【动态规划】
暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!
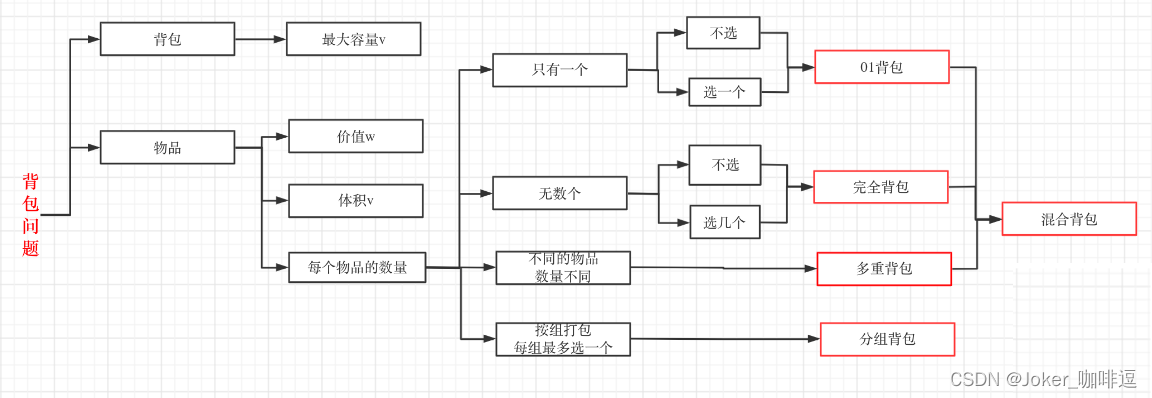
背包问题是动态规划(Dynamic Planning) 里的非常重要的一部分,关于几种常见的背包,其关系如下:
在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。
(1) 确定dp数组及其下标的含义
(2) 确定递推公式
(3) dp数组的初始化
(4) 确定遍历顺序
1. 问能否能装满背包(或者最多装多少):
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i])
2. 问装满背包有几种方法:
dp[j] += dp[j - nums[i]]
3. 问背包装满最大价值:
dp[j] = max(dp[j], dp[j - weight[i]] + value[i])
4. 问装满背包所有物品的最小个数:
dp[j] = min(dp[j], dp[j - coins[i]] + 1)
有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i]
。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
对于背包问题,有一种写法是使用二维数组。
动规四部曲:
1) 确定dp数组及其下标的含义
2) 确定递推公式
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
3)dp数组的初始化
* 首先从dp[i][j]的定义出发,如果背包容量j为0的话,即dp[i][0],无论是选取哪些物品,背包价值总和一定为0
* 状态转移方程 dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 可以看出i 是由 i-1 推导出来,那么i为0的时候就一定要初始化。
* dp[0][j]:存放编号0的物品的时候,各个容量的背包所能存放的最大重量j。
那么很明显当 j < weight[0]时,dp[0][j] 应该是 0(背包容量比编号0的物品重量还小)
同理,当j >= weight[0]时,dp[0][j] 应该是value[0](背包容量足够放编号0物品)
4) 确定遍历顺序
bag_size = 4
weight = [1, 3, 4]
value = [15, 20, 30]
rows, cols = len(weight), bag_size + 1
dp = [[0]*cols for _ in range(rows)]
# 初始化dp数组.
for i in range(rows):
dp[i][0] = 0
first_item_weight, first_item_value = weight[0], value[0]
for j in range(1, cols):
if first_item_weight <= j:
dp[0][j] = first_item_value
# 更新dp数组: 先遍历物品, 再遍历背包.
for i in range(1, rows):
for j in range(1, cols):
if weight[i] > j: # 说明背包装不下当前物品.
dp[i][j] = dp[i - 1][j] # 所以不装当前物品.
