pd.concat, pd.appendpandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
objs
axis=0
keys
join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
ignore_index=False
匹配级联
df1 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','B','C'])
df2 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','D','C'])
pd.concat((df1,df1),axis=1) #行列索引都一致的级联叫做匹配级联

不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有2种连接方式:
外连接:补NaN(默认模式)
pd.concat((df1,df2),axis=0) or pd.concat((df1,df2),axis=1, join='outer')

内连接:只连接匹配的项
pd.concat((df1,df2),axis=0,join='inner') #inner直把可以级联的级联不能级联不处理

如果想要保留数据的完整性必须使用outer(外连接)
append函数的使用
append函数的使用
df1.append(df1)
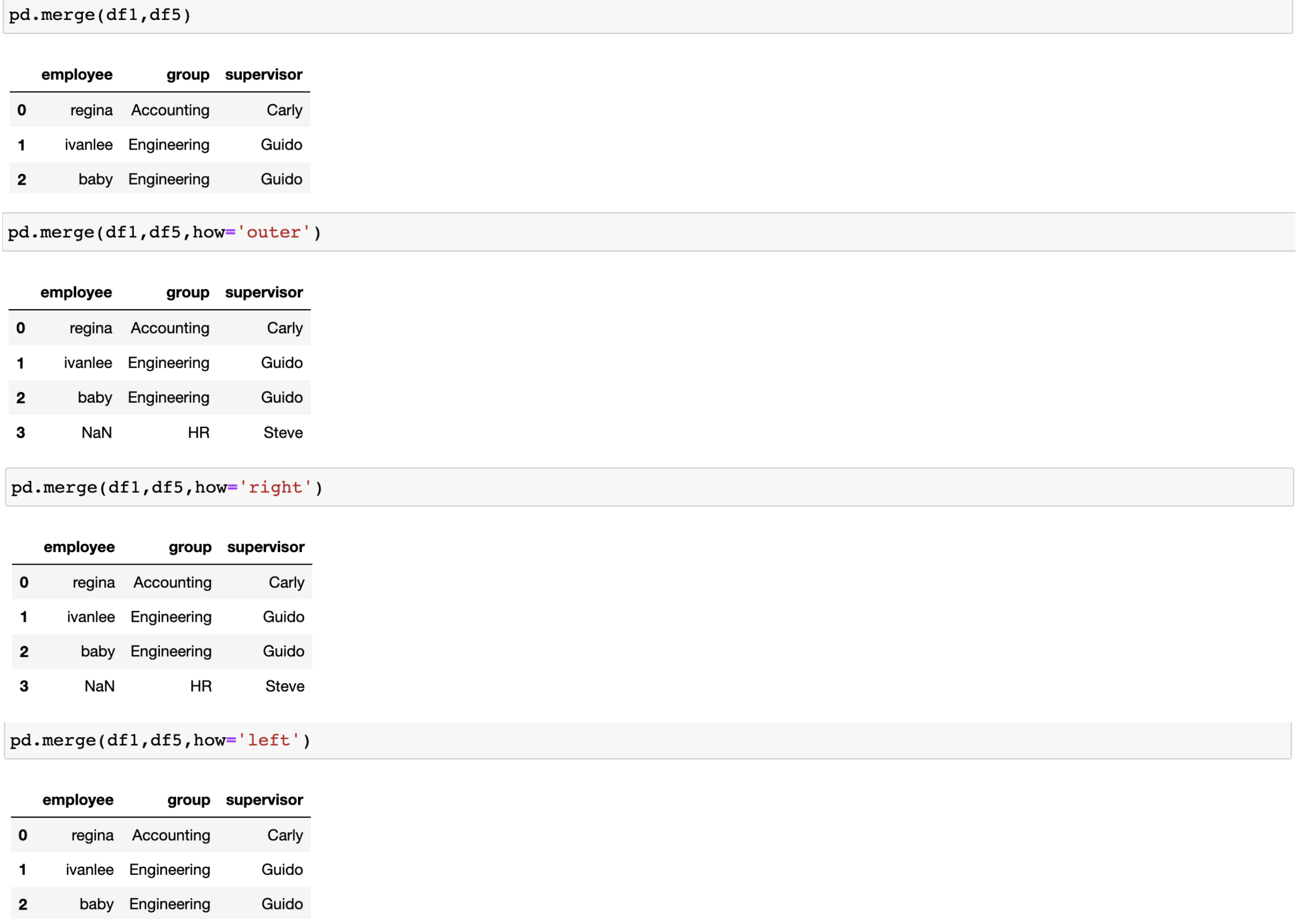
df1 = DataFrame({'employee':['regina','ivanlee','baby'],
'group':['Accounting','Engineering','Engineering'],
})
df2 = DataFrame({'employee':['regina','ivanlee','baby'],
'hire_date':[2004,2008,2012],
})
pd.merge(df1,df2,on='employee')

