Kafka 是由 LinkedIn 开发一个分布式的基于发布订阅模式的消息队列,是一个实时数据处理系统,可以横向扩展。与 RabbitMQ、RockerMQ 等中间件一样拥有几大特点:
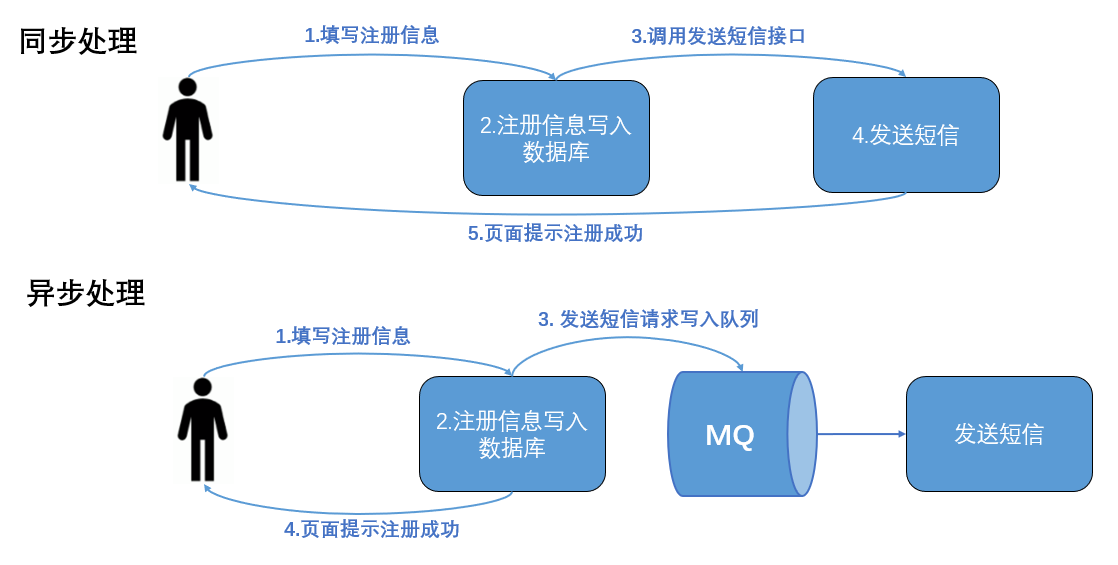
下图是异步处理的示例图。
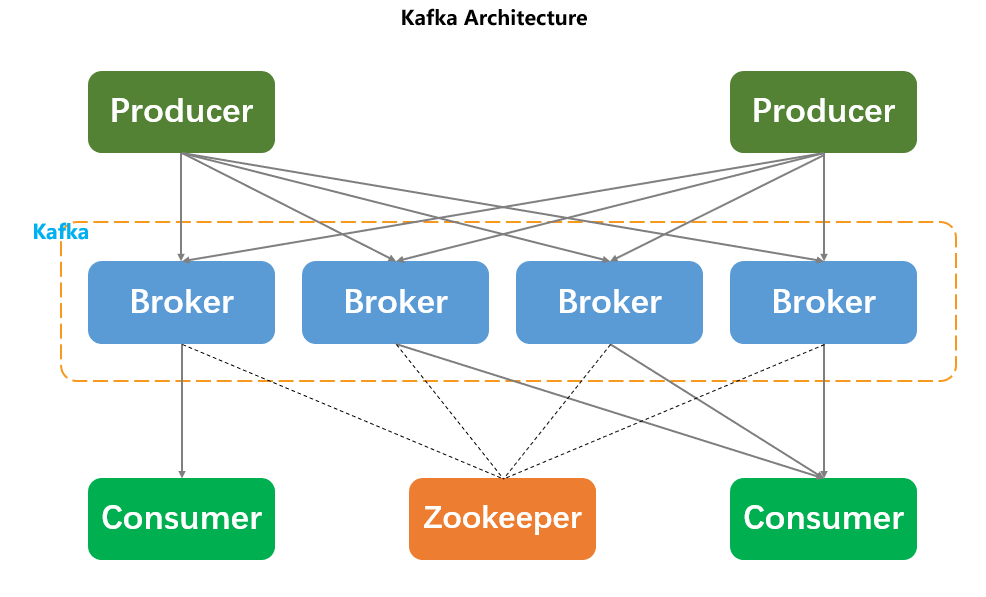
如下图,一个 Kafka 架构包含若干个 Producer,若干个 Consumer,若干个 Broker 和一个 Zookeeper 集群。
Kafka 对消息进行归类,发送到集群的每一条消息都要指定一个 Topic, 一个 Topic 为一类消息,逻辑上被认为是一个 Queue,Producer 生产的每条消息必须指定一个 Topic,然后 Consumer 会根据订阅的 Topic 到对应的 Broker 上去拉取消息。每个 Topic 包含一个或多个 Partition,一个 Partition 对应一个文件夹,这个文件夹下存储 Partition (分区) 的数据和索引文件,每个 Partition 内部是有序的。这样一个 Topic 分成一个或多个 Partition,每个 Partition 有多个副本分布在不同的 Broker中。一个分区的多个副本之间是一主(Leader)多从(Follower)的关系,Leader 对外提供服务,这里的对外指的是与客户端程序进行交互,而 Follower 只是被动地同步 Leader 而已,不能与外界进行交互。通过多副本机制实现了故障的自动转移,当集群中某个 Broker 失效时仍然能保证服务可用,可以提升容灾能力。 如下图所示,Kafka 集群中有 4 个 Broker,某个 Topic 有三个分区,假设副本因子也设置为了 3,那么每个分区就会有一个 Leader 和两个 Follower 副本。
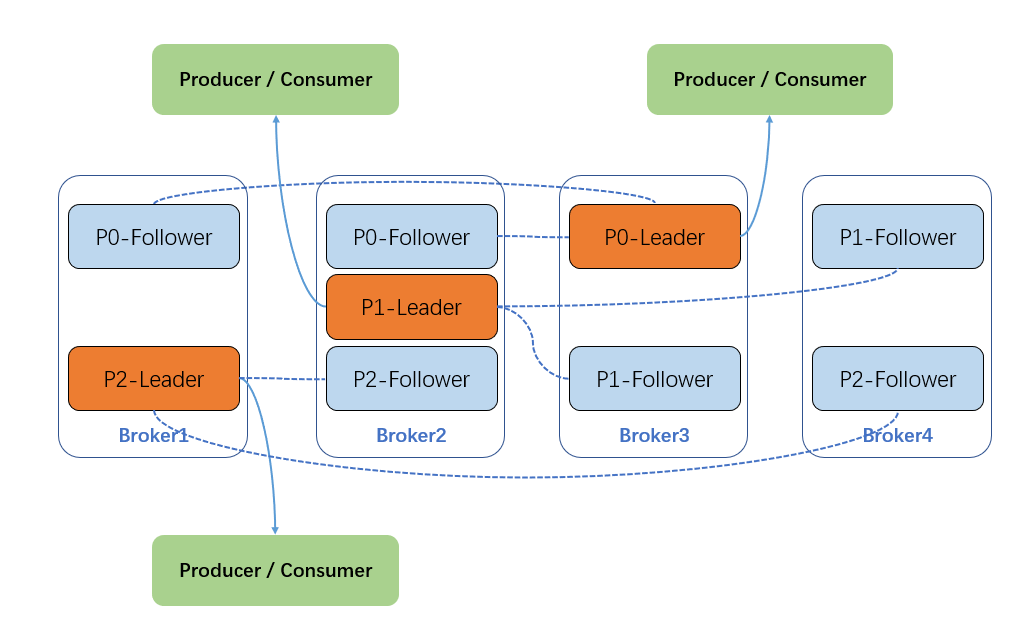
分区副本处于不同 Broker 中,生产者与消费者只和 Leader 副本进行交互,而 Follower 副本只负责消息的同步。当 Leader 副本出现故障时,会从 Follower 副本中重新选举新的 Leader 副本对外提供服务。
下面来看一下 Kafka 多副本机制中的一些重要术语。
首先,生产者会将消息发送给 Leader 副本,然后 Follower 副本才能从 Leader 中拉取消息进行同步,在同一时刻,所有副本中的消息不完全相同,也就是说同步期间,Follower 相对于 Leader 而言会有一定程度上的滞后。这样可以看到三者的关系:AR = ISR + OSR。
Leader 负责维护和跟踪 ISR 集合中所有 Follower 副本的滞后状态,当 Follower 出现滞后太多或者失效时,Leader 将会把它从 ISR 集合中剔除。当然,如果 OSR 集合中有 Follower 同步范围追上了 Leader,那么 Leader 也会把它从 OSR 集合中转移至 ISR 集合。一般情况下,当 Leader 发送故障或失效时,只有 ISR 集合中的 Follower 才有资格被选举为新的 Leader,而 OSR 集合中的 Follower 则没有这个机会(不过可以修改参数配置来改变)。
接下来介绍 Kafka 指标的详细信息。
UnderReplicatedPartitions¶
UnderReplicatedPartitions 未同步状态的分区个数,即失效副本的分区数,异常值非 0。在运行状况良好的群集中,同步副本(ISR)的数量应完全等于副本的总数。 该值非零表示 Broker 上的 Leader 分区存在没有完全同步并跟上 ISR 的副本的分区数量。可能存在问题:
| 指标集 | kafka_replica_manager | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| UnderReplicatedPartitions | 处于未同步状态的 Partition 个数 | int |