else:
# 定义dp数组: dp[i][j] 前i个物品里,放进容量为j的背包,价值总和最大是多少。
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i])
print(dp)
在使用二维数组的时候,递推公式:dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i])
其实可以发现如果把dp[i - 1]那一层拷贝到dp[i]上,表达式完全可以是:dp[i][j] = max(dp[i][j], dp[i][j - weight[i]] + value[i]);
与其把dp[i - 1]这一层拷贝到dp[i]上,不如只用一个一维数组了,只用dp[j](一维数组,也可以理解是一个滚动数组)。
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
weight = [1, 3, 4]
value = [15, 20, 30]
bag_weight = 4
# 初始化: 全为0
dp = [0] * (bag_weight + 1)
# 先遍历物品, 再遍历背包容量
for i in range(len(weight)):
for j in range(bag_weight, weight[i] - 1, -1):
# 递归公式
dp[j] = max(dp[j], dp[j - weight[i]] + value[i])
print(dp)
有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i]。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。
完全背包和01背包问题唯一不同的地方就是,每种物品有无限件。
我们知道01背包内嵌的循环是从大到小遍历,为了保证每个物品仅被添加一次。
而完全背包的物品是可以添加多次的,所以要从小到大去遍历,即:
// 01背包 先遍历物品,再遍历背包
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
// 1. 先遍历物品,再遍历背包
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = weight[i]; j <= bagWeight ; j++) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
// 2. 先遍历背包,再遍历物品
for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
for(int i = 0; i < weight.size(); i++) { // 遍历物品
// 容量 > 物品重量, 则更新dp数组
if (j >= weight[i]) dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
python
// 1.先遍历物品,再遍历背包
def test_complete_pack1():
weight = [1, 3, 4]
value = [15, 20, 30]
bag_weight = 4
dp = [0]*(bag_weight + 1)
for i in range(len(weight)):