df3 = DataFrame({
'employee':['regina','ivanlee'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})
df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
pd.merge(df3,df4)#on如果不写,默认情况下使用两表中公有的列作为合并条件

df5 = DataFrame({'group':['Accounting','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
how 参数默认是inner,也可以是outer,right,left
当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
df5 = DataFrame({'name':['ivanlee','zjr','liyifan'],
'hire_dates':[1998,2016,2007]})
pd.merge(df1,df5,left_on='employee',right_on='name')

- 需求:
- 导入文件,查看原始数据
- 将人口数据和各州简称数据进行合并
- 将合并的数据中重复的abbreviation列进行删除
- 查看存在缺失数据的列
- 找到有哪些state/region使得state的值为NaN,进行去重操作
- 为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN
- 合并各州面积数据areas
- 我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行
- 去除含有缺失数据的行
- 找出2010年的全民人口数据
- 计算各州的人口密度
- 排序,并找出人口密度最高的州
#导入文件,查看原始数据
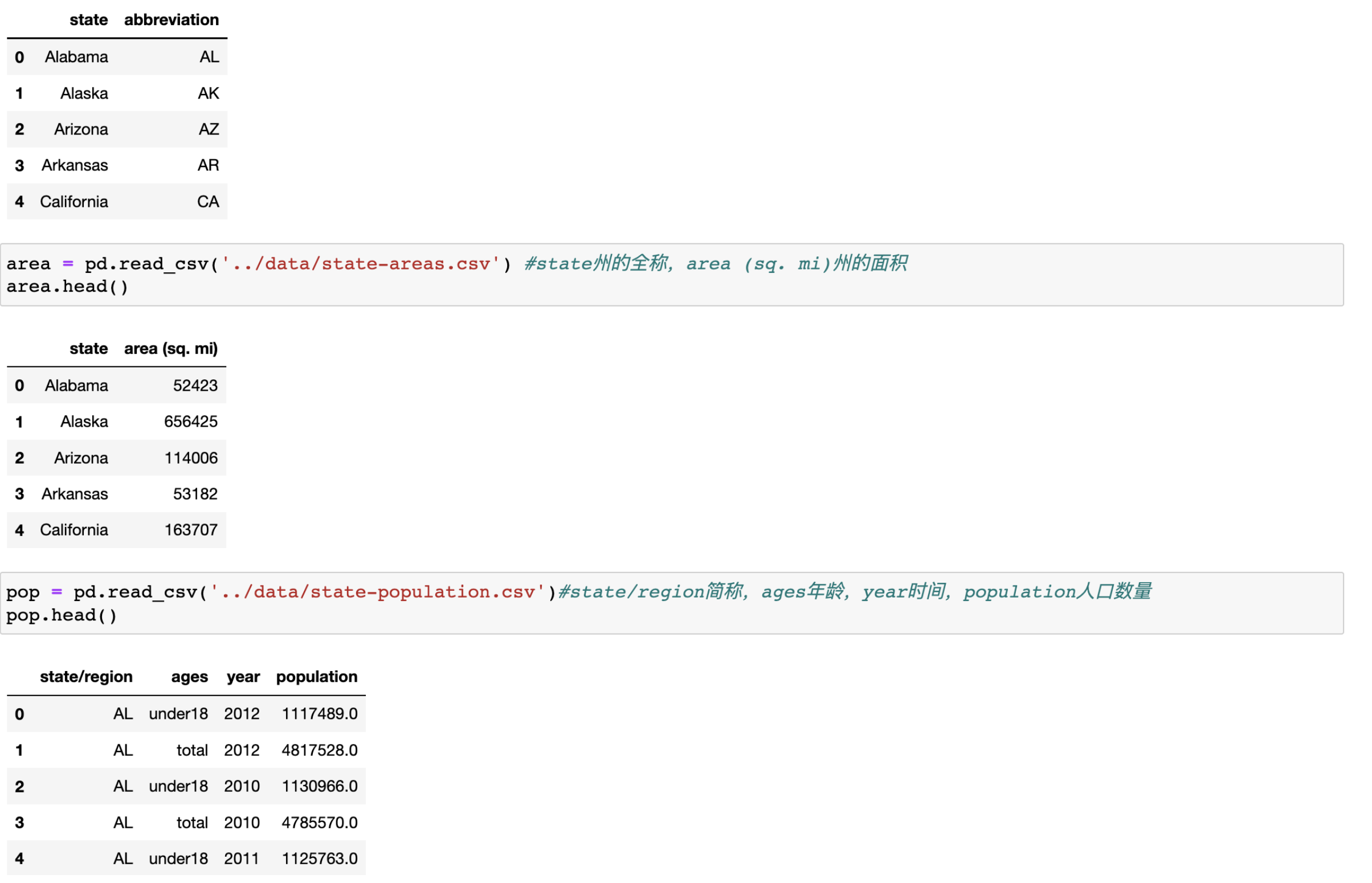
abb = pd.read_csv('../data/state-abbrevs.csv') #state(州的全称)abbreviation(州的简称)
area = pd.read_csv('../data/state-areas.csv') #state州的全称,area (sq. mi)州的面积
pop = pd.read_csv('../data/state-population.csv')#state/region简称,ages年龄,year时间,population人口数量
#将人口数据和各州简称数据进行合并
abb_pop = pd.merge(abb,pop,left_on='abbreviation',right_on='state/region',how='outer') 必须保证数据完整
abb_pop.head()

