哈希表:也叫做散列表。是根据关键字和值(Key-Value)直接进行访问的数据结构。也就是说,它通过关键字 key 和一个映射函数 Hash(key) 计算出对应的值 value,然后把键值对映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做哈希函数(散列函数),用于存放记录的数组叫做 哈希表(散列表)。 哈希表的关键思想是使用哈希函数,将键 key 和值 value 映射到对应表的某个区块中。可以将算法思想分为两个部分:
哈希表的原理示例图如下所示:
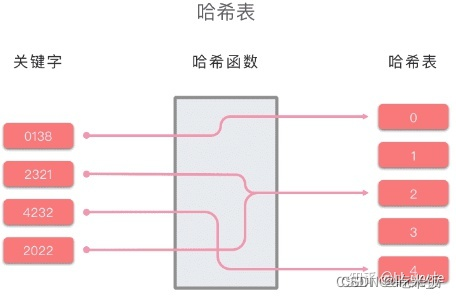
哈希函数:将哈希表中元素的关键键值映射为元素存储位置的函数。一般来说,哈希函数会满足以下几个条件:
在哈希表的实际应用中,关键字的类型除了数字类型,还有可能是字符串类型、浮点数类型、大整数类型,甚至还有可能是几种类型的组合。一般会将各种类型的关键字先转换为整数类型,再通过哈希函数,将其映射到哈希表中。 而关于整数类型的关键字,通常用到的哈希函数方法有:直接定址法、除留余数法、平方取中法、基数转换法、数字分析法、折叠法、随机数法、乘积法、点积法等。
哈希冲突:不同的关键字通过同一个哈希函数可能得到同一哈希地址,即 key1 ≠ key2,而 Hash(key1) = Hash(key2),这种现象称为哈希冲突。
开放地址法:指的是将哈希表中的「空地址」向处理冲突开放。当哈希表未满时,处理冲突时需要尝试另外的单元,直到找到空的单元为止。H(i) = (Hash(key) + F(i)) \% m,i = 1, 2, 3, ..., n (n ≤ m - 1)
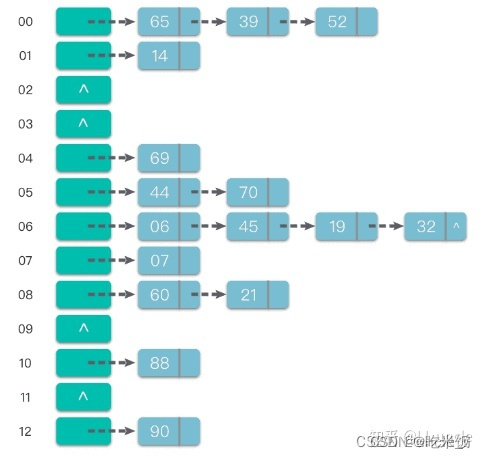
链地址法:将具有相同哈希地址的元素(或记录)存储在同一个线性链表中。 链地址法是一种更加常用的哈希冲突解决方法。相比于开放地址法,链地址法更加简单。 假设哈希函数产生的哈希地址区间为 [0, m - 1],哈希表的表长为 m。则可以将哈希表定义为一个有 m 个头节点组成的链表指针数组 T。
这样在插入关键字的时候,只需要通过哈希函数 Hash(key) 计算出对应的哈希地址 i,然后将其以链表节点的形式插入到以 T[i] 为头节点的单链表中。在链表中插入位置可以在表头或表尾,也可以在中间。如果每次插入位置为表头,则插入操作的时间复杂度为 O(1)。
而在在查询关键字的时候,只需要通过哈希函数 Hash(key) 计算出对应的哈希地址 i,然后将对应位置上的链表整个扫描一遍,比较链表中每个链节点的键值与查询的键值是否一致。查询操作的时间复杂度跟链表的长度 k 成正比,也就是 O(k)。对于哈希地址比较均匀的哈希函数来说,理论上讲,k= n//m,其中 n 为关键字的个数,m 为哈希表的表长。
相对于开放地址法,采用链地址法处理冲突要多占用一些存储空间(主要是链节点占用空间)。但它可以减少在进行插入和查找具有相同哈希地址的关键字的操作过程中的平均查找长度。这是因为在链地址法中,待比较的关键字都是具有相同哈希地址的元素,而在开放地址法中,待比较的关键字不仅包含具有相同哈希地址的元素,而且还包含哈希地址不相同的元素。
#pragma once
#include "RBTree.h"
template<typename Key, typename Value>
class HashTable {
private:
int M;
int size;
RBTree<Key, Value> *hashTable[];
int hash(Key key) {
return (hashCode(key) & 0x7fffffff) % M;
}
int hashCode(Key key) {
std::hash<Key> key_hash;
return key_hash(key);
}
public:
HashTable(int M) : M(M), size(0) {
*hashTable = new RBTree<Key, Value>[M]{};
for (int i = 0; i < M; ++i) {
hashTable[i] = new RBTree<Key, Value>();
}
}
HashTable() : M(97), size(0) {
*hashTable = new RBTree<Key, Value>[M]{};
for (int i = 0; i < M; ++i) {
hashTable[i] = new RBTree<Key, Value>();
}
}
int getSize() const {
return size;
}
void add(Key key, Value value) {
RBTree<Key, Value> *rbTree = hashTable[hash(key)];
if (rbTree->contains(key)) {
rbTree->set(key, value);
} else {
rbTree->add(key, value);
size++;
}
}
Value *remove(Key key) {
}
bool contains(Key key) {
return hashTable[hash(key)]->contains(key);
}
Value *get(Key key) {
return hashTable[hash(key)]->get(key);
}
void set(Key key, Value value) {
RBTree<Key, Value> *rbTree = hashTable[hash(key)];
if (!rbTree->contains(key)) {
throw key + "doesn't exist";
}
rbTree->set(key, value);
}
};
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
我在搜索我的值是方法的散列时遇到问题。我只是不想运行plan_type与键匹配的方法。defmethod(plan_type,plan,user){foo:plan_is_foo(plan,user),bar:plan_is_bar(plan,user),waa:plan_is_waa(plan,user),har:plan_is_har(user)}[plan_type]end目前如果我传入“bar”作为plan_type,所有方法都会运行,我怎么能只运行plan_is_bar方法呢? 最佳答案 这个变体怎么样?defmethod
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu
因此,对于普通哈希,您可以使用它来获取key:hash.keys如何获取如下所示的多维哈希的第二维键:{""=>{"first_name"=>"test","last_name"=>"test_l","username"=>"test_user","title"=>"SalesManager","office"=>"test","email"=>"test@test.com"}}每个项目都是唯一的。所以我想从上面得到的键是:first_name,last_name,username,title,officeandemail 最佳答案
我正在尝试循环哈希数组。当我到达获取枚举器开始循环的位置时,出现以下错误:undefinedmethod`[]'fornil:NilClass我的代码如下所示:defextraireAttributs(attributsParam)classeTrouvee=falsescanTrouve=falseownerOSTrouve=falseownerAppTrouve=falseresultat=Hash.new(0)attributs=Array(attributsParam)attributs.eachdo|attribut|#CRASHESHERE!!!typeAttribut=a
这个问题在这里已经有了答案:HashsyntaxinRuby[duplicate](1个回答)关闭5年前。我有一个Recipe,其中包含以下未通过lint测试的代码:service'apache'dosupports:status=>true,:restart=>true,:reload=>trueend失败并出现错误:UsethenewRuby1.9hashsyntax.supports:status=>true,:restart=>true,:reload=>true不确定新语法是什么样的...有人可以帮忙吗?