文章目录
2.2、超前进位加法器(Carry-Lookahead Adder,CLA)
FPGA底层的CARRY4本质上就是用来实现最基本的加、减法运算的,在了解CARRY4之前,我们需要对1bit以及多bit的二进制加法及其FPGA实现做一个了解。
1bit的二进制加法可以分为两类:无底层进位的半加器与有底层进位的全加器。减法运算本质上仍是一种加法运算,在二进制电路中采用加上负数的补码实现。
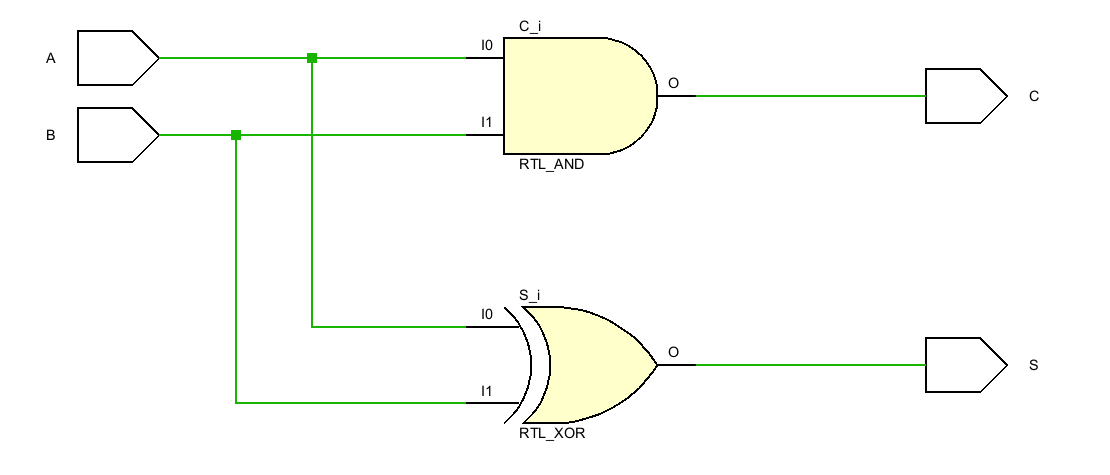
半加器电路是指对两个输入数据位相加,输出一个结果位和进位,没有进位输入的加法器电路。
半加器有两个1位2进制数输入,输出1个进位、1个结果位。真值表如下:
| A | B | Carry | Sum |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 0 |
从真值表,我们可以推断出其实现:
映射到电路就是一个2输入异或门加一个2输入与门:
全加器是在半加器的基础上的升级版,除了加数和被加数加和外还要加上前上一级传进来的进位信号。全加器真值表为:
| A | B | Cin | Cout | Sum |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 0 | 1 |
