文章目录
🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
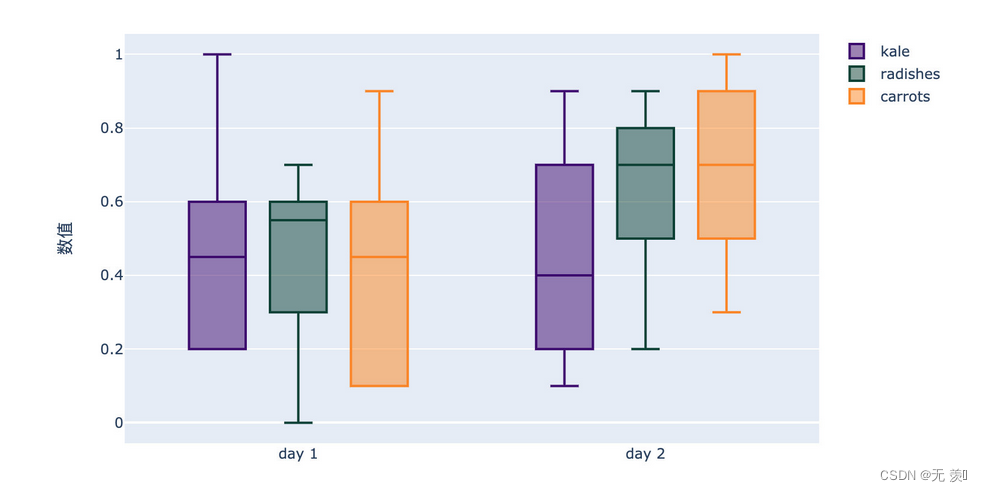
箱形图(Box-plot)又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。在各种领域也经常被使用,常见于品质管理。它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比 较。箱线图的绘制方法是:先找出一组数据的上边缘、下边缘、中位数和两个四分位数;然后, 连接两个四分位数画出箱体;再将上边缘和下边缘与箱体相连接,中位数在箱体中间。箱形图是由首位两个四分位数(Q1,Q3)以及中位数(Q2)组成的,它能够反映出一组数据的基本统计特性,如分布的范围、中位数、变异程度等。
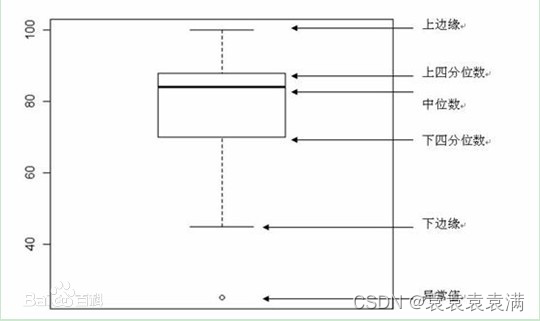
特点:箱形图是概括性较强的一种图,它能够准确反映出数据的主要特点,包括最大值、最小值、四分位数、中位数和实例数,同时观测异常点。
应用场景:箱形图主要用于比较多组数据的分布情况,它非常适用于表示连续变量的分布和比较,是显著进行数据可视化的一种常用工具。
“盒式图"或叫"盒须图”"箱形图"boxplot(也称箱须图(Box-whiskerPlot)须图又称为箱形图,其绘制须使用常用的统计量,能提供有关数据位置和分散情况的关键信息,尤其在比较不同的母体数据时更可表现其差异。
主要包含六个数据节点,将一组数据从大到小排列,分别计算出他的上边缘,上四分位数Q3,中位数,下四分位数Q1,下边缘,还有一个异常值。标示了图中每条线表示的含义,其中应用到了分位值(数)的概念,如下图所示:
matplotlib绘制箱形图的函数是boxplot(),以下是函数代码:
import matplotlib.pyplot as plt
plt.boxplot(
x, notch=None, sym=None, vert=None, whis=None,
positions=None, widths=None, patch_artist=None,
bootstrap=None, usermedians=None, conf_intervals=None,
meanline=None, showmeans=None, showcaps=None, showbox=None,
showfliers=None, boxprops=None, labels=None, flierprops=None,
medianprops=None, meanprops=None, capprops=None,
whiskerprops=None, manage_ticks=True, autorange=False,
zorder=None, *, data=None)
参数说明如下:
下面代码绘制一个简单的箱型图,其中Q1、Q3 分别表示上下四分位数;Q2 表示中位数;low_limit、upper_limit 分别表示下限和上限;val 表示异常值。在绘制箱形图时,设置sym="o"即可显示异常值:
import pandas as pd
import matplotlib.pyplot as plt