| UnderMinIsrPartitionCount | 低于最小 ISR Partition 个数。 | int |
OfflineLogDirectoryCount¶
OfflineLogDirectoryCount 离线日志目录数量,异常值非 0 。需要观测该指标,以检查是否存在脱机日志目录。
| 指标集 | kafka_log | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| OfflineLogDirectoryCount | 离线日志目录数量 | int |
IsrShrinksPerSec / IsrExpandsPerSec¶
任意一个分区的处于同步状态的副本数(ISR)应该保持稳定,除非您正在扩展 Broker 节点或删除分区。 为了保持高可用, Kafka 集群必须保证最小 ISR 数,以防在某个分区的 Leader 挂掉时它的 Follower 可以接管。一个副本从 ISR 池中移走有以下一些原因:Follower 的 offset 远远落后于 Leader(改变 replica.lag.max.messages 配置项),或者某个 Follower 已经与 Leader 失去联系了某一段时间(改变 replica.socket.timeout.ms 配置项),不管是什么原因,如果 IsrShrinksPerSec(ISR缩水) 增加了,但并没有随之而来的 IsrExpandsPerSec(ISR 扩展)的增加,就将引起重视并人工介入。
| 指标集 | kafka_replica_manager | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| IsrShrinksPerSec.Count | ISR 缩减数量 | int |
| IsrShrinksPerSec.OneMinuteRate | ISR 缩减频率 | float |
| IsrExpandsPerSec.Count | ISR 膨胀数量 | int |
| IsrExpandsPerSec.OneMinuteRate | ISR 膨胀频率 | float |
ActiveControllerCount¶
ActiveControllerCount 当前处于激活状态的控制器的数量,异常值 0。Kafka 集群中第一个启动的节点自动成为 Controller,有且只能有一个这样的节点、正常情况下 Controller 所在的 Broker 上的这个指标应该是 1,其它 Broker 上的这个值应该是 0。Controller 的职责是维护分区 Leader 的列表,当某个 Leader 不可用时协调 Leader 的变更。如果有必要更换 Controller,一个新的 Controller 将会被 Zookeeper 从 Broker 池中随机的选取出来,通常来说这个值不可能大于 1,但当遇到这个值等于 0 且持续了一段时间 (<1) 的时候,必须发出明确的警告,所以该指标可用作告警。
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| ActiveControllerCount.Value | Controller 存活数量 | int |
OfflinePartitionsCount¶
OfflinePartitionsCount 没有活跃 Leader 的分区数,异常值非 0。由于所有的读写操作都只在 Partition Leader上进行,任何没有活跃 Leader 的 Partition 都会彻底不可用,且该 Partition 上的消费者和生产者都将被阻塞,直到 Leader 变成可用。该指标可用作告警。
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| OfflinePartitionsCount.Value | 下线 Partition 数量 | int |
LeaderElectionRateAndTimeMs¶