#将合并的数据中重复的abbreviation列进行删除
abb_pop.drop(labels='abbreviation',axis=1,inplace=True)
#查看存在缺失数据的列
#方式1:isnull,notll,any,all
abb_pop.isnull().any(axis=0)
#state,population这两列中是存在空值

#1.将state中的空值定位到
abb_pop['state'].isnull()
#2.将上述的布尔值作为源数据的行索引
abb_pop.loc[abb_pop['state'].isnull()]#将state中空对应的行数据取出
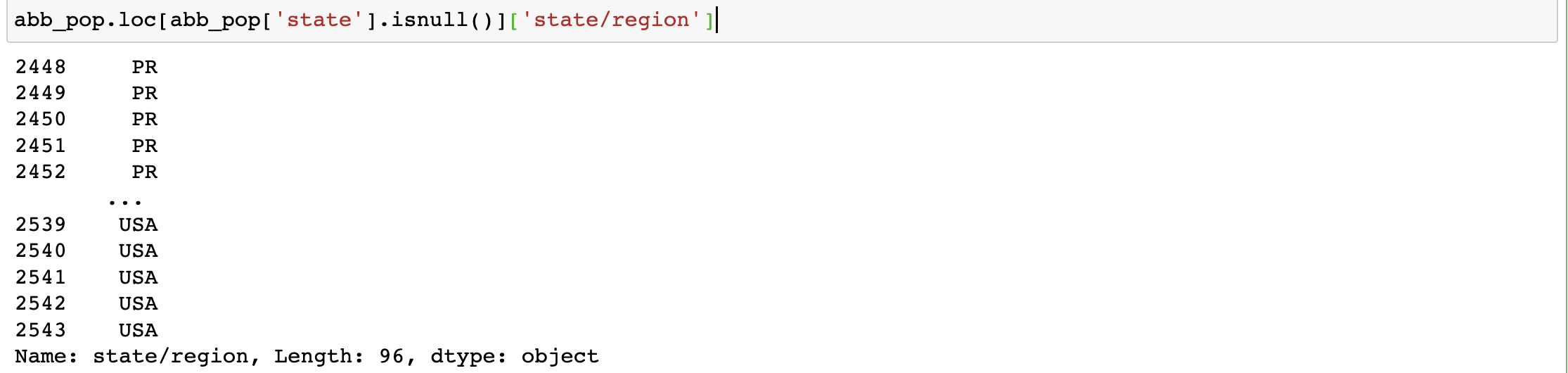
#3.将简称取出
abb_pop.loc[abb_pop['state'].isnull()]['state/region']
#4.对简称去重
abb_pop.loc[abb_pop['state'].isnull()]['state/region'].unique()
#结论:只有PR和USA对应的全称数据为空值
#为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN
#思考:填充该需求中的空值可不可以使用fillna?
# - 不可以。fillna可以使用空的紧邻值做填充。fillna(value='xxx')使用指定的值填充空值
# 使用给元素赋值的方式进行填充!
#1.先给USA的全称对应的空值进行批量赋值
abb_pop.loc[abb_pop['state/region'] == 'USA']#将usa对应的行数据取出
#1.2将USA对应的全称空对应的行索引取出
indexs = abb_pop.loc[abb_pop['state/region'] == 'USA'].index
abb_pop.iloc[indexs]
abb_pop.loc[indexs,'state'] = 'United States'
#2.可以将PR的全称进行赋值
abb_pop['state/region'] == 'PR'
abb_pop.loc[abb_pop['state/region'] == 'PR'] #PR对应的行数据
indexs = abb_pop.loc[abb_pop['state/region'] == 'PR'].index
abb_pop.loc[indexs,'state'] = 'PPPRRR'
