这部分不会详细展开,以后写教程时会深入。以下只是核心概念,是绝大多数 WebGPU 原生程序要接触的,并不是全部。
适配器,也就是 GPUAdapter,指代真正的物理显卡,WebGPU 给了个对象来代替它:
const adapter = await navigator.gpu.requestAdapter()
它提供了一个最重要行为,请求设备对象 GPUDevice:
const device = await adapter.requestDevice()
那么什么是 Device?其实,显卡很忙。
WebGPU 程序只是三大图形 API 中某个的“上层封装”,除了 WebGPU,调用三大图形 API 的程序远不止,游戏、三维建模工具、视频编解码器,都有可能会调用,甚至会直接调取 GPU 厂商给的 SDK 或驱动程序。
显然,作为显卡“本身”,适配器为了极高效率地工作,喂给它的数据资源和指令最好就是翻译过的,尽可能专注地执行计算 —— 就像大老板不可能日理万机一样,最好给到老板的决策资料,就是经过整理的,他要做的就是使用他多年的经验快速决策、签字(效率高的老总 = RTX4090,超市小老板 = GT1030)。
那么,谁负责与各个部门(各个对显卡有需要的程序)负责人沟通具体业务呢?
我认为是老总的全权代理人,一般是秘书 + 副总经理。
不同封装有不同的概念,至少在 WebGPU 中,这个代理人叫做“设备”,GPUDevice,它几乎就是显卡的分身,WebGPU 程序中所要调取的资源、创建的对象、要触发的行为,都交给设备对象实现。
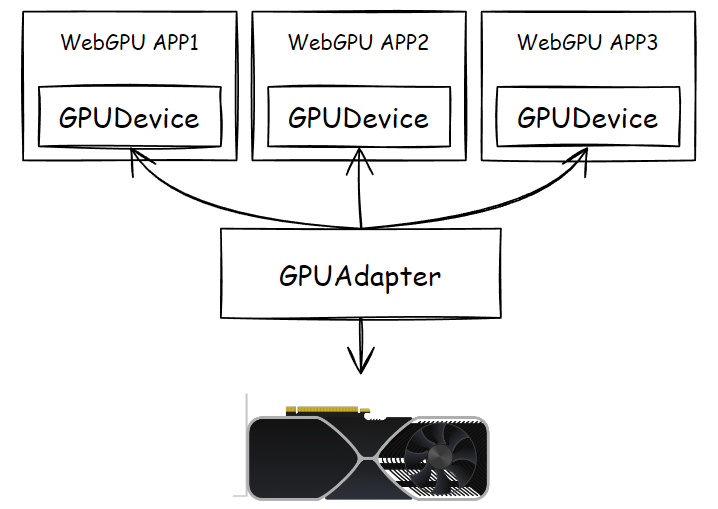