data = {'num': ['1', '2', '3', '4', '5', '6', '7'],
'value': [-15, 7, 10, 15, 20, 33, 5]}
df = pd.DataFrame(data)
plt.boxplot(x=df['value'], whis=1.5, widths=0.5, patch_artist=True, showmeans=True, boxprops={'facecolor': 'c'},
flierprops={'markerfacecolor': 'red', 'markersize': 4},
meanprops={'marker': '*', 'markerfacecolor': 'skyblue'}, medianprops={'linestyle': '--', 'color': 'orange'},
capprops={'color': 'r'})
Q1 = df['value'].quantile(q=0.25)
Q2 = df['value'].quantile(q=0.5)
Q3 = df['value'].quantile(q=0.75)
low_limit = Q1 - 1.5 * (Q3 - Q1)
upper_limit = Q3 + 1.5 * (Q3 - Q1)
print('下四分位数:', Q1)
print('中位数:', Q2)
print('上四分位数:', Q3)
print('下限:', low_limit)
print('上限:', upper_limit)
# 查找异常值
val = df['value'][(df['value'] > upper_limit) | (df['value'] < low_limit)]
print('异常值:', val)
#显示图像
plt.show()
运行结果:
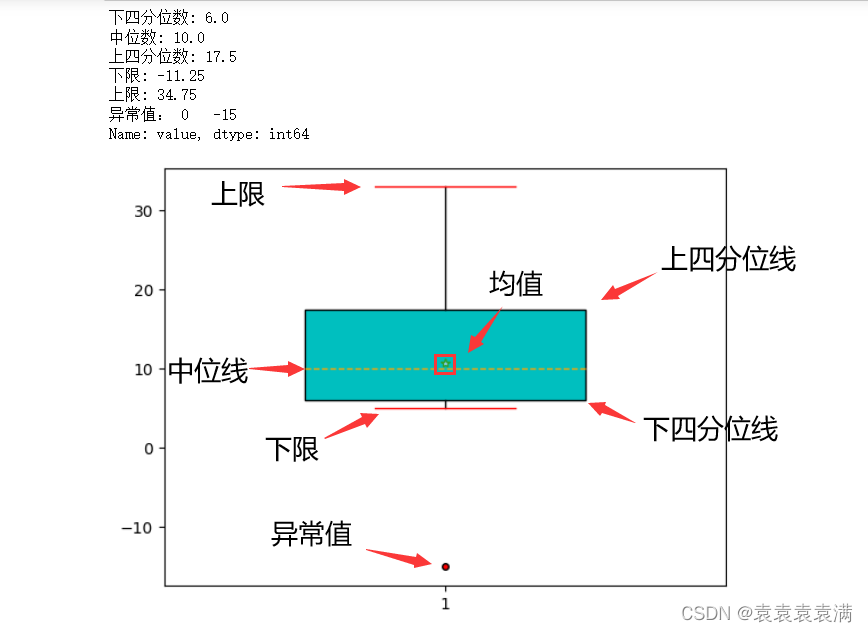
数学层面理解箱形图每个部分的含义(下四分位线,中位数,上四分位数,上限,下限,异常值,极端异常值):
计算方法:
极端异常值:
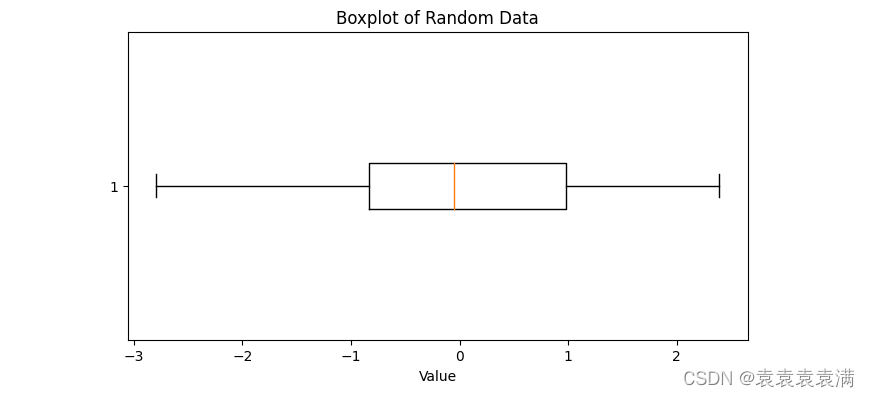
与基本箱形图类似,但是箱形图是水平的,适用于较长的标签或较短的数据集:
import matplotlib.pyplot as plt
import numpy as np
# 生成一组随机数据
np.random.seed(123)
data = np.random.normal(0, 1, 100)
# 绘制水平箱形图
fig, ax = plt.subplots(figsize=(8, 4))
ax.boxplot(data, vert=False)
# 设置图表标题和坐标轴标签
ax.set_title('Boxplot of Random Data')
ax.set_xlabel('Value')
# 显示图表
plt.show()
代码解释:
首先导入matplotlib.pyplot和numpy模块。
使用numpy.random.normal函数生成一组均值为0、标准差为1的正态分布随机数据。
创建一个图表对象fig和一个坐标轴对象ax,并设置图表大小为8x4。