#合并各州面积数据areas
abb_pop_area = pd.merge(abb_pop,area,how='outer')
#我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行
abb_pop_area['area (sq. mi)'].isnull()
abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()] #空对应的行数据
indexs = abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()].index
#找出2010年的全民人口数据(基于df做条件查询)
abb_pop_area.query('ages == "total" & year == 2010')
#计算各州的人口密度(人口除以面积)
abb_pop_area['midu'] = abb_pop_area['population'] / abb_pop_area['area (sq. mi)']
abb_pop_area
#排序,并找出人口密度最高的州
abb_pop_area.sort_values(by='midu',axis=0,ascending=False).iloc[0]['state']
替换操作可以同步作用于Series和DataFrame中
单值替换
多值替换
to_replace=[] value=[]to_replace={to_replace:value,to_replace:value}
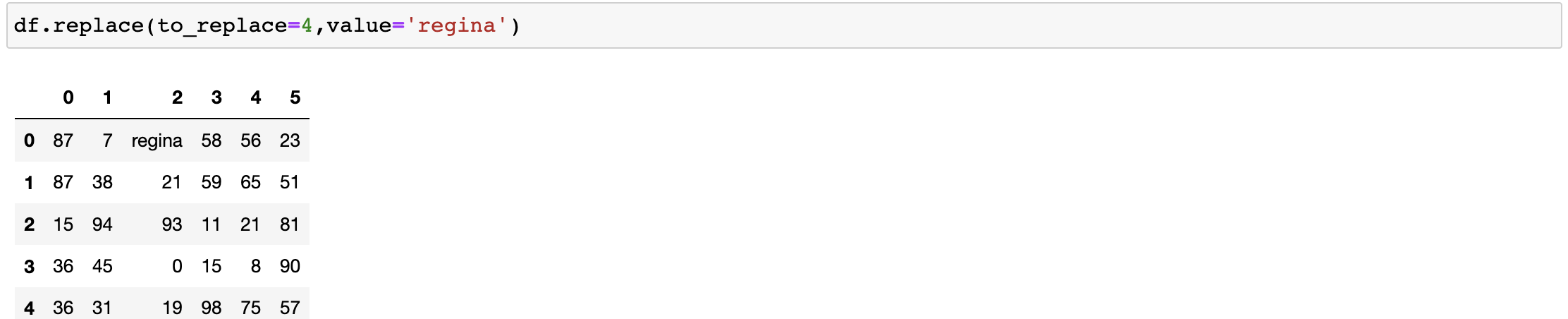
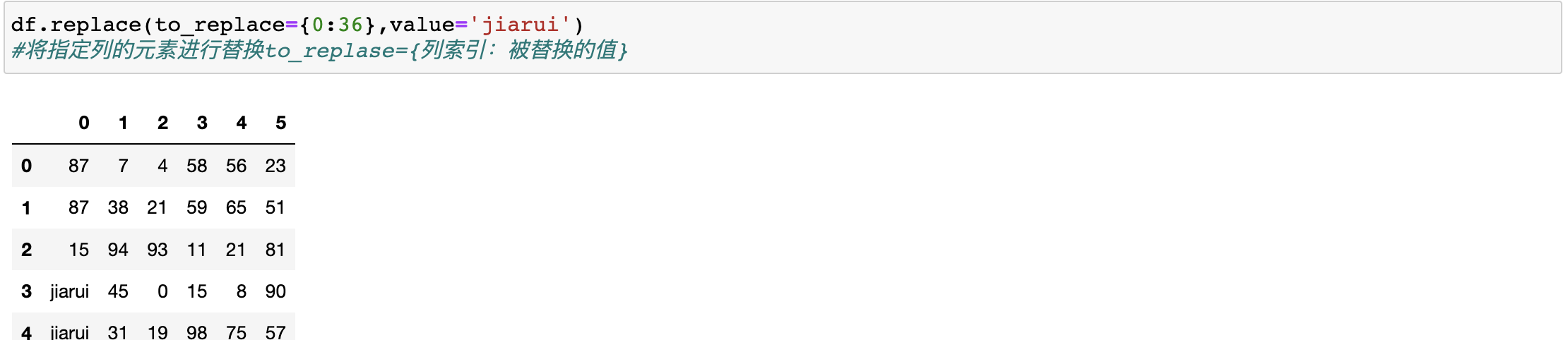
我们要替换某列当中的数值
df.replace(to_replace={0,36},value='jiarui')
#将指定列的元素进行替换to_replase={列索引:被替换的值}
概念:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定(给一个元素值提供不同的表现形式)
创建一个df,两列分别是姓名和薪资,然后给其名字起对应的英文名
dic = {
'name':['regina','ivanlee','regina'],
'salary':[15000,20000,15000]
}
df = DataFrame(data=dic)