当 Parition Leader 挂了之后就会触发选举,就会触发新 Leader 的选举。通过 LeaderElectionRateAndTimeMs 可以观测 Leader 每秒钟选举多少次,选举频率。
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| LeaderElectionRateAndTimeMs.Count | Leader 选举次数 | int |
| LeaderElectionRateAndTimeMs.OneMinuteRate | Leader 选举比率 | float |
| LeaderElectionRateAndTimeMs.50thPercentile | Leader 选举比率 | float |
| LeaderElectionRateAndTimeMs.75thPercentile | Leader 选举比率 | float |
| LeaderElectionRateAndTimeMs.99thPercentile | Leader 选举比率 | float |
UncleanLeaderElectionsPerSec¶
当 Kafka Brokers 分区 Leader 不可用时,就会发生 unclean 的 Leader 选举,将从该分区的 ISR 集中选举出新的 Leader。 从本质上讲,unclean leader 选举牺牲了可用性的一致性。 同步中没有可用的副本,只能在未同步的副本中进行 Leader 选举,则前 Leader 未经同步的消息都会永远丢失。UncleanLeaderElectionsPerSec.Count 异常值是不等于 0,此时代表着数据丢失,因此需要进行告警。
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| UncleanLeaderElectionsPerSec.Count | Unclean Leader 选举次数 | int |
TotalTimeMs¶
TotalTimeMs 度量本身是四个指标的总和:
TotalTimeMs 用来衡量服务器请求的用时,正常情况下该指标比较稳定,只有非常小的波段,如果发现异常,则会出现不规则的数据波动。这时需要检查各个 queue、local、remote 和 response 的值,定位处造成延迟的原因到底处于哪个 segment。
| 指标集 | kafka_request | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| TotalTimeMs.Count | 总请求用时 | int |
PurgatorySize¶
PurgatorySize: 作为一个临时存放的区域,使得生产(produce)和消费(fetch)的请求在那里等待直到被需要的时候。留意 purgatory 的大小有助于确定潜伏期的根本原因。例如,如果 purgatory 队列中获取请求的数量相应增加,则可以很容易地解释消费者获取时间的增加。
| 指标集 | kafka_purgatory | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| Fetch.PurgatorySize | Fetch Purgatory 大小 | int |
| Produce.PurgatorySize | Produce Purgatory 大小 | int |
| Rebalance.PurgatorySize | Rebalance Purgatory 大小 | int |
| topic.PurgatorySize | topic Purgatory 大小 | int |
| ElectLeader.PurgatorySize | 选举 Leader Purgatory 大小 | int |
| DeleteRecords.PurgatorySize | 删除记录 Purgatory 大小 | int |
