怕什么
往前冲才是青春
向阳盛开才是我们

目录:
- 最宽宏大量的关键字 - auto
- 最快的关键字 - register
- 最爱打小报告的关键字 - extern
- 最名不符实的关键字 - static
首先在学auto关键字之前,我们得先了解局部变量、全局变量以及它们的作用域和生命周期
局部变量:包含在代码块中的变量叫做局部变量。局部变量具有临时性、局部性。进入代码块,自动形成局部变量,退出代码块自动释放。
注意:局部变量、自动变量、临时变量都是一回事,我们统称为局部变量
代码块:用一对花括号{}括起来的一条或多条语句叫做代码块,在语法上用{}括起来的语句视为一条语句称为代码块或者复合语句
正确示范:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<Windows.h>
int main()
{
for (int i = 0; i < 5; i++)
{
int j = 0;//i、j都是for循环的代码块局部变量
printf("%d ", j);//打印5个0,j进入for循环的代码块自动形成局部变量,退出代码块自动释放。
}
system("pause");
return 0;
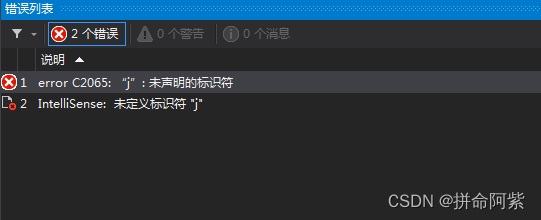
}错误示范:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<Windows.h>
int main()
{
for (int i = 0; i < 5; i++)
{
int j = 0;
printf("%d ", j);
}
printf("%d ", j);//j出了for循环的代码块已经释放了,所以会报错
system("pause");
return 0;
}
全局变量:在所有函数外定义的变量,叫做全局变量。全局变量具有全局性。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<Windows.h>
int a = 6;//全局变量
int main()
{
printf("%d\n", a);
system("pause");
return 0;
}注意:当进入代码块,发现局部变量与全局变量同名时优先使用局部变量(main函数也是函数,也有代码块{})
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<Windows.h>
int a = 6;//全局变量
int main()
{
int a = 5;//局部变量
printf("%d\n", a);//打印局部变量5
system("pause");
return 0;
}作用域概念:指的是该变量的可以被正常访问的代码区域
生命周期概念:指的是该变量从定义到被释放的时间范围,所谓的释放,指的是曾经开辟的空间”被释放“
默认的所有变量都是auto吗?
答案:当然不是,auto一般只修饰局部变量,所以的局部变量都是有auto修饰的,只不过省略了
记忆方法:局部变量又称自动变量,auto是声明自动变量,所以局部变量都是由auto声明的
结论:一般在代码块中定义的变量,即局部变量,默认都是auto修饰的,不过一般省略
注意:全局变量不能用auto修饰,否则报错
其实,CPU主要是负责进行计算的硬件单元,但是为了方便运算,一般第一步需要先把数据从内存读取到CPU内,那 么也就需要CPU具有一定的数据临时存储能力。所以现代CPU内,都集成了一组叫做寄存器的硬件,用来做临时数据的保存。

寄存器存在的本质:在硬件层面上,提高计算机的运算效率。因为不需要从内存里读取数据啦。
作用:建议尽量将所修饰变量,放入CPU寄存区中,从而达到提高效率的目的
注意:只是建议,计算机不一定会完全执行
那么什么样的变量,可以采用register呢?
- 局部的(全局会导致CPU寄存器被长时间占用)
- 不会被写入的(写入就需要写回内存,后续还要读取检测的话,register的意义在哪呢?)
- 高频被读取的(提高效率所在)
- 如果要使用,请不要大量使用,因为寄存器数量有限
注意: register修饰的变量,不能取地址(因为已经放在寄存区中了,地址是内存相关的概念)
结论:早期编译器需要人为指定register,来进行手动优化,现在不需要了。因为现在的计算机比较智能化,它会自动把一些使用频率比较高的放进寄存器(能够进行比人更好的代码优化)
多文件:将多个文件放在一个项目里叫做多文件
问题:文件里的函数和全局变量可以跨文件使用吗?
