲线的两个指标都聚焦于正例。类别不平衡问题中由于主要关心正例,所以在此情况下PR曲线被广泛认为优于ROC曲线。
Non-Maximum Suppression就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的bounding box。对于有重叠在一起的预测框,只保留得分最高的那个。
(1)NMS计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为队列中首个要比较的对象;
(2)计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box,保留小的IoU得预测框;
(3)然后重复上面的过程,直至候选bounding box为空。
最终,检测了bounding box的过程中有两个阈值,一个就是IoU,另一个是在过程之后,从候选的bounding box中剔除score小于阈值的bounding box。需要注意的是:Non-Maximum Suppression一次处理一个类别,如果有N个类别,Non-Maximum Suppression就需要执行N
次。
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
我正在构建一个应用程序,想知道是否将未使用的对象设置为nil是生产级编码中的常见做法。我知道这只是垃圾收集器的提示,并不总是处理对象。 最佳答案 根据这个thread如果您使用完一个成员对象,将其设置为nil将引发被引用对象被垃圾回收。如果它是局部变量,方法exit将做同样的事情。也就是说,如果您要求将成员显式设置为nil,我会质疑您的设计。 关于ruby-将对象设置为nil是否很常见?,我们在StackOverflow上找到一个类似的问题: https://
我最近与一位同事讨论了以下Ruby语法:value=ifa==0"foo"elsifa>42"bar"else"fizz"end我个人并没有看到太多这种逻辑,但我的同事指出,这实际上是一种相当普遍的Rubyism。我试着用谷歌搜索这个主题,但没有找到任何文章、页面或SO问题来讨论它,这让我相信这可能是一种非常实际的技术。然而,另一位同事发现语法令人困惑,而是将上面的逻辑写成这样:ifa==0value="foo"elsifa>42value="bar"elsevalue="fizz"end缺点是value=的重复声明和隐式elsenil的丢失,如果我们想使用它的话。这也感觉它与Ruby
我想知道我的代码是否在rspec下运行。这可能吗?原因是我正在加载一些错误记录器,这些记录器在测试期间会被故意错误(expect{x}.toraise_error)弄得乱七八糟。我查看了我的ENV变量,没有(明显的)测试环境变量的迹象。 最佳答案 在spec_helper.rb的开头添加:ENV['RACK_ENV']='test'现在您可以在代码中检查RACK_ENV是否经过测试。 关于ruby-检测由RSpec、Ruby运行的代码,我们在StackOverflow上找到一个类似的问题
我正在使用rubydaemongem。想知道如何向停止操作添加一些额外的步骤?希望我能检测到停止被调用,并向其添加一些额外的代码。任何人都知道我如何才能做到这一点? 最佳答案 查看守护程序gem代码,它似乎没有用于此目的的明显扩展点。但是,我想知道(在守护进程中)您是否可以捕获守护进程在发生“停止”时发送的KILL/TERM信号...?trap("TERM")do#executeyourextracodehereend或者你可以安装一个at_exit钩子(Hook):-at_exitdo#executeyourextracodehe
我有一个定义类的Ruby脚本。我希望脚本执行语句BoolParser.generate:file_base=>'bool_parser'仅当脚本作为可执行文件被调用时,而不是当它被irbrequire(或通过-r在命令行上传递)时。我可以用什么来包装上面的语句,以防止它在我的Ruby文件加载时执行? 最佳答案 条件$0==__FILE__...!/usr/bin/ruby1.8classBoolParserdefself.generate(args)p['BoolParser.generate',args]endendif$0==_
我有以下字符串,我想检测那里的换行符。但是Ruby的字符串方法include?检测不到它。我正在运行Ruby1.9.2p290。我哪里出错了?"/'ædres/\nYour".include?('\n')=>false 最佳答案 \n需要在双引号内,否则无法转义。>>"\n".include?'\n'=>false>>"\n".include?"\n"=>true 关于Ruby无法检测字符串中的换行符,我们在StackOverflow上找到一个类似的问题: h
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su