每个 WebGPU 程序应该都有自己的 GPUDevice,不同的设备对象创建的 Buffer、Texture 等资源是不互通的,而适配器呢,一般情况下是同一个,除非你短时间内把电脑的显卡给更改过,前一会儿是独显,过一会儿可能是核显了(这段话还有待技术验证,仅为我不负责任的猜测)。
如果你写过原生的 WebGL,你可能会联想到 gl 上下文变量了,没错,设备对象大部分时候就是 gl 上下文的作用,但是是有本质区别的。
缓冲、纹理,即 GPUBuffer、GPUTexture 均是 GPU 显存中的数据对象,能在客户端代码(如果没特别说明,就是指浏览器端的 JavaScript)组织、创建、上载数据、相互转化、反读数据。
WebGPU 进行渲染绘图时,Canvas 是一个特殊的 GPUTexture。
采样器则是着色器程序对纹理采样时的参数封装。
看起来是 WebGL 类似对象 WebGLBuffer、WebGLTexture 以及纹理采样函数的“升级”,实际上调用时提供了更细致的传参,在数据上载、纹理与缓冲相互转化、再从显存读取到内存的“映射机制”上却大有不同。
这三个对象被称作“资源”,均由 GPUDevice 创建。
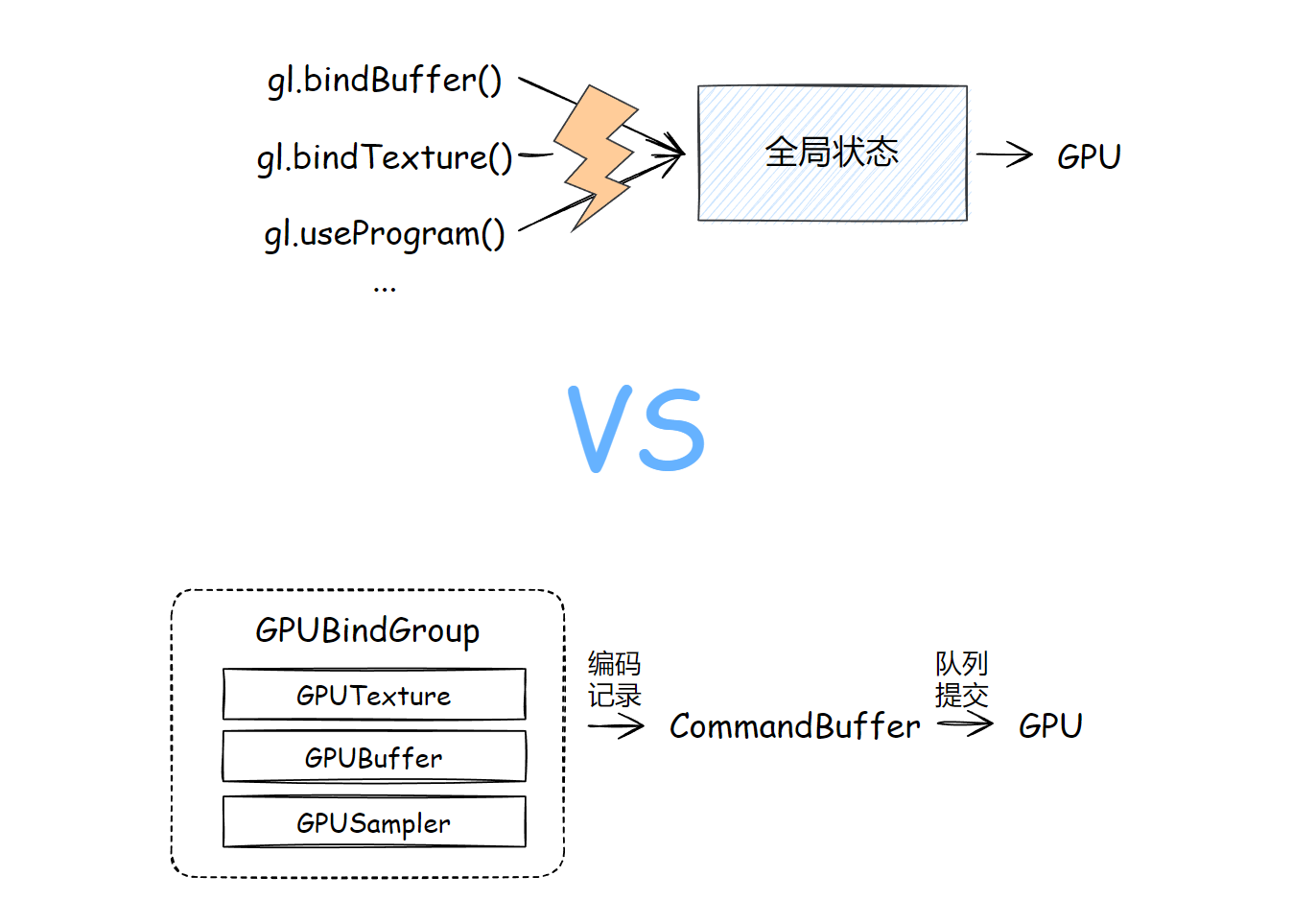
绑定组,我更愿意称之为“资源绑定组”,即 GPUBindGroup;资源即“缓冲、纹理、采样器”的任意组合。
使用绑定组,允许把一组你需要的资源“打组”,传进着色器代码中,它与下面的“管线”是紧密相关的。
为什么要打组呢?为什么我不能写个函数,按我需要把 GPUBuffer、GPUTexture、GPUSampler 挨个像 WebGL 一样绑定到某个绑定点呢?