| 1 | 1 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 1 | 1 | 0 |
| 0 | 1 | 1 | 1 | 0 |
| 1 | 1 | 1 | 1 | 1 |
从真值表,我们可以推断出其实现:
映射到电路的实现:
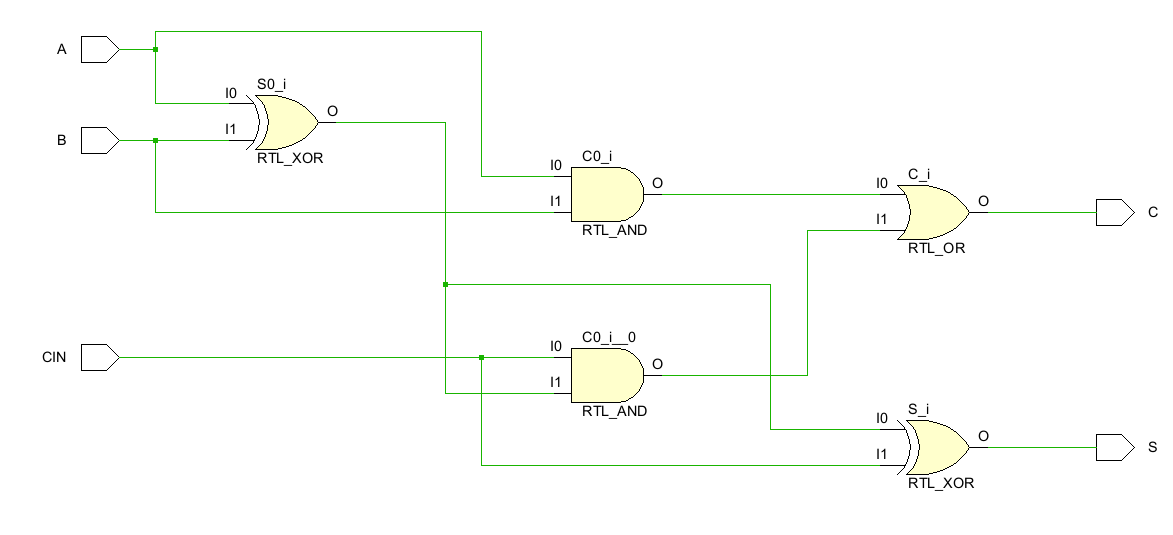
比半加器要复杂一些,构成为2个异或门+2个与门+1个或门。
有了单个bit的二进制加法电路(全加器)后,我们就可以通过级联来实现多bit的二进制加法了,但是多个全加器如何级联则是一个需要考虑的问题。
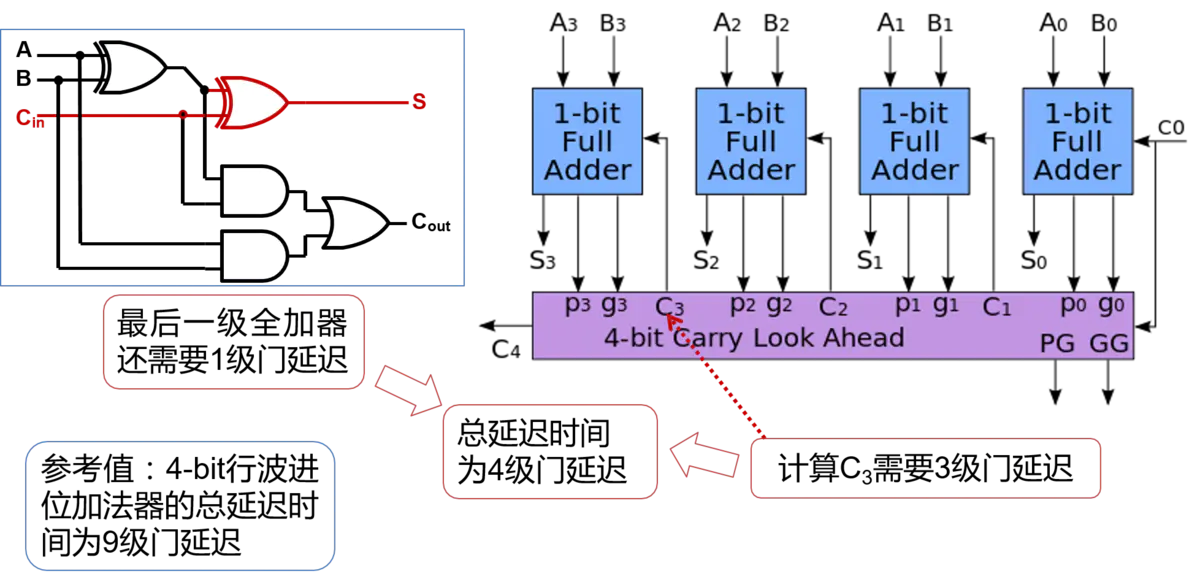
进行两个4bit的二进制数相加,就要用到4个全加器。那么在进行加法运算时,首先准备好的是1号全加器的3个input。而2、3、4号全加器的Cin全部来自前一个全加器的Cout,只有等到1号全加器运算完毕,2、3、4号全加器才能依次进行进位运算,最终得到结果。 这样进位输出,像波浪一样,依次从低位到高位传递, 最终产生结果的加法器,也因此得名为行波进位加法器(Ripple-Carry Adder,RCA)。
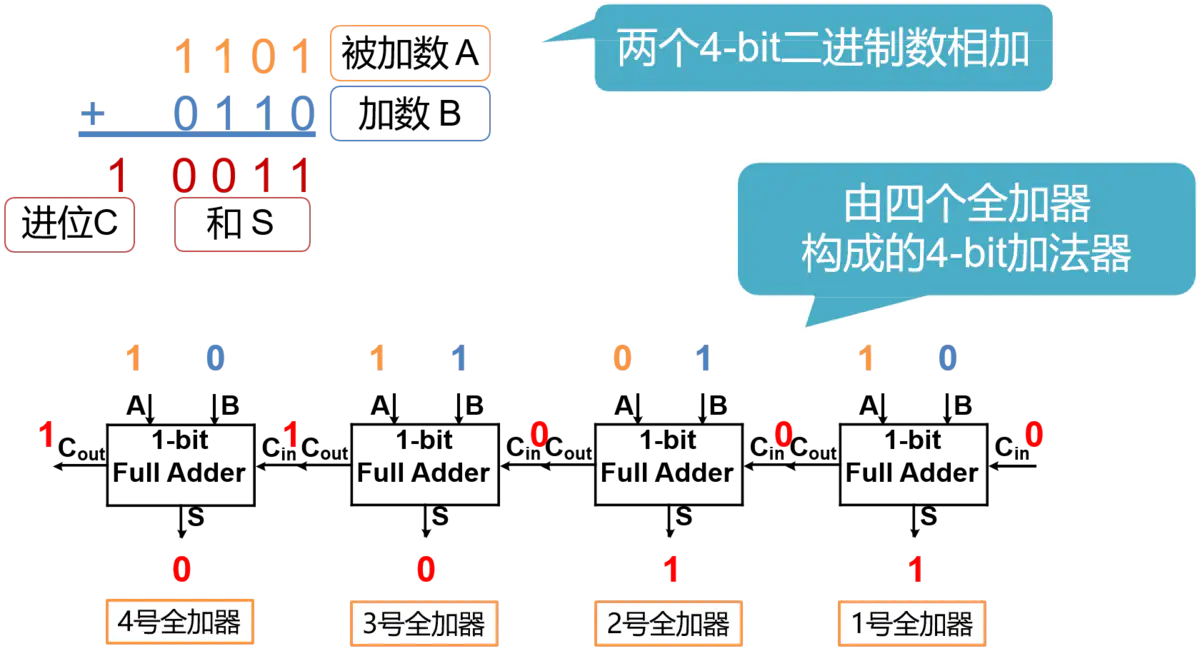