先指定给regina映射为zhangjiarui,首先建立一张映射关系表
#映射关系表
dic = {
'regina':'zhangjiarui',
'ivanlee':'liyifan'
}
df['e_name'] = df['name'].map(dic)

map是Series的方法,只能被Series调用
超过3000部分的钱缴纳50%的税,计算每个人的税后薪资
#该函数是我们指定的一个运算法则
def after_sal(s):#计算s对应的税后薪资
return s - (s-3000)*0.5
df['after_sal'] = df['salary'].map(after_sal)#可以将df['salary']这个Series中每一个元素(薪资)作为参数传递给s

df = DataFrame(data=np.random.randint(0,100,size=(100,3)),columns=['A','B','C'])
#生成乱序的随机序列
np.random.permutation(10)
#将原始数据打乱
df.take([2,0,1],axis=1)
df.take(np.random.permutation(3),axis=1)
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})

#想要水果的种类进行分析
df.groupby(by='item')
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7fac66bd1b20>
#查看详细的分组情况
df.groupby(by='item').groups

分组聚合
#计算出每一种水果的平均价格
df.groupby(by='item')['price'].mean()
out:
item
Apple 3.00
Banana 2.75
Orange 3.50
Name: price, dtype: float64
#计算每一种颜色对应水果的平均重量
df.groupby(by='color')['weight'].mean()
out:
color
green 31.333333
red 12.000000
yellow 35.000000
Name: weight, dtype: float64
dic = df.groupby(by='color')['weight'].mean().to_dict()
#将计算出的平均重量汇总到源数据
df['mean_w'] = df['color'].map(dic)