有两个原因:
绑定组是由 GPUDevice 创建的,是由第 ⑤ 小节中的 可编程通道编码器 调用并与管线实际一起运作的。
着色器即 GPUShaderModule,管线一般指 GPURenderPipeline、GPUComputePipeline 两个。
着色器支持把任意着色器混在一段字符串中,顶点着色器、片元着色器、计算着色器可以共用一个 GPUShaderModule 对象,只需指定入口函数,这点与 WebGL 分开创建 VS、FS 是不一样的。
管线可不是 WebGLProgram 的升级,虽然 gl.useProgram 和 passEncoder.setPipeline 在行为上有类似的作用,即切换到指定的行为过程,但是,在 WebGPU 中这两个管线对象,除了附着对应的着色器对象外,还限定着管线不同阶段对应的状态参数。有三个状态参数对应着两大管线:
vertex、fragment
compute
例如:
/*
---------
这里不详细展开,仅作为简略
---------
*/
const positionAttribDesc: GPUVertexAttribute = {
shaderLocation: 0, // wgsl - @location(0)
offset: 0,
format: 'float32x3'
}
const colorAttribDesc: GPUVertexAttribute = {
shaderLocation: 1, // wgsl - @location(1)
offset: 0,
format: 'float32x3'
}
const positionBufferDesc: GPUVertexBufferLayout = {
attributes: [positionAttribDesc],
arrayStride: 4 * 3, // sizeof(float) * 3
}
const colorBufferDesc: GPUVertexBufferLayout = {
attributes: [colorAttribDesc],
arrayStride: 4 * 3, // sizeof(float) * 3
}
// --- 创建 state 参数对象
const vertexState: GPUVertexState = {
module: shaderModule,
entryPoint: 'vs_main',
buffers: [positionBufferDesc, colorBufferDesc]
}
const fragmentState: GPUFragmentState = {
module: shaderModule,
entryPoint: 'fs_main',
targets: [{
format: navigator.gpu.getPreferredCanvasFormat()
}],
}
const primitiveState: GPUPrimitiveState = {
topology: 'triangle-list'
}
// --- 渲染管线 ---
const renderPipeline = device.createRenderPipeline({
layout: 'auto',
vertex: vertexState,
fragment: fragmentState,
primitive: primitiveState
})
// --- 计算管线 ---
const computePipeline = device.createComputePipeline({
layout: 'auto',
compute: {
module: shaderModule,
entryPoint: 'cs_main',
}
})
对应 GPUVertexState、GPUFragmentState、GPUComputeState 类型;上面说到绑定组是与管线紧密相关的,这几个状态参数对象,与绑定组中的各个资源对象有着对应关系。
着色器模块对象和管线对象也是由 GPUDevice 创建的,管线对象甚至提供了异步创建的方法。
WebGPU 使用“编码器”去“记录”一帧内要做什么事情,譬如切换管线、设定接下来要用什么缓冲、绑定组,进而要进行什么操作(绘图或触发并行计算)。
这有什么好处?