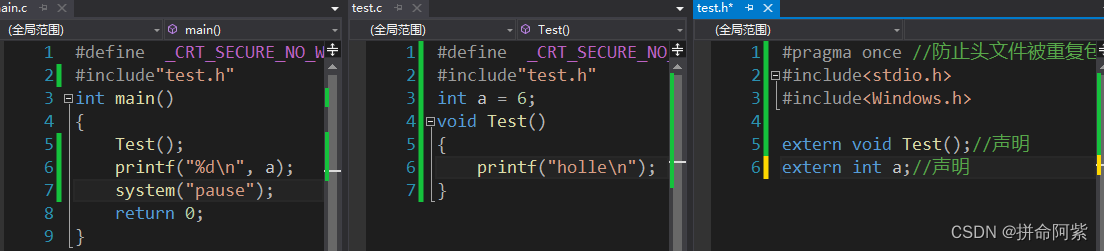
答案:函数和全局变量可以跨文件使用,但是需要用extern进行声明。
提示:当函数不声明可以运行,但是会出现警告。当全局变量不声明,会直接保错
注意:当函数声明是前面不加extern编译器也会识别出它是声明,但全局变量声明时不加extern会被编译器理解为是在定义全局变量
#pragma once预处理指令是为了防止头文件重复包含,保证头文件只被编译一次!
先声明后使用
结论:
- 全局变量,是可以跨文件,被访问的。
- 全局函数,是可以跨文件,被访问的。

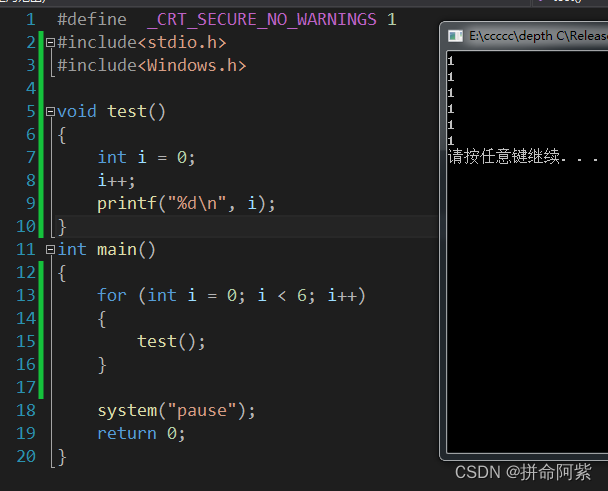
当无static修饰时:
当有static修饰时:
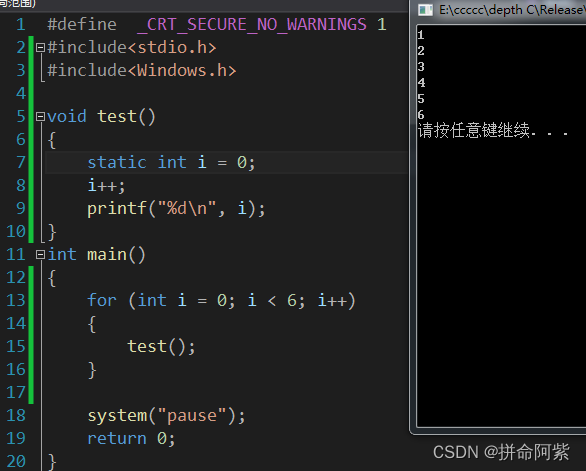
结论:static修饰局部变量,变量的生命周期变成全局周期。(作用域不变)
局部变量经static修饰后放在了全局\静态存储区
我需要一个非常简单的字符串验证器来显示第一个符号与所需格式不对应的位置。我想使用正则表达式,但在这种情况下,我必须找到与表达式相对应的字符串停止的位置,但我找不到可以做到这一点的方法。(这一定是一种相当简单的方法……也许没有?)例如,如果我有正则表达式:/^Q+E+R+$/带字符串:"QQQQEEE2ER"期望的结果应该是7 最佳答案 一个想法:你可以做的是标记你的模式并用可选的嵌套捕获组编写它:^(Q+(E+(R+($)?)?)?)?然后你只需要计算你获得的捕获组的数量就可以知道正则表达式引擎在模式中停止的位置,你可以确定匹配结束
我正在尝试学习Ruby词法分析器和解析器(whitequarkparser)以了解更多有关从Ruby脚本进一步生成机器代码的过程。在解析以下Ruby代码字符串时。defadd(a,b)returna+bendputsadd1,2它导致以下S表达式符号。s(:begin,s(:def,:add,s(:args,s(:arg,:a),s(:arg,:b)),s(:return,s(:send,s(:lvar,:a),:+,s(:lvar,:b)))),s(:send,nil,:puts,s(:send,nil,:add,s(:int,1),s(:int,3))))任何人都可以向我解释生成的
eruby和erb有什么区别?哪些考虑因素会促使我选择其中之一?我的应用程序正在为网络设备(路由器、负载平衡器、防火墙等)生成配置文件。我的计划是对配置文件进行模板化,在源文件中使用嵌入式ruby(通过eruby或erb)来执行诸如迭代生成路由器的所有接口(interface)配置block之类的操作(这些block都非常相似,仅在标签上有所不同和IP地址)。例如,我可能有这样一个配置模板文件:hostnamesample-routerlogging10.5.16.26当通过嵌入式ruby解释器(erb或eruby)运行时,会产生以下输出:hostnamesample-rout
下面的代码工作正常:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson)do|key,oldv,newv|ifkey==:aoldvelsifkey==:bnewvelsekeyendendputskerson.inspect但是如果我在“ifblock”中添加return,我会得到一个错误:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson
随着ruby被引入为新的编程救世主,我想知道是否有人基于易用性、运行所需的资源、可用性和易定制性而有偏好。两者有更好的吗? 最佳答案 好吧,任何基于Rails的社交网络应用程序的比较都应该包括insoshi(http://portal.insoshi.com/)。话虽这么说,这三个都非常相似,区别在于实现细节。Lovd和Insoshi都是完整的Rails应用程序;它旨在供您将它们用作入门工具包,并使用您自己的自定义功能对其进行扩展。另一方面,CommunityEngine是一个Rails插件。这意味着您可以更轻松地向现有Rail
我有1.8.6附带的VanillaMacOSXLeopard。我是RoR的新手,所以会学习网上的教程。在使用更高版本的Ruby时,我是否可能会发现遵循它们的问题?我目前正在查看提到1.8.6和1.8.7的这个-http://www.railstutorial.org/book 最佳答案 RoR教程对两者都适用,但如果您正在学习Ruby,则应该学习1.9。Rails3将不支持1.8.6,所以我会选择1.8.7或1.9。我还推荐使用RVM在Ruby版本之间切换。 关于ruby-on-rail
我定义了一个方法:defmethod(one:1,two:2)[one,two]end当我这样调用它时:methodone:'one',three:'three'我得到:ArgumentError:unknownkeyword:three我不想从散列中一个一个地提取所需的键或排除额外的键。除了像这样定义方法之外,有没有办法规避这种行为:defmethod(one:1,two:2,**other)[one,two,other]end 最佳答案 如果不想写**other中的other,可以省略。defmethod(one:1,two:2
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion我正在为Rails3/ActiveRecord项目寻找一个相对简单的状态机插件。我做了一些研究并提出了以下插件:转换:https://github.com/qoobaa/transitions从旧的ActiveRecord状态机库中提取
一些我找到的选项是ActiveCouchCouchRESTCouchPotatoRelaxDBcouch_foo我更喜欢GitHub上的项目,因为这让我更容易fork和推送修复。所有这些都符合该要求。我习惯了Rails,所以我喜欢像ActiveRecord模型一样工作的东西。另一方面,我也不希望我和Couch之间太多--毕竟我使用它作为我的数据库是有原因的。最后,它们似乎都得到了相当积极的维护(couch_foo可能是个异常(exception))。所以我想这归结为(不可否认和不幸的)主观:有没有人对他们有过好的或坏的经历? 最佳答案
我知道我能做到:classParentdefinitialize(args)args.eachdo|k,v|instance_variable_set("@#{k}",v)endendendclassA但我想使用关键字参数来更清楚地说明可以接受哪个散列键方法(并进行验证表明不支持此键)。所以我可以写:classAdefinitialize(param1:3,param2:4)@param1=param1@param2=param2endend但是有没有可能写一些更短的东西而不是@x=x;@y=y;...从传递的关键字参数初始化实例变量?是否可以访问作为哈希传递的关键字参数?