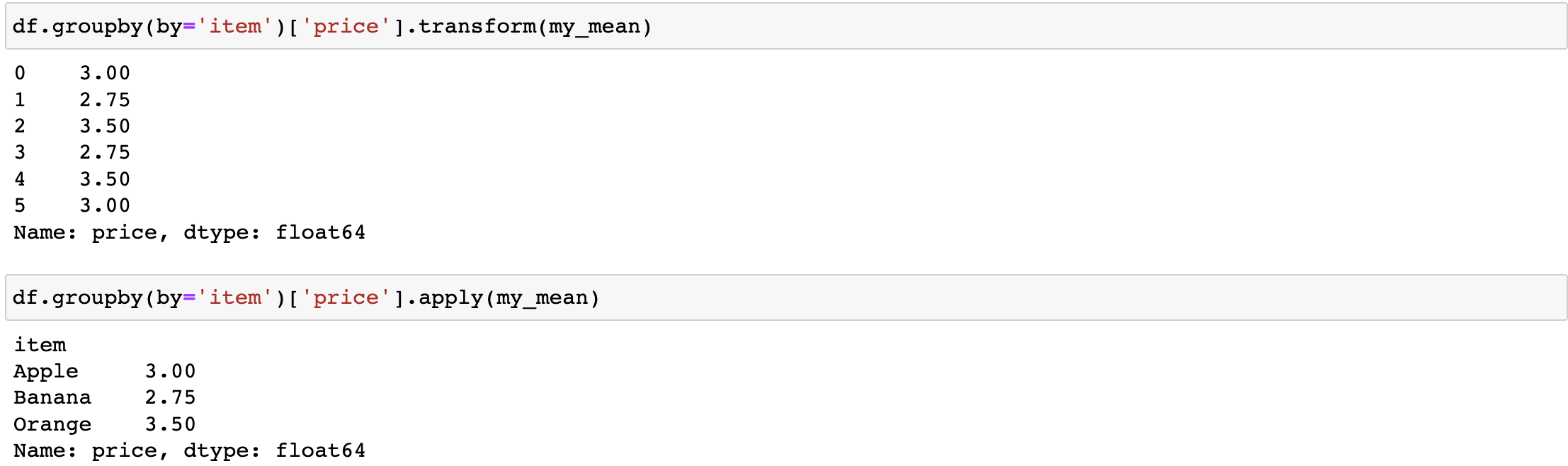
df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)def my_mean(s):
m_sum = 0
for i in s:
m_sum += i
return m_sum / len(s)
可以通过自定义的方式设计一个聚合操作
df.groupby(by='item')['price'].transform(my_mean) #经过映射
df.groupby(by='item')['price'].apply(my_mean) #不经过映射
读取type-.txt文件数据
 第一行被认成了列索引
第一行被认成了列索引
将文件中每一个词作为元素存放在DataFrame中
pd.read_csv('../data/type-.txt',header=None,sep='-') 原始的第一句话就不再是列索引

读取数据库中的数据
#连接数据库,获取连接对象
import sqlite3 as sqlite3
conn = sqlite3.connect('../data/weather_2012.sqlite')
#读取库表中的数据值
sql_df=pd.read_sql('select * from weather_2012',conn)
#将一个df中的数据值写入存储到db
df.to_sql('sql_data456',conn)
透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
透视表的优点:
pivot_table有四个最重要的参数index、values、columns、aggfunc
index参数:分类汇总的分类条件
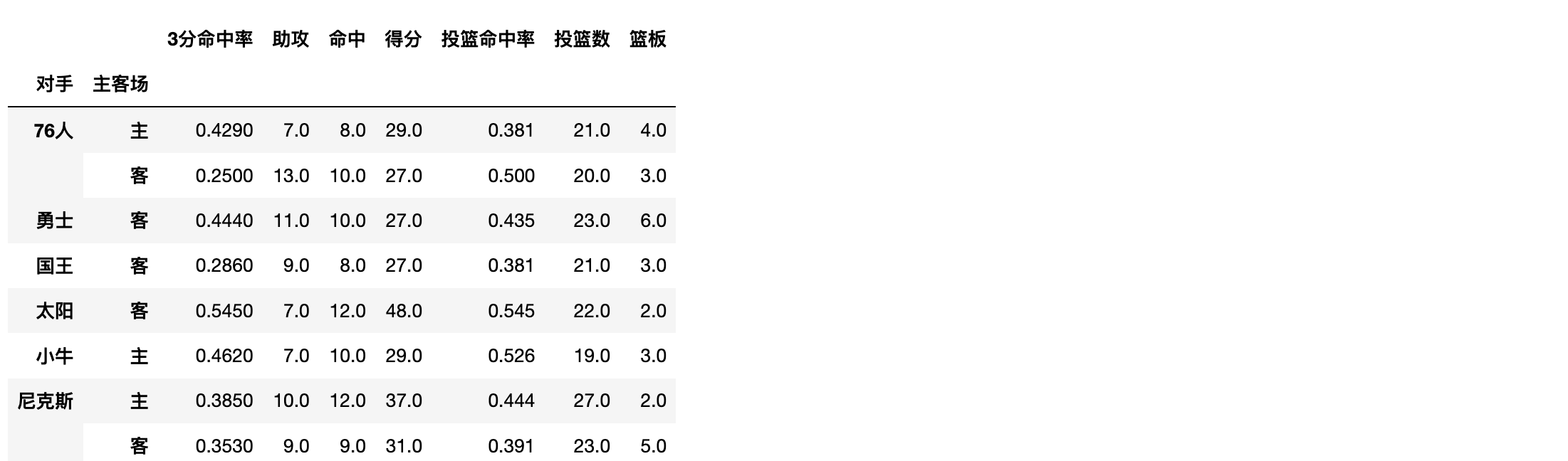
想看看对阵同一对手在不同主客场下的数据,分类条件为对手和主客场
df.pivot_table(index=['对手','主客场'])
values参数:需要对计算的数据进行筛选
如果我们只需要在主客场和不同胜负情况下的得分、篮板与助攻三项数据:
df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'])

