一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立 的单词),然后输出 tokens 流。 例如,whitespace tokenizer 遇到空白字符时分割文本。它会将文本 "Quick brown fox!" 分割 为 [Quick, brown, fox!]。 该 tokenizer(分词器)还负责记录各个 term(词条)的顺序或 position 位置(用于 phrase 短 语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的 start(起始)和 end(结束)的 character offsets(字符偏移量)(用于高亮显示搜索的内容)。
Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)
注意:不能用默认 elasticsearch-plugin install xxx.zip 进行自动安装
找到github上的开源分词器插件
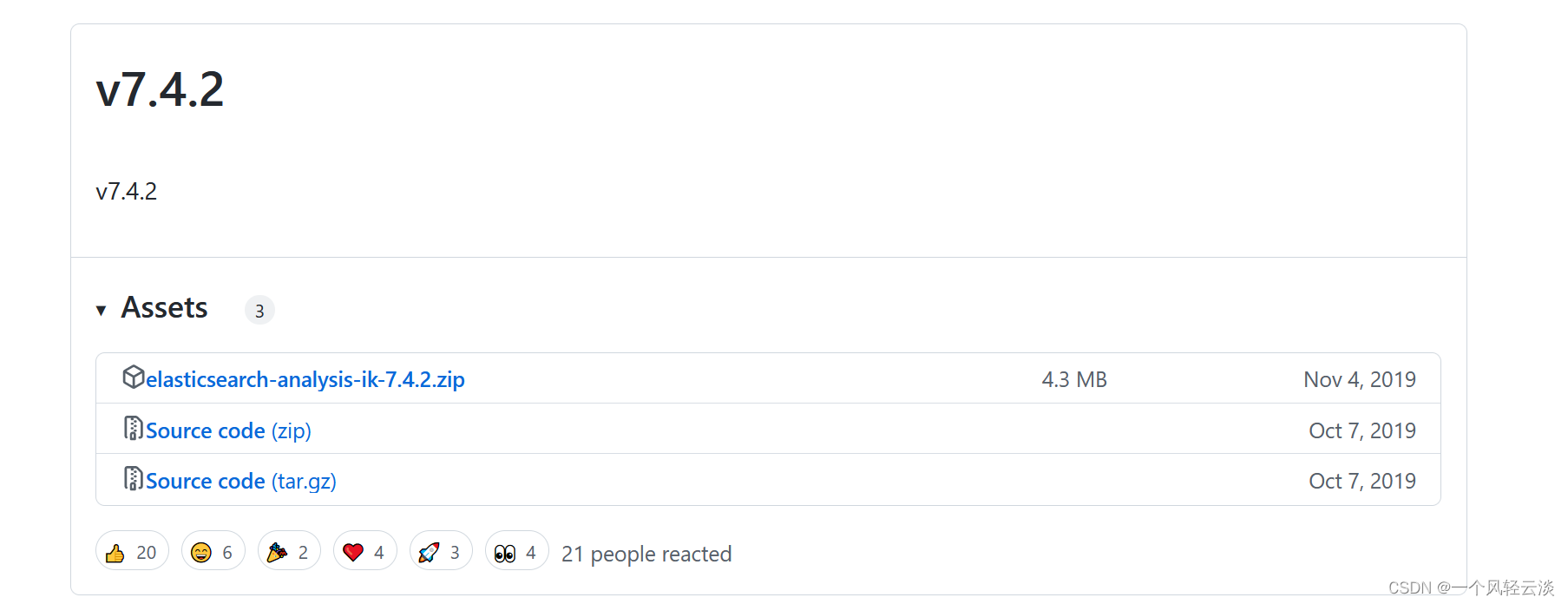
找到对应的Es对应的版本,一定要找对应的版本,不然会出现一些乱七八糟的错误
下载elasticsearch-analysis-ik-7.4.2.zip
下载完解压以后传到虚拟机对应Docker中对应的Es挂载的插件位置
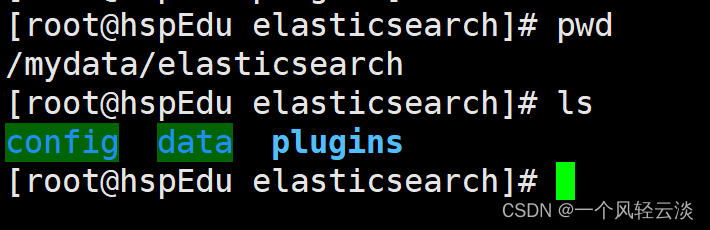
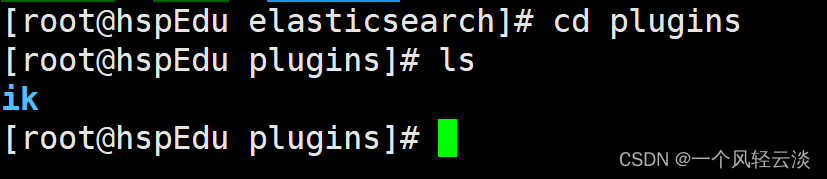 将文件命名为ik
将文件命名为ik
检查是不是安装好了,进入Es容器内部
docker exec -it 容器 id /bin/bash即可列出系统的分词器
elasticsearch-plugin list最后记得Es容器
POST _analyze
{
"text": "我是中国人"
}{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "中",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "国",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "人",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
能够看出不同的分词器,分词有明显的区别,所以以后定义一个索引不能再使用默 认的 mapping 了,要手工建立 mapping, 因为要选择分词器。
这里采用nginx配合使用自定义分词器
随便启动一个 nginx 实例,只是为了复制出配置
docker run -p 80:80 --name nginx -d nginx:1.10
将容器内的配置文件拷贝到当前目录:docker container cp nginx:/etc/nginx .
别忘了后面的点
修改文件名称:mv nginx conf 把这个 conf 移动到/mydata/nginx 下
终止原容器:docker stop nginx
执行命令删除原容器:docker rm $ContainerId
创建新的 nginx;执行以下命令
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10
在nginx挂载的文件下的html中创建:
mkdir escd esvi fenci.txt
保存退出
修改/usr/share/elasticsearch/plugins/ik/config/中的 IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.128.130/fenci/myword.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>然后重启 es 服务器,重启 nginx。 在 kibana 中测试分词效果
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是乔碧罗殿下"
}{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "乔碧罗",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "殿下",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
}
]
}
更新完成后,es 只会对新增的数据用新词分词。历史数据是不会重新分词的。如果想要历 史数据重新分词。需要执行:
POST my_index/_update_by_query?conflicts=proceed
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
 https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.4.2&page=8
https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.4.2&page=8