for j in range(weight[i], bag_weight + 1):
dp[j] = max(dp[j], dp[j - weight[i]] + value[i])
print(dp[bag_weight])
// 2. 先遍历背包,再遍历物品
def test_complete_pack2():
weight = [1, 3, 4]
value = [15, 20, 30]
bag_weight = 4
dp = [0]*(bag_weight + 1)
for j in range(bag_weight + 1):
for i in range(len(weight)):
if j >= weight[i]: dp[j] = max(dp[j], dp[j - weight[i]] + value[i])
print(dp[bag_weight])
if __name__ == '__main__':
test_complete_pack1()
test_complete_pack2()
多重背包和01背包是非常像的, 为什么和01背包像呢?
每件物品最多有Mi件可用,把Mi件摊开,其实就是一个01背包问题了。
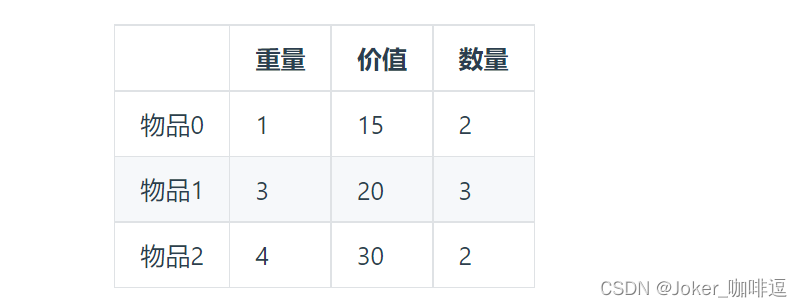
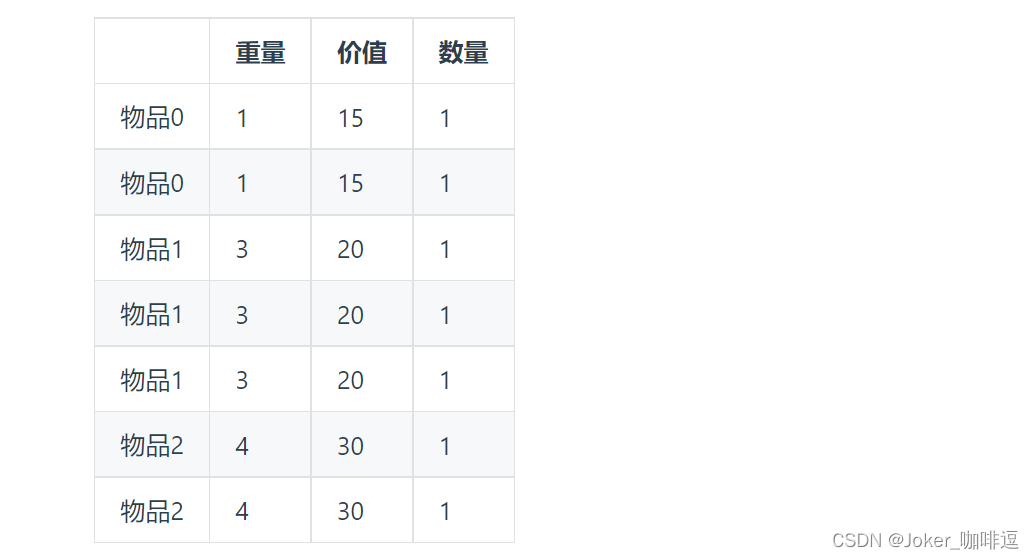
# 版本一: 将物品全摊开,转化为 01背包问题
weight = [1, 3, 4]
value = [15, 20, 30]
nums = [2, 3, 2]
bag_weight = 10
# 将物品全部展开,数量全为1
for i in range(len(nums)):
if nums[i] > 1:
weight.append(weight[i])
value.append(value[i])
nums[i] -= 1
# 动态规划五部曲:
dp = [0]*(bag_weight+1)
# 遍历物品
for i in range(len(weight)):
# 遍历背包
for j in range(bag_weight, weight[i] -1, -1):
dp[j] = max(dp[j], dp[j - weight[i]] + value[i])
print("".join(map(str,dp)))
# 版本二: 直接加上个数维度
weight = [1, 3, 4]
value = [15, 20, 30]
nums = [2, 3, 2]
bag_weight = 10
dp = [0] * (len(bag_weight) + 1)
for i in range(len(weight)): # 物品的重量
for j in range(bag_weight, weight[i] - 1, -1): # 背包的重量
# 以上是 01背包
for k in range(1, nums[i]+1):
if j >= k*weight[i]:
dp[j] = max(dp[j], dp[j - k*weight[i]] + k*value[i])
print("".join(max(str, dp)))
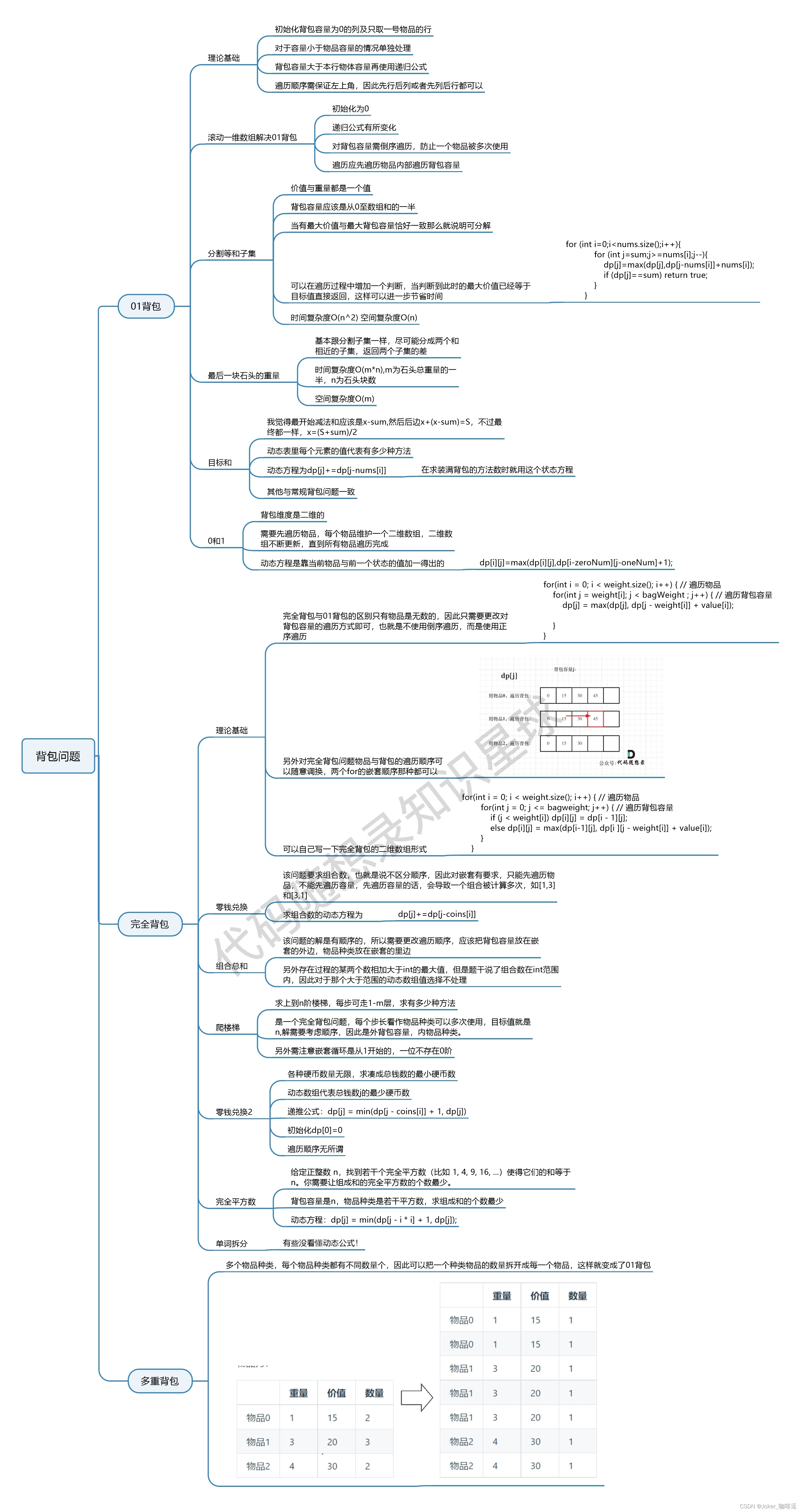
知识星球的总结:
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主