RCA的优点是电路布局简单,设计方便, 我们只要设计好了全加器,连接起来就构成了多位的加法器。 但是缺点也很明显,也就是高位的运算必须等待低位的运算完成, 这样造成了整个加法器的延迟时间很长。将4bit的RCA内部结构全部打开,就得到了如图所示的4-bit RCA的门电路图。要对一个电路的性能进行分析,我们就要找出其中的最长路径。 也就是找出所有的从输入到输出的电路连接中,经过的门数最多的那一条,也称为关键路径。
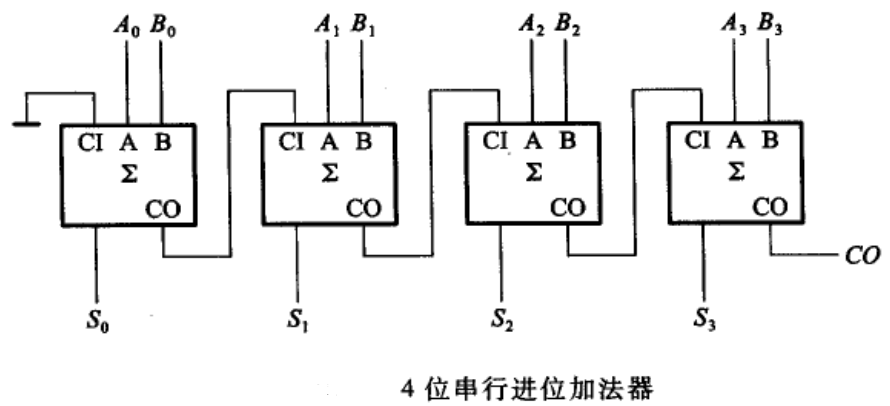
我们来做一个简单的分析, 对于最低位的全加器,它在A、B和Cin都已经准备好。其实,输入信号进入到这块电路之后,在连接线上传递需要花时间。 称为线延迟,而经过这样的门,也需要花时间,称为门延迟。
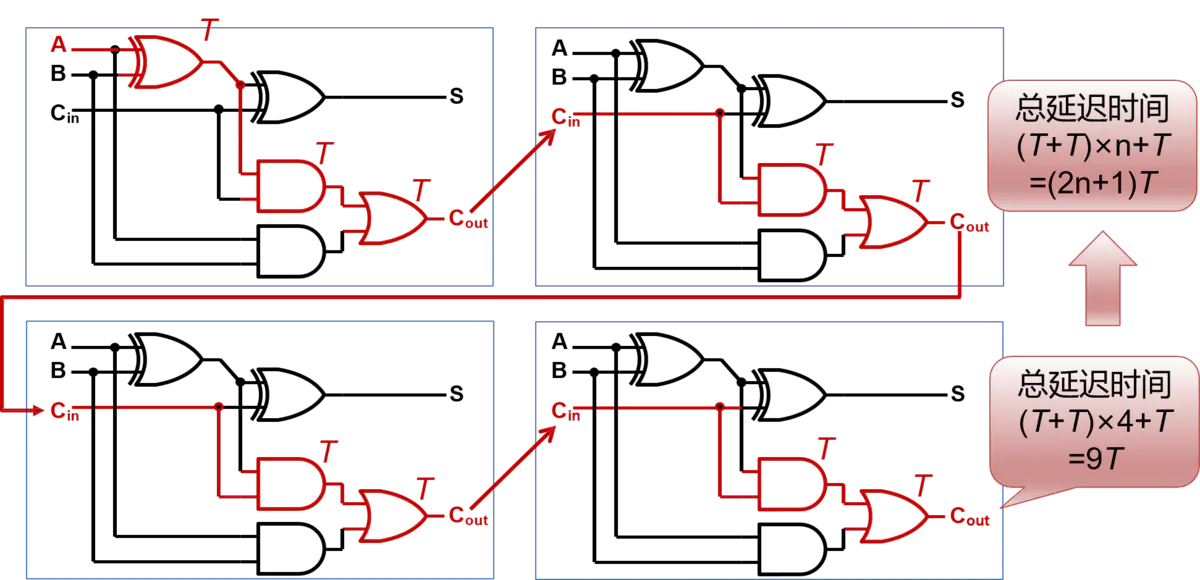
对于第一个全加器,它的最长路径,是红色线标记的那条。
那么,假设经过一个门电路的延迟时间为T,那么经过4个全加器所需要的总延迟时间就是:2T x 4 + T(第一个全加器产生3个T) = 9T。所以推出,经过n个全加器所产生的总延迟时间为2T x n + T = (2n+1)T。从此可以看出来RCA电路的最大问题就是组合逻辑延迟太高。
用前一个全加器的参数来表示后面的进位输出(Cout),即:
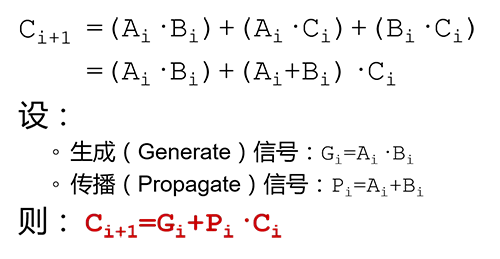
由此来表示4个全加器的进位输出为:

最终需要得到的是C4,经过换算,C4=G3+P3·G2+P3·P2·G1+P3·P2·P1·G0+P3·P2·P1·P0·C0,而这些参数,全部已知!并不需要前一个全加器运算输出,就可以提前计算进位输出, 用这样的方法实现了加法器就被称为超前进位加法器(Carry-Lookahead Adder,CLA)。
重新绘制CLA的布线方式:
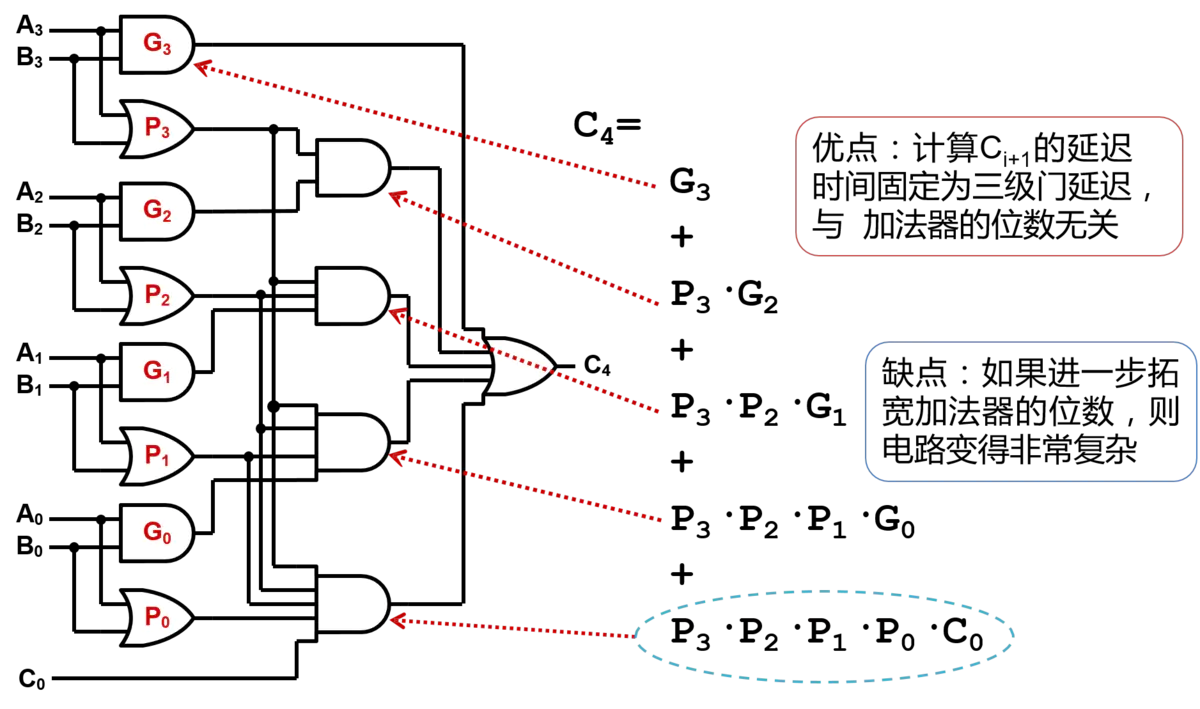
CLA的方式获得了较短的组合逻辑延迟,但是电路的面积却大了非常的多,这就是FPGA设计中非常经典的“面积换时间”。
同时需要注意的是,上面的门电路实现仅仅是求得C4,而如果要同时求C3 C2 C1的话,电路面积还会增大许多。
所以在FPGA内部会是使用CLA这种方式来实现加法器吗?答案是也不是。
Xilinx FPGA底层的加法器(进位链)CARRY4是一种超前进位的加法器,但是为了面积与普适性其实现原理与上述的CLA电路还是有一点区别。
每个SLICE中都有1个(每个CLB则有2个)CARRY4用来实现进位逻辑,不同的进位链可级联以形成更宽的加/减逻辑:
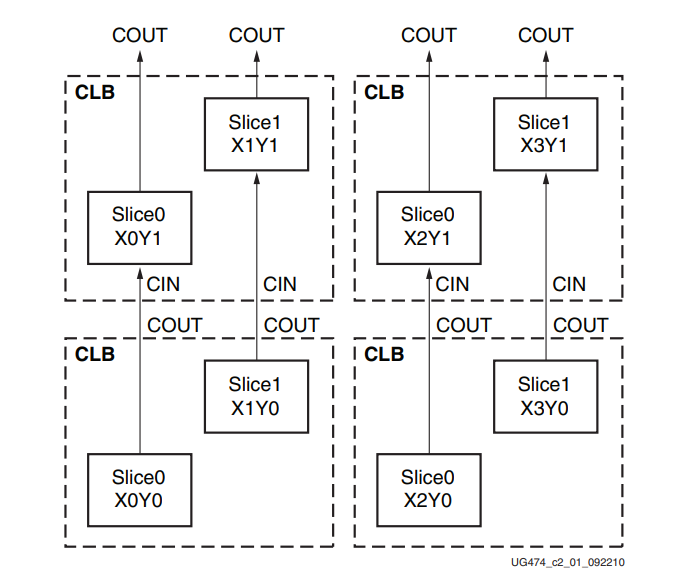
先来看下CARRY的整体构成及其端口:
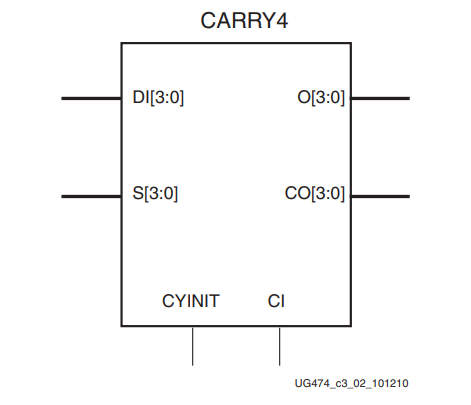
端口含义:
仅仅只看端口无法理解CARRY4是如何实现进位算法的,接下来看下内部的具体实现:
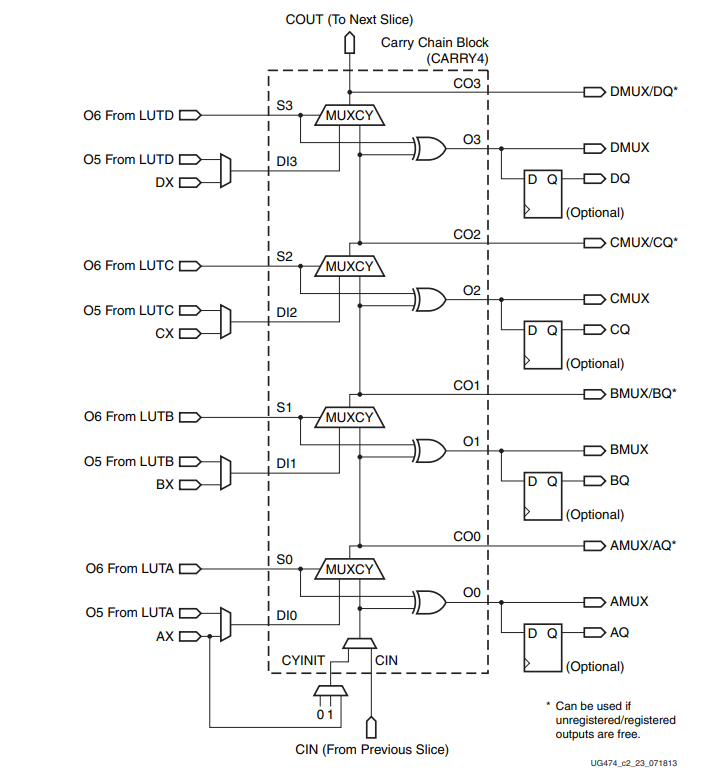