使用坐标轴对象的boxplot方法绘制水平箱形图,其中vert=False表示绘制水平箱形图。
使用坐标轴对象的set_title和set_xlabel方法设置图表标题和坐标轴标签。
使用matplotlib.pyplot的show函数显示图表。
运行结果:
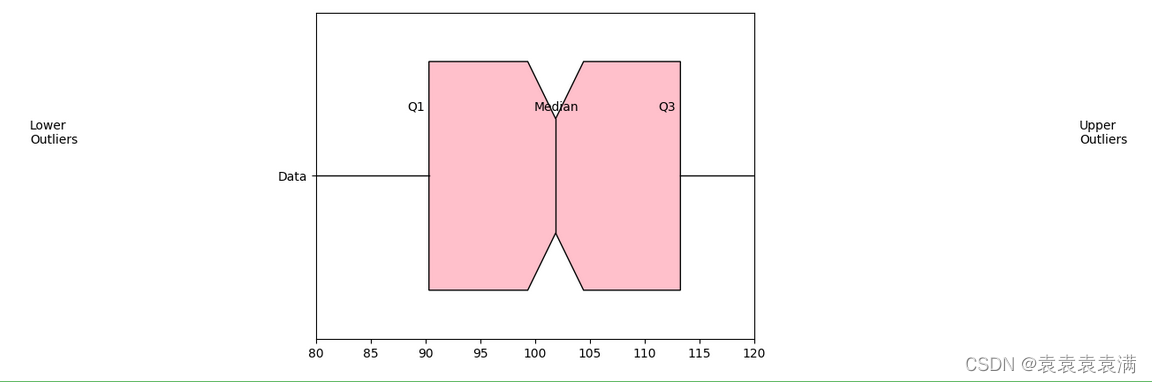
在基本箱形图的基础上,为中位数添加一个缺口,以显示置信区间。如果数据中存在离群值(Outlier),箱形图就会失去一些效果。因此,有时候需要绘制带有缺口的箱形图来突出离群值的存在。
在下面示例中,我们使用了 notch=True 参数来绘制缺口。缺口的位置是根据数据分布情况自动计算的。我们还使用了 patch_artist=True 参数来填充箱体的颜色,并使用相应的参数来设置箱体、须、中位数和离群值的样式。最后,我们添加了一些说明来解释图表中的每个部分:
import matplotlib.pyplot as plt
import numpy as np
# 生成随机数据
np.random.seed(10)
data = np.random.normal(100, 20, 200)
# 计算箱形图的五个关键值
q1, median, q3 = np.percentile(data, [25, 50, 75])
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
# 绘制箱形图
fig, ax = plt.subplots()
ax.boxplot(data, notch=True, vert=False, widths=0.7, patch_artist=True,
boxprops=dict(facecolor='pink', color='black'),
whiskerprops=dict(color='black'),
medianprops=dict(color='black'),
capprops=dict(color='black'))
# 绘制离群值
outliers = data[(data < lower_bound) | (data > upper_bound)]
ax.scatter(outliers, np.ones(len(outliers)), marker='o', color='black')
# 设置坐标轴
ax.set_yticks([1])
ax.set_yticklabels(['Data'])
ax.set_xlim([80, 120])
ax.axvline(lower_bound, linestyle='--', color='black')
ax.axvline(upper_bound, linestyle='--', color='black')
# 添加说明
ax.text(lower_bound - 2, 1.1, 'Lower\nOutliers', fontsize=10)
ax.text(upper_bound + 2, 1.1, 'Upper\nOutliers', fontsize=10)
ax.text(q1 - 2, 1.2, 'Q1', fontsize=10)
ax.text(median - 2, 1.2, 'Median', fontsize=10)