编码器“记录”这些行为,是在 CPU 侧,也就是 JavaScript 完成的,这就解决了 WebGL 全局状态对象的问题:改变一个状态,就要发起一条或多条 GL 函数的调用(尽管使用扩展或在 WebGL 2.0 用各种技术进行了弥补,但是也不能实际解决问题)。
编码记录完成后,会在 CPU 这边生成一个叫做“指令缓冲”对象,把当前帧的所有指令缓冲一次性提交给一个队列,那么当前帧就结束了战斗。
合情合理,大部分的逻辑组织交给更擅长处理这些事情的 CPU 完成,最后集中发射给 GPU,这就是 WebGPU 于 WebGL 的一大优点。
编码器有哪些?
上面一段文字比较粗略。
首先,为了区分绘图操作、GPU 通用计算操作,WebGPU 使用“渲染通道编码器”、“计算通道编码器”,也就是 GPURenderPassEncoder、GPUComputePassEncoder 来实现各自的行为编码、记录;以渲染通道编码为例:

上图参考自博客 Raw WebGPU。
而能创建这两个特定 GPU 计算的“通道编码器”的,叫做“指令编码器”,也就是 GPUCommandEncoder:
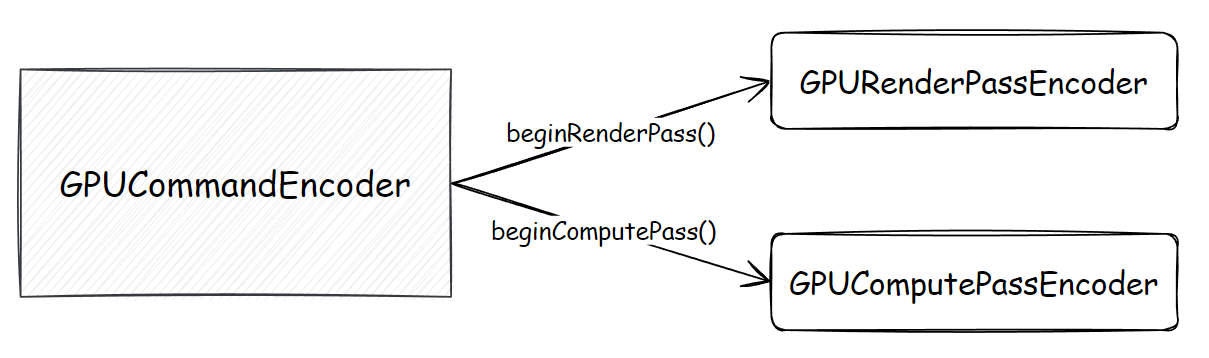
指令编码器除了承载上面两个通道编码器的编码结果外,还额外提供了资源的拷贝行为、查询行为的编码,例如纹理与缓冲对象之间的互相拷贝等:

在实际的代码中,是按 GPUCommandEncoder 调用某个方法的顺序进行记录的,例如 beginRenderPass()、copyBufferToTexture() 等。
队列与指令缓冲
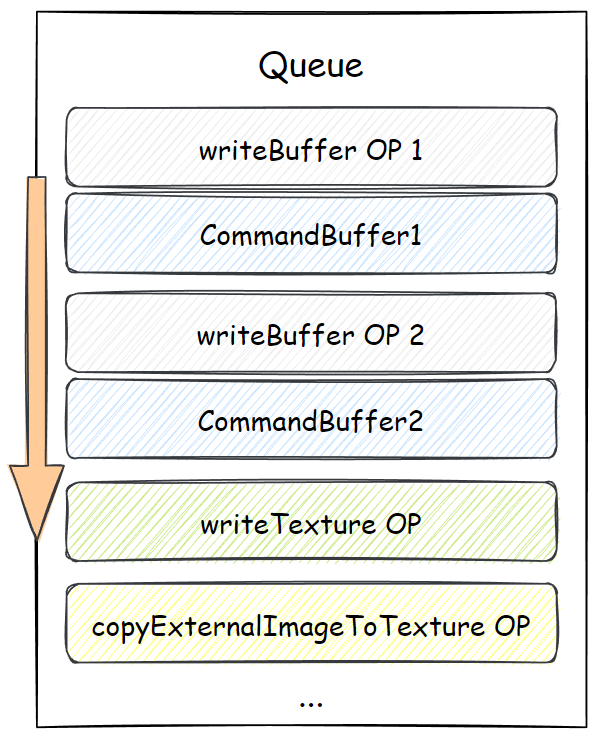
指令编码器的 finish 方法返回一个指令缓冲对象,即 GPUCommandBuffer,这个可以提交给队列对象 GPUQueue,队列对象是设备对象上的一个实例字段。
排列在队列上的除了指令缓冲,还有队列自己发出的“队列时间线”上的行为,例如写入缓冲数据、写入纹理数据等。图示如下:
缓冲映射,简单的说就是使得内存、显存中的缓冲数据可以交换着用的一种机制。详细的文章可以参考:
WebGPU 规范中不同的行为也许发生在的层面是不一样的,每个层面在运作的过程中都有它自己的时间线。规范给出了三条时间线:
内容时间线:内容时间线上的行为,大多数是 JavaScript 对象的创建、JavaScript 方法的调用,这是最上面的一层;
设备时间线:此“设备”非 GPUDevice;设备时间线上的行为,大多数是指浏览器底层 WebGPU 实现中的变化,这类行为的层级低于 JavaScript 的执行,操作的是“内部对象”,却还没到 GPU 执行的部分,例如生成指令缓冲;
队列时间线:此“队列”非 GPUQueue;队列时间线上发生的行为,通常就是指 GPU 中具体任务的执行,例如绘制、资源上载、资源复制、通用计算调度等。
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
我正在尝试创建一个与compass一起使用的本地配置文件,这样我们就可以处理开发人员机器上的不同导入路径。到目前为止,我已经尝试将文件导入到异常block中,以防它不存在,然后进一步使用该变量:local_config.rbVENV_FOLDER='venv'config.rbVENV_FOLDER='.'beginrequire'local_config.rb'rescueLoadErrorendputsVENV_FOLDER通常我是一名Python开发人员,所以我希望导入将VENV_FOLDER的值更改为venv,但它仍然是。之后。有没有一种方法可以导入local_config.r
最好用一个例子来解释:文件1.rb:deffooputs123end文件2.rb:classArequire'file1'endA.new.foo将给出错误“':调用了私有(private)方法'foo'”。我可以通过执行A.new.send("foo")来解决这个问题,但是有没有办法公开导入的方法?编辑:澄清一下,我没有混淆include和require。另外,我不能使用正常包含的原因(正如许多人正确指出的那样)是因为这是元编程设置的一部分。我需要允许用户在运行时添加功能;例如,他可以说“run-this-app--includefile1.rb”,应用程序的行为将根据他在file1