从上图可以看到,实际上CARRY4是分为相同的4个部分的,每个部分都用MUX2加异或门来实现进位逻辑。
这里需要说明的是,上述MUX2的实现逻辑均为:S = 0,结果为左侧输入; S = 1,结果为则右侧输入。
一步一步来看:
(一:O0、CO0)
最底层的结果O0等于S0异或CIN,S0则为两个加数的异或,也就是O0 = A0 ^ B0^ CIN。
若S0 = 0,则意味着两个加数相等,即00或11,此时O0的结果与CIN一致。若S0 = 1,则意味着两个加数不相等,即01或10,此时O0的结果与CIN相反。
当S0 = 0,则意味着两个加数相等,即00或11,此时MUX2选择DI0作为进位CO0的结果。若DI0为0,则意味着A0,B0,CO0都为0;若DI0为1,则意味着A0,B0,CO0都为1;
当S0 = 1,则意味着两个加数不相等,即01或10,此时MUX2选择CIN作为进位CO0的结果。若CIN为0,则意味着A0,B0,CIN为100,此时不需要进位,与CIN相等;若CIN为1,则意味着A0,B0,CIN为101,此时需要进位,仍与CIN相等;
省略(O1、CO1),(O2、CO2)的推断过程······
(四:O3、CO3)
结果O3等于S3异或CO2,S3则为两个加数的异或,也就是O3 = A3 ^ B3 ^ CO2。
若S3 = 0,则意味着两个加数相等,即00或11,此时O3的结果与CO2一致。