ax.text(q3 - 2, 1.2, 'Q3', fontsize=10)
plt.show()
运行结果:
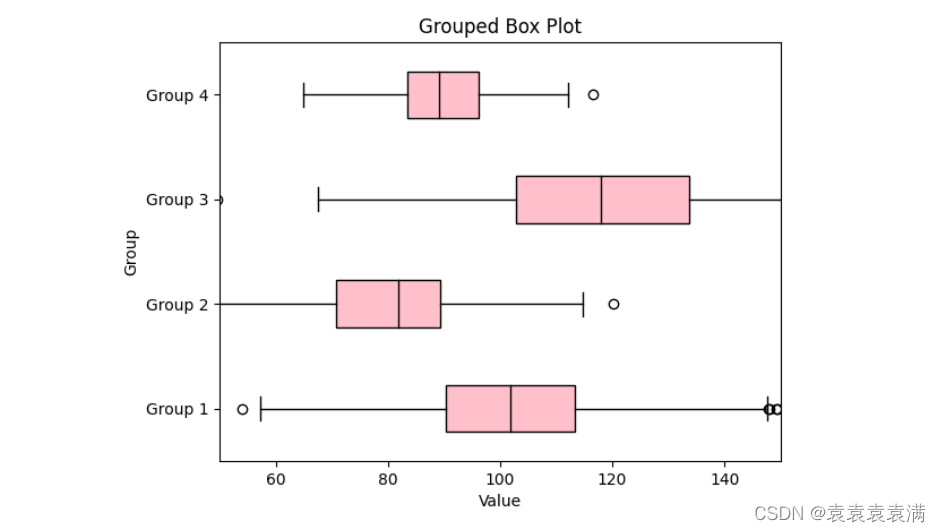
群组箱形图(Grouped box plot)是一种用于比较多组数据分布情况的图表。它用于比较两个或多个数据集的中位数、四分位数和异常值。可以将多组数据按照分类变量分组,并在同一图表中展示出来,以便于比较不同组之间的差异。
在下面示例中,我们使用了 labels 参数将数据按照分类变量分组,并使用了 vert=False 参数将图表方向设置为水平方向。我们还使用了相应的参数来设置箱体、须、中位数的样式,并使用了 patch_artist=True 参数来填充箱体的颜色。最后,我们添加了标题和标签来解释图表的含义:
import matplotlib.pyplot as plt
import numpy as np
# 生成随机数据
np.random.seed(10)
data1 = np.random.normal(100, 20, 200)
data2 = np.random.normal(80, 15, 200)
data3 = np.random.normal(120, 25, 200)
data4 = np.random.normal(90, 10, 200)
# 将数据按照分类变量分组
data = [data1, data2, data3, data4]
labels = ['Group 1', 'Group 2', 'Group 3', 'Group 4']
# 绘制群组箱形图
fig, ax = plt.subplots()
ax.boxplot(data, labels=labels, vert=False, patch_artist=True,
boxprops=dict(facecolor='pink', color='black'),
whiskerprops=dict(color='black'),
medianprops=dict(color='black'),
capprops=dict(color='black'))
# 设置坐标轴
ax.set_xlim([50, 150])
# 添加标题和标签
ax.set_title('Grouped Box Plot')
ax.set_xlabel('Value')
ax.set_ylabel('Group')
plt.show()
运行结果:
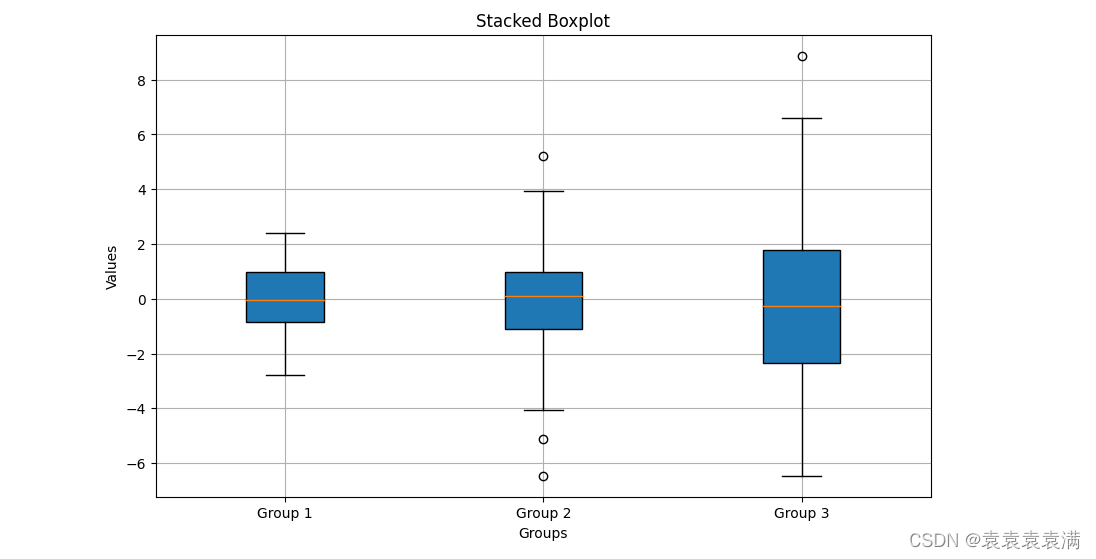
堆叠箱形图(Stacked box plot)是一种用于比较两个或多个数据集的分布情况,将箱形图堆叠在一起。它可以将多组数据按照分类变量分组,并在同一图表中展示出来,并且在每个组内部又按照另一个分类变量进行分层,以便于比较不同组之间和不同层之间的差异。
堆叠箱形图显示了三个组之间的分布,每个组有100个观测值。每个箱子代表每个组的中位数、上下四分位数和最大/最小值。箱子的颜色表示每个组的标识符,即Group 1、Group 2和Group 3。可以看到,Group 1和Group 3的数据分布相似,而Group 2的数据分布略有不同:
import matplotlib.pyplot as plt