尝试在我的Rails应用程序中导入CSV文件时,出现错误UTF-8中的无效字节序列。一切正常,直到我添加了一个gsub方法来将其中一个CSV列与我的数据库中的一个字段进行比较。当我导入CSV文件时,我想检查每一行的地址是否包含在特定客户端的不同地址数组中。我有一个带有alt_addresses属性的客户端模型,其中包含客户端地址的几种不同可能格式。然后我有一个引用模型(如果您熟悉本地SEO,您就会知道这个术语)。引用模型没有地址字段,但它有一个nap_correct?字段(NAP代表“姓名”、“地址”、“电话号码”)。如果CSV行的名称、地址和电话号码与我在该客户的数据库中拥有的相同,
我的感觉是Camping和Sinatra之间的差异不是很大,您可以安全地选择其中任何一个并且没问题。但我想问问Ruby专家,这是不是真的。Sinatra和Camping微框架之间实际上有什么重要区别吗?您将如何决定使用哪一个? 最佳答案 我知道的唯一显着区别是Camping像Rails一样基于MVC模式,并且与ActiveRecord耦合。Sinatra更加不可知。Camping也不再维护,而Sinatra正在积极开发中。仅这一点就足以让我们先看看Sinatra。编辑:感谢Philippe的更正,很高兴听到Camping的开发正在进
我是Ruby分析的新手,看起来像ruby-prof是一个受欢迎的选择。我刚刚安装了gem并调用了我的程序:ruby-prof./my-prog.rb但是,输出非常冗长,因为包含所有Ruby核心和标准库方法以及其他gem的分析数据。例如,前三行是:8.790.0110.0100.0000.0013343*String#%7.280.0780.0090.0000.0692068*Array#each4.930.0380.0060.0000.0321098*Array#map这对我来说不是什么有用的信息,因为我已经知道我的程序经常处理字符串和数组,并且大概已经对这些类进行了优化。我只关心我代
下面两个语句除了编码风格有区别吗?/regex/=~"some_string_with_regex""some_string_with_regex"=~/regex/ 最佳答案 是的,有区别。正如在http://www.ruby-doc.org/core/classes/Regexp.html#M001232中提到的If=~isusedwitharegexpliteralwithnamedcaptures,capturedstrings(ornil)isassignedtolocalvariablesnamedbythecaptur
我在bitbucket上创建了一个私有(private)git存储库并提交了代码。现在我想导出所有(提交、代码、历史记录)并将其导入github上的gitrepo。有没有办法做到这一点?谢谢 最佳答案 在本地检查所有内容到您的计算机和gitpull。创建一个github存储库将此存储库添加为您的第二个远程(“使用gitremote添加githubURL”)推送到第二个Remote 关于ruby-git:从bitbucket导出并导入github(带提交),我们在StackOverflow
点击->操作系统复习的文章集目录操作系统线程线程是什么进程与线程的关系用户态/内核态操作系统资源管理内核态用户态内核态/用户态切换程序运行类型分析计算密集型IO密集型结合进程,线程来理解程序运行类型分析协程基础上下文切换协程协程为什么叫协作式线程?协程的优缺点操作系统线程典型问题:简述进程和线程的区别以下内容带您一步步了解线程是什么比进程更小的独立运行的基本单位-线程(Threads)线程的提出主要是为了提高系统内程序并发执行的程度,从而进一步提升系统的吞吐量,充分发挥多核CPU的优越性而设计的引入进程是为了操作系统更加方便地管理程序,使得多个程序能并发管理和执行而线程则是为了减少程序在并发执
目录一、什么是Websocket二、WebSocket部分header介绍三、HTTPVSWebSocket四、什么时候使用WebSockets五、关于SockJS和STOMP一、什么是Websocket根据RFC6455标准,Websocket协议提供了一种标准化的方式在客户端和服务端之间通过TCP连接建立全双工、双向通信渠道。它是一种不同于HTTP的TCP协议,但是被设计为在HTTP基础上运行。Websocket交互始于HTTP请求,该请求会通过HTTPUpgrade请求头去升级请求,进而切换到Websocket协议。请求报文如下:GET/spring-websocket-portfoli