Aggfunc参数:设置我们对数据聚合时进行的函数操作
df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'],aggfunc='sum')


Columns:可以设置列层次字段
#获取所有队主客场的总得分
df.pivot_table(index='主客场',values='得分',aggfunc='sum')

#获取每个队主客场的总得分(在总得分的基础上又进行了对手的分类)
df.pivot_table(index='主客场',values='得分',columns='对手',aggfunc='sum',fill_value=none)

pd.crosstab(index,colums)

#求出不同性别的抽烟人数
pd.crosstab(df.smoke,df.sex)

鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在尝试用ruby中的gsub函数替换字符串中的某些单词,但有时效果很好,在某些情况下会出现此错误?这种格式有什么问题吗NoMethodError(undefinedmethod`gsub!'fornil:NilClass):模型.rbclassTest"replacethisID1",WAY=>"replacethisID2andID3",DELTA=>"replacethisID4"}end另一个模型.rbclassCheck 最佳答案 啊,我找到了!gsub!是一个非常奇怪的方法。首先,它替换了字符串,所以它实际上修改了
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
两个gsub产生不同的结果。谁能解释一下为什么?代码也可在https://gist.github.com/franklsf95/6c0f8938f28706b5644d获得.ver=9999str="\tCFBundleDevelopmentRegion\n\ten\n\tCFBundleVersion\n\t0.1.190\n\tAppID\n\t000000000000000"putsstr.gsub/(CFBundleVersion\n\t.*\.).*()/,"#{$1}#{ver}#{$2}"puts'--------'putsstr.gsub/(CFBundleVersio
假设我在Store的模型中有这个非常简单的方法:defgeocode_addressloc=Store.geocode(address)self.lat=loc.latself.lng=loc.lngend如果我想编写一些不受地理编码服务影响的测试脚本,这些脚本可能已关闭、有限制或取决于我的互联网连接,我该如何模拟地理编码服务?如果我可以将地理编码对象传递到该方法中,那将很容易,但我不知道在这种情况下该怎么做。谢谢!特里斯坦 最佳答案 使用内置模拟和stub的rspecs,你可以做这样的事情:setupdo@subject=MyCl
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我有以下内容:text.gsub(/(lower)(upper)/,'\1\2')我可以将\2替换为大写吗?类似于:sed-e's/\(abc\)/\U\1/'这在Ruby中可行吗? 最佳答案 查看gsub文档:str.gsub(模式){|匹配|block}→new_str在block形式中,当前匹配字符串作为参数传入,$1、$2、$`、$&、$'等变量将被适当设置。block返回的值将替换为每次调用的匹配项。"alowerupperb".gsub(/(lower)(upper)/){|s|$1+""+$2.upcase}