import numpy as np
# 生成数据集
np.random.seed(123)
data = [np.random.normal(0, std, 100) for std in range(1, 4)]
# 绘制堆叠箱形图
fig, ax = plt.subplots(figsize=(10, 6))
ax.boxplot(data, vert=True, patch_artist=True, labels=['Group 1', 'Group 2', 'Group 3'])
# 显示网格
plt.grid(True)
# 设置箱子颜色
colors = ['#0000FF', '#FFA500', '#00FFFF']
for patch, color in zip(ax.artists, colors):
patch.set_facecolor(color)
# 添加标题和标签
ax.set_title('Stacked Boxplot')
ax.set_xlabel('Groups')
ax.set_ylabel('Values')
# 展示图表
plt.show()
运行结果:
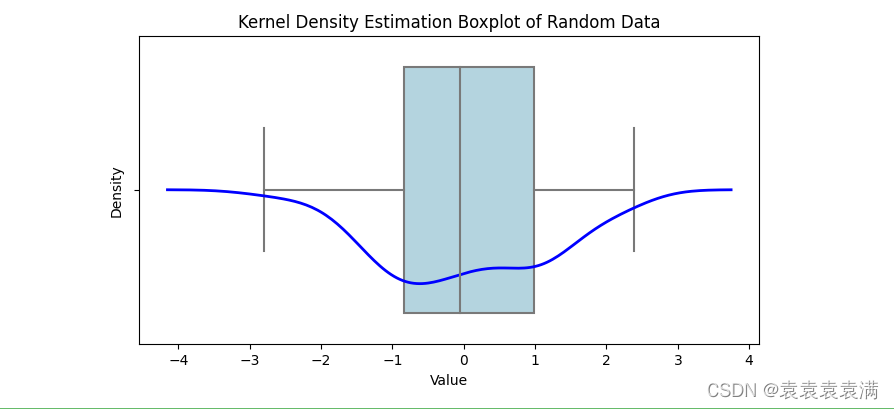
核密度估计箱形图是一种结合了核密度估计和箱形图的图表,添加核密度估计曲线,它可以更准确地反映数据的分布情况,并且能够同时显示出异常值等信息:
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
# 生成一组随机数据
np.random.seed(123)
data = np.random.normal(0, 1, 100)
# 绘制核密度估计箱形图
fig, ax = plt.subplots(figsize=(8, 4))
sns.boxplot(x=data, ax=ax, color='lightblue')
sns.kdeplot(x=data, ax=ax, color='blue', linewidth=2)
# 设置图表标题和坐标轴标签
ax.set_title('Kernel Density Estimation Boxplot of Random Data')
ax.set_xlabel('Value')
# 显示图表
plt.show()
代码解释:
首先导入matplotlib.pyplot、numpy和seaborn模块。
使用numpy.random.normal函数生成一组均值为0、标准差为1的正态分布随机数据。
创建一个图表对象fig和一个坐标轴对象ax,并设置图表大小为8x4。
使用seaborn的boxplot方法绘制箱形图,并设置颜色为'lightblue'。
使用seaborn的kdeplot方法绘制核密度估计图,并设置颜色为'blue'、线宽为2。
使用坐标轴对象的set_title和set_xlabel方法设置图表标题和坐标轴标签。
使用matplotlib.pyplot的show函数显示图表。
运行结果:
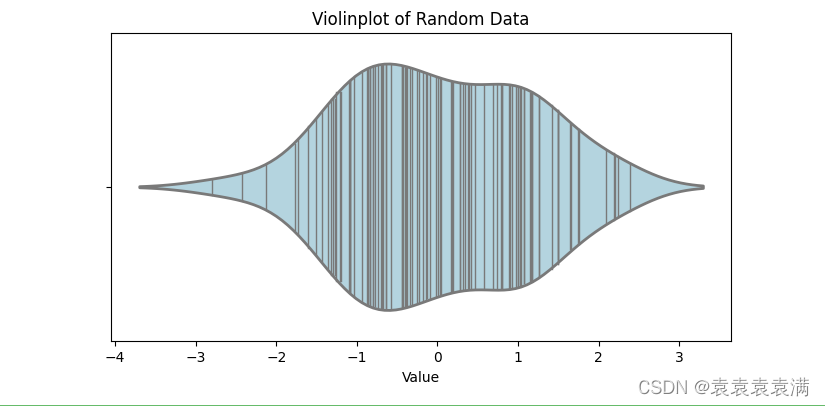
小提琴箱形图是一种结合了箱形图和核密度估计的图表,它可以更好地反映数据的分布情况,并且能够同时显示出异常值等信息:
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
# 生成一组随机数据
np.random.seed(123)
data = np.random.normal(0, 1, 100)
# 绘制小提琴箱形图
fig, ax = plt.subplots(figsize=(8, 4))
sns.violinplot(x=data, ax=ax, color='lightblue', inner='stick', linewidth=2)
# 设置图表标题和坐标轴标签
ax.set_title('Violinplot of Random Data')
ax.set_xlabel('Value')
# 显示图表
plt.show()
代码解释:
首先导入matplotlib.pyplot、numpy和seaborn模块。
使用numpy.random.normal函数生成一组均值为0、标准差为1的正态分布随机数据。
创建一个图表对象fig和一个坐标轴对象ax,并设置图表大小为8x4。
使用seaborn的violinplot方法绘制小提琴箱形图,并设置颜色为'lightblue'、内部样式为'stick'、线宽为2。
使用坐标轴对象的set_title和set_xlabel方法设置图表标题和坐标轴标签。
使用matplotlib.pyplot的show函数显示图表。
运行结果:
我即将开始一个将录制和编辑音频文件的项目,我正在寻找一个好的库(最好是Ruby,但会考虑Java或.NET以外的任何库)以进行实时可视化波形。有人知道我应该从哪里开始搜索吗? 最佳答案 要流入浏览器的数据量很大。Flash或Flex图表可能是唯一能提高内存效率的解决方案。Javascript图表往往会因大型数据集而崩溃。 关于ruby-Ruby中的波形可视化,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
多年来,我在各种网站上遇到过各种问题,用户在字符串和文本字段的开头/结尾放置空格。有时这些会导致格式/布局问题,有时会导致搜索问题(即搜索顺序看起来不对,但实际上并非如此),有时它们实际上会使应用程序崩溃。我认为这会很有用,而不是像我过去所做的那样放入一堆before_save回调,向ActiveRecord添加一些功能以在保存之前自动调用任何字符串/文本字段上的.strip,除非我告诉它不是,例如do_not_strip:field_x,:field_y或类定义顶部的类似内容。在我去弄清楚如何做到这一点之前,有没有人看到更好的解决方案?明确一点,我已经知道我可以做到这一点:befor
我有一个Highstock图表(带有标记和阴影的线条),并且想以编程方式显示一个highstock工具提示,例如,当我选择某个表上的一行(包含图表数据)我想显示相应的highstock工具提示。这可能吗? 最佳答案 股票图表thissolution不起作用:在thisexample你必须更换这个:chart.tooltip.refresh(chart.series[0].data[i]);为此:chart.tooltip.refresh([chart.series[0].points[i]]);解决方案可用here.