若S3 = 1,则意味着两个加数不相等,即01或10,此时O3的结果与CO2相反。
当S3 = 0,则意味着两个加数相等,即00或11,此时MUX2选择DI3作为进位CO3的结果。若DI3为0,则意味着A3,B3,CO3都为0;若DI3为1,则意味着A3,B3,CO3都为1;
当S3 = 1,则意味着两个加数不相等,即01或10,此时MUX2选择CO2作为进位CO3的结果。若CO2为0,则意味着A3,B3,CO2为100,此时不需要进位,与CO2相等;若CO2为1,则意味着A3,B3,CO2为101,此时需要进位,仍与CO2相等;
这样的结构看起来很像行波进位加法器RCA,最高层的进位需要从最底层一步步往上传递,实则不然。
可以举例,假如两个加数的最高位A3,B3为00或11,即S3=0时,此时的CO3直接等于DI3(因为00+0不进位和11+1要进位),也就是A3或者说B3(相等的),此时就不需要从下一层传递进位信号过来参与运算,这一情况出现的概率为50%。而另外50%的情况A3,B3不相等,即01或10(S3=1)时,此时的CO3取决于CO2(因为10或01+1进位;+0则不进位)。在次高位到最低位的情况均与上述一致。
也就是说只有在最极端的情况下,才需要在每一位考虑来自下一级的进位(如1010+0101,也就是每一位的两个加数均不一致),此时的进位组合逻辑是可能存在的最长组合逻辑路径。但是这种架构和上述的超前进位加法器比起来,其面积减少了非常多,仅使用了4个MUX2 + 4个XOR门,且这8个门电路均位于CLB的同一个SLICE里边,不同与传统的门电路的延迟,其线延迟可以控制得非常小。
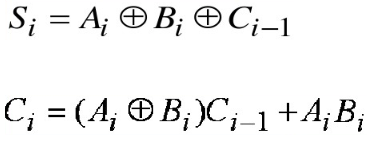
为什么说其本质还是超前进位加法器,我们可以从其逻辑式入手进行推断:
对于CARRY4,S=a ^ b端口D可以任选a、b输入当中的一个,如选择b
输出端:那么O端即表示输出端:O = S ^ cin = a ^ b ^ cin
进位端:
CO=(a^b)'b +(a^b)cin //多路复用器:y=s’b+scin
=(a’b+ab’)‘b+(a^b)cin
=(a’b)’(ab’)‘b+(a^b)cin
=(a+b’)(a’+b)b+(a^b)cin
=(ab+b’b)(a’+b)+(a^b)cin
=ab(a’+b)+(a^b)cin
=(a^b)cin+ab
假设有十进制的4bit数 4 + 8 =12,则二进制为 0100 + 1000 = 1100,用CARRY4的端口:
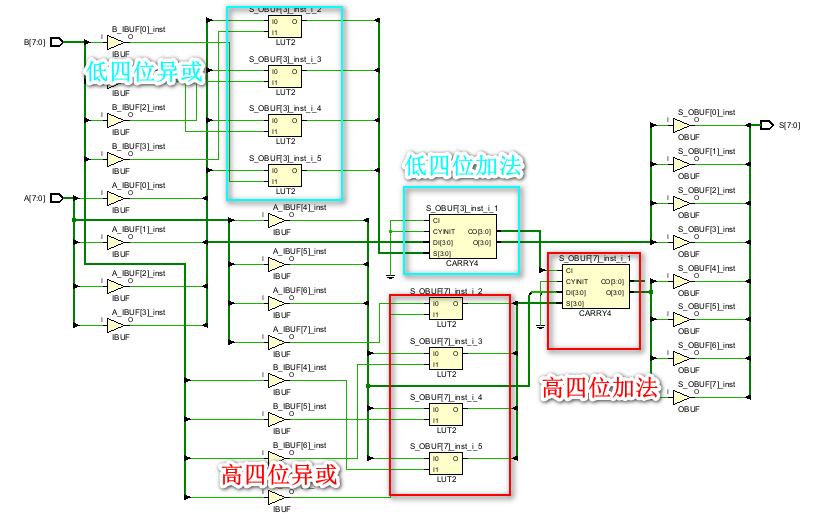
接下来写个简单的实例测试一下(2个8位数相加):
module test(
input [7:0] A,
input [7:0] B,
output [7:0] S
);
assign S = A + B;
endmodule 由于是8bit的加法,所以其综合结果是2个CARRY4级联组成。
`timescale 1ns / 1ns
module tb_test();
reg [7:0] A;
reg [7:0] B;
wire [7:0] S;
//例化test模块
test test_inst(
.A (A),
.B (B),
.S (S)
);
initial begin
A =0;
B =0;
#200 $finish;
end
always #10 begin
A ={$random }%64;
B ={$random }%64;
end
endmodule测试结果不说了,一目了然:

我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
我正在开发一个Rails应用程序,我需要在其中找到给定特定偏移量或时区的夏令时开始和结束日期。我基本上在我的数据库中保存了从用户浏览器接收到的时区偏移量(“+3”,“-5”),我想在它出现时修改它由于夏令时的变化。我知道Time实例变量有dst?和isdst方法,如果存储在它们中的日期在夏令时与否。>Time.new.isdst=>true但是使用它来查找夏令时的开始和结束日期会占用太多资源,而且我还必须为我拥有的每个时区偏移量执行此操作。我想知道更好的方法。 最佳答案 好的,基于你所说的和@dhouty'sanswer:您希望能够