使用parted命令完成磁盘分区后会有如下提示。意思就是我们新增了磁盘分区,提醒我们需要更新/etc/fstab文件。Linux系统都是各磁盘或者分区是通过挂载的方式访问的,临时使用的U盘、光盘等我们可以使用mount命令临时挂载,如果是系统固定的磁盘则需要我们将磁盘挂载写入/etc/fstab文件,实现开机自动挂载。我们可以通过查看/etc/fastab文件了解磁盘挂载信息,也可以通过编辑该文件更新、修改磁盘挂载信息。
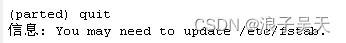
fstab文件内容样式如下,#开头的行是该文件的说明,其他行是开机自动挂载的配置内容,每一行包括设备标识、挂载点、文件系统类型、挂载参数、是否dump、检查顺序六项内容。
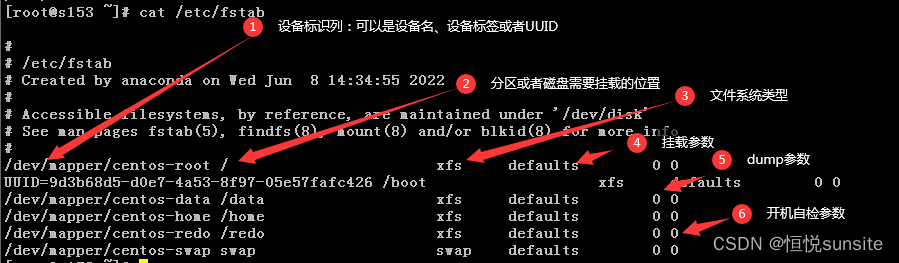
如果我们需要了解/etc/fstab文件各列字段的说明可以使用man fstab查看并获取帮助。
| 序号 | 列名 | 说明 |
|---|---|---|
| 1 | fs_spec | 此列表示要安装的块特殊设备或远程文件系统 |
| 2 | fs_file | 此列表示存储挂载点 |
| 3 | fs_vfstype | 此列表示挂载的文件系统类型 |
| 4 | fs_mntops | 文件系统挂载参数 |
| 5 | fs_freq | 是否转储dump,未配置则默认为0, |
| 6 | fs_passno | fsck程序使用此字段来确定在重新启动时执行文件系统检查的顺序。0表示不检查;1表示第一位检查,一般用于根挂载点,其他磁盘配置参数2。 |
fs_spec字段我们可以使用设备文件名、UUID或者标签,也可以是NFS等远程文件系统。远程文件系统配置方式是<host>:<dir>,与直接使用mount命令挂载远程文件系统是一致的。其中UUID和LABEL配置方式是LABEL=<label> 或者 UUID=<uuid>。设备文件、UUID、label作为标识的不同:
建议使用UUID的方式挂载。我们可以使用blkid命令查看UUID,可以使用命令ls -l /dev/disk/by-label/查看label。如果磁盘或者分区都没有配置标签,by-label文件可能并不存在。
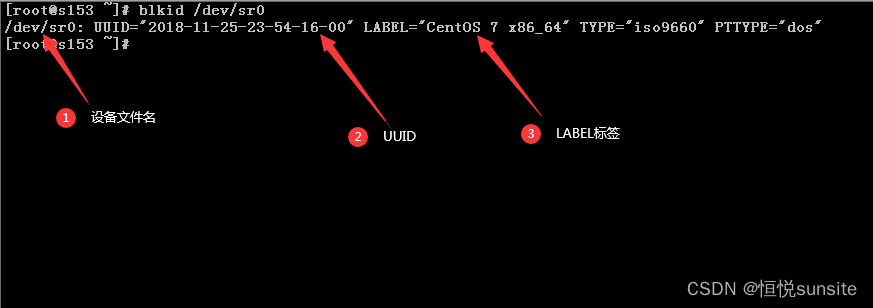
fs_file字段就是我们需要挂载的位置,如果是swap则写swap,其他的写具体的文件系统路径。