我有一个RubyonRails应用程序和一个具有以下结构的PostgreSQL数据库:classA只有几个A,而且增长缓慢(比如一个月5个)。每个A有数千个B,每个B有数万个C(因此每个A有数百万个C)。A是独立的,并且永远不会同时需要来自不同A的B和C(即在同一查询中)。我的问题是现在我只有几个A,ActiveRecord查询需要很长时间。当C的表有数千万行时,查询将永远无法进行。我正在考虑水平扩展数据库(即A的一张表,B的一张表和每个A的一张C的表)。但我不知道该怎么做。我猜这是一种分片,但我无法弄清楚如何动态创建数据库表并使用ActiveRecord访问数据(如果该表取决于我正在
我正在尝试为ChefRecipe编写一个库,以简化一些常见的搜索。例如,我希望能够在cookbook/libraries/library.rb中执行类似的操作,然后从同一Recipe中的Recipe中使用它:moduleExampledefself.search_attribute(attribute_name)returnsearch(:nodes,node[attribute_name])endend问题是,在Chef库文件中,node对象或search函数都不可用。似乎可以使用Chef::Search::Query.new().search(...)进行搜索,但我找不到任何可以访
Unity数据可视化图表插件XCharts3.0发布历时8个多月,业余时间,断断续续,XCharts3.0总算发布了。如果要打个满意度,我给3.0版本来个80分。对于代码框架结构设计的调整改动,基本符合预期,甚是满意。相比之前的1.0和2.0版本,我认为3.0才是一个拿得出手给广大开发者使用的版本。1.0发布的时候,很兴奋,从0.1到1.0,也磨了一年,真的等不及想给大家试用了,还特地写过一篇文章以示庆祝。那个时候,1.0虽然还还不够完善,功能也不够丰富,但它是XCharts的开始,没有1.0,也就没有后面的2.0和3.0。后面的2.0发布,做了很多改进和优化,随着版本迭代,慢慢的发现有不少硬
本人是音乐爱好者,从小就特别喜欢那个随着音乐跳动的方框效果,就是这个:arduino上一大把对,我忍你很久了,我就想用mpy做,全网没有,行我自己研究。果然兴趣是最好的老师,我之前有篇博客专门讲音频,有兴趣的可以回顾一下。提到可视化频谱,必然绕不开fft,大学学过这玩意,当时一心玩,老师讲的一个字都么听进去,网上教程简略扫了一下,大该就是把时域转频域的工具,我大mpy居然没有fft函数,奶奶的,先放着。音频信息如何收集?第一种傻瓜式的ADC,模拟转数字,原始粗暴,第二种,I2S库,我之前博客有讲过,数据是PCM编码。然后又去学PCM编码,一学豁然开朗,舒服,以代码为例:audio_in=I2S
我以前在Laravel4上工作过,它有一个很棒的日志查看器工具laravellogviewer查看demo我正在寻找与Rubyonrails4.2非常相似的东西,如果你们知道Rails4.2的任何好的可视化日志记录GEM,请告诉我..从代码我需要记录不同的日志级别,这个工具应该直观地组织我的日志,谢谢.. 最佳答案 这应该可以帮助您入门https://github.com/shadabahmed/logstasher如其所说Thisgemisheavilyinspiredfromlograge,butit'sfocusedonone
有没有一种简单的方法可以获取集合中某个属性的平均值?例如,每个用户都有一个分数。给定一组用户(@users),您如何获得该组的平均分?有没有类似@users.average(:score)的东西?我想我在数据库字段中遇到过类似的东西,但我需要它来处理集合...... 最佳答案 对于你的问题,实际上可以这样做:@users.collect(&:score).sum.to_f/@users.lengthif@users.length>0早些时候我认为,@users.collect(&:score).average会起作用。对于数据库字段