| DeleteRecords.NumDelayedOperations | 延时删除记录数 | int |
| Heartbeat.NumDelayedOperations | 心跳监测 | int |
BytesInPerSec / BytesOutPerSec¶
BytesInPerSec/BytesOutPerSec 传入/传出字节数。通常磁盘吞吐量、网络吞吐量都可能成为瓶颈。 如果您要跨数据中心发送消息,Topic 数量众多,或者副本正在赶上 Leader,则网络吞吐量可能会影响 Kafka 的性能。 通过这些指标,在跟踪 Broker 上的网络吞吐量来判断瓶颈出在何处。
| 指标集 | kafka_topics | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| BytesInPerSec.Count | 每秒流入字节数 | int |
| BytesInPerSec.OneMinuteRate | 每秒流入速率 | float |
| BytesOutPerSec.Count | 每秒流出字节数 | int |
| BytesOutPerSec.OneMinuteRate | 每秒流出速率 | float |
RequestsPerSec¶
RequestsPerSec 每秒请求次数。通过观测该指标,可以实时掌握生产者,消费者的请求率,以确保您的 Kafka 高效通信。如果该指标持续维持高位,可以考虑增加生产者或者消费者的数量,进而提高吞吐量,从而减少不必要的网络开销。
| 指标集 | kafka_topics | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| TotalFetchRequestsPerSec.Count | 每秒拉取请求的次数 | int |
| TotalProduceRequestsPerSec.Count | 生产者每秒写入请求的次数 | int |
| FailedFetchRequestsPerSec.Count | Topic 失败 Fetch 数量 | int |
| FailedProduceRequestsPerSec.Count | 发送请求失败速率 | int |
其它常用指标¶
| 指标集 | kafka_controller | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| GlobalTopicCount.Value | 集群总 Topic 数量 | int |
| GlobalPartitionCount.Value | 分区数 | int |
| TotalQueueSize.Value | 队列总数 | int |
| EventQueueSize.Value | 事件队列数 | int |
| 指标集 | kafka_request | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| RequestQueueTimeMs.Count | 请求队列时间 | int |
| ResponseSendTimeMs.Count | 相应队列时间 | int |
| MessageConversionsTimeMs.Count | 消息转换时间 | int |
| 指标集 | kafka_topics | |
|---|---|---|
| 指标 | 描述 | 数据类型 |
| PartitionCount.Value | Partition 数量 | int |
| LeaderCount.Value | Leader 数量 | int |
| BytesRejectedPerSec.Count | Topic 请求被拒绝数量 | int |
在开始使用观测云观测 Kafka 之前,您需要先注册一个 观测云账号 ,注册完成后登录到观测云工作空间。然后按照 Kafka 集成文档来实现 Kafka 的可观测。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i