文件系统类型字段指的是我们需要挂载的文件系统类型,支持的很多ext2, ext3, hfs, hpfs, iso9660, jfs, minix, msdos, ncpfs, nfs, ntfs, proc, qnx4, reiserfs, romfs, smbfs, sysv, tmpfs, udf, ufs, umsdos, vfat, xenix, xfs等,只要是mount命令支持的都可以。linux系统现在常用的是ext4和xfs,也支持window文件系统ntfs、vfat等,如果是交换区,则设置为swap。
fs_mntops表示挂载时的参数选项,各参数说明如下,我们常用defaults。
dump命令将此字段用于这些文件系统,以确定需要转储哪些文件系统。字段可以设置为0或者1,如果第五个字段不存在,返回零值,dump将假设不需要转储文件系统。
fsck程序使用此字段来确定在重新启动时执行文件系统检查的顺序。该字段值可以设置为0|1|2,根文件系统的fs_passno应为1,其他文件系统的fs_passno应为2。将按顺序检查驱动器内的文件系统,但同时检查不同驱动器上的文件系统,以利用硬件中可用的并行性。如果第六个字段不存在或不为零,则返回零值,fsck将假设不需要检查文件系统。
我们可以使用命令mount -a命令检查配置文件是否有错误,可以检查出UUID错误、挂载点不存在等错误。如果/etc/fstab配置文件错误可能导致开机启动失败。
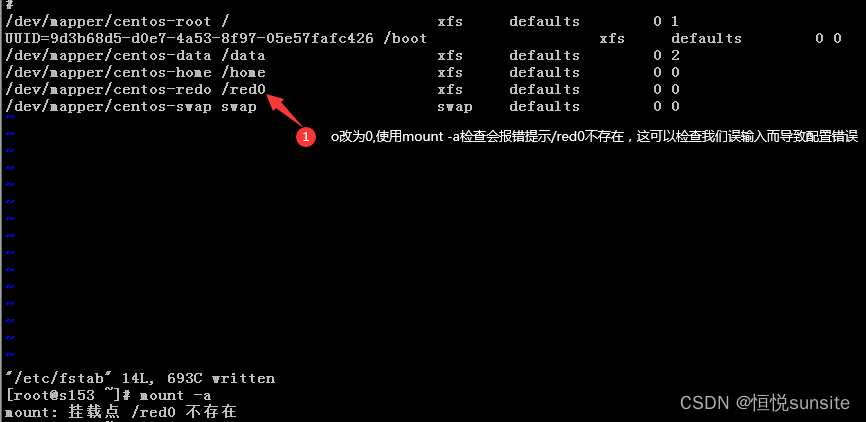
[root@s153 ~]# mount -a
mount: /etc/fstab:解析出错:忽略第 11 行的记录。
mount: 找不到 UUID=9d3b68d5-d0e7-4a53-8f97-05e57fafc427
mount: 挂载点 /red0 不存在
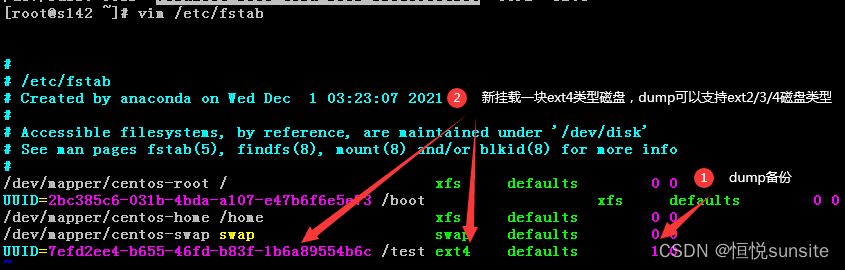
dump配置只针对ext2/3/4文件系统类型有效,为了满足测试需求,我们新挂载一块ext4磁盘,另外centos7默认dump命令没有安装,我们需要手动安装dump命令。
[root@s142 ~]# yum install